 Atari游戲史上最強通關算法來了——Go-Explore!
Atari游戲史上最強通關算法來了——Go-Explore!
Atari游戲史上最強通關算法來了——Go-Explore!蒙特祖瑪獲分超過200萬,平均得分超過40萬;Pitfall平均超過21000分!
通關Atari游戲的最強算法來了!
在強化學習中,解決經典Atari游戲《蒙特祖瑪的復仇》和《Pitfall》一直是個巨大的挑戰。
這些游戲代表了一大類具有挑戰性的、現實世界中的問題,這些問題被稱為“硬探索問題(hard-exploration problems)”,而智能體必須通過獎勵(reward)來學習復雜的任務。
在采用最先進算法的情況下,蒙特祖瑪的平均得分為11347分,最高得分為17500分,并在十次嘗試中能通過一個關卡。然而令人驚訝的是,盡管進行了大量的研究,到目前為止還沒有算法在Pitfall上得到大于0的分數。
而一個新的算法Go-Explore,能夠在蒙特祖瑪中獲得超過200萬分,平均得分超過40萬分!Go-Explore非常穩定地把整個游戲都通關了,級別甚至能達到159級!
在Pitfall上,Go-Explore的平均分超過了21000分,遠遠超過了人類的平均成績,并且在所有學習算法上,首次得到超過0分的成績。要做到這一點,智能體需要穿過40個房間,搖擺于水上的繩索,跳過鱷魚、陷阱以及滾動桶等。
總而言之,Go-Explore使得蒙特祖瑪和Pitfall在技術水平上都得到了大幅度的提高。它無需涉及“人類的演示”,并且在結果和性能上完敗目前最先進的算法。
Go-Explore可以從人工領域知識(domain knowledge)中獲益,無需人類先行通關來演示。領域知識是最小的,很容易從像素中獲得,突出了Go-Explore利用最小先驗知識的能力。而即使沒有任何領域知識,Go-Explore在蒙特祖瑪中得分也超過了3.5萬分,是目前最高水平的三倍多。
Go-Explore與其他深度強化學習算法有很大區別。它可以在許多重要的且具有挑戰性的問題上取得突破性進展,尤其是機器人技術。
“稀疏獎勵”和“欺騙性”是最具難度的挑戰
獎勵(reward)較少的問題是比較棘手的,因為隨機行動不可能產生獎勵,因此無法學習。《蒙特祖瑪的復仇》就是一種“稀疏獎勵問題(sparse reward problem)”。
更具挑戰的是當獎勵具有欺騙性時,這意味著在短期內最大化獎勵會讓智能體在獲得更高分數時出錯。Pitfall就是具有欺騙性的,因為許多行為會導致較小的負面獎勵(比如攻擊敵人),因此大多數算法學習到的結果就“不動”。
許多具有挑戰性的現實問題也是既稀疏又具有欺騙性。
普通的強化學習算法通常無法從蒙特祖瑪的第一個房間(得分400或更低)中跳出,在Pitfall中得分為0或更低。為了解決這類挑戰,研究人員在智能體到達新狀態(情境或地點)時,會給他們獎勵,這種探索通常被稱為內在動機(intrinsic motivation,IM)。
盡管IM算法是專門設計用來解決稀疏獎勵問題的,但它們在蒙特祖瑪和Pitfall表現依舊不佳:在蒙特祖瑪中,很少能通過第一關,在Pitfall中就完全是失敗的,得分為0。
IM算法分離的例子。綠色區域表示內在獎勵,白色區域表示沒有內在獎勵的區域,紫色區域表示算法目前正在探索的區域。
假設當前IM算法的一個主要缺點是分離,算法會忘記它們訪問過的“有獎勵”的區域,這意味著它們不會返回這些區域,來查看它們是否會導致新的狀態。
比如,兩個迷宮之間有一個智能體,首先它會隨機地向西開始探索左邊的迷宮,由于算法在行為或參數中加入了隨機性,智能體可能在探索完左邊50%的迷宮的時候,開始探索向東探索右邊的迷宮。右邊的迷宮探索完之后,智能體可以說已然是“遺忘”了剛才探索左邊迷宮的事情了。
而更糟糕的是,左邊的迷宮已經有一部分是探索過的,換句話說,智能體在左邊迷宮已經“消費”了一定的獎勵,當它再回頭探索相同的迷宮時,不會再有更多的獎勵了,這就嚴重的影響了學習的效果。
Go-Explore
Go-Explore算法概述
Go-Explore將學習分為兩個步驟:探索和強化。
第一階段:探索,直到解決。Go-Explore構建了一個有趣的不同游戲狀態(我們稱之為“單元格”)和導致這些狀態的軌跡檔案,在問題解決之前會一直做如下的重復:
隨機選擇存檔中的單元格;
回到那個單元格;
從該單元格中探索(例如,隨機進行n個步驟);
對于所有訪問的單元格(包括新的單元格),如果新的軌跡更好(例如更高的分數),則將其作為到達該單元格的軌跡進行交換。
第二階段:強化。如果找到的解決方案對噪聲不夠魯棒(就像Atari軌跡那樣),就用模擬學習算法將它們組合成一個深層神經網絡。
單元格表示(Cell representation)
要在像Atari這樣的高維狀態空間中易于處理,Go-Explore需要一個低維的單元表示來形成它的存檔。因此,單元格表示應該合并足夠相似而不值得單獨研究的狀態。重要的是,創建這樣的表示并不需要游戲特定的領域知識。最簡單的單元格表示方式所得到的結果會非常好,即簡單地對當前游戲框架進行下采樣。
下采樣單元格表示。 完全可觀察狀態(彩色圖像)縮小為具有8個像素強度的11×8灰度圖像。
返回單元格(Returning to cells)
根據環境的限制,可以通過三種方式返回單元格(在進行探索之前)。按效率排序:
在可重置環境中,可以簡單地將環境狀態重置為單元格的狀態;
在確定性環境中,可以將軌跡重放到單元格;
在隨機環境中,可以訓練目標條件策略(goal-conditioned policy),學習返回到單元。
采用穩健的深度神經網絡策略的結果
試圖從通關蒙特祖瑪的復仇第1級的軌跡中產生穩健的策略的努力都取得了成效。平均得分為35410分,是之前最好成績的11347分的3倍多,略高于人類專家平均水平的34900分!
