 谷歌的研究人員提出了一種監督學習方法來實現語音特征的聚類
谷歌的研究人員提出了一種監督學習方法來實現語音特征的聚類
用過智能音箱的小伙伴可能會有過這樣的經歷,當你和朋友同時對它講話時,它有時候同時面對兩位小主的臨幸會感覺很凌亂,不知道該聽誰的,分不清到底是誰在向它發出指令誰才是它的主人。
其實這涉及到語音識別領域一個重要的問題Speaker diarization(即說話人分類技術),這一技術的目的在于從音頻流中分離出不同人說話的語音,并將分離出的語音歸并到所屬的說話人上,其核心問題在于解決“who speak when”。這一技術對于理解對話、視頻標注以及移動端語音識別具有重要的意義。
對于Speaker diarization來說,其處理過程一般分為四個步驟:
語音分割:將不同說話人的語音片段分割出來,在音頻流中標記分割點;
音頻特征抽取:利用諸如MFCC、說話人因子或i-vector等來從片段中抽取特征;
聚類:當檢測到多個說話人并獲取了對應語音片段的特征后需要利用聚類方法將相應的片段歸類到對應的說話人中去。
重分割:優化聚類結果來提升說話人分類的精度。
近年來,基于神經網絡的音頻處理系統促進了這一領域的快速發展,但要訓練一個在任意情況下能夠準確快速識別分類說話人的模型并不是一件簡單的事情。與標準的監督學習分類任務不同的是,說話人分類模型需要對新出現的說話人有著足夠魯棒的識別和分類性能,而在訓練的過程中卻無法囊括現實中各式各樣的說話人。這在很大程度上限制了語音識別系統特別是在線系統的實時能力。
雖然已有很多工作在這個領域進行了努力,但目前整個Speaker diarization系統中依然存在著非監督學習的部分——聚類過程。聚類的表現對于整個系統有著重要的作用,但目前大多數算法都是無監督的方法,這使得我們無法通過語音樣本的監督學習來改進這些算法。此外典型的聚類方法如k均值和譜聚類等非監督算法對于在線說話人識別時,應對不斷輸入的音頻流很難有效聚類。
為了進一步提高模型的表現,谷歌的研究人員提出了一種監督學習方法來實現語音特征的聚類。在最近發表的論文“Fully Supervised Speaker Diarization”中,研究人員提出了一個名為unbounded interleaved-state recurrentneural network (UIS-RNN)的聚類算法來提高了模型的性能。在語音識別數據集上達到了7.6%的錯誤率,超過了其先前基于聚類方法(8.8%)和深度網絡嵌入方法(9.9%)。
這一方法與通常聚類方法的主要區別在于研究人員使用了參數共享的循環神經網絡為所有的說話人(embeddings)建模,并通過循環神經網絡的不同狀態來識別說話人,這就能將不同的語音片段與不同的人對應起來。
具體來看,每一個人的語音都可以看做權值共享的RNN的一個實例,由于生成的實例不受限所以可以適應多個說話人的場景。將RNN在不同輸入下的狀態對應到不同的說話人即可實現通過監督學習來實現語音片段的歸并。通過完整的監督模型,可以得到語音中說話人的數量,并可以通過RNN攜帶時變的信息,這將會對在線系統的性能帶來質的提升。
這一論文的主要貢獻如下:
提出了無界間隔狀態(. Unbounded interleaved-state )RNN,一個可以通過監督學習訓練的對于時變數據分割和聚類的算法;
全監督的說話人分類系統;
數據集上誤差提升到7.6%;
提高線上任務表現。
