 伯克利RISELab推出了多主體強化學習包Ray RLlib 0.6.0
伯克利RISELab推出了多主體強化學習包Ray RLlib 0.6.0
近日伯克利RISELab推出了多主體強化學習包Ray RLlib 0.6.0,并同時與伯克利BAIR合作推進多主體強化學習在不同用戶場景下的應用,將現有的單主體算法訓練拓展到用戶個性化算法的大規模訓練上。
為什么需要多主體強化學習?
在使用強化學習的過程中,多主體強化學習的想法常常縈繞在研究人員的腦海里。相較于單主體強化學習算法,多主體的方式將帶來以下優勢:對于問題更自然地解構。例如如果想要訓練一個控制移動通信蜂窩天線塔控制算法的策略,逾期使用一個超級智能體來控制城市中所有的天線,倒不如為每個天線建立獨立的模型來的自然,以為在移動通信中只有相鄰的天線及其附近的用戶才與每個站點的控制相關。具有大規模學習的潛力。首先將觀測和行動從一個單一的主體解構成多個簡單的主體不僅減少了單個智能體輸入輸出的維數,同時有效增加了在環境中訓練每一步所產生的數據量。其次將行動和觀測空間按照主體分為多個部分,其效果與時域抽象很類似,這種方法已經成功地加速了單主體條件下的學習效率。并且一些分層方法也可以利用類似多主體系統的方法來實現。最后,良好的解構還可以更好地遷移到變換的環境中,更具有適應性。而單個超級智能體在特定的環境中可能面臨過擬合的危險。
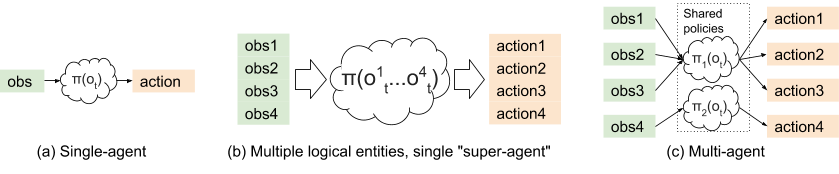
單智能體、超級智能體和多智能體強化學習的區別。
一些多智能體應用場景
在緩解交通擁堵方面,只需要控制極少量自動駕駛車輛的速度,就能大幅度提高交通流的效率。多主體強化學習就可以用于這樣的場景,在混合駕駛的情況下我們暫時無法通過單一主體來為交通燈和所有的車輛建模,而利用多主體的方法可以有效的解決大范圍內多主體間觀測和行動的實時性。下圖顯示了加入少量紅色的無人駕駛車輛,整體通行效率大幅提高。詳細報道可以閱讀傳送門>>無人駕駛與智能算法如何協作處理實際生活中的復雜交通問題?
移動通信中的蜂窩天線控制問題,基站的聯合配置可以通過優化局部使用分布和環境形態來得到,這里每一個基站就可以看作是多主體強化學習中的一個,共同覆蓋整個城市的通信服務。
在電競游戲中OpenAI Five的表現令人印象深刻,其中的智能體訓練出配合的策略來與人類抗衡。每一個AI主體都有一個獨立的神經網絡策略并與大規模的PPO(Proximal Policy Optimization)進行聯合訓練。
支持多主體的強化學習庫ray-RLlib
在了解了多主體強化學習的優勢的應用場景后,我們就來看看這一新版本的強化學習庫具有哪些優勢和特點。RLlib兼容多種強化學習分布式算法,包括:A2C / A3C, PPO, IMPALA, DQN, DDPG, 和Ape-XD等等。在接下來的部分中文章將首先探討多主體強化學習面臨的挑戰、展示如何通過現有的算法來訓練多主體策略,如何在動態和變化增加的多主體環境中實現多特定的算法。這一算法包的目的在于減小研究人員從單主體到多主體強化學習實現過程中的研究成本,加速項目的實施。
支持多主體強化學習的難點
像強化學習這樣快速變化的領域構建軟件面領著巨大的挑戰,多主體強化學習更是如此。下面讓我們通過例子來感受一下非靜態環境中多主體強化學習面臨的難點。下圖中紅色車輛的學習目標是控制車速,而藍色車輛的學習目標則是盡可能縮短途中運輸的時間。紅色的車輛在一開始就簡單的初始化為期望的固定速度。然而在多主體的環境下,其他的主體將會不斷去優化自己的目標。在這個例子下,藍色的車就會嘗試超越紅色的車。在單主體的角度下(紅色車)這會引起一系列問題。因為在紅色車看來,藍色車也是環境的一部分。藍色車超越的行為造成了動態環境的問題,這違背了單主體在Q學習和DQN中需要的馬爾科夫假設收斂的條件。
