


編者按:談到加速模型訓練,并行計算現在已經成為一個人人可以信手拈來的術語和技巧——通過把單線程轉為多線程同時進行,我們可以把訓練用時從一禮拜縮短到幾天甚至幾小時。但無論你有沒有嘗試過并行訓練,你是否思考過這樣一些問題:模型訓練是否存在一個閾值,當batch size變化到一定程度后,訓練所用的步數將不再減少;對于不同模型,這個閾值是否存在巨大差異……

摘要
近年來,硬件的不斷發展使數據并行計算成為現實,并為加速神經網絡訓練提供了解決方案。為了開發下一代加速器,最簡單的方法是增加標準minibatch神經網絡訓練算法中的batch size。在這篇論文中,我們的目標是通過實驗表征增加batch size對訓練時間的影響,其中衡量訓練時間的是到達目標樣本外錯誤時模型所需的訓練步驟數。
當batch size增加到一定程度后,模型訓練步數不再發生變化。考慮到batch size和訓練步驟之間的確切關系對從業者、研究人員和硬件設計師來說都至關重要,我們還研究了不同訓練算法、模型和數據記下這種關系的具體變化,并發現了它們之間的巨大差異。在論文最后,我們調整了以往文獻中關于batch size是否會影響模型性能的說法,并探討了論文結果對更快、更好訓練神經網絡的意義。
研究結果
通過全面定性定量的實驗,我們最終得出了以下結論:
1. 實驗表明,在測試用的六個不同的神經網絡、三種訓練算法和七個數據集下,batch size和訓練步驟之間關系都具有相同的特征形式。
具體來說,就是對于每個workload(模型、訓練算法和數據集),如果我們在剛開始的時候增加batch size,模型所需的訓練步驟數確實會按比例逐漸減少,但越到后期,步驟數的減少量就越低,直到最后不再發生變化。與之前那些對元參數做出強有力假設的工作不同,我們的實驗嚴格對照了不同網絡、不同算法和不同數據集的變化,這個結論更具普遍性。
2. 我們也發現,最大有用batch size在不同workload上都有差異,而且取決于模型、訓練算法和數據集的屬性。
相比一般SGD,具有動量的SGD(以及Nesterov動量)的最大有用batch size更大,這意味著未來大家可以研究不同算法和batch size縮放屬性之間的關系。
有些模型的最大有用batch size很大,有些則很小,而且它們的這種關系并不像以前論文中介紹的那么簡單(比如更寬的模型并不總能更好地擴展到更大的batch size)。
相比神經網絡和算法,數據集對最大有用batch size的影響較小,但它的影響方式有些復雜。
3. 我們還發現,訓練元參數的最佳值并不總是遵循和batch size的任何簡單數學關系。比如近期有一種比較流行的學習率設置方法是直接線性縮放batch size,但我們發現這種方法并不適用于所有問題,也不適用于所有batch size。
4. 最后,通過回顧先前工作中使用的實驗方案細節,我們沒有找到任何關于增加batch size必然會降低模型性能的證據,但當batch size過大時,額外的正則化確實會變得至關重要。
實驗
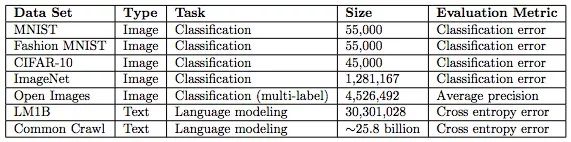
