 如何看懂R中的探索性數據分析(附R代碼)
如何看懂R中的探索性數據分析(附R代碼)
探索性數據分析(EDA)是數據項目的第一步。我們將創建一個代碼模板來實現這一功能。
簡介
EDA由單變量(1個變量)和雙變量(2個變量)分析組成。在這篇文章中,我們將回顧一些我們在案例分析中使用的功能:
第1步:取得并了解數據;
第2步:分析分類變量;
第3步:分析數值變量;
第4步:同時分析數值和分類變量。
基本EDA中的一些關鍵點:
數據類型
異常值
缺失值
數值和分類變量的分布(數字和圖形的形式)
分析結果的類型
結果有兩種類型:信息型或操作型。
信息型:例如繪圖或任何長變量概要,我們無法從中過濾數據,但它會立即為我們提供大量信息。大多數用于EDA階段。
操作型:這類結果可直接用于數據工作流(例如,選擇缺失比例低于20%的變量)。最常用于數據準備階段。
準備開始
如果您沒有這些擴展包,請刪除‘#’來導入:
# install.packages("tidyverse")
# install.packages("funModeling")
# install.packages("Hmisc")
funModeling已發布更新版本的Ago-1,請更新!
現在加載所需的程序包
library(funModeling)
library(tidyverse)
library(Hmisc)
tl; dr(代碼)
使用以下函數一鍵運行本文中的所有函數:
basic_eda <- function(data)
{
glimpse(data)
df_status(data)
freq(data)
profiling_num(data)
plot_num(data)
describe(data)
}
替換data為您的數據,然后就可以啦!
basic_eda(my_amazing_data)
創建示例數據:
使用heart_disease數據(來自funModeling包)。為了使本文容易理解,我們只選取四個變量。
data=heart_disease %>% select(age, max_heart_rate, thal, has_heart_disease)
第一步:了解數據
統計第一個例子中觀測(行)和變量的數量,并使用head顯示數據的前幾行。
glimpse(data)
## Observations: 303
## Variables: 4
## $ age
## $ max_heart_rate
## $ thal
## $ has_heart_disease
獲取有關數據類型,零值,無窮數和缺失值的統計信息:
df_status(data)
## variable q_zeros p_zeros q_na p_na q_inf p_inf type unique
## 1 age 0 0 0 0.00 0 0 integer 41
## 2 max_heart_rate 0 0 0 0.00 0 0 integer 91
## 3 thal 0 0 2 0.66 0 0 factor 3
## 4 has_heart_disease 0 0 0 0.00 0 0 factor 2
df_status會返回一個表格,因此很容易篩選出符合某些條件的變量,例如:
有至少80%的非空值(p_na < 20)
有少于50個唯一值(unique <= 50)
建議:
所有變量都是正確的數據類型嗎?
有含有很多零或空值的變量嗎?
有高基數變量嗎?
更多相關信息請瀏覽:
https://livebook.datascienceheroes.com/exploratory-data-analysis.html
第二步:分析分類變量
freq函數自動統計數據集中所有因子或字符變量:
freq(data)
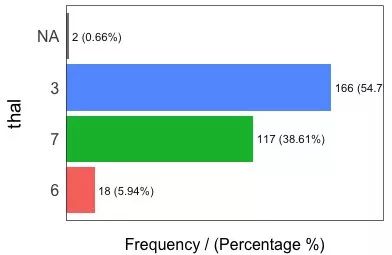
## thal frequency percentage cumulative_perc
## 1 3 166 54.79 55
## 2 7 117 38.61 93
## 3 6 18 5.94 99
## 4
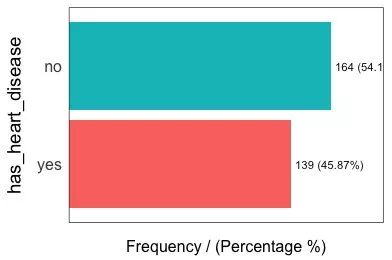
## has_heart_disease frequency percentage cumulative_perc
## 1 no 164 54 54
## 2 yes 139 46 100
## [1] "Variables processed: thal, has_heart_disease"
建議:
如果freq用于一個變量-freq(data$variable),它會生成一個表格。這對于處理高基數變量(如郵政編碼)非常有用。
將圖表以jpeg格式保存到當前目錄中:
freq(data, path_out = ".")
分類變量的所有類別都有意義嗎?
有很多缺失值嗎?
經常檢查絕對值和相對值。
第三步:分析數值變量
我們將看到:plot_num和profiling_num兩個函數,它們都自動統計數據集中所有數值/整數變量:
1. 繪制圖表
plot_num(data)
將圖表導出為jpeg格式:
plot_num(data, path_out = ".")
建議:
試著找出極度偏態分布的變量。
作圖檢查任何有異常值的變量。
更多相關信息請瀏覽:
https://livebook.datascienceheroes.com/exploratory-data-analysis.html