非靜態環境,兩種主體的學習目標不一致造成了環境的變化。
為了解決這一問題,人們提出了多種算法。包括LOLA,RIAI和Q-MIX。在更高的層次這些算法考慮了在強化學習過程中其他主體造成的影響。通常在訓練時使用部分中心化的方式,而執行時使用去中心化的方式。這就意味著策略網絡依賴于其他的主體。下面是Q-MIX中一個混合網絡的例子:
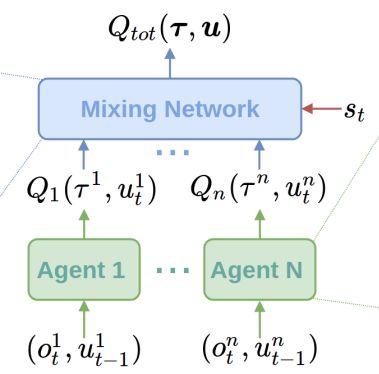
Q-MIX的網絡架構,個體的Q估計通過單一的混合網絡集成,是的最終的行動計算更有效率。
同樣,類似于A3C和PPO這類的策略梯度算法在多主體的情況下會面臨很多困難,例如信用分配問題( credit assignment problem)就會隨著個體的增加而變得復雜。例如,道路上發生了在很多自動駕駛汽車間交通擁堵,為了避免碰撞,他們會將速度設置為0,那么給主體的獎勵與速度的關系將越來越弱,使得擁堵的解決變得困難。
在上圖所示的交通擁堵中,我們不清楚哪一輛車造成問題的原因最多,解決擁堵問題我們也不知道那一輛車貢獻的最多。對于這些問題,其中一類解決辦法就是利用中心化的價值函數(下圖中的Q部分)為其他主體造成的影響建模,MA-DDPG,就屬于這類方法。通過考慮其他主體的行為,個體的優勢估計變換將會變得穩定。
MA-DDPG架構,在執行時策略只用了局域信息、但在訓練時充分利用了全局信息。
通過上面的例子可以看到,對于多主體強化學習有兩大類不同的挑戰和實現方式。有時候利用單主體強化學習算法訓練多主體策略可以取得很好的效果。例如OpenAI Five成功地結合了一個大規模的PPO和特定的網絡模型,并利用超參數”團隊精神”來共享獎勵解決多主體訓練問題,并利用共享的“主體間最大池化”為模型提供共享的觀測信息。
利用RLlib進行多主體訓練
為了在多主體的情況下同時考慮特定算法和標準單主體強化學習算法,RLlib使用了兩條原則來將這一過程大大簡化:策略被表示成了對象:在RLlib中所有基于梯度的算法被視為圖對象,其中包含了策略模型、后處理函數以及策略損失等。這一策略圖對象充分適應分布式架構對于初始環境、經驗收集和改善策略等方面的處理。策略對象是黑箱:為了支持多主體運行,RLlib僅僅需要管理每個環境中多主體策略圖的創建和執行即可,并在策略優化時加總損失。策略圖對象被視為一個黑箱過程,這意味著它可以使用任意的網絡框架來實現,無論是TensorFlow或者pytorch都可以。此外,策略圖在使用特定算法時可以共享變量和層而無需而外的架構支持。
多主體環境模型
下面讓我們來感受一下這一算法包是如何工作的。在一個多主體的環境中,每一步將會有多個行動產生,下面控制交通流量的例子引入了多個控制量(自動駕駛車和交通燈)來減少高速路上的擁堵。在這一場景中,每個主體行為都表現出不同的時間尺度;環境中主體的行為是一個時間過程。
工具包中的多主體環境可以為多個獨立的主體建模,可以為不同的主體分配不同的策略.可以看到交通燈、和不同的自動駕駛汽車使用了不同的策略
利用多主體環境接口,可以得到多個主體在每一步的觀測和獎勵值:
# Example: using a multi-agent env> env = MultiAgentTrafficEnv(num_cars=20, num_traffic_lights=5)# Observations are a dict mapping agent names to their obs. Not all# agents need to be present in the dict in each time step.