 關于機器學習研究者和從業者的12個寶貴經驗
關于機器學習研究者和從業者的12個寶貴經驗
01 “表征+評估+優化”構成機器的主要內容
表征(Representation):分類器必須用計算機可以處理的形式化語言來表示。相反地,為訓練模型選擇一個表征就等同于選擇可訓練分類器的集合。這個集合稱為訓練模型的「假設空間」。如果分類器不在「假設空間」中,那么它就不能由訓練所得到。一個相關的問題是如何表征輸入,即使用哪些特征。
評估(Evaluation):需要一個評估函數來區分分類器的好壞。算法內部使用的評估函數可能與分類器優化的外部評估函數不同,這是為了便于優化,并且是由我們下一節所要討論的問題導致的。
優化(Optimization):我們要用一種方法搜索得分最高的分類器。優化方法的選擇對于提升模型的效率非常關鍵。另外,如果評估函數具有一個以上的最優值,則優化方法有助于確定最后產生的分類器。新的訓練模型一開始常常使用現有的優化器,后來常會轉而使用自定義的優化器。
02 “泛化能力”很關鍵,“測試數據”驗證至關重要
機器學習的主要目標是對訓練集之外的樣本進行泛化。因為無論有多少數據,都不太可能在測試中再次看到完全相同的例子。在訓練集上具有良好表現很容易。機器學習初學者最常犯的錯誤是把模型放在訓練數據中進行測試,從而產生成功的錯覺。
如果被選擇的分類器在新的數據上進行測試,一般情況,結果往往和隨機猜測相差無幾。所以,如果你雇傭他人建立分類器,一定要留一些數據給你自己,以便在他們給你的分類器中進行測試。相反,如果有人雇傭你建立一個分類器,請保留一部分數據對你的分類器進行最終測試。

03 僅有數據是不夠的,知識相結合效果更好
把泛化能力作為目標,會又另一個后果:只有數據是不夠的,無論你擁有多少數據。這是否讓人沮喪。那么,我們怎么能奢求它學到東西呢?
不過,現實世界中我們想學習的函數并不都是從數學上可能的函數中提取出來的!實際上,使用一般假設——例如平滑性、相似樣本有相似分類、有限的依賴性或有限復雜度——往往能做得足夠好,這也正是機器學習能如此成功的大部分原因。
正如演繹一樣,歸納(訓練模型所做的)是一個知識杠桿——它將少量知識輸入轉化為大量知識輸出。歸納是一個比演繹更為強大的杠桿,僅需更少的知識就能產出有用的結果。不過,它仍然需要大于零的知識輸入才能工作。正如任何一個杠桿一樣,輸入得越多,得到的也越多。
這樣回想起來,訓練過程中對知識的需求沒什么好驚訝的。機器學習并非魔術,它無法做到無中生有,它所做的是舉一反三。如同所有的工程一樣,編程需要做大量的工作:我們必須從頭開始構建所有的東西。訓練的過程更像是耕種,其中大部分工作是自然完成的。農民將種子與營養物質結合起來,種植作物。訓練模型將知識與數據結合起來,編寫程序。
04 “過擬合”讓機器學習效果產生錯覺
如果我們所擁有的知識和數據不足以完全確定正確的分類器,分類器(或其中的一部分)就可能產生「錯覺」。所獲得的分類器并不是基于現實,只是對數據的隨機性進行編碼。這個問題被稱為過擬合,是機器學習中棘手的難題。如果你的訓練模型所輸出的分類器在訓練數據上準確率是 100%,但在測試數據上準確率只有 50%,那么實際上,該分類器在兩個集合上的輸出準確率總體可能約為 75%,它發生了過擬合現象。
在機器學習領域,人人都知道過擬合。但是過擬合有多種形式,人們往往不能立刻意識到。理解過擬合的一種方法是將泛化的誤差進行分解,分為偏差和方差。偏差是模型不斷學習相同錯誤的傾向。而方差指的是不管真實信號如何,模型學習隨機信號的傾向。線性模型有很高的偏差,因為當兩個類之間的邊界不是一個超平面時,模型無法做出調整。決策樹不存在這個問題,因為它們可以表征任何布爾函數。但是另一方面,決策樹可能方差很大:如果在不同訓練集上訓練,生成的決策樹通常差異很大,但事實上它們應該是相同的。