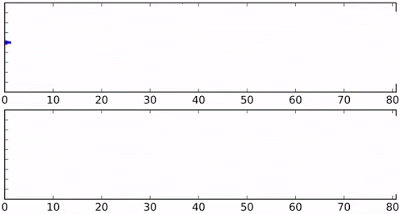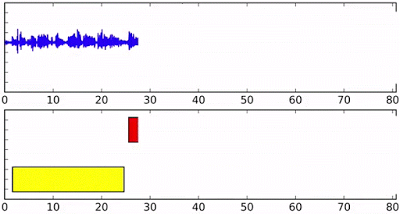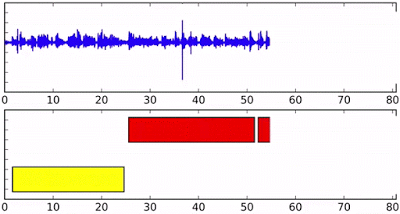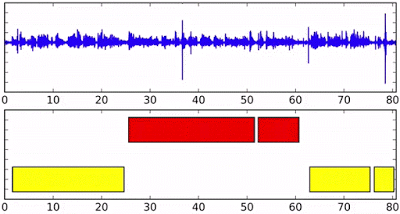
那么它具體是怎么工作的呢?假設我們有四個人同時對著這個AI說話(這是個例子,模型其實可以處理更多的人)。那么每個人將會得到一個自己的RNN實例,擁有相同的初始狀態和參數。隨著語音片段的特征不斷被送入到網絡中而更新狀態。
例如下面的藍色人在實例化后,他將一直保持RNN的狀態,直到黃色的語音片段進入并開啟新的RNN實例,這時在最頂部輸出的狀態就成為了黃色了。但后面如果藍色繼續說話,藍色RNN狀態也會相應的重新轉移到藍色上。下圖最后的虛線顯示了y7各種不同的狀態。對于新出現的綠色說話人來說,將重新開啟一個新的實例。
利用RNN對說話人語音進行表示,將能夠利用RNN參數從不同的說話人和言語中學習到高層級的知識,這對于標記豐富的數據集來說將會得到更對更好的結果。利用帶有時間戳的說話人標簽數據,可以通過隨機梯度下降法來訓練模型,可用于新的說話人,并提高在線任務的表現。
在未來研究人員將會改進這一模型用于離線解碼上下文信息的整合;同時還希望直接利用聲學特征代替d-vectors作為音頻特征,這樣就能實現完整的端到端模型了。
其實,谷歌先前的工作為這一方法打下了堅實的基礎。去年的論文“SPEAKER DIARIZATION WITH LSTM”中就提出了利用LSTM與d-vertor結合來提升模型的表現。
但這篇論文中使用的聚類算法依然是無監督的方法,這也為這次新工作的提出奠定了基礎。
除此之外,研究人員們還嘗試了利用視覺輔助的方法來識別誰在說話,并在論文“Looking to Listen at the Cocktail Party”中提出了利用視覺信息識別混合場景下說話人的方法:
相信不久后,家里的各種小可愛智能音響將可以清楚的分辨出誰是爸爸誰是媽媽,誰才是它的主人。對于嘈雜多人環境下語音指令的準確性和對話系統的交互表現有著重要的作用。同時對于音視頻分析和音頻高維語義信息的抽取學習將會有很大的促進作用。如果可以準確識別對話中每個人的對話、時長、分布,甚至可以分析出每個用戶的語言習慣、說話節奏等高級特征,與其他技術結合將能夠在行為識別、情感分析甚至語音加密等方面帶來重要的影響。
-
谷歌
+關注
關注
27文章
6161瀏覽量
105304 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100719 -
數據集
+關注
關注
4文章
1208瀏覽量
24689
原文標題:聽不清誰在講話?谷歌新模型助力分辨聲音的主人
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深非監督學習-Hierarchical clustering 層次聚類python的實現
一種聚類個數自適應的聚類方法(簡稱SKKM)

一種改進的BIRCH算法聚類方法
深度解析機器學習三類學習方法
Python無監督學習的幾種聚類算法包括K-Means聚類,分層聚類等詳細概述

利用機器學習來捕捉內部漏洞的工具運用無監督學習方法可發現入侵者
密度峰值聚類算法實現LGG的半監督學習

華裔女博士提出:Facebook提出用于超參數調整的自我監督學習框架
基于成對學習和圖像聚類的肺癌亞型識別
基于特征組分層和半監督學習的鼠標軌跡識別方法
融合零樣本學習和小樣本學習的弱監督學習方法綜述






 工商網監
工商網監
評論