") 何愷明、Ross Girshick等大神深夜扔出“炸彈”:ImageNet預(yù)訓(xùn)練并非必須
何愷明、Ross Girshick等大神深夜扔出“炸彈”:ImageNet預(yù)訓(xùn)練并非必須
何愷明、Ross Girshick等大神深夜扔出“炸彈”:ImageNet預(yù)訓(xùn)練并非必須。大神們使用隨機(jī)初始化變得到了媲美COCO冠軍的結(jié)果,無情顛覆“預(yù)訓(xùn)練+微調(diào)”思維定式——再看此前預(yù)訓(xùn)練與此后微調(diào)所付出的種種,嗚呼哀哉,好不苦矣!
ImageNet 有用嗎?
當(dāng)然有用。
但 ImageNet 預(yù)訓(xùn)練卻并非必須!
剛剛,何愷明等人在arxiv貼出一篇重磅論文,題為《重新思考“ImageNet預(yù)訓(xùn)練”》,讓似乎本已經(jīng)平靜的ImageNet湖面,再掀波瀾!
Facebook 人工智能研究所何愷明、Ross Cirshick 和 Piotr Dollar 三人在arxiv上貼出最新論文:重新思考ImageNet預(yù)訓(xùn)練
過去幾年來,使用ImageNet這套大規(guī)模數(shù)據(jù)集進(jìn)行預(yù)訓(xùn)練的視覺模型,對于執(zhí)行計算機(jī)視覺任務(wù)而言都是必不可少的存在。雖然并沒用多少時間,但人們似乎都默認(rèn),計算機(jī)視覺任務(wù)需要使用ImageNet預(yù)訓(xùn)練模型。
然而,何愷明等人卻站出來說——不!
ImageNet 預(yù)訓(xùn)練模型并非必須,ImageNet 能做的只是加速收斂,對最終物體檢測的精度或?qū)嵗指畹男阅懿o幫助。
他們使用隨機(jī)初始化的模型,不借助外部數(shù)據(jù),取得了不遜于COCO 2017冠軍的結(jié)果。
大神不愧為大神——此前我們預(yù)訓(xùn)練ImageNet模型再辛辛苦苦微調(diào),都是為了什么?!
不用ImageNet預(yù)訓(xùn)練,隨機(jī)初始化就能媲美COCO冠軍!
何愷明等人研究表明,在COCO數(shù)據(jù)集上進(jìn)行隨機(jī)初始化訓(xùn)練,其效果能做到不次于在ImageNet上進(jìn)行預(yù)訓(xùn)練。
而且,即使只用COCO中10%的訓(xùn)練數(shù)據(jù)進(jìn)行訓(xùn)練,依然有可能實(shí)現(xiàn)上述結(jié)果。
他們還發(fā)現(xiàn),可以在相當(dāng)于ImageNet規(guī)模4倍大的數(shù)據(jù)集上,使用隨機(jī)初始化訓(xùn)練,而結(jié)果不發(fā)生過擬合。