交叉驗證可以幫助對抗過擬合,例如,通過使用交叉驗證來選擇決策樹的最佳規模用于訓練。但這不是萬能的,因為如果我們用交叉驗證生成太多的參數選擇,它本身就會開始產生過擬合現象。
除交叉驗證之外,還有很多方法可以解決過擬合問題。最流行的是在評估函數中增加一個正則化項。舉個例子,這樣一來就能懲罰含更多項的分類器,從而有利于生成參數結構更簡單的分類器,并減少過擬合的空間。另一種方法是在添加新的結構之前,進行類似卡方檢驗的統計顯著性檢驗,在添加新結構前后確定類的分布是否真的具有差異。當數據非常少時,這些技術特別有用。
盡管如此,你應該對某種方法完美解決了過擬合問題的說法持懷疑態度。減少過擬合(方差)很容易讓分類器陷入與之相對的欠擬合誤差(偏差)中去。如果要同時避免這兩種情況,需要訓練一個完美的分類器。在沒有先驗信息的情況下,沒有任何一種方法總能做到最好(天下沒有免費的午餐)。
05 機器學習中最大的問題就是“維度災難”
除了過擬合,機器學習中最大的問題就是維度災難。這一名詞是由 Bellman 在 1961 年提出的,指的是當輸入維度很高時,許多在低維工作正常的算法將無法正常工作。但是在機器學習中,它的意義更廣。隨著樣本維度(特征數量)的增加,進行正確泛化變得越來越難,因為固定大小的訓練集對輸入空間的覆蓋逐漸縮減。
高維的一般問題是,來自三維世界的人類直覺通常不適用于高維空間。在高維度當中,多元高斯分布的大部分數據并不接近平均值,而是在其周圍越來越遠的「殼」中;此外,高維分布的大部分體積分布在表面,而不是體內。
如果恒定數量的樣本在高維超立方體中均勻分布,那么在超越某個維數的情況下,大多數樣本將更接近于超立方體的一個面,而不是它們的最近鄰。
此外,如果我們通過嵌入超立方體的方式逼近一個超球面,那么在高維度下,超立方體幾乎所有的體積都在超球面之外。這對于機器學習來說是個壞消息,因為一種類型的形狀常常可以被另一種形狀所逼近,但在高維空間中卻失效了。
建立二維或三維分類器容易;我們可以僅通過視覺檢查找出不同類別樣本之間的合理邊界。但是在高維中,我們很難理解數據的分布結構。這又反過來使設計一個好的分類器變得困難。簡而言之,人們可能會認為收集更多的特征一定不產生負面作用,因為它們最多只是不提供有關分類的新信息而已。但事實上,維度災難的影響可能大于添加特征所帶來的利益。
06 “理論保證”與“實際出入”的相互關系
機器學習論文中充斥著理論保證。最常見的保證就是關于保持模型良好泛化能力的訓練樣本數量約束問題。首先,該問題顯然是可證的。歸納通常與演繹相對:通過演繹,你可以確保結論是正確的; 在歸納中,所有臆想都被摒棄。或許這就是傳世的古老智慧。近十年的主要突破就是認識到歸納的結果是可證的這一事實,尤其在我們愿意給出概率保證時。
必須斟酌這類約束意味著什么。這并不意味著,如果你的網絡返回與某個特定訓練集一致的假設,那么這個假設就可能具有很好的泛化能力。而是,給定一個足夠大的訓練集,你的網絡很可能會返回一個泛化能力好的假設或無法得到一致的假設。這類約束也沒有教我們如何選擇一個好的假設空間。它只告訴我們,如果假設空間包含好的分類器,那么隨著訓練集的增大,網絡訓練出一個弱分類器的概率會減小。如果縮小假設空間,約束條件作用會增強,但是訓練出一個強分類器的概率也會下降。
另一種常見的理論保證是漸進性:假如輸入的數據規模是無窮大的,那么網絡肯定會輸出一個強分類器。聽起來靠譜,但是由于要保證漸近性,選擇某個網絡而非另一個就顯得過于輕率。在實踐中,我們很少處于漸近狀態。由上面討論的偏差 - 方差權衡可知,如果網絡 A 在具有海量數據時比網絡 B 好,則在有限數據情況下,B 往往比 A 好。
