 Linux內核同步機制之原子操作
Linux內核同步機制之原子操作
一、源由
我們的程序邏輯經常遇到這樣的操作序列:
2、修改該變量的值(也就是修改寄存器中的值)
3、將寄存器中的數值寫回memory中的變量值
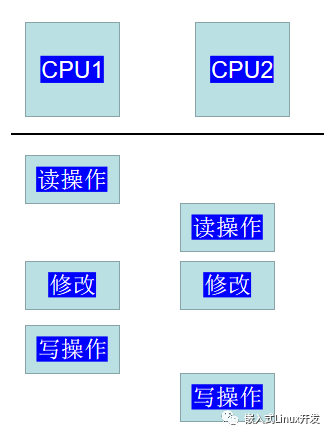
如果這個操作序列是串行化的操作(在一個thread中串行執行),那么一切OK,然而,世界總是不能如你所愿。在多CPU體系結構中,運行在兩個CPU上的兩個內核控制路徑同時并行執行上面操作序列,有可能發生下面的場景:
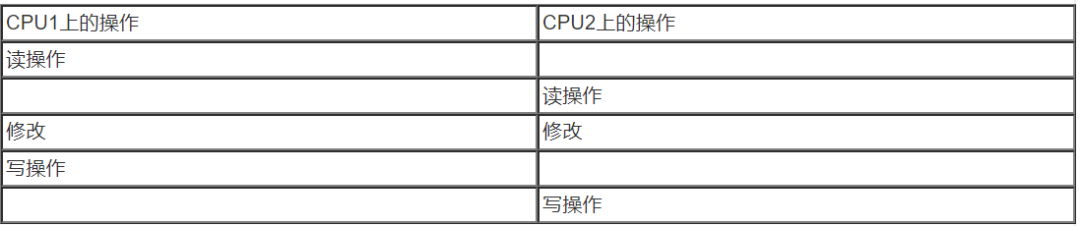
多個CPUs和memory chip是通過總線互聯的,在任意時刻,只能有一個總線master設備(例如CPU、DMA controller)訪問該Slave設備(在這個場景中,slave設備是RAM chip)。因此,來自兩個CPU上的讀memory操作被串行化執行,分別獲得了同樣的舊值。完成修改后,兩個CPU都想進行寫操作,把修改的值寫回到memory。但是,硬件arbiter的限制使得CPU的寫回必須是串行化的,因此CPU1首先獲得了訪問權,進行寫回動作,隨后,CPU2完成寫回動作。在這種情況下,CPU1的對memory的修改被CPU2的操作覆蓋了,因此執行結果是錯誤的。
不僅是多CPU,在單CPU上也會由于有多個內核控制路徑的交錯而導致上面描述的錯誤。一個具體的例子如下:
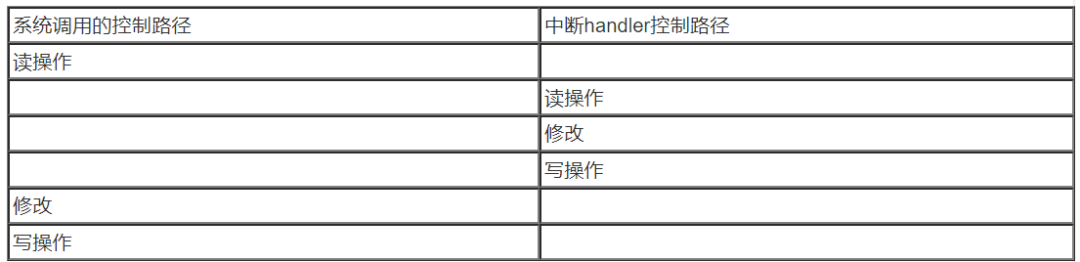
系統調用的控制路徑上,完成讀操作后,硬件觸發中斷,開始執行中斷handler。這種場景下,中斷handler控制路徑的寫回的操作被系統調用控制路徑上的寫回覆蓋了,結果也是錯誤的。
二、對策
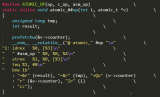
對于那些有多個內核控制路徑進行read-modify-write的變量,內核提供了一個特殊的類型atomic_t,具體定義如下:

從上面的定義來看,atomic_t實際上就是一個int類型的counter,不過定義這樣特殊的類型atomic_t是有其思考的:內核定義了若干atomic_xxx的接口API函數,這些函數只會接收atomic_t類型的參數。這樣可以確保atomic_xxx的接口函數只會操作atomic_t類型的數據。同樣的,如果你定義了atomic_t類型的變量(你期望用atomic_xxx的接口API函數操作它),這些變量也不會被那些普通的、非原子變量操作的API函數接受。
