 MySQL 基本知識點梳理和查詢優化
MySQL 基本知識點梳理和查詢優化
一、索引相關
1、索引基數:基數是數據列所包含的不同值的數量。例如,某個數據列包含值1、3、7、4、7、3,那么它的基數就是4。索引的基數相對于數據表行數較高(也就是說,列中包含很多不同的值,重復的值很少)的時候,它的工作效果最好。如果某數據列含有很多不同的年齡,索引會很快地分辨數據行。如果某個數據列用于記錄性別(只有"M"和"F"兩種值),那么索引的用處就不大。如果值出現的幾率幾乎相等,那么無論搜索哪個值都可能得到一半的數據行。在這些情況下,最好根本不要使用索引,因為查詢優化器發現某個值出現在表的數據行中的百分比很高的時候,它一般會忽略索引,進行全表掃描。慣用的百分比界線是"30%"。
2、索引失效原因:
1、對索引列運算,運算包括(+、-、*、/、!、<>、%、like'%_'(%放在前面)2、類型錯誤,如字段類型為varchar,where條件用number。3、對索引應用內部函數,這種情況下應該建立基于函數的索引如select * from template t where ROUND(t.logicdb_id) = 1此時應該建ROUND(t.logicdb_id)為索引,mysql8.0開始支持函數索引,5.7可以通過虛擬列的方式來支持,之前只能新建一個ROUND(t.logicdb_id)列然后去維護4、如果條件有or,即使其中有條件帶索引也不會使用(這也是為什么建議少使用or的原因),如果想使用or,又想索引有效,只能將or條件中的每個列加上索引5、如果列類型是字符串,那一定要在條件中數據使用引號,否則不使用索引;6、B-tree索引 is null不會走,is not null會走,位圖索引 is null,is not null 都會走7、組合索引遵循最左原則
索引的建立
1、最重要的肯定是根據業務經常查詢的語句
2、盡量選擇區分度高的列作為索引,區分度的公式是 COUNT(DISTINCT col) / COUNT(*)。表示字段不重復的比率,比率越大我們掃描的記錄數就越少
3、如果業務中唯一特性最好建立唯一鍵,一方面可以保證數據的正確性,另一方面索引的效率能大大提高
二、EXPLIAN中有用的信息
基本用法
1、desc 或者 explain 加上你的sql
2、extended explain加上你的sql,然后通過show warnings可以查看實際執行的語句,這一點也是非常有用的,很多時候不同的寫法經過sql分析之后實際執行的代碼是一樣的
提高性能的特性
1、索引覆蓋(covering index):需要查詢的數據在索引上都可以查到不需要回表 EXTRA列顯示using index
2、ICP特性(Index Condition Pushdown):本來index僅僅是data access的一種訪問模式,存數引擎通過索引回表獲取的數據會傳遞到MySQL server層進行where條件過濾,5.6版本開始當ICP打開時,如果部分where條件能使用索引的字段,MySQL server會把這部分下推到引擎層,可以利用index過濾的where條件在存儲引擎層進行數據過濾。EXTRA顯示using index condition。需要了解mysql的架構圖分為server和存儲引擎層
3、索引合并(index merge):對多個索引分別進行條件掃描,然后將它們各自的結果進行合并(intersect/union)。一般用OR會用到,如果是AND條件,考慮建立復合索引。EXPLAIN顯示的索引類型會顯示index_merge,EXTRA會顯示具體的合并算法和用到的索引
extra字段
1、using filesort:說明MySQL會對數據使用一個外部的索引排序,而不是按照表內的索引順序進行讀取。MySQL中無法利用索引完成的排序操作稱為“文件排序” ,其實不一定是文件排序,內部使用的是快排
2、using temporary:使用了臨時表保存中間結果,MySQL在對查詢結果排序時使用臨時表。常見于排序order by和分組查詢group by
3、using index:表示相應的SELECT操作中使用了覆蓋索引(Covering Index),避免訪問了表的數據行,效率不錯。