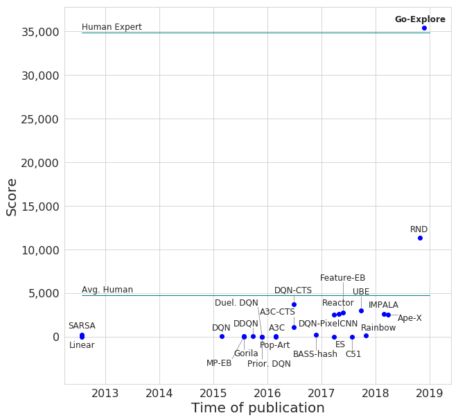
無領域知識的Go-Explore與其他RL算法在蒙特祖瑪的復仇中的比較。圖中的每一點都代表了蒙特祖瑪的復仇上測試的不同算法。
添加領域知識
算法如果能集成易于取得的領域知識,這是一項重要的能力。Go-Explore提供了在cell representation中利用領域知識的機會。我們在蒙特祖瑪的復仇中測試了具有領域知識的Go-Explore版本,其中cell被定義為智能體的x-y坐標、當前房間、當前關卡和當前持有的密鑰數量的唯一組合。我們編寫了一些簡單的代碼來直接從像素中提取這些信息。
使用這種改進的state representation,Go-Explore在Phase 1找到了238個房間,平均通關了超過9個關卡,并且與縮小的圖像單元表示相比,模擬器步驟減少了一半。
Go-Explore在Phase 1發現的房間數量
Robustified的結果
對Go-Explore領域知識版本中發現的軌跡進行Robustifying,可以生成深度神經網絡策略,可靠地解決了蒙特祖瑪的復仇的前3個關卡。因為在這個游戲中,關卡3之外的所有關卡幾乎都是相同的(如上所述),Go-Explore已經解決了整個游戲!
事實上,我們的agent超越了它們的初始軌跡,平均解決了29個關卡,平均得分達到469209分!這打破了針對蒙特祖瑪的復仇的傳統RL算法和模仿學習算法的最高水平,這兩種算法都以人類演示的形式給出解決方案。令人難以置信的是,Go-Explore的一些神經網絡得分超過200萬,達到159關!為了充分了解這些agent能夠做到什么程度,我們不得不增加了OpenAI的Gym允許agent玩游戲的時間。Go-Explore的最高分數遠遠超過了人類1,219,200分的世界紀錄,即使是最嚴格的“超越人類表現”的定義,它也達到了。
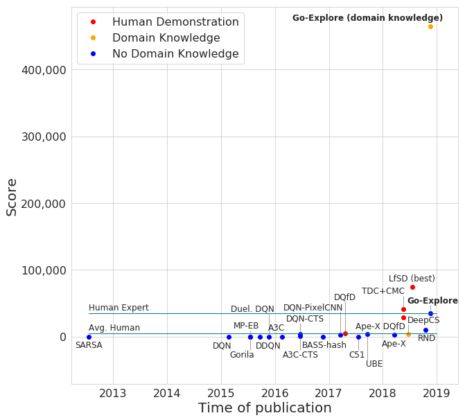
具有領域知識的Go-Explore與其他RL算法在蒙特祖瑪的復仇游戲中的比較。紅點表示以人類演示的形式給出解決方案的算法。
即使加速了4倍,這個破紀錄的運行的完整視頻也有53分鐘。并且,agent還沒有死,只是達到了時間限制(時間已經大大增加)。
Pitfall游戲
Pitfall也需要大量的探索,而且比蒙特祖瑪的復仇更難,因為它的獎勵更稀疏(只有32個正面的獎勵分散在255個房間中),而且許多操作產生的負面獎勵很小,這阻礙了RL算法探索環境。到目前為止,我們所知的RL算法還沒有在這個游戲中得到哪怕是一個正面的獎勵(在沒有給出人類演示的情況下)。
相比之下,Go-Explore只需要最少的領域知識(屏幕上的位置和房間號,都可以從像素中獲取),就能夠到達所有255個房間,收集超過60000點。在沒有領域知識(即縮小的像素表示)的情況下,Go-Explore找到了22個房間,但沒有找到任何獎勵。我們認為縮小的像素表示在Pitfall中表現不佳,因為游戲包含許多具有相同像素表示的不同狀態(即游戲中位置不同、但外觀相同的房間)。在沒有領域知識的情況下區分這些狀態可能需要考慮先前狀態的狀態表示,或者開發其他技術。