2. 定量分析
profiling_num自動統計所有數值型/整型變量:
data_prof = profiling_num(data)
## variable mean std_dev variation_coef p_01 p_05 p_25 p_50 p_75 p_95
## 1 age 54 9 0.17 35 40 48 56 61 68
## 2 max_heart_rate 150 23 0.15 95 108 134 153 166 182
## p_99 skewness kurtosis iqr range_98 range_80
## 1 71 -0.21 2.5 13 [35, 71] [42, 66]
## 2 192 -0.53 2.9 32 [95.02, 191.96] [116, 176.6]
建議:
嘗試根據其分布描述每個變量(對報告分析結果也很有用)。
注意標準差很大的變量。
選擇您最熟悉的統計指標:data_prof %>% select(variable, variation_coef, range_98):variation_coef得到較大值可能提示異常值。range_98顯示絕大部分數值的范圍。
第四步:同時分析數值和分類變量
使用Hmisc包的describe。
library(Hmisc)
describe(data)
## data
##
## 4 Variables 303 Observations
## ---------------------------------------------------------------------------
## age
## n missing distinct Info Mean Gmd .05 .10
## 303 0 41 0.999 54.44 10.3 40 42
## .25 .50 .75 .90 .95
## 48 56 61 66 68
##
## lowest : 29 34 35 37 38, highest: 70 71 74 76 77
## ---------------------------------------------------------------------------
## max_heart_rate
## n missing distinct Info Mean Gmd .05 .10
## 303 0 91 1 149.6 25.73 108.1 116.0
## .25 .50 .75 .90 .95
## 133.5 153.0 166.0 176.6 181.9
##
## lowest : 71 88 90 95 96, highest: 190 192 194 195 202
## ---------------------------------------------------------------------------
## thal
## n missing distinct
## 301 2 3
##
## Value 3 6 7
## Frequency 166 18 117
## Proportion 0.55 0.06 0.39
## ---------------------------------------------------------------------------
## has_heart_disease
## n missing distinct
## 303 0 2
##
## Value no yes
## Frequency 164 139
## Proportion 0.54 0.46
## ---------------------------------------------------------------------------
這對于快速了解所有變量非常有用。但是當我們想要使用統計結果來改變我們的數據工作流時,這個函數不如freq和profiling_num好用。
建議:
檢查最小值和最大值(異常值)。
檢查分布(與之前相同)。
更多相關信息請瀏覽:
https://livebook.datascienceheroes.com/exploratory-data-analysis.html
推薦閱讀
(點擊標題可跳轉閱讀)
數據科學家需要知道的 5 個基本統計學概念
2 種數據科學編程中的思維模式,了解一下
數據科學領域,你該選 Python 還是 R ?
-
eda
+關注
關注
71文章
2755瀏覽量
173201 -
代碼
+關注
關注
30文章
4779瀏覽量
68525 -
數據分析
+關注
關注
2文章
1445瀏覽量
34050
原文標題:一文讀懂 R 中的探索性數據分析
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據分析需要的技能
怎么有效學習Python數據分析?
什么是探索性測試ET
探索性數據分析(EDA)及其應用

設計多網絡協議的Python網絡編程的探索性指南
探索性大數據分析系統對基因組醫學研究的幫助

細分模型探索性數據分析和預處理


Sweetviz讓你三行代碼實現探索性數據分析
Sweetviz: 讓你三行代碼實現探索性數據分析





 工商網監
工商網監
評論