 如何用機器學習解決數據庫運維難題
如何用機器學習解決數據庫運維難題
回顧整個運維的發展史,從最開始的系統管理到基礎腳本運維,再到自動化運維,最后發展到了智能運維。經過這些年的發展,運維人員的工作內容發生了翻天覆地的變化:
十幾年前,我們不知道故障會出現在哪,也不知道什么時候會出現故障,只有在故障出現的時候才能去查找根因并解決故障,這是一種很被動的方法。
到后來大規模的腳本引入,我們處理問題的方式變得更加科學了,速度也差強人意,但還是沒有改變這一種被動解決問題的本質現象;有了先前的經驗,很多公司引入了監控系統,發展了自己的自動化運維平臺,旨在問題發生或者即將發生時能夠自動地去解決問題,這種方式剛突破了之前所有的“被動運維”的本質,能夠防患于未然,將故障扼殺在搖籃中。但與之而來的卻是大量的告警及海量的監控數據,如何更加高效地解決故障成了我們現在必須解決的難題。
人工智能時代的來臨恰好解決了上面我們所面臨的問題,而AIOps就是希望基于已有的運維數據(日志、監控信息、應用信息等),并通過機器學習的方式來進一步解決自動化運維沒辦法解決的問題。
我們目前正在積極推動數據庫運維從自動化到智能化的轉變。眾所周知,數據挖掘和機器學習離不開海量的數據作為基礎,而平安科技通過這幾年的自動化運維的應用,已經積累了海量多維的數據庫性能數據、日志數據和主機數據。
利用這些數據,我們可以通過機器學習等方法在時間序列異常檢測、根因分析、郵件告警收斂、容量預測等多個應用場景中獲取我們想要的信息,從而進行故障的自動發現、自動診斷和自動解決。
一、時間序列異常檢測
時序數據是AIOps的基礎數據,有著規模大、種類多、需求多樣的特點。在自動化運維階段,我們所采用的大多是恒定閾值的方法。
這種方法簡單易實現,但是缺點也顯而易見:它不夠靈活,發現故障也不夠及時,無法滿足現在的告警需求。如下圖所示,傳統的閾值告警會忽略掉兩個波動的異常:
恒定閾值方法
動態閾值的方法在此時應運而生,傳統的動態閾值的方法采用了基于同比和環比的統計方法,這種方法解釋性強,易于實現,但是靈活性較差,受節假日影響較大(如下圖中,9月24號為中秋節,流量和上周相比下降明顯,此時環比和同比的方法不適用),發現問題也不夠及時。
還有許多公司采用帶權移動平均的方法來做動態閾值,他們認為在同一個維度下,某一個點的數值必然和它之前一段時間的數據有關,如以下公式所示:
9/18-9/25指標數據圖
我們目前正將機器學習應用在時序數據異常檢測中,和上述方法相比,機器學習的方法更為準確,成本也更大。
時間序列異常檢測本質上也可以看做“正常”和“異常”的二分類問題,通過將歷史的監控數據打上標簽,再將有監督和無監督算法結合建立模型,可以判斷當前的時間序列是否是正常的。
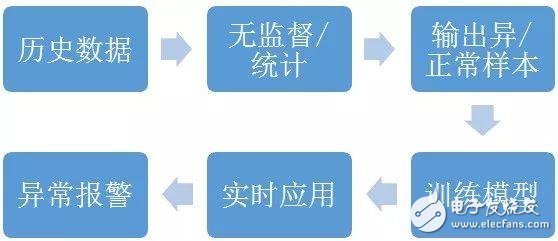
二、根因分析
大多數情況下,由于監控指標的相關聯性,如果某個指標異常了,很多相關指標也會異常。如果同時對所有的告警指標進行分析和處理,會浪費許多人力。為了解決這個問題,我們需要進行根因分析來進行針對性處理。
通常我們可以通過下列3種方法對數據進行根因分析:
相關度指標獲取,找到和異常指標在特定時間段內相似的指標。
在大量的樣本中,找出經常一起出現的異常指標(該問題就轉換成了頻繁序列挖掘問題),實現方法有關聯規則、APRIORI、FP_GROTH等。
利用決策樹的強可解釋性,對正負樣本進行分類,然后通過異常指標的分類樹途徑,找到頻繁的異常指標集。
第一種方法找出當前時間段內與DB_TIME指標有相似曲線的指標,并將最相似指標TOP N作為根因;
第二種方法則是在歷史數據中,當DB_TIME異常時,把其他異常的指標組成若干個項集,再從這些項集里面利用關聯規則找出強相關組合,則這些組合中的其他指標被視為根因;
第三種方法,則是在歷史數據中根據DB_TIME是否異常,將歷史數據分為正、負樣本,訓練決策樹模型得到最終的根因。
