 AI領域的研究論文是否應該公開代碼?
AI領域的研究論文是否應該公開代碼?
九月底,一篇CVPR論文由于“無法復現一致的結果”引發質疑,被要求撤稿。論文一作是CMU博士、來自中國的徐覺非同學,今天,他發表了詳細分析和回應,并談及他對公開代碼、開放研究的看法。
AI領域的研究論文是否應該公開代碼?這是一個長期以來爭議不休的話題。
多數人認為,科學研究應該可以讓其他研究人員在相同的條件下重現其結果。
在AI領域,事情更加明顯:如果我們想要信任AI,就必須能夠復現它。
而對于機器學習的研究來說,由于各種超參數對結果影響很大,并且論文里不太可能把所有實現的細節都說清楚,公布代碼就成了保證復現的重要途徑。
但是,如果代碼開源了,復現論文的時候卻發現結果和論文差異太大,怎么辦?
這里有一個教科書般的案例。如果你對是否應該為了復現實驗結果而開源代碼有爭議,非常值得一讀。
事情是這樣的:
9月底,Reddit上一篇帖子對CVPR 2018的一篇題為“Perturbative Neural Networks”的論文提出了質疑。質疑者名為Michael Klachko(以下簡稱MK),Reddit ID為p1esk,他表示,自己試圖按照論文中的模型和方法重現實驗結果,結果并沒有達到文中聲稱的準確率。MK認為,原文中的計算存在錯誤,并直截了當地表示,這篇文章也許應該被撤稿。
由于CVPR在AI研究領域的地位,此貼一發,頓時引發眾多網友熱議。
這篇論文來自CMU的Felix Juefei-Xu和Marios Savvides,以及密歇根州立大學的 Vishnu Naresh Boddeti三人。
其中,第一作者Felix Juefei-Xu(徐覺非)來自中國,本科畢業于上海交通大學電子工程專業,在CMU獲得電子與計算機工程碩士和博士學位。在CMU讀博期間,徐覺非師從Marios Savvides教授,在CMU CyLab生物特征識別中心研究模式識別、機器學習、計算機視覺和圖像處理等領域,特別是這些領域在生物識別中的應用。
徐覺非的主頁
徐覺非當時表示,他們將徹底分析問題,并且得到 100% 確定的結果之后再給出進一步的回復。 他說:“我們正在重新運行所有的實驗。如果分析表明我們的結果確實跟提交 CVPR 的版本中相差很多,會撤回這篇論文。”
現在,結果來了。在介紹徐覺非的詳細回復之前,讓我們先簡要看看這篇論文的主要內容和爭議的焦點。
復現結果不一致,CVPR論文引撤稿爭議
從這篇論文的內容來看,作者提出了一個簡單有效的模塊,名為“干擾層”(perturbation layer),作為卷積層的替代。干擾層不使用傳統意義上的卷積,而是將其響應計算為一個線性加權和,由增加的噪音干擾輸入的非線性激活組成。作者表明,由這些“干擾層”組成的干擾神經網絡(PNN)的性能和CNN一樣好。
而提出撤稿質疑的MK則表示,使用3X3卷積換成1X1再在輸入中增加一些干擾,實際上并沒有什么意義。他的測試結果是這樣的:
在關于學術論文的討論中,被人質疑是否應該撤稿,可以說是非常直接的指控了。此貼一經發出,立即引發了網友關于“是否應該撤稿”的討論。
當時,網友的觀點大致分為以下幾類:
1、不用撤,既然作者都把代碼公開了,顯然是無心之過,只要將錯誤改過來就好了。
2、 撤!有錯誤當然撤,不僅如此,以后還應該規定所有論文提交時都必須公開代碼,不僅論文要評審,連代碼也要一并審核。
3、先把撤稿的事放在一邊:雙盲評審過程本身并不涉及代碼的審核,就好像生物學領域的論文不會在審稿期間去重復實驗,也無法做到一一核查代碼,原本就是論文發表后,由其他同行來復現,由此判斷其結論是否經得起科學論證。
時隔兩個月,作者再發詳細澄清帖,獲網友一邊倒支持
