 英偉達再出AI黑科技,通過生成模型渲染3D環境
英偉達再出AI黑科技,通過生成模型渲染3D環境
近日,在蒙特利爾舉行的神經信息處理系統大會(NeurIPS)上,英偉達在一篇題為“視頻到視頻合成(“Video-to-Video Synthesis” )”的技術論文中闡述了其最新AI成果。
據透露,英偉達最新研發的這項成果,是可以渲染合成交互式3D環境的AI技術。在創建逼真的3D環境時,英偉達研發團隊不再使用傳統的圖形技術,而是使用神經網絡 ,特別是“生成模型”,通過來自如YouTube等來源的真實視頻,進行模型訓練,最終構建逼真的3D虛擬世界。
英偉達研發團隊之所以使用“生成模型”來提高輸出的準確性,是由于這種模型要求機器必須有效地內化數據的本質,它也因此被廣泛認為是促進機器“理解”大量數據之間關系的最有前途的方法之一。
但是,像所有神經網絡一樣,使用這個模型也需要訓練數據。幸運的是,英偉達研發團隊將AI模型應用于街景,通過自動駕駛項目采集到的大量視頻數據,確保了其關于城市街道上行駛車輛的訓練鏡頭,再以分段網絡識別不同的對象類別,如地面,樹木,汽車,天空,建筑物等,開發算法以了解每個對象與其他對象的關系,最終,這些模型創建了城市環境的基本拓撲結構,然后AI再從基于從訓練數據中學到的東西,模擬世界外觀,包括照明,材料和動態等,由此生成幾乎是還原性的高逼真3D環境。
“由于場景是完全合成生成的,因此可以輕松編輯以刪除,修改或添加對象”英偉達表示。
在論文中,英偉達研發團隊得出的結論是:“我們提出了一種基于條件生成對抗網絡(GAN)的通用視頻到視頻合成框架:通過精心設計的發生器、鑒別器網絡以及時空對抗物鏡,我們可以合成高分辨率、照片級真實、時間一致的視頻,大量實驗表明,我們的結果明顯優于最先進方法的結果。”
不得不承認,迄今為止,AI已經是人類最強有力的創新“加速器”,它讓人類的能力得以延展,并逐漸變得更加強大。我們都能看到,在全世界范圍內,數以萬計的科學家們都在為AI技術的前沿突破做出努力,除了英偉達之外,不論是像Google、Facebook這樣的海外巨頭,還是類似國內曠視科技、極鏈科技這樣的AI科技公司,都致力于全力研發產出能像人一樣思考的AI技術。今天,曠視科技已經實現AI識別人臉對象中的各種特征,極鏈科技已經實現AI理解海量視頻的場景表達,而未來,AI必然不僅是會讓機器“知其然”,還要做到讓它“知其所以然”,以最終實現推動整個AI進入“深度智能”的偉大愿景。
-
AI
+關注
關注
87文章
31335瀏覽量
269712
發布評論請先 登錄
相關推薦
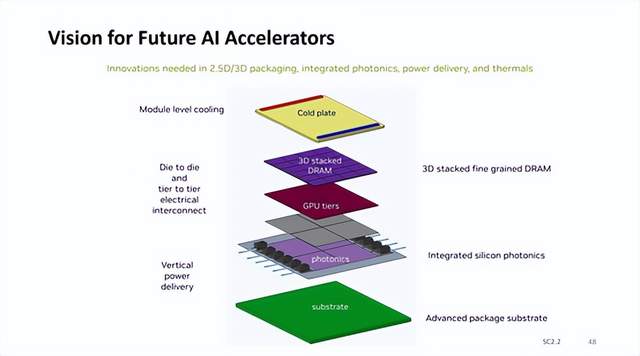
英偉達AI加速器新藍圖:集成硅光子I/O,3D垂直堆疊 DRAM 內存
鴻海與英偉達攜手打造下世代AI工廠
英偉達Cosmos AI項目曝光:構建先進視頻模型
歡創播報 騰訊元寶首發3D生成應用

VIVERSE 推行實時3D渲染: 探索Polygon Streaming技術力量與應用

英偉達首席執行官黃仁勛:AI模型推動英偉達AI芯片需求
進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
烘焙vs渲染:3D模型制作中的效率與質量之爭

NVIDIA生成式AI研究實現在1秒內生成3D形狀






 工商網監
工商網監
評論