4、impossible where:WHERE子句的值總是false,不能用來獲取任何元組
5、select tables optimized away:在沒有GROUP BY子句的情況下基于索引優化MIN/MAX操作或者對于MyISAM存儲引擎優化COUNT(*)操作, 不必等到執行階段再進行計算,查詢執行計劃生成的階段即完成優化
6、distinct:優化distinct操作,在找到第一匹配的元祖后即停止找同樣值的操作
using filesort,using temporary這兩項出現時需要注意下,這兩項是十分耗費性能的,在使用group by的時候,雖然沒有使用order by,如果沒有索引,是可能同時出現using filesort,using temporary的,因為group by就是先排序在分組,如果沒有排序的需要,可以加上一個order by NULL來避免排序,這樣using filesort就會去除,能提升一點性能。
type字段
system:表只有一行記錄(等于系統表),這是const類型的特例,平時不會出現
const:如果通過索引依次就找到了,const用于比較主鍵索引或者unique索引。 因為只能匹配一行數據,所以很快。如果將主鍵置于where列表中,MySQL就能將該查詢轉換為一個常量
eq_ref:唯一性索引掃描,對于每個索引鍵,表中只有一條記錄與之匹配。常見于主鍵或唯一索引掃描
ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。本質上也是一種索引訪問,它返回所有匹配 某個單獨值的行,然而它可能會找到多個符合條件的行,所以它應該屬于查找和掃描的混合體
range:只檢索給定范圍的行,使用一個索引來選擇行。key列顯示使用了哪個索引,一般就是在你的where語句中出現between、<、>、in等的查詢,這種范圍掃描索引比全表掃描要好,因為只需要開始于縮印的某一點,而結束于另一點,不用掃描全部索引
index:Full Index Scan ,index與ALL的區別為index類型只遍歷索引樹,這通常比ALL快,因為索引文件通常比數據文件小。 (也就是說雖然ALL和index都是讀全表, 但index是從索引中讀取的,而ALL是從硬盤讀取的)
all:Full Table Scan,遍歷全表獲得匹配的行
參考地址:
https://blog.csdn.net/DrDanger/article/details/79092808
三、字段類型和編碼
1、mysql返回字符串長度:CHARACTER_LENGTH方法(CHAR_LENGTH一樣的)返回的是字符數,LENGTH函數返回的是字節數,一個漢字三個字節
2、varvhar等字段建立索引長度計算語句:select count(distinct left(test,5))/count(*) from table; 越趨近1越好
3、mysql的utf8最大是3個字節不支持emoji表情符號,必須只用utf8mb4。需要在mysql配置文件中配置客戶端字符集為utf8mb4。jdbc的連接串不支持配置characterEncoding=utf8mb4,最好的辦法是在連接池中指定初始化sql,例如:hikari連接池,其他連接池類似spring.datasource.hikari.connection-init-sql=set names utf8mb4。否則需要每次執行sql前都先執行set names utf8mb4。
4、msyql排序規則(一般使用_bin和_genera_ci):
utf8_genera_ci不區分大小寫,ci為case insensitive的縮寫,即大小寫不敏感,
utf8_general_cs區分大小寫,cs為case sensitive的縮寫,即大小寫敏感,但是目前MySQL版本中已經不支持類似于***_genera_cs的排序規則,直接使用utf8_bin替代。
utf8_bin將字符串中的每一個字符用二進制數據存儲,區分大小寫。