合理歸合理,但說到底,此事終究懸而未決。近兩個月過去,11月25日,此文第一作者Felix Juefei-Xu(ID:katanaxu)在Reddit上再次發帖更新情況,詳細說明了質疑者MK的實現方法和原文中方法的差異,并表示,這些差異是造成精度下降的主要原因。
徐覺非表示,經比較,MK的實現方式與原論文中的實現方式并不一致,主要體現在六個方面,分別為:
優化方法、添加的噪音水平、學習率、學習率schedule、Conv-BN-ReLU module ordering、以及對Dropout的使用。
此次徐同學的回應要比9月份那次具體得多,并在自己的Github上貼出了詳細的比較結果。與兩個月前網友輿論基本勢均力敵相比,此次網友基本對原作者表示了一邊倒的支持。
比如,一位id為“nnatlab”在引用了作者的澄清內容后,對質疑者MK表示,在正式發表質疑言論之前,應該反復確認實現方式。作者列出的都是導致結果不一致的重要因素。這種情況下直接發出“應該撤稿”的質疑顯然不夠成熟,也不夠專業。
也有網友認為,在事情還未定論的情況下就拋出“撤稿”這樣刺眼的字眼顯然不合適。科學研究需要時間和精力,對研究成果提出質疑,也應該給予研究者充分的回應時間。
絕大部分網友認為作者的此次回應有理有力,甚至有人表示,“可以祝賀原作者了”。
質疑者“MK”再現身:現在下結論仍為時尚早
凡事有來必有往。兩個月前發出質疑帖子的MK在本帖現身回復,他在回復中對自己和作者的溝通情況作了簡要說明,表示自己現在正忙著準備12月的另一篇論文,等忙完了將再次對PNN進行測試。在回復中,MK對自己的兩個月前的質疑作出了四點澄清:
1.我在原貼中發布的PNN準確率下降了5%的結果,其資源來自作者給出的資源庫,所有原始超參數都未經修改。我只改變了測試精度的量度。
2、我真的很愿意相信,原作者找到了神奇的解決辦法,因為這樣我就可以證明能夠以這個方法進行硬件實現(并發表一篇論文)。但是:
3、在有人(我自己或第三方)成功運行新代碼,并確認主要結果之前(即PNN可以獲得與CNN相當的表現)之前,對原作者表示祝賀還為時尚早。我建議這個論壇的人自己去做這個比較。不必像我一樣重新實現,只需驗證一切都可以按照論文中的步驟順利完成就行。
4、如果PNN確實像此文聲稱的那樣強大,這可是件大事。目前,卷積神經網絡(CNN)是深度學習的核心,如果我們真的不再需要使用sliding shared filters從輸入中提取出模式,那么此文作者就發現了一些非常有趣的東西,并找到了處理信息的開創性的新方式。這個發現可能與Hinton的膠囊網絡一樣新穎和重要。
看得出,面對原作者的詳細說明和網友的輿論壓力,MK仍然在堅持自己的觀點。
論文一作的詳細回應
第1節:Michael Klachko的實現設置不一致
根據我們的分析,所謂的性能下降(~5%)主要是由于Michael Klachko(以下簡稱MK)在PNN的實現中存在各種不一致和次優的超參數選擇。
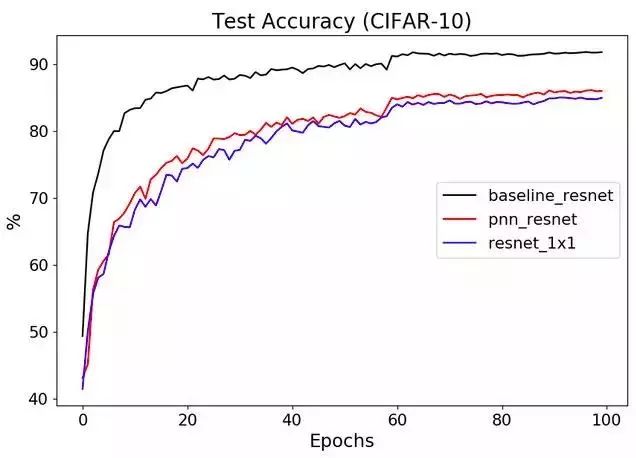
在次優的設置和超參數選擇下,MK的實現在CIFAR-10上的結果是~85-86%,性能下降了5%,如下面的repo快照所示。
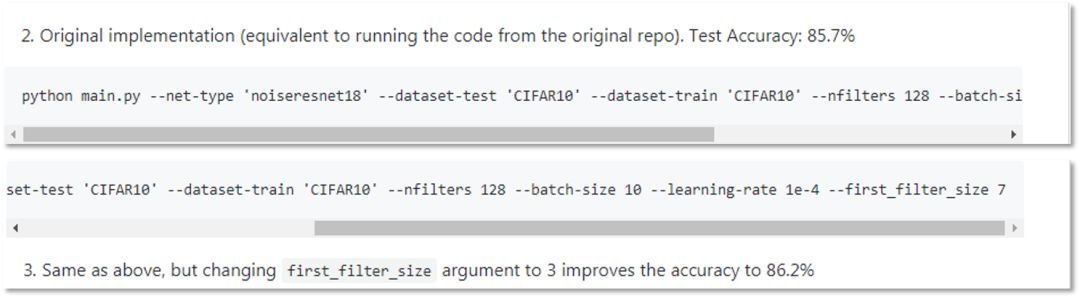
將MK的實現與我們的進行比較,可以發現以下不一致之處:
優化方法不同:MK采用SGD,我們采用Adam。
附加噪聲水平不同:MK使用0.5,我們使用0.1。
學習率不同:MK使用的學習率是1e-3,我們使用1e-4。
learning rate scheduling不同(見文末鏈接)。
Conv-BN-ReLU模塊順序不同見文末鏈接)。
dropout的使用不同:MK使用0.5,我們使用None。
如下圖所示,存在諸多不一致。MK的實現是左邊,我們的是右邊。