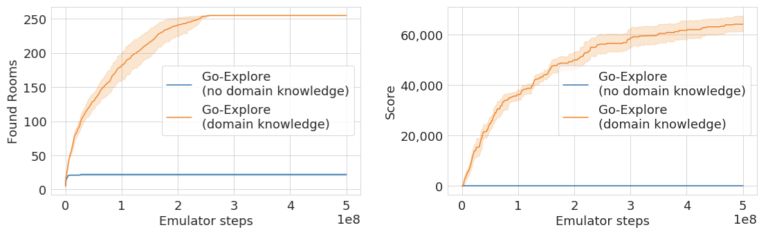
圖:Go-Explore在Pitfall游戲的探索階段找到的房間(左)和獲得的獎勵(右)
從探索階段收集的軌跡中,我們能夠可靠地對收集超過21,000點的軌跡進行強化,這大大超過了目前最優的水平和人類的平均表現。事實證明,較長的、得分較高的軌跡很難區分,這可能是因為視覺上難以區分的狀態可能需要不同的行為。
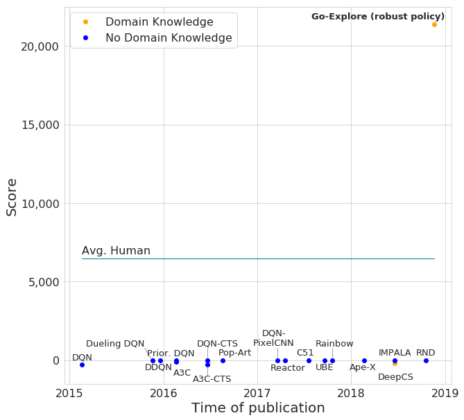
Go-Explore生成的深度神經網絡策略與其他RL算法在Pitfall上的比較。
Pitfall游戲中得分超過21000分的AI
三個關鍵見解
Go-Explore在硬探索問題上的表現非常出色,原因有三個:
1、記住探索過程中好的情況(墊腳石)
2、先回到一個狀態,然后探索
3、先解決問題,然后進行強化(如果需要的話)
這些原則在大多數RL算法中都不存在,但是將它們編入其中會很有趣。正如上面所討論的,當前的RL算法不會做第1點。第2點很重要,因為當前的RL算法通過隨機擾動現行策略的參數或行為來探索新領域的環境,但當大幅打破或改變策略時,這種方法是無效的,因為不能在進一步探索之前先返回難以到達的狀態。
達到某種狀態所需的動作序列越長、越復雜、越精確,這個問題就越嚴重。Go-Explore解決了這個問題,它首先返回到一個狀態,然后從那里開始探索。這樣做可以進行深入的探索,從而找到問題的解決方案,然后對問題進行糾正,進而產生可靠的策略(原則3)。
值得注意的是,Go-Explore的當前版本在探索過程中采取完全隨機的行動(沒有任何神經網絡!),甚至在對狀態空間進行非常簡單的離散化時,它也是有效的。盡管如此簡單的探索取得了成功,但它強烈地表明,記住和探索好的墊腳石是有效探索的關鍵,而且即使是在其他簡單的探索中這樣做,也比當代deepRL方法更有助于尋找新的狀態并表示這些狀態。通過將其與有效的、可學習的表示形式結合起來,并將當前的隨機探索替換為更智能的探索策略,Go-Explore可能會更加強大。我們正在研究這兩種途徑。
結論
總的來說,Go-Explore是一個令人興奮的新算法家族,用于解決難以探索的強化學習問題,即那些具有稀疏和/欺騙性獎勵的問題。它開辟了大量新的研究方向,包括不同的cell representations,不同的探索方法,不同的robustification方法,如不同的模仿學習算法等。
我們也很興奮地看到Go-Explore在哪些領域擅長,在什么時候會失敗。它給我們的感覺就像一個充滿各種可能性的游樂場,我們希望你能加入我們的行列一起來研究這個領域。
我們將很快提供Go-Explore的源代碼和完整論文。
-
智能體
+關注
關注
1文章
152瀏覽量
10590 -
強化學習
+關注
關注
4文章
267瀏覽量
11263
原文標題:史上最強Atari游戲通關算法:蒙特祖瑪獲分超過200萬!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦







 工商網監
工商網監
評論