 如何借鑒人類聽覺系統,基于自編碼器學習音頻嵌入表示
如何借鑒人類聽覺系統,基于自編碼器學習音頻嵌入表示
編者按:Kanda機器學習工程師Daniel Rothmann講解了如何借鑒人類聽覺系統,基于自編碼器學習音頻嵌入表示。
圖片來源:Jonathan Gross
AI技術的顯著突破都是通過建模人類系統達成的。盡管人工神經網絡這一數學模型不過是從人類神經元運作的方式中獲得了最初的啟發,它們在解決復雜而含混的真實世界問題上的應用有目共睹。此外,建模人腦神經網絡的架構深度為學習數據更多有意義表示開啟了廣泛的可能性。
在圖像識別和處理領域,借鑒復雜而更具有空間不變性的視覺系統細胞的CNN大大改進了我們的技術。如果你有興趣在音頻頻譜上應用圖像識別技術,可以看下本系列的第二篇文章。
只要人類的感知能力超過機器,我們就能持續通過理解人類學習的原理而取得進展。人類非常擅長感知任務,特別是機器聽覺這一領域,當前AI的表現與人類的差距明顯。有鑒于視覺處理依靠借鑒人類系統得到的收獲,我認為用于機器聽覺的神經網絡能夠持續基于類似的過程得到改進。
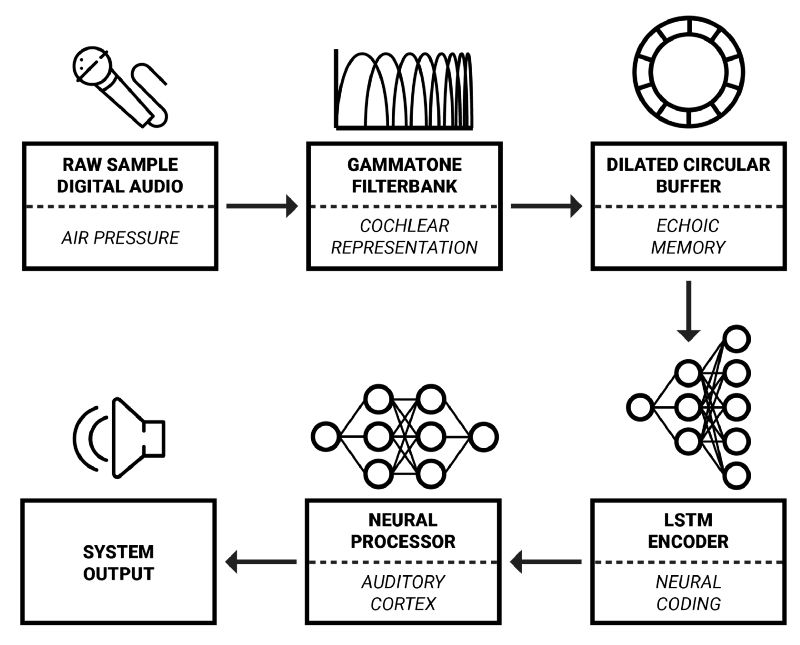
框架概覽
在這一系列文章中,我將詳細介紹奧胡斯大學和智能揚聲器生產商Dynaudio A/S合作開發的實時音頻信號處理框架。該框架的靈感主要來自于認知科學——試圖結合生物學、神經科學、心理學、哲學以更好地理解我們的認知能力的科學。
認知聲音性質
也許聲音最抽象的一方面就是人類是如何感知它的。盡管信號處理問題的解答方案需要在低層操作強度、空間、時間性質的參數,但最終的目標常常是認知上的:以特定方式變換信號,調整聲音的感知。
例如,如果有人想要通過編程的方式將說話錄音的性別修改一下,那么在定義其低層屬性之前,有必要先以更有意義的形式描述這一問題。說話人的性別可以被視作一個由多種因素決定的認知性質:嗓音的音高、音色,發音的不同,措辭的不同,以及通常人們如何理解這些性質和性別的關系。