理論保證在機器學習中存在的意義不僅僅是作為評判實際決策的標準,而且是理解的方法及設計算法的動力。鑒于此,它十分有用。事實上,這么多年以來,正是理論聯系實際促進了機器學習的飛躍式進步。注意:學習是一個復雜的現象,它在理論上說得通,在實際工作中可行,也并不表示前者是導致后者的原因。
07 “特征工程”是機器學習的關鍵
最后,有些機器學習項目大獲成功,有些卻失敗了。這是什么造成的?最重要的影響因素就是使用的特征。如果你獲取到很多獨立的且與所屬類別相關的特征,那么學習過程就很容易。相反,若某一個類是特征的極其復雜的函數,你的模型可能無法學習到該函數。通常來說,原始數據格式很不適合學習,但是可以基于它來構建特征。這正是機器學習項目最重要的部分,通常也是最有趣的部分,直覺、創造力、「魔術」和技術同樣重要。
初學者常常會驚訝于機器學習項目實際上花在機器學習上的時間很少。但是當你將收集、整合、清洗和預處理數據以及將數據重構成特征過程中解決錯誤等瑣事所消耗的時間考慮在內就不奇怪了。而且,機器學習并不只是構建數據集跑一次模型就沒事了,它通常是一個跑模型、分析結果、修改數據集/模型的迭代式過程。學習是其中最快的部分,但這取決于我們已經可以熟練運用它!特征工程因為針對特定的領域,所以很難做,而模型架構的適用范圍更廣泛。但是,這二者之間并沒有清晰的界線,這通常可以解釋那些整合了領域知識的模型具有更好的性能。
08 記住:數據量比算法還重要
在計算機科學的大多數領域,時間和內存是兩大緊缺資源。但在機器學習中,數據集儼然是第三個緊缺資源。隨著時間的推移,瓶頸之爭也在不斷改變。在 20 世紀 80 年代,數據通常是瓶頸。而如今時間更為寶貴。我們今天有海量的數據可用,但是卻沒有充足的時間去處理它,這些數據因此被擱置。
這就產生了一個悖論:即使在原則上講,大量的數據意味著可以學習到更復雜的分類器,但在實踐中,我們往往采用更簡單的分類器,因為復雜的分類器意味著更長的訓練時間。部分解決方案是提出可以快速學習到復雜分類器的方法,且今天在這一方向上確實取得了顯著的進展。
使用更智能的算法的收益不如期望的部分原因是,第一次取近似值時,它跟其它算法無異。當你認為表征方式之間的區別與規則、神經網絡之間的區別類似時,這會讓你驚訝。但事實是,命題規則可以輕易地編碼進神經網絡,并且其它的表征方式之間也有類似的關系。模型本質上都是通過將近鄰樣本分到相同的類別而實現的,關鍵差異在于「近鄰」的含義。
對于非均勻分布的數據,模型可以產生廣泛不同的邊界,同時在重要的區域(具有大量訓練樣例的區域,因此也是大多數文本樣例可能出現的區域)中產生相同的預測。這也能解釋為什么強大的模型可能是不穩定的但仍然很準確。
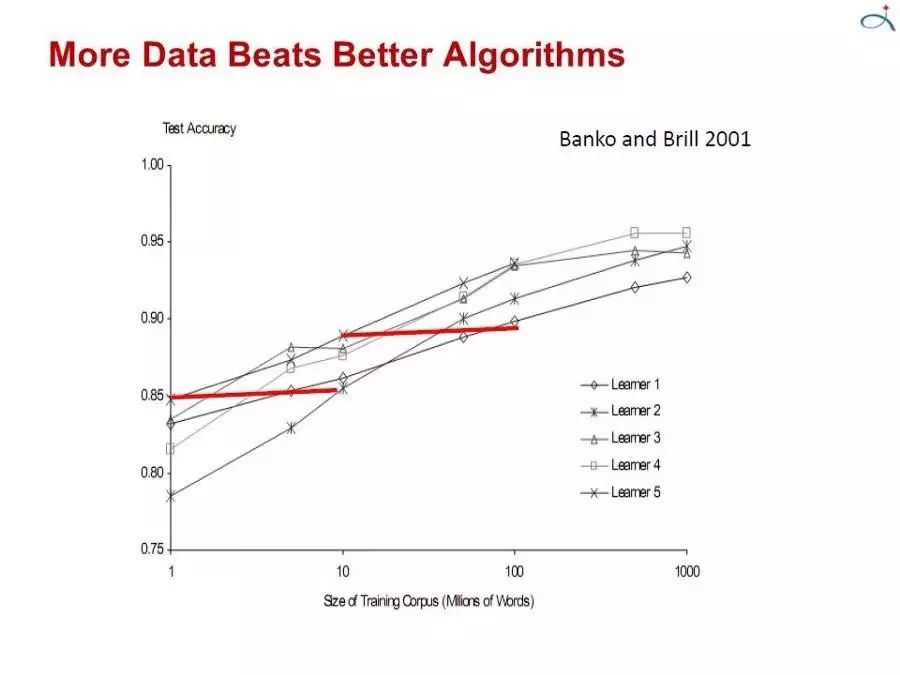
一般來說,我們首先要考慮最簡單的模型(例如,先考慮樸素貝葉斯而非 logistic 回歸,先考慮 K-近鄰而非支持向量機)。模型越復雜越誘人,但是它們通常很難使用,因為你需要調整很多的節點以獲得好的結果,同時,它們的內部構造極其不透明。
模型可以分為兩種主要類型:一種是規模固定的模型,例如線性分類器,另一種是表征能力隨數據集增強的模型,例如決策樹。固定規模的模型只能利用有限的數據。規模可變的模型理論上可以擬合任何函數,只要有足夠大的數據集,但是現實很骨感,總存在算法的局限性或計算成本。而且,由于維度災難,現有的數據集可能不夠。鑒于這些原因,更智能的算法—那些充分利用數據和計算資源的算法--如果你愿意努力去調試,最終會得到好的結果。