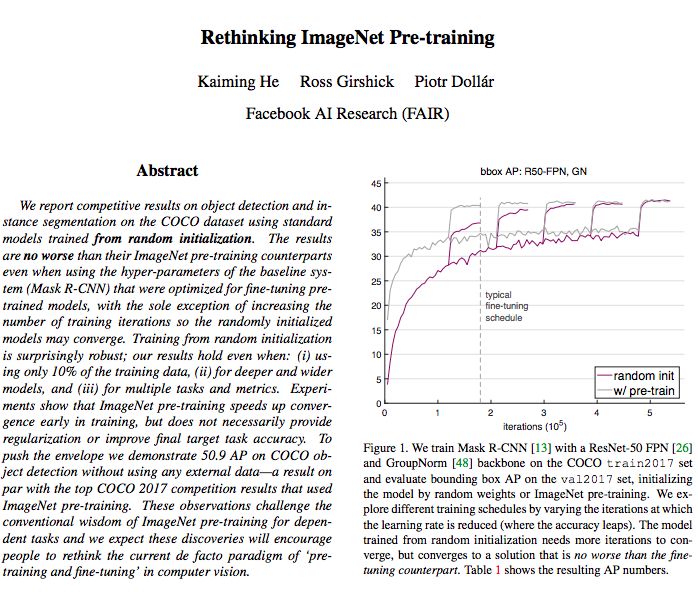
圖1:我們在COCO train2017數(shù)據(jù)集上使用ResNet-50 FPN[26]和GroupNorm[48]訓(xùn)練Mask R-CNN[13],并在val2017數(shù)據(jù)集上評估邊界框AP,通過隨機(jī)權(quán)重或ImageNet預(yù)訓(xùn)練初始化模型。我們通過改變學(xué)習(xí)率降低(準(zhǔn)確率提高)的迭代來探索不同的訓(xùn)練計劃。從隨機(jī)初始化訓(xùn)練出來的模型需要更多的迭代來收斂,但是只收斂到一個與finetuning相似的解決方案。
實(shí)驗(yàn)表明,ImageNet的預(yù)訓(xùn)練在訓(xùn)練的早期加速了收斂,但并不一定提供正則化或提高最終目標(biāo)任務(wù)的精度。
具體說,何愷明等人通過實(shí)驗(yàn)觀察到以下情況:
1、ImageNet預(yù)訓(xùn)練方式加快了收斂速度,特別是在訓(xùn)練早期,但隨機(jī)初始化訓(xùn)練可以在訓(xùn)練一段時間后趕上來。考慮到前者還要進(jìn)行模型的微調(diào),訓(xùn)練總時間二者大體相當(dāng)。由于在研究目標(biāo)任務(wù)時經(jīng)常忽略ImageNet預(yù)訓(xùn)練的成本,因此采用短期訓(xùn)練進(jìn)行的“對照”比較可能會掩蓋隨機(jī)初始化訓(xùn)練的真實(shí)表現(xiàn)。
2、ImageNet預(yù)訓(xùn)練不能自動提供性能更優(yōu)的正則化。在使用較少的圖像(不到COCO數(shù)據(jù)集的10%)進(jìn)行訓(xùn)練時,我們發(fā)現(xiàn)必須選擇新的超參數(shù)進(jìn)行微調(diào)(來自預(yù)訓(xùn)練)以避免過度擬合。當(dāng)用這些同樣的超參數(shù)進(jìn)行隨機(jī)初始化訓(xùn)練時,該模型精度可以達(dá)到預(yù)訓(xùn)練模型的水平,無需任何額外的正則化處理。
3、當(dāng)目標(biāo)任務(wù)或指標(biāo)對空間定位預(yù)測更敏感時,ImageNet預(yù)訓(xùn)練模型沒有表現(xiàn)出任何優(yōu)勢。我們觀察到,采用隨機(jī)初始化訓(xùn)練時,預(yù)測性能出現(xiàn)明顯改善。我們還發(fā)現(xiàn),采用隨機(jī)初始化訓(xùn)練的收斂速度也較預(yù)訓(xùn)練模型快。直觀地說,基于分類任務(wù)的類ImageNet的預(yù)訓(xùn)練方式,與本地化的敏感目標(biāo)任務(wù)之間的任務(wù)間存在鴻溝,這可能會限制預(yù)訓(xùn)練模型的優(yōu)勢。
有沒有ImageNet預(yù)訓(xùn)練,區(qū)別真沒那么大
作者在論文中寫道,他們的結(jié)果挑戰(zhàn)了ImageNet對依賴任務(wù)進(jìn)行預(yù)訓(xùn)練的傳統(tǒng)思想,他們的發(fā)現(xiàn)將鼓勵人們重新思考當(dāng)前計算機(jī)視覺中“預(yù)訓(xùn)練和微調(diào)”的“范式”。
那么,完全從零開始訓(xùn)練,與使用ImageNet預(yù)訓(xùn)練相比,最大的不同在哪里呢?
答案是“時間”。
使用ImageNet做預(yù)訓(xùn)練的模型已經(jīng)具備了邊緣、紋理等低級表征,而完全從零開始訓(xùn)練的模型需要迭代更久,因此需要更多的訓(xùn)練時間。
但是,從所需要的訓(xùn)練樣本的像素(而非實(shí)例數(shù))來看,隨機(jī)初始化與使用ImageNet預(yù)訓(xùn)練,兩者其實(shí)相差不太多。

圖2:在所有訓(xùn)練迭代中看到的圖像、實(shí)例和像素的總數(shù),分別表示預(yù)訓(xùn)練+微調(diào)(綠色條)vs.隨機(jī)初始化(紫色條)。我們考慮到ImageNet預(yù)訓(xùn)練需要100 epochs,fine-tuning采用2× schedule (~24 epochs over COCO),隨機(jī)初始化采用6× schedule (~72 epochs over COCO)。我們計算ImageNet實(shí)例為1 per image (COCO是~7),和ImageNet像素為224×224,COCO為800×1333。
下圖展示了另一個例子,使用隨機(jī)初始化(深紅和深綠)和ImageNet預(yù)訓(xùn)練(淺紅和淺綠),在多種情況下,兩者的結(jié)果都是可比的。
區(qū)別大嗎?
真的沒有那么大!