基于我們有限的試驗次數,我們發現在這些不一致性中,前兩個(優化方法和噪聲水平)對PNN的性能影響最大。優化方法的選擇確實非常重要,在小規模的實驗中,每一種優化方法(SGD、Adam、RMSProp等)的遍歷方式都有很大的不同。添加噪聲水平的選擇也非常重要,我們將在第3節中再次討論。
那么,讓我們看看PNN在正確地設置超參數后是如何執行的。保持相同數量的噪聲掩碼(——nfilters 128),我們可以達到90.35%的準確率,而MK在他的repo中報告的準確率只有85-86%。
python main.py --net-type 'noiseresnet18' --dataset-test 'CIFAR10' --dataset-train 'CIFAR10' --nfilters 128 --batch-size 10 --learning-rate 1e-4 --first_filter_size 3 --level 0.1 --optim-method Adam --nepochs 450
第2節:關于CVPR論文結果
目前,對CVPR實驗的重新評估已經基本完成。有一小部分實驗受到平滑函數中錯誤的默認標志的影響。對于那些受影響的,性能會有小幅下降,可以通過增加網絡參數來補償。我們將在PNN論文的arxiv版本中更新結果。
第3節:所有層中的Uniform Additive Noise
接下來要討論的內容,我們在CVPR論文中并沒有涉及,而是打算在PNN的后續工作中進一步探討。其中一個主題是在所有層應用擾動噪聲(perturbative noise),包括第一層。
在CVPR論文中,我們在第一層使用3x3或7x7空間卷積作為特征提取,所有后續層使用擾動噪聲模塊。由于MK已經嘗試并實現了PNN的all-layer perturbative noise版本,我們認為提供我們的見解也有幫助。
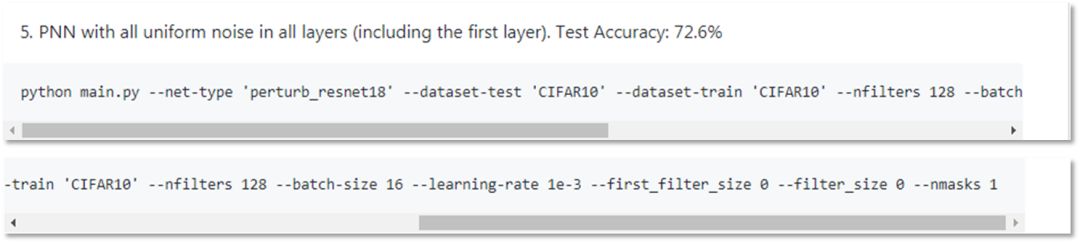
根據MK的repo(如下圖所示),所有層(包括第一層)均勻噪聲的PNN在CIFAR-10上的準確率為72.6%。在這里,我們提供了一個簡單的解決方案(與MK的實現沒有太大變化),可以達到~85-86%的準確率。不過,這仍然是許多正在進行的關于PNN的研究課題之一,我們將在后續的工作中進一步報告結果。
我們從class PerturbLayerFirst(n.module)中創建了一個名為class PerturbLayerFirst(n.module)的重復類,以便將第一層噪聲模塊與其他層的噪聲模塊區別開來。大部分修改發生在class PerturbLayerFirst(nn.Module)和class PerturbResNet(nn.Module)中。
修改的主要想法是:
我們需要更多noise masks。使用3個高度相關(RGB通道)的基本圖像來創建128或256個噪聲擾動響應映射是遠遠不夠的。
噪聲水平的選擇是次優的,需要針對第一層進行放大。在MK的實現中,第一層輸入和后續層的歸一化是不同的,動態范圍也有很大的不同。
因此,經過修改后,具有全層噪聲擾動模塊的PNN準確率可以達到85.92%,而MK在repo中報告的準確率為72.6%。
python main.py --net-type 'perturb_resnet18' --dataset-test 'CIFAR10' --dataset-train 'CIFAR10' --nfilters 256 --batch-size 20 --learning-rate 1e-4 --first_filter_size 0 --filter_size 0 --nmasks 1 --level 0.1 --optim-method Adam --nepochs 450
第4節:為什么PNN有意義?
