 分析3種分布式鎖的設計與實現
分析3種分布式鎖的設計與實現
多線程情況下對共享資源的操作需要加鎖,避免數據被寫亂,在分布式系統中,這個問題也是存在的,此時就需要一個分布式鎖服務。常見的分布式鎖實現一般是基于DB、Redis、zookeeper。下面筆者會按照順序分析下這3種分布式鎖的設計與實現,想直接看分布式鎖總結的小伙伴可直接翻到文檔末尾處。
分布式鎖的實現由多種方式,但是不管怎樣,分布式鎖一般要有以下特點:
排他性:任意時刻,只能有一個client能獲取到鎖
容錯性:分布式鎖服務一般要滿足AP,也就是說,只要分布式鎖服務集群節點大部分存活,client就可以進行加鎖解鎖操作
避免死鎖:分布式鎖一定能得到釋放,即使client在釋放之前崩潰或者網絡不可達
除了以上特點之外,分布式鎖最好也能滿足可重入、高性能、阻塞鎖特性(AQS這種,能夠及時從阻塞狀態喚醒)等,下面就話不多說,趕緊上(開往分布式鎖的設計與實現的)車~
DB鎖
在數據庫新建一張表用于控制并發控制,表結構可以如下所示:
CREATETABLE`lock_table`(`id`int(11)unsignedNOTNULLCOMMENT'主鍵',`key_id`bigint(20)NOTNULLCOMMENT'分布式key',`memo`varchar(43)NOTNULLDEFAULT''COMMENT'可記錄操作內容',`update_time`datetimeNOTNULLCOMMENT'更新時間',PRIMARYKEY(`id`,`key_id`),UNIQUEKEY`key_id`(`key_id`)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8;
key_id作為分布式key用來并發控制,memo可用來記錄一些操作內容(比如memo可用來支持重入特性,標記下當前加鎖的client和加鎖次數)。將key_id設置為唯一索引,保證了針對同一個key_id只有一個加鎖(數據插入)能成功。此時lock和unlock偽代碼如下:
deflock:execsql:insertintolock_table(key_id,memo,update_time)values(key_id,memo,NOW())ifresult==true:returntrueelse:returnfalsedefunlock:execsql:deletefromlock_tablewherekey_id='key_id'andmemo='memo'
注意,偽代碼中的lock操作是非阻塞鎖,也就是tryLock,如果想實現阻塞(或者阻塞超時)加鎖,只修反復執行lock偽代碼直到加鎖成功為止即可。基于DB的分布式鎖其實有一個問題,那就是如果加鎖成功后,client端宕機或者由于網絡原因導致沒有解鎖,那么其他client就無法對該key_id進行加鎖并且無法釋放了。為了能夠讓鎖失效,需要在應用層加上定時任務,去刪除過期還未解鎖的記錄,比如刪除2分鐘前未解鎖的偽代碼如下:
defclear_timeout_lock:execsql:deletefromlock_tablewhereupdate_time
因為單實例DB的TPS一般為幾百,所以基于DB的分布式性能上限一般也是1k以下,一般在并發量不大的場景下該分布式鎖是滿足需求的,不會出現性能問題。不過DB作為分布式鎖服務需要考慮單點問題,對于分布式系統來說是不允許出現單點的,一般通過數據庫的同步復制,以及使用vip切換Master就能解決這個問題。
以上DB分布式鎖是通過insert來實現的,如果加鎖的數據已經在數據庫中存在,那么用select xxx where key_id = xxx for udpate方式來做也是可以的。
Redis鎖
Redis鎖是通過以下命令對資源進行加鎖:
setkey_idkey_valueNXPXexpireTime
其中,set nx命令只會在key不存在時給key進行賦值,px用來設置key過期時間,key_value一般是隨機值,用來保證釋放鎖的安全性(釋放時會判斷是否是之前設置過的隨機值,只有是才釋放鎖)。由于資源設置了過期時間,一定時間后鎖會自動釋放。
set nx保證并發加鎖時只有一個client能設置成功(Redis內部是單線程,并且數據存在內存中,也就是說redis內部執行命令是不會有多線程同步問題的),此時的lock/unlock偽代碼如下:
deflock:if(redis.call('set',KEYS[1],ARGV[1],'ex',ARGV[2],'nx'))thenreturntrueendreturnfalsedefunlock:if(redis.call('get',KEYS[1])==ARGV[1])thenredis.call('del',KEYS[1])returntrueendreturnfalse