圖5:使用Mask R-CNN對不同系統(tǒng)進(jìn)行隨機(jī)初始化與預(yù)訓(xùn)練的比較,包括:(i)使用FPN和GN的baseline,(ii)使用訓(xùn)練時間多尺度增強(qiáng)的baseline,(iii)使用Cascade RCNN[3]和訓(xùn)練時間增強(qiáng)的baseline,以及(iv)加上測試時間多尺度增強(qiáng)的baseline。上圖:R50;下圖R101。
此論文實(shí)驗(yàn)部分寫得非常漂亮,了解詳情推薦閱讀原文(地址見文末)。
“ImageNet時代完結(jié)”,從零開始訓(xùn)練完全可行
何愷明等人在這篇論文中,探討了以下幾點(diǎn):
無需更改架構(gòu),就能對目標(biāo)任務(wù)進(jìn)行從頭開始的訓(xùn)練。
從頭開始訓(xùn)練需要更多的迭代,以充分收斂。
在許多情況下,從頭開始的訓(xùn)練并不比ImageNet預(yù)訓(xùn)練的同個模型差,甚至在只有10k COCO圖像的情況下也是如此。
ImageNet預(yù)訓(xùn)練加速了目標(biāo)任務(wù)的收斂。
ImageNet預(yù)訓(xùn)練不一定有助于減少過擬合,除非數(shù)據(jù)量真的非常小。
如果目標(biāo)任務(wù)對定位比對分類更敏感,那么ImageNet預(yù)訓(xùn)練的幫助較小。
從目前的文獻(xiàn)來看,這些結(jié)果是令人驚訝的,并對當(dāng)前凡是計算機(jī)視覺任務(wù)就先拿ImageNet來預(yù)訓(xùn)練的做法不啻一記當(dāng)頭棒喝。
這些結(jié)果表明,當(dāng)沒有足夠的目標(biāo)數(shù)據(jù)或計算資源來對目標(biāo)任務(wù)進(jìn)行訓(xùn)練時,ImageNet預(yù)訓(xùn)練方式是一種基于“歷史”的解決方法(并且可能會持續(xù)一段時間)。
現(xiàn)在看,ImageNet標(biāo)注方便、應(yīng)用廣泛,似乎是“免費(fèi)”資源,拿來用即可。
但不是的,拋開構(gòu)建ImageNet花費(fèi)了多少人力物力和時間不說,對于某些任務(wù)而言,如果目標(biāo)數(shù)據(jù)與ImageNet相差太大,用在微調(diào)ImageNet預(yù)訓(xùn)練模型上的時間和精力,還不如直接從頭開始訓(xùn)練。
這項(xiàng)工作也并非要我們徹底拋棄預(yù)訓(xùn)練模型,而是表明(至少視覺檢測任務(wù))除了用 ImageNet 預(yù)訓(xùn)練之外,還存在另一種訓(xùn)練方式,從零開始訓(xùn)練也完全可以。
這篇論文貼出來沒多久,知乎上便出現(xiàn)了討論“如何評價何愷明等 arxiv 新作 Rethinking ImageNet Pre-training?”
截止發(fā)稿前,點(diǎn)贊最高的回答來自中科院計算所博士“王晉東不在家”:
我不是排斥使用ImageNet pretrained network,我只是覺得,應(yīng)該找一些領(lǐng)域,讓ImageNet真正有用。不妨試試用這些預(yù)訓(xùn)練好的網(wǎng)絡(luò)去進(jìn)行醫(yī)學(xué)圖像分類、極端圖像(低分辨率、逆光、精細(xì)圖像、衛(wèi)星)分類,這才是ImageNet的正確價值。
不過,欣喜的是,也有一批采用了淺層網(wǎng)絡(luò),或者是加入對抗機(jī)制的淺層網(wǎng)絡(luò),在最近的頂會上有所突破。
不能一直隨大流,是時候重新思考了。
另一位計算機(jī)視覺從業(yè)者mileistone也表示:
深度學(xué)習(xí)領(lǐng)域理論發(fā)展慢于應(yīng)用,像“train from scratch”類似的common practice很多,這些common practice很多沒有理論支撐,我們也沒法判斷有沒有道理,我們只知道大家都這么用。因?yàn)榭少|(zhì)疑的地方太多了,我們很容易失去獨(dú)立思考的能力。
希望更多的“rethink”文章出來,這些文章像鯰魚一樣,持續(xù)激發(fā)深度學(xué)習(xí)領(lǐng)域的活力。
何愷明等人認(rèn)為,他們的論文和實(shí)驗(yàn)表明,隨機(jī)初始化也有可能生成媲美COCO冠軍的結(jié)果,正因如此,計算機(jī)視覺從業(yè)者才更應(yīng)該慎待預(yù)訓(xùn)練特征。
計算機(jī)視覺的通用表征,仍然值得我們?nèi)プ非蟆?/p>
-
計算機(jī)視覺
+關(guān)注
關(guān)注
8文章
1698瀏覽量
45980 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24690 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5500瀏覽量
121114
原文標(biāo)題:何愷明拋出重磅炸彈!ImageNet并非必要
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
基于不同量級預(yù)訓(xùn)練數(shù)據(jù)的RoBERTa模型分析
【大語言模型:原理與工程實(shí)踐】大語言模型的預(yù)訓(xùn)練
索尼發(fā)布新的方法,在ImageNet數(shù)據(jù)集上224秒內(nèi)成功訓(xùn)練了ResNet-50
ResNet原始結(jié)果無法復(fù)現(xiàn)?大神何愷明受到了質(zhì)疑
新的預(yù)訓(xùn)練方法——MASS!MASS預(yù)訓(xùn)練幾大優(yōu)勢!

騰訊開源首個3D醫(yī)療影像大數(shù)據(jù)預(yù)訓(xùn)練模型
華為扔出一顆重磅炸彈:華為云手機(jī),橫空出世!
小米在預(yù)訓(xùn)練模型的探索與優(yōu)化






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論