這些參數可以通過強度、空間、時間性質之類的低層特征描述,但通過更復雜的組合它們才形成了高層表示。這形成了音頻特性的層次結構,從中可以導出聲音的“含義”。表示人類嗓音的認知性質可以看成聲音的強度、空間、統計學性質的時域發展的組合模式。
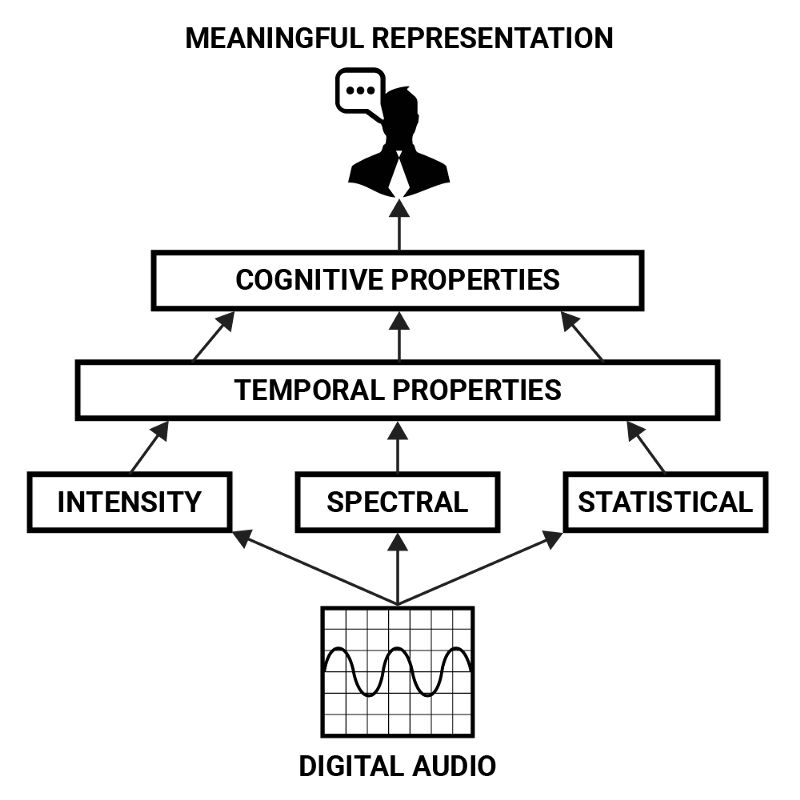
神經網絡非常擅長提取數據的抽象表示,因此很適合檢測聲音的認知性質這一任務。為了構建達成這一目的的系統,讓我們首先檢視下人類聽覺器官是如何表示聲音的,供神經網絡處理的聲音表示可以從中得到借鑒。
耳蝸表示
人類的聽覺始于外耳的耳廓。耳廓起到空間預處理的作用,取決于傳入聲音和聽話人的相對方向,耳廓修改了傳入的聲音。接著,聲音從耳廓的開口傳入耳道。耳道通過共鳴進一步修改傳入聲音的空間特性,共鳴將放大1-6kHz中的頻率1。
聲波到達耳道盡頭后刺激附著在鼓膜上的聽小骨(人體內最小的骨頭)。這些聽小骨將耳道的壓力傳輸到內耳中充滿液體的耳蝸1。神經網絡的聲音表示對借鑒耳蝸很有興趣,因為耳蝸正是人類負責將聽覺振動轉換為神經活動的器官。
耳蝸是由賴斯納氏膜和基底膜分隔的盤管。耳蝸中有大約3500個內毛細胞1。隨著壓力傳入耳蝸,耳蝸中的兩道膜被下壓。基底膜底部窄而硬,頂部寬而松,這樣,特定頻率上的回應自頂部至底部遞增。
簡單地說,基底膜可以被看成一組連續的帶通濾波器,沿著基底膜區分出聲音的頻譜成分。
這就是人類轉換聲音壓力至神經活動的主要機制。因此,我們有理由假設聲音的空間表示對使用AI建模聲音感知會有幫助。由于基底膜的頻率響應呈指數變化2,對數頻率表示可能是最高效的。我們可以使用gammatone濾波器組得到這樣的表示。這些濾波器常用于建模聽覺系統的空間過濾,因為它們近似revor函數。通過測量聽覺神經纖維對白噪聲刺激的響應,我們可以導出人類聽覺過濾器的沖動響應函數,該函數被稱為revor函數3。
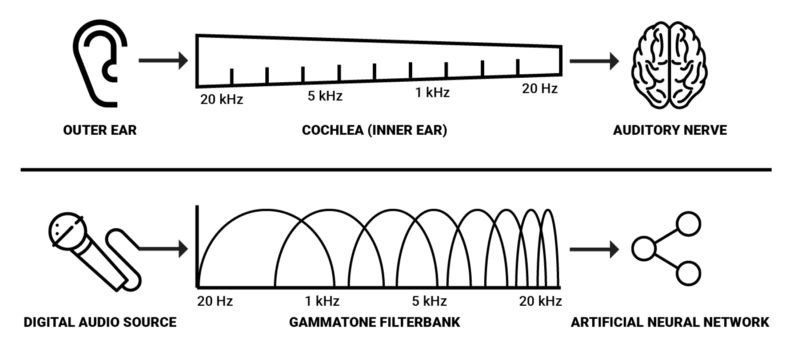
由于耳蝸具備大約3500個內毛細胞,而人類能夠檢測到約2-5毫秒的聲音空隙1,空間解析度為3500的gammatone濾波器組搭配2毫秒的窗口看上去是在機器上達到類似人類的空間表示的最佳參數。然而,在實際場合,我覺得可以假定更低的解析度仍能在大多數分析和處理任務中取得所需效果,而且從算力的角度來說這樣更可行。