那么,同樣是區分大小寫,utf8_general_cs和utf8_bin有什么區別?cs為case sensitive的縮寫,即大小寫敏感;bin的意思是二進制,也就是二進制編碼比較。utf8_general_cs排序規則下,即便是區分了大小寫,但是某些西歐的字符和拉丁字符是不區分的,比如?=a,但是有時并不需要?=a,所以才有utf8_binutf8_bin的特點在于使用字符的二進制的編碼進行運算,任何不同的二進制編碼都是不同的,因此在utf8_bin排序規則下:?<>a
5、sql yog中初始連接指定編碼類型使用連接配置的初始化命令
四、SQL語句總結
常用的但容易忘的:
1、如果有主鍵或者唯一鍵沖突則不插入:insert ignore into
2、如果有主鍵或者唯一鍵沖突則更新,注意這個會影響自增的增量:INSERT INTOroom_remarks(room_id,room_remarks) VALUE(1,"sdf") ON DUPLICATE KEY UPDATE room_remarks="234"
3、如果有就用新的替代,values如果不包含自增列,自增列的值會變化:REPLACE INTOroom_remarks(room_id,room_remarks) VALUE(1,"sdf")
4、備份表:CREATE TABLE user_info SELECT * FROM user_info
5、復制表結構:CREATE TABLE user_v2 LIKE user
6、從查詢語句中導入:INSERT INTO user_v2 SELECT * FROM user或者INSERT INTO user_v2(id,num) SELECT id,num FROM user
7、連表更新:UPDATE user a, room b SET a.num=a.num+1 WHERE a.room_id=b.id
8、連表刪除:DELETE user FROM user,black WHERE user.id=black.id
鎖相關(作為了解,很少用)
1、共享鎖:select id from tb_test where id = 1 lockin share mode;
2、排它鎖:select id from tb_test where id = 1for update
優化時用到:
1、強制使用某個索引:select * from table force index(idx_user) limit 2;
2、禁止使用某個索引:select * from table ignore index(idx_user) limit 2;
3、禁用緩存(在測試時去除緩存的影響):select SQL_NO_CACHE from table limit 2;
查看狀態
1、查看字符集 SHOW VARIABLES LIKE 'character_set%';
2、查看排序規則 SHOW VARIABLES LIKE 'collation%';
SQL編寫注意
1、where語句的解析順序是從右到左,條件盡量放where不要放having
2、采用延遲關聯(deferred join)技術優化超多分頁場景,比如limit 10000,10,延遲關聯可以避免回表
3、distinct語句非常損耗性能,可以通過group by來優化
4、連表盡量不要超過三個表
五、踩坑
1、如果有自增列,truncate語句會把自增列的基數重置為0,有些場景用自增列作為業務上的id需要十分重視
2、聚合函數會自動濾空,比如a列的類型是int且全部是NULL,則SUM(a)返回的是NULL而不是0
3、mysql判斷null相等不能用“a=null”,這個結果永遠為UnKnown,where和having中,UnKnown永遠被視為false,check約束中,UnKnown就會視為true來處理。所以要用“a is null”處理
六、千萬大表在線修改
mysql在表數據量很大的時候,如果修改表結構會導致鎖表,業務請求被阻塞。mysql在5.6之后引入了在線更新,但是在某些情況下還是會鎖表,所以一般都采用pt工具( Percona Toolkit)
如對表添加索引:
如下:
pt-online-schema-change--user='root'--host='localhost'--ask-pass--alter"addindexidx_user_id(room_id,create_time)"D=fission_show_room_v2,t=room_favorite_info--execute
七、慢查詢日志
有時候如果線上請求超時,應該去關注下慢查詢日志,慢查詢的分析很簡單,先找到慢查詢日志文件的位置,然后利用mysqldumpslow去分析。查詢慢查詢日志信息可以直接通過執行sql命令查看相關變量,常用的sql如下:
--查看慢查詢配置--slow_query_log慢查詢日志是否開啟--slow_query_log_file的值是記錄的慢查詢日志到文件中--long_query_time指定了慢查詢的閾值--log_queries_not_using_indexes是否記錄所有沒有利用索引的查詢SHOWVARIABLESLIKE'%quer%';--查看慢查詢是日志還是表的形式SHOWVARIABLESLIKE'log_output'--查看慢查詢的數量
mysqldumpslow的工具十分簡單,我主要用到的是參數如下:
-t:限制輸出的行數,我一般取前十條就夠了
-s:根據什么來排序默認是平均查詢時間at,我還經常用到c查詢次數,因為查詢次數很頻繁但是時間不高也是有必要優化的,還有t查詢時間,查看那個語句特別卡。
-v:輸出詳細信息
例子:mysqldumpslow -v -s t -t 10 mysql_slow.log.2018-11-20-0500
八、查看sql進程和殺死進程
如果你執行了一個sql的操作,但是遲遲沒有返回,你可以通過查詢進程列表看看他的實際執行狀況,如果該sql十分耗時,為了避免影響線上可以用kill命令殺死進程,通過查看進程列表也能直觀的看下當前sql的執行狀態,如果當前數據庫負載很高,在進程列表可能會出現,大量的進程夯住,執行時間很長。命令如下:
--查看進程列表SHOWPROCESSLIST;--殺死某個進程kill183665
如果你使用的sqlyog,那么也有圖形化的頁面,在菜單欄-工具-顯示-進程列表。在進程列表頁面可以右鍵殺死進程。如下所示:
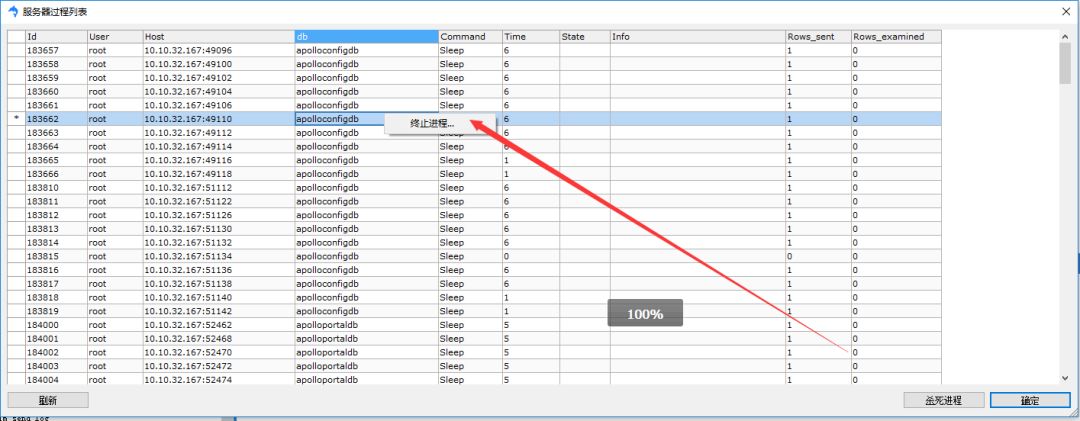
九、一些數據庫性能的思考
在對公司慢查詢日志做優化的時候,很多時候可能是忘了建索引,像這種問題很容易解決,加個索引就行了。但是有兩種情況就不是簡單能加索引能解決了:
1、業務代碼循環讀數據庫:考慮這樣一個場景,獲取用戶粉絲列表信息 加入分頁是十個 其實像這樣的sql是十分簡單的,通過連表查詢性能也很高,但是有時候,很多開發采用了取出一串id,然后循環讀每個id的信息,這樣如果id很多對數據庫的壓力是很大的,而且性能也很低
2、統計sql:很多時候,業務上都會有排行榜這種,發現公司有很多地方直接采用數據庫做計算,在對一些大表的做聚合運算的時候,經常超過五秒,這些sql一般很長而且很難優化, 像這種場景,如果業務允許(比如一致性要求不高或者是隔一段時間才統計的),可以專門在從庫里面做統計。另外我建議還是采用redis緩存來處理這種業務
3、超大分頁:在慢查詢日志中發現了一些超大分頁的慢查詢如limit 40000,1000,因為mysql的分頁是在server層做的,可以采用延遲關聯在減少回表。但是看了相關的業務代碼正常的業務邏輯是不會出現這樣的請求的,所以很有可能是有惡意用戶在刷接口,所以最好在開發的時候也對接口加上校驗攔截這些惡意請求。
這篇文章就總結到這里,希望能夠對你有所幫助!
-
編碼
+關注
關注
6文章
940瀏覽量
54814 -
MySQL
+關注
關注
1文章
804瀏覽量
26531 -
索引
+關注
關注
0文章
59瀏覽量
10468
原文標題:MySQL 基本知識點梳理和查詢優化
文章出處:【微信號:DBDevs,微信公眾號:數據分析與開發】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
STM32的GPIO端口模式基本知識點介紹
使用C語言進行單片機編程的基本知識點和編程規范資料總結
MySQL的基本知識點梳理和常用操作總結
STM32--基本知識點








 工商網監
工商網監
評論