下表是實驗采用的數據集,size一欄指的是訓練集中的樣本數,訓練數據分為圖像和文本兩類。
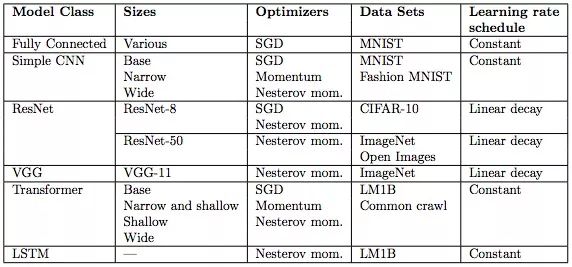
下表是實驗用的模型,它們都是從業者會在各類任務中使用的主流模型。表中也展示了我們用于每個模型和數據集的學習率。學習率的作用是加速神經網絡訓練,但找到最佳學習率本身是一個優化問題。
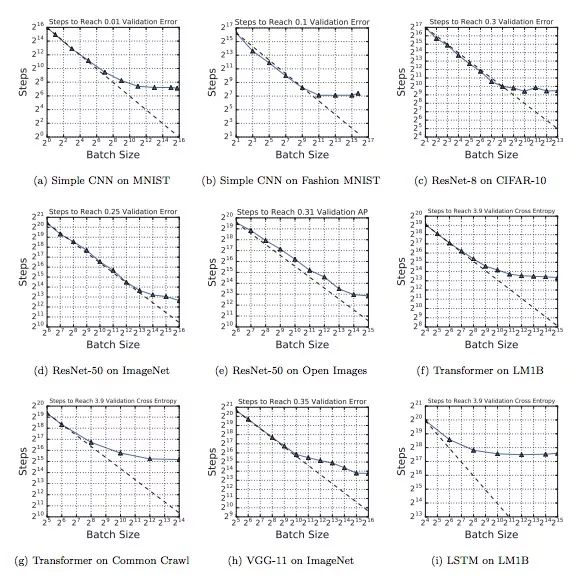
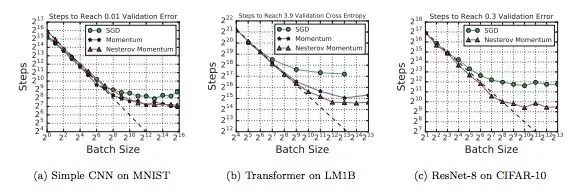
下圖展示了不同workload下batch size和訓練步驟之間關系變化。可以發現,雖然使用的神經網絡、算法和數據集不同,但這九幅圖都表現出了同樣的特征,就是在初始階段,隨著batch size逐漸增加,訓練步驟數會有一段線性遞減的區間,緊接著是一個收益遞減的區域。最后,當batch size突破最大有用batch size閾值后,訓練步數不再明顯下降,即便增加并行線程也不行。
下圖不同模型下batch size和訓練步驟之間關系變化。其中a、b、c三個模型的最大有用batch size比其他模型大得多,d和f表明改變神經網絡的深度和寬度可以影響模型利用較大batch size的能力,但這種做法只適用于同模型對比,不能推廣到不同模型架構的對比中。
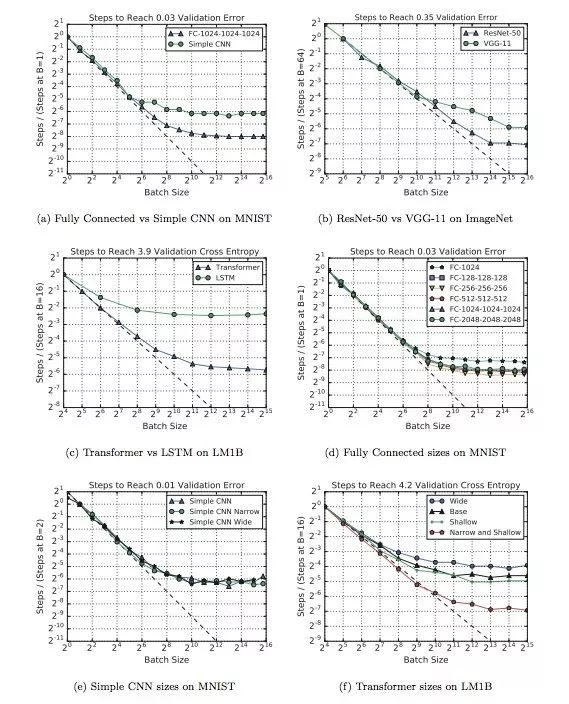
在上圖的實驗中,MNIST模型用的都是常規的mini-batch SGD,而其他模型則用了Nesterov momentum。經過比較,我們發現Nesterov在處理較大batch size上比mini-batch SGD更好一些,所以這些模型的最大可用batch size也更大。
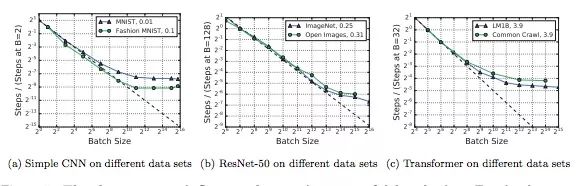
下圖顯示了不同數據集對batch size和訓練步驟之間關系的影響。如圖所示,雖然不大,但影響確實是客觀存在的,而且非常復雜。比如對于MNIST,子集大小對最大有用batch size的影響幾乎為0;但對于ImageNet,子集小一點似乎訓練起來更快。
小結
這里我們只呈現了部分實驗圖表,感興趣的讀者可以閱讀原文進行更深入的研究。總而言之,這篇論文帶給我們的啟示是,盡管增加batch size在短期來看是加速神經網絡訓練最便捷的方法,但如果我們盲目操作,即便擁有最先進的硬件條件,它在到達閾值后也不會為我們帶來額外收益。
當然,這些實驗數據也我們發掘了不少優化算法,它們可能能夠在許多模型和數據集中始終如一地加速模型訓練。
-
神經網絡
+關注
關注
42文章
4814瀏覽量
103759 -
算法
+關注
關注
23文章
4712瀏覽量
95475 -
數據集
+關注
關注
4文章
1224瀏覽量
25470
原文標題:Google:數據并行對神經網絡訓練用時的影響
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監

評論