網上有一些用于聽覺分析的軟件庫。值得注意的一個例子是Jason Heeris的Gammatone Filterbank Toolkit。它提供了可供調整的濾波器,以及使用gammatone濾波器對音頻信號進行頻譜類分析的工具。
神經編碼
在神經活動從耳蝸到聽覺神經,沿著聽覺通路傳遞的過程中,在達到聽覺皮層之前,腦干核團對其進行了一系列處理。
這些處理形成了表示刺激和感知之間的接口的神經編碼4。關于這些核團的特定內部工作機制的很多知識都是基于推測的,或者未知的,所以我將僅僅介紹核團的高層功能。
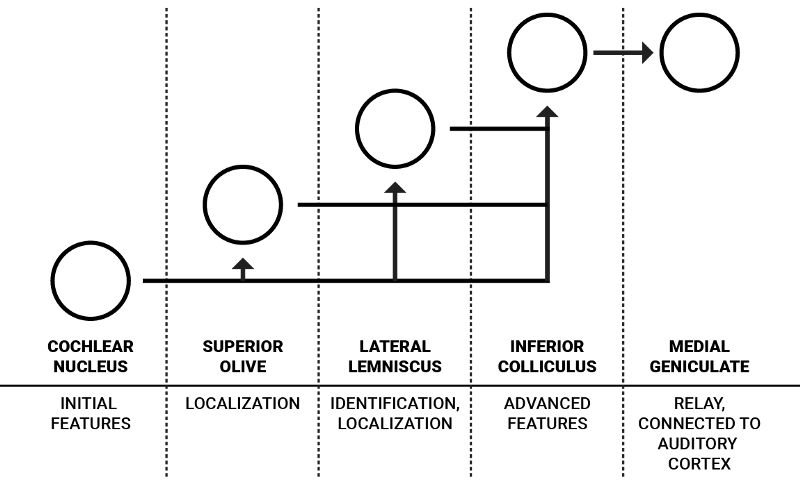
單耳聽覺通路的簡化示意圖
人類每只耳朵都有一組核團,這些核團相互連接。不過,出于簡單性,上圖只畫了單耳的流程。耳蝸核是來自聽覺神經的神經信號的第一個編碼步驟。它包含性質不同的各種神經元,對聲音的特征進行初步處理,其中部分傳向負責定位聲音的上橄欖體,剩余部分傳向和更高級特征相關的外側丘系和下丘1。
J. J. Eggermont在“Between sound and perception: reviewing the search for a neural code”(聲音和感知之間:神經編碼研究回顧)一文中詳細描述了耳蝸核中的信息流:“腹側耳蝸核(VCN)提取并增強在聽覺神經纖維的激活模式中多路傳播的頻率和時間信息,并將結果分配到兩個通路:聲音定位通路和聲音識別通路。VCN的前部(AVCN)主要負責聲音定位,它的兩種多毛細胞為上橄欖復合體(SOC)提供輸入,SOC在每個頻率上分別映射雙耳時間差(ITD)和強度差(ILD)。”4
聲音識別通路傳輸的信息可以表示元音之類復雜的頻譜。這一表示主要由腹側耳蝸核中特殊類型的單元(梳齒型神經元)創建4。這些聽覺編碼的細節難以明確,但它們啟發我們傳入頻率頻譜的“編碼”形式可能改善對低層聲音特征的理解,也讓神經網絡處理聲象不那么昂貴。
頻譜聲音編碼
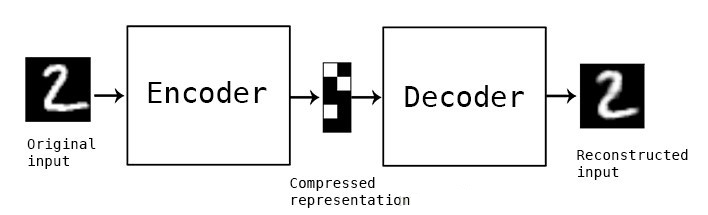