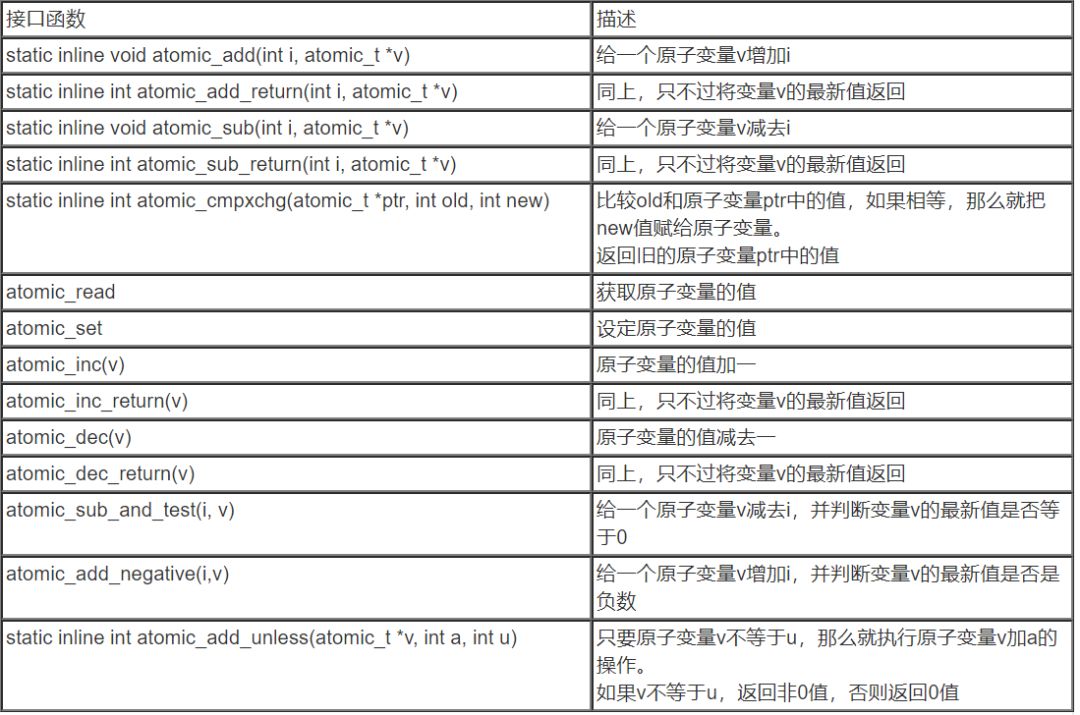
具體的接口API函數整理如下:
三、ARM中的實現
我們以atomic_add為例,描述linux kernel中原子操作的具體代碼實現細節:
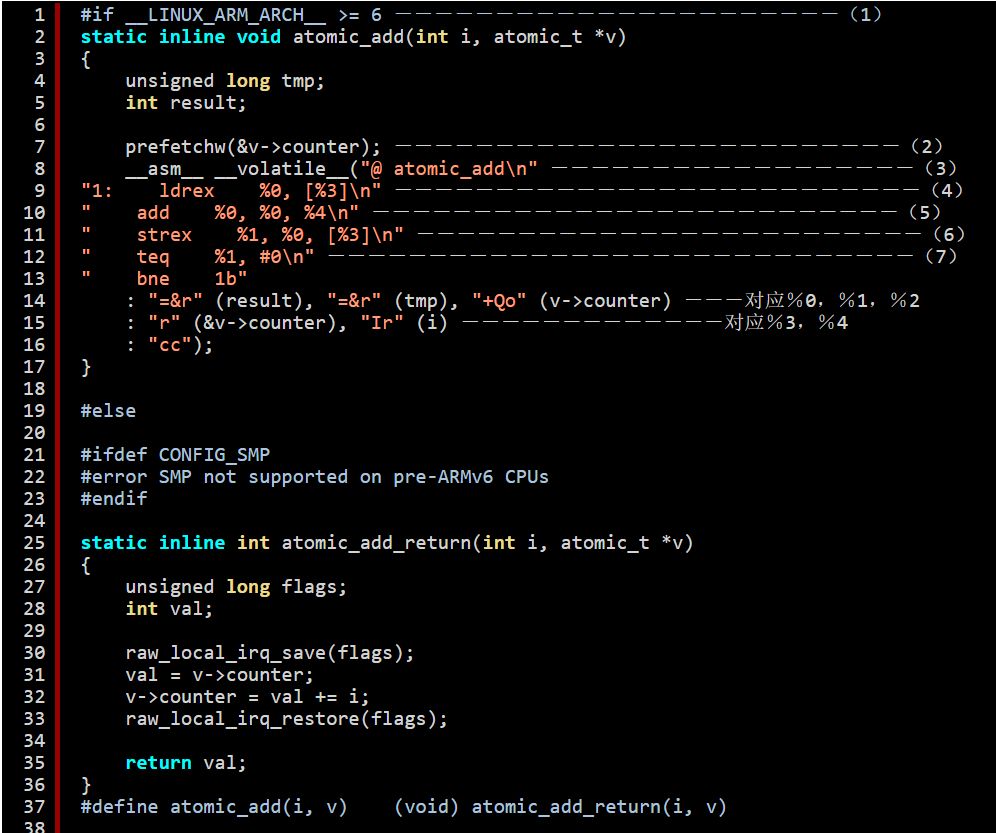
(1)ARMv6之前的CPU并不支持SMP,之后的ARM架構都是支持SMP的(例如我們熟悉的ARMv7-A)。因此,對于ARM處理,其原子操作分成了兩個陣營,一個是支持SMP的ARMv6之后的CPU,另外一個就是ARMv6之前的,只有單核架構的CPU。對于UP,原子操作就是通過關閉CPU中斷來完成的。
(2)這里的代碼和preloading cache相關。在strex指令之前將要操作的memory內容加載到cache中可以顯著提高性能。
(3)為了完整性,我還是重復一下匯編嵌入c代碼的語法:嵌入式匯編的語法格式是:asm(code : output operand list : input operand list : clobber list)。output operand list 和 input operand list是c代碼和嵌入式匯編代碼的接口,clobber list描述了匯編代碼對寄存器的修改情況。為何要有clober list?我們的c代碼是gcc來處理的,當遇到嵌入匯編代碼的時候,gcc會將這些嵌入式匯編的文本送給gas進行后續處理。這樣,gcc需要了解嵌入匯編代碼對寄存器的修改情況,否則有可能會造成大麻煩。例如:gcc對c代碼進行處理,將某些變量值保存在寄存器中,如果嵌入匯編修改了該寄存器的值,又沒有通知gcc的話,那么,gcc會以為寄存器中仍然保存了之前的變量值,因此不會重新加載該變量到寄存器,而是直接使用這個被嵌入式匯編修改的寄存器,這時候,我們唯一能做的就是靜靜的等待程序的崩潰。還好,在output operand list 和 input operand list中涉及的寄存器都不需要體現在clobber list中(gcc分配了這些寄存器,當然知道嵌入匯編代碼會修改其內容),因此,大部分的嵌入式匯編的clobber list都是空的,或者只有一個cc,通知gcc,嵌入式匯編代碼更新了condition code register。