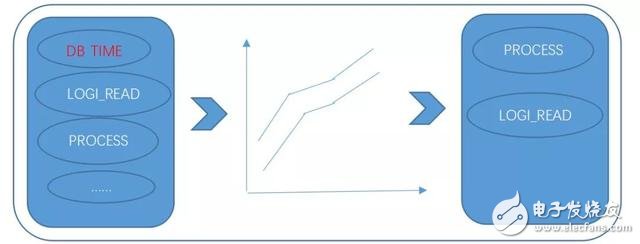
根因分析方法一
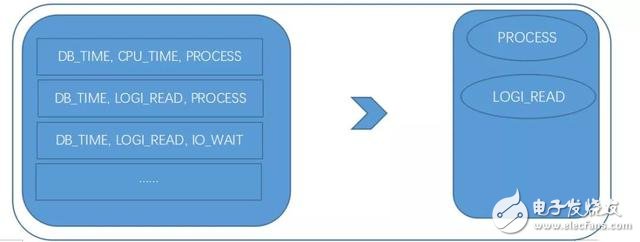
根因分析方法二
根因分析方法三
三、告警收斂
當監控業務發展到一定規模時,每日收到的告警郵件數會呈指數型增長,尤其是一些監控頻率較高的監控項出現問題時,這種情況特別明顯。
為了解決這一問題,在最開始,我們設定了告警頻率,讓同一種告警在一段時間內只出現一次。
這種方法確實會減少一部分告警,但是還有一些顯而易見的告警可以通過制定規則的方法來實現進一步的告警收斂。比如同一個集群內的數據庫都出現了ping不通的問題,又比如同一個網段內的所有IP流量突增,就可以將這些告警整合后再發送。
而在AIOps時代,告警收斂和根因分析往往是一起進行的。
和根因分析方法二類似,我們可以先獲取告警項集數據,并提取頻繁項。如果在頻繁告警項集中,告警A和告警B經常一起出現并且在A出現的時間比B早,則在郵件告警中,我們可以忽略B告警,只將A告警推送給運維人員。
不同場景下的告警收斂有著不同的需求,和AIOps相比,傳統的告警收斂方法更加簡單和高效,基于規則的方法也具有很強的拓展性和解釋性;而AIOps卻能挖掘出我們利用常識和經驗無法發現的關聯項并進行告警收斂。
四、容量預測
容量預測在數據庫運維中的很多地方都應用著,不同的應用場景有不同的特性,我們很難找到一個模型去適應所有的數據。
在容量預測上,我們的典型應用是數據庫DB_SIZE容量預測,數據庫容量具有總體上升、無規律、波動大的特點。對數據庫容量進行合理的預測,短期可以提前發現可能的故障,進行主動預防和提前解決,無需在問題發生時被動處理;長期可以進行合理的容量規劃和資源分配。
最開始,我們想到的是線性回歸加上簡單的數據預處理,但是結果十分不理想。由于業務規模的落差,不同數據庫的容量有著很大的差別,并且在數據庫進行導表,擴容等操作時,線性擬合或者非線性擬合的效果不盡人意。
顯然,傳統的線性回歸方法雖然簡單,但是預測效果較差,不能滿足要求。為了解決這一問題,我們將容量數據進行了分類,分為周期型和突升突降型,分類的方法可以采用統計方法,也可以使用聚類或分類的方法。
對于周期型數據,我們可以認為其實線性可擬合的,因為在總體上升的趨勢上,周期型的數據在周期內的增長值是線性遞增的。對于這種類型的數據,我們可以采用線性回歸的機器學習方法來對數據庫容量進行預測。
周期型數據
而對于突增突降型的數據,線性擬合效果較差,這時我們使用環比增量求和的方法,求得歷史數據中星期一到星期天的具體每天增量的加權平均值;再將這個增量應用到預測中。和單純的線性擬合方法相比,這種方法的準確性提高了很多,平均預測數據的均方殘差縮小了近一倍。
突升突降型數據
以上四個應用場景的技術開拓都是致力于通過AI讓運維更加高效,讓更多的故障可以被提前發現和解決。關于AIOps,我們還有很多東西可以去嘗試和探索,如智能問答機器人、日志集中分析平臺等,后續有相關成果再與大家分享。
-
數據庫
+關注
關注
7文章
3816瀏覽量
64470 -
機器學習
+關注
關注
66文章
8422瀏覽量
132743 -
運維
+關注
關注
1文章
259瀏覽量
7589
發布評論請先 登錄
相關推薦
請教如何用SQL語句來壓縮ACCESS數據庫
請問查詢sql數據庫的表格結果都是升序排列的,如何用降序排列?二維數組排列也只能升序?
學習Linux運維發展方向
跨平臺嵌入式數據庫EffiProz介紹
ADO 控件訪問數據庫的各種技巧探討
數據庫,數據庫是什么意思
SQL Server數據庫學習總結
MySQL數據庫誤刪后的回復技巧
數據庫學習教程之數據庫的發展狀況如何數據庫有什么新發展
數據庫系統的常見用戶
python有什么用 如何用python創建數據庫
體驗領禮啦!體驗自建數據庫遷移到阿里云數據庫RDS,領取桌面置物架!





 工商網監
工商網監
評論