> print(env.reset()) { "car_1": [[...]], "car_2": [[...]], "traffic_light_1": [[...]], } # Actions should be provided for each agent that returned an observation.> new_obs, rewards, dones, infos = env.step( actions={"car_1": ..., "car_2": ...})# Similarly, new_obs, rewards, dones, infos, etc. also become dicts> print(rewards) {"car_1": 3, "car_2": -1, "traffic_light_1": 0}# Individual agents can early exit; env is done when "__all__" = True> print(dones) {"car_2": True, "__all__": False}
任何OpenAI gym中的離散的字典、元組或者Box觀測空間都可以被用于這些獨立的個體上,這使得每個主體多傳感器輸出成為可能(也包括了主體間的通信過程)在API中包含了多層級的API,從單主體的共享策略到多策略,再到完全用戶定制化的策略優化:
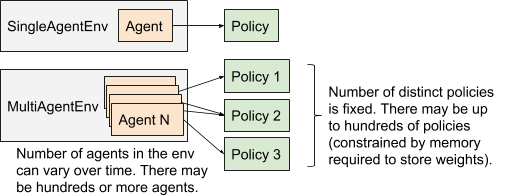
多主體執行模型與單主體執行模型的比較
API分為了三個層次,分別是多主體和共享策略、多主體多策略以及定制化的訓練策略。使用這三種不同的策略可以在不同的層次針對不同的場景來訓練模型。
性能
RLlib設計的初衷就在于大規模集群多主體的使用,但同時研究人員了為單核機器設計了較好的接口,是的小型電腦也可以有效地執行多主體APIs。下圖展示了多主體策略的表現。其中基準是一個小型的浮點數適量,策略網絡利用了16*16的小型全連接網絡。并未每一個主體分配策略池中的策略。結果表明,RLlib在單CPU上,為單個環境中的1萬個主體每秒管理7萬次行動,當矢量化關閉時性能下降了近四十倍。
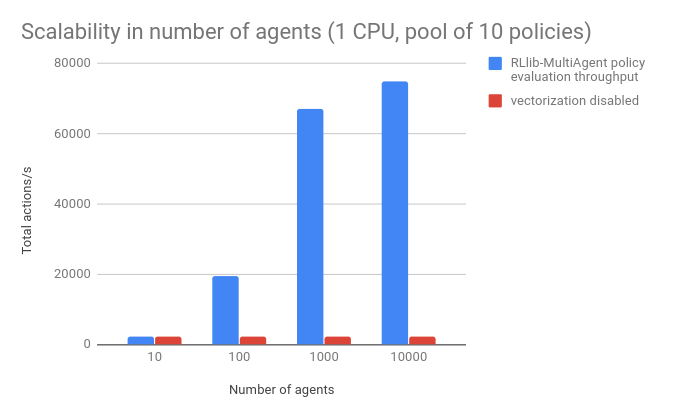
同時也測試了1-50個不同策略數量下的表現:
希望這工具能為強化學習領域的小伙伴們帶來一種對于多主體強化學習迅速和通用的解決框架,如果你希望使用這個工具包,只需要使用pip安裝即可:pip install ray[rllib]更多詳細資料請參看:doc: https://ray.readthedocs.io/en/latest/rllib.htmllab:https://rise.cs.berkeley.edu/blog/scaling-multi-agent-rl-with-rllib/
-
智能體
+關注
關注
1文章
144瀏覽量
10575 -
強化學習
+關注
關注
4文章
266瀏覽量
11246
原文標題:伯克利推出大規模多主體強化學習算法庫
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Facebook推出ReAgent AI強化學習工具包

美國勞倫斯伯克利國家實驗室開發出“病毒發電”元件
伯克利(Berkeley)聯網程序代碼介紹
華為投入1百萬美元和伯克利合作推進 AI 技術
谷歌和UC伯克利的新式Actor-Critic算法快速在真實世界訓練機器人
推特公開宣布了伯克利機器人學習實驗室最新開發的機器人BLUE
UC伯克利新機器人成果:靈活自由地使用工具
加州大學伯克利分校研發可以操控的機器人
美國伯克利市考慮2027年出臺汽油車禁售令
《自動化學報》—多Agent深度強化學習綜述






 工商網監
工商網監
評論