在攻讀博士學位的最后一年,我投入了一些探索深度學習新方法的研究工作,這些方法在統計學上是有效的,同時也具有穩健性。這一系列研究始于我們在CVPR 2017發表的Local Binary Convolutional Neural Networks (LBCNN)論文。在LBCNN論文中,我們試圖回答這個問題:我們真的需要可學習的空間卷積嗎?事實證明,并不需要。使用 binary或Gaussian filters + learnable channel pooling的Non-learnable隨機卷積也可以。接著,下一個自然而來的問題是:我們真的需要空間卷積嗎?也許另一種特征提取技術(例如additive noise)+ learnable channel pooling也能起到同樣的作用?這就是PNN論文試圖闡明的問題。
learnable channel pooling和non-learnable convolutional filters兩者的混合讓我們得以重新思考卷積濾波器在深度CNN模型中的作用。通過各種視覺分類任務,我發現了LBCNN和CNN之間具有可比性。
基于這些觀察,一種自然而然的方法就是完全取代隨機卷積運算。在每個local patch中,由于它是一個線性操作,涉及中心像素的鄰域和一組通過點積創建標量輸出的隨機濾波器權重,該標量輸出攜帶局部信息,即,將中心像素映射到響應圖中相應的輸出像素。那么,可以替代的最簡單的線性操作就是添加隨機噪聲(additive random noise)。
這就是PNN的動機所在,我在其中介紹了一個非常簡單但有效的模塊,稱為擾動層(perturbation layer),作為卷積層的替代。
我們在LBCNN工作中的經驗表明,通過隨機卷積的隨機特征提取和深度神經網絡中的learnable channel pooling結合,可以學習有效的圖像特征。PNN中的加性隨機噪聲是一種最簡單的隨機特征提取方法。
第5節:結語
當我寫完這篇文章時,我不禁回想起過去兩個月的經歷。我不得不承認,當MK決定在Reddit上公開質疑時,我有點震驚,尤其是我已經答應會調查這個問題了。一周之內,這篇文章引起了中國多家主流科技/人工智能媒體的關注。這個帖子在中國社交媒體上被分享,包括討論這一問題的報道文章,點擊量超過了100萬。有些文章和評論很苛刻,但有些是合理和公正的。雖然我很堅強,但不能說我沒有受到壓力。
但我開始意識到一件事情:作為一名研究人員,面對公眾的審視不是一種選擇,而是一種責任。為此,我真的要感謝Michael,他不僅花費了時間和精力來重新創建和驗證一個已發布的方法,更重要的是,在發現結果不匹配時說出來。我堅信,正是通過這些努力,我們整個研究社區才能取得真正的進展。
此外,我想對剛剛進入AI領域的年輕研究人員或即將進入AI領域的大學生(以及高中生!)說幾句話。這樣的事情確實會發生,但是你永遠不應對開放源代碼或進行開放研究感到氣餒。這是AI領域發展如此迅速的核心原因。我在最近回國的旅途中,遇到了一位高三學生,他非常熱情的和我討論了Batch Normalization和Group Normalization的實施細節。我真的很驚訝。對于所有年輕的AI研究人員和從業人員,我真誠地鼓勵你們打破常規思考,不要停留在教條上,探索尚未被探索的東西,走少有人走的路,最重要的是,做開放的研究,分享你們的代碼和發現。這樣,你就是在幫助社區向前發展,即使每次只前進一英寸。
所以,讓我們繼續探索、研究和分享。
-
AI
+關注
關注
87文章
31079瀏覽量
269413 -
代碼
+關注
關注
30文章
4799瀏覽量
68728 -
機器學習
+關注
關注
66文章
8424瀏覽量
132761
原文標題:CVPR 18論文“無法重現”?中國作者再度澄清獲網友一邊倒支持
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
RISC-V在AI領域的發展前景怎么樣?
AI大模型的最新研究進展

AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
生成式AI在學術領域的應用亟需高度重視
在NodeMCU上公開強制休眠API,無法讓定時light_sleep工作怎么解決?
探討AI編寫代碼技術,以及提高代碼質量的關鍵:靜態代碼分析工具Perforce Helix QAC & Klocwork
助力科學發展,NVIDIA AI加速HPC研究






 工商網監
工商網監
評論