我們可以應用無監督自編碼器神經網絡架構來學習復雜頻譜的常見性質。類似詞嵌入,我們有可能找到頻率頻譜中的共性,這些共性表示聲音的選定特征(或者高度壓縮的含義)。
訓練自編碼器編碼輸入為壓縮表示,該表示可以重建和輸入高度相似的表示。這意味著自編碼器的目標輸出是輸入自身5。如果輸入可以在損失不大的情況下重建,那就說明網絡學習到了所需編碼方式,這一方式編碼的內部壓縮表示中包含足夠多的有意義信息。我們將這一內部表示稱為嵌入。自編碼器的編碼部分可以和解碼器解耦,為其他應用生成嵌入。
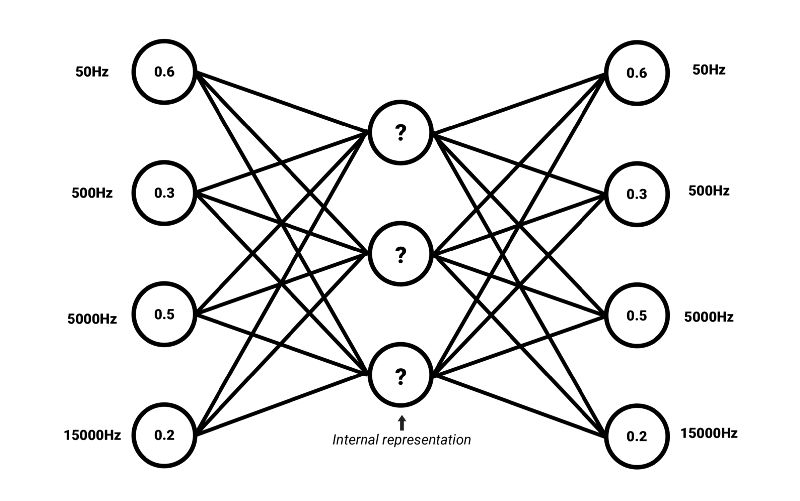
嵌入還有一個優勢,嵌入常常比原始數據的維度要低。例如,自編碼器可以將共有3500個值的頻率頻譜壓縮為長度為500的向量。簡單來說,這樣的向量的每個值可以描述頻譜的高層特征,例如元音、刺耳、諧波——這些只是舉例,因為自編碼器推導出的統計學共同因素的含義常常難以用簡單的語言標記。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100718 -
視覺系統
+關注
關注
3文章
334瀏覽量
30697 -
ai技術
+關注
關注
1文章
1266瀏覽量
24287
原文標題:機器聽覺:三、基于自編碼器學習聲音嵌入表示
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于變分自編碼器的異常小區檢測
是什么讓變分自編碼器成為如此成功的多媒體生成工具呢?

自編碼器介紹
稀疏自編碼器及TensorFlow實現詳解
基于稀疏自編碼器的屬性網絡嵌入算法SAANE
自編碼器基礎理論與實現方法、應用綜述
一種多通道自編碼器深度學習的入侵檢測方法

基于變分自編碼器的網絡表示學習方法
基于自編碼特征的語音聲學綜合特征提取
結合深度學習的自編碼器端到端物理層優化方案
自編碼器神經網絡應用及實驗綜述
堆疊降噪自動編碼器(SDAE)
自編碼器 AE(AutoEncoder)程序






 工商網監
工商網監
評論