分布式鎖服務中的一個問題
如果一個獲取到鎖的client因為某種原因導致沒能及時釋放鎖,并且redis因為超時釋放了鎖,另外一個client獲取到了鎖,此時情況如下圖所示:
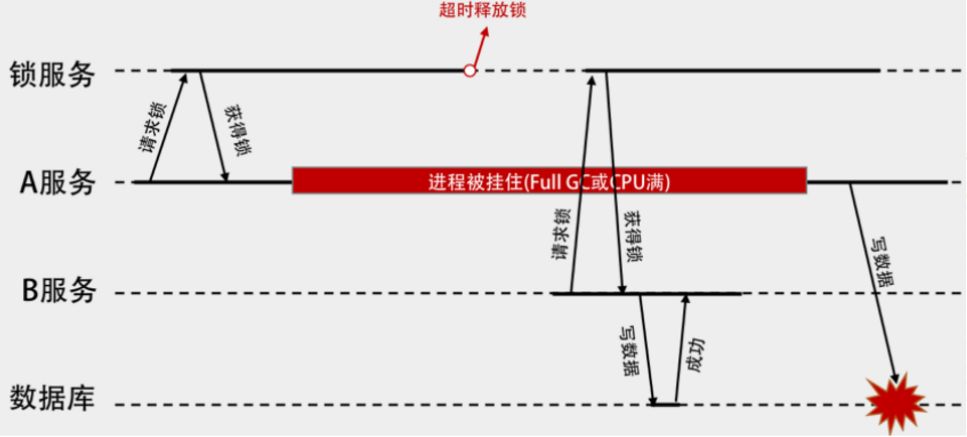
那么如何解決這個問題呢,一種方案是引入鎖續約機制,也就是獲取鎖之后,釋放鎖之前,會定時進行鎖續約,比如以鎖超時時間的1/3為間隔周期進行鎖續約。
關于開源的redis的分布式鎖實現有很多,比較出名的有redisson、百度的dlock,關于分布式鎖,筆者也寫了一個簡易版的分布式鎖redis-lock,主要是增加了鎖續約和可同時針對多個key加鎖的機制。
對于高可用性,一般可以通過集群或者master-slave來解決,redis鎖優勢是性能出色,劣勢就是由于數據在內存中,一旦緩存服務宕機,鎖數據就丟失了。像redis自帶復制功能,可以對數據可靠性有一定的保證,但是由于復制也是異步完成的,因此依然可能出現master節點寫入鎖數據而未同步到slave節點的時候宕機,鎖數據丟失問題。
zookeeper分布式鎖
ZooKeeper是一個高可用的分布式協調服務,由雅虎創建,是Google Chubby的開源實現。ZooKeeper提供了一項基本的服務:分布式鎖服務。zookeeper重要的3個特征是:zab協議、node存儲模型和watcher機制。通過zab協議保證數據一致性,zookeeper集群部署保證可用性,node存儲在內存中,提高了數據操作性能,使用watcher機制,實現了通知機制(比如加鎖成功的client釋放鎖時可以通知到其他client)。
zookeeper node模型支持臨時節點特性,即client寫入的數據時臨時數據,當客戶端宕機時臨時數據會被刪除,這樣就不需要給鎖增加超時釋放機制了。當針對同一個path并發多個創建請求時,只有一個client能創建成功,這個特性用來實現分布式鎖。注意:如果client端沒有宕機,由于網絡原因導致zookeeper服務與client心跳失敗,那么zookeeper也會把臨時數據給刪除掉的,這時如果client還在操作共享數據,是有一定風險的。
基于zookeeper實現分布式鎖,相對于基于redis和DB的實現來說,使用上更容易,效率與穩定性較好。curator封裝了對zookeeper的api操作,同時也封裝了一些高級特性,如:Cache事件監聽、選舉、分布式鎖、分布式計數器、分布式Barrier等,使用curator進行分布式加鎖示例如下:
總結
從上面介紹的3種分布式鎖的設計與實現中,我們可以看出每種實現都有各自的特點,針對潛在的問題有不同的解決方案,歸納如下:
性能:redis > zookeeper > db。
避免死鎖:DB通過應用層設置定時任務來刪除過期還未釋放的鎖,redis通過設置超時時間來解決,而zookeeper是通過臨時節點來解決。
可用性:DB可通過數據庫同步復制,vip切換master來解決,redis可通過集群或者master-slave方式來解決,zookeeper本身自己是通過zab協議集群部署來解決的。注意,DB和redis的復制一般都是異步的,也就是說某些時刻分布式鎖發生故障可能存在數據不一致問題,而zookeeper本身通過zab協議保證集群內(至少n/2+1個)節點數據一致性。
鎖喚醒:DB和redis分布式鎖一般不支持喚醒機制(也可以通過應用層自己做輪詢檢測鎖是否空閑,空閑就喚醒內部加鎖線程),zookeeper可通過本身的watcher/notify機制來做。
使用分布式鎖,安全性上和多線程(同一個進程內)加鎖是沒法比的,可能由于網絡原因,分布式鎖服務(因為超時或者認為client掛了)將加鎖資源給刪除了,如果client端繼續操作共享資源,此時是有隱患的。因此,對于分布式鎖,一個是盡量提高分布式鎖服務的可用性,另一個就是要部署同一內網,盡量降低網絡問題發生幾率。這樣來看,貌似分布式鎖服務不是“完美”的(PS:技術貌似也不好做到十全十美 :( ),那么開發人員該如何選擇分布式鎖呢?最好是結合自己的業務實際場景,來選擇不同的分布式鎖實現,一般來說,基于redis的分布式鎖服務應用較多。
-
數據庫
+關注
關注
7文章
3798瀏覽量
64370 -
多線程
+關注
關注
0文章
278瀏覽量
19947
原文標題:一文弄懂“分布式鎖”
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
深入理解redis分布式鎖
什么是分布式鎖 Redis的五種分布式鎖方案





 工商網監
工商網監
評論