大家對著上面的code就可以分開各段內容了。@符號標識該行是注釋。
這里的__volatile__主要是用來防止編譯器優化的。也就是說,在編譯該c代碼的時候,如果使用優化選項(-O)進行編譯,對于那些沒有聲明__volatile__的嵌入式匯編,編譯器有可能會對嵌入c代碼的匯編進行優化,編譯的結果可能不是原來你撰寫的匯編代碼,但是如果你的嵌入式匯編使用__asm__ __volatile__(嵌入式匯編)的語法格式,那么也就是告訴編譯器,不要隨便動我的嵌入匯編代碼哦。
(4)我們先看ldrex和strex這兩條匯編指令的使用方法。ldr和str這兩條指令大家都是非常的熟悉了,后綴的ex表示Exclusive,是ARMv7提供的為了實現同步的匯編指令。
LDREX
STREX
和LDREX指令類似,
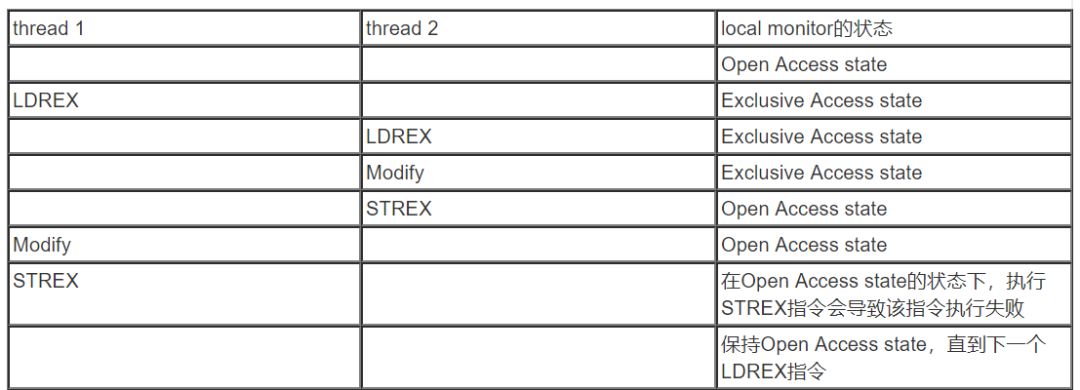
開始的時候,local monitor處于Open Access state的狀態,thread 1執行LDREX 命令后,local monitor的狀態遷移到Exclusive Access state(標記本地CPU對xxx地址進行了LDREX的操作),這時候,中斷發生了,在中斷handler中,又一次執行了LDREX ,這時候,local monitor的狀態保持不變,直到STREX指令成功執行,local monitor的狀態遷移到Open Access state的狀態(清除xxx地址上的LDREX的標記)。返回thread 1的時候,在Open Access state的狀態下,執行STREX指令會導致該指令執行失敗(沒有LDREX的標記,何來STREX),說明有其他的內核控制路徑插入了。
對于shareable memory,需要系統中所有的local monitor和global monitor共同工作,完成exclusive access,概念類似,這里就不再贅述了。
大概的原理已經描述完畢,下面回到具體實現面。
其中%3就是input operand list中的"r" (&v->counter),r是限制符(constraint),用來告訴編譯器gcc,你看著辦吧,你幫我選擇一個通用寄存器保存該操作數吧。%0對應output openrand list中的"=&r" (result),=表示該操作數是write only的,&表示該操作數是一個earlyclobber operand,具體是什么意思呢?編譯器在處理嵌入式匯編的時候,傾向使用盡可能少的寄存器,如果output operand沒有&修飾的話,匯編指令中的input和output操作數會使用同樣一個寄存器。因此,&確保了%3和%0使用不同的寄存器。
(5)完成步驟(4)后,%0這個output操作數已經被賦值為atomic_t變量的old value,毫無疑問,這里的操作是要給old value加上i。這里%4對應"Ir" (i),這里“I”這個限制符對應ARM平臺,表示這是一個有特定限制的立即數,該數必須是0~255之間的一個整數通過rotation的操作得到的一個32bit的立即數。這是和ARM的data-processing instructions如何解析立即數有關的。每個指令32個bit,其中12個bit被用來表示立即數,其中8個bit是真正的數據,4個bit用來表示如何rotation。更詳細的內容請參考ARM ARM文檔。
(6)這一步將修改后的new value保存在atomic_t變量中。是否能夠正確的操作的狀態標記保存在%1操作數中,也就是"=&r" (tmp)。
(7)檢查memory update的操作是否正確完成,如果OK,皆大歡喜,如果發生了問題(有其他的內核路徑插入),那么需要跳轉到lable 1那里,從新進行一次read-modify-write的操作。
-
寄存器
+關注
關注
31文章
5336瀏覽量
120232 -
cpu
+關注
關注
68文章
10855瀏覽量
211590 -
函數
+關注
關注
3文章
4327瀏覽量
62573
原文標題:Linux內核同步機制之(一):原子操作
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解linux內核中的mutex同步機制
Linux內核同步機制原子操作詳解
Linux內核同步機制mutex詳解
linux內核機制有哪些
linux內核鎖機制
你知道linux 同步機制的complete?
你了解Linux內核的同步機制?
可以了解并學習Linux 內核的同步機制
Linux內核的同步機制





 工商網監
工商網監
評論