在設計模型與學習分類器之間并沒有十分清晰的界線;但是,任何給定的知識點都可以編碼進模型或從數據中學習到。因此,模型設計往往是機器學習項目中的重要組成部分,設計者最好擁有相關專業背景。
09 “單模型”很難實現最優,“多模型集成”才是出路
在機器學習發展的早期,大家都有各自喜愛的模型,用一些先驗的理由說明它的優越性。研究員對模型開發了大量的變體并從中挑選一個最優的模型。隨后,系統的經驗比較表明,最好的模型隨應用的改變而改變,開始出現了包含許多不同模型的系統。
現在的研究開始嘗試調試多個模型的不同變體,然后挑選表現最好的那一個。但研究人員開始注意到,不選擇找到的最佳變體,而是結合多個變體,卻得到了更好的結果(通常會好很多),而且這沒有增加工作量。
現在,模型集成已經是標準方法。其中最簡單的技術叫 bagging 算法,我們僅通過重采樣來生成訓練數據集的隨機變體,再基于這些變體分別學習分類器,并通過投票整合這些分類器的結果。此法的可行性在于它大幅減少了方差,且只微微提升了一點偏差。
在 boosting 算法中,訓練樣例有權重,而且這些權重各不相同,因此每個新分類器都把重點放在前面的模型會出錯的樣例上。在 stacking 算法中,每個單獨的分類器的輸出作為「高層」模型的輸入,這些高層模型會以最佳方式組合這些模型。
還有很多其它的方法,就不一一列舉了,但是總的趨勢是規模越來越大的集成學習。在 Netflix 的獎金激勵下,全世界的團隊致力于構建最佳視頻推薦系統。隨著競賽的推進,競賽團隊發現通過結合其它團隊的模型可以獲得最佳結果,同時這也促進團隊的合并。冠軍和亞軍模型都是由 100 多個小模型組成的集成模型,兩個集成模型相結合可進一步提高成績。毫無疑問,將來還會出現更大的集成模型。
10 “簡單”不能代表是“準確”
奧卡姆剃刀原理指出,如無必要,勿增實體。在機器學習中,這通常意味著,給定兩個具有相同訓練誤差的分類器,兩者中較簡單的分類器可能具有最低的評估誤差。關于這一說法的佐證在文獻中隨處可見,但實際上有很多反例用來反駁它,「沒有免費午餐」定理質疑它的真實性。
我們在前文中也看到了一個反例:集成模型。即使訓練誤差已經達到零,通過增加分類器,增強集成模型的泛化誤差仍然可以繼續減少。因此,與直覺相悖,模型的參數數量與其過擬合趨勢并沒有必然的聯系。
一個巧妙的觀點是將模型復雜性等同于假設空間的大小,因為較小的空間允許用較短的編碼表征假設。類似理論保證部分中的界限可能被理解成較短的假設編碼有更好的泛化能力。通過在有先驗偏好的空間中對假設進行較短的編碼,我們可以進一步細化這一點。
但是把這看作準確率和簡單性之間的權衡的證明則是循環論證:我們通過設計使偏愛的假設更簡單,如果它們準確率不錯,那是因為偏愛假設的正確,而不是因為在特定表征下假設的「簡單」。
11 “可表征”并不代表“可學習”
所有運用于非固定規模的模型表征實際上都有「任意函數都可以使用該表征來表示或無限逼近」之類的相關定理。這使得某表征方法的偏好者常常會忽略其它要素。然而,僅憑可表征性并不意味著模型可以學習。例如,葉節點多于訓練樣本的決策樹模型就不會學習。在連續的空間中,通常使用一組固定的原語表征很簡單的函數都需要無限的分量。
進一步講,如果評估函數在假設空間有很多局部最優點(這很常見),模型可能就找不到最優的函數,即使它是可表征的。給定有限的數據、時間及存儲空間,標準的模型只能學到所有可能函數集的一個很小的子集,且這個子集隨所選的表征方法的不同而不同。因此,關鍵問題不在「模型是否可表示」,而「模型是否可學習」以及嘗試不同的模型(甚至是集成模型)是很重要的。
12 “相關性”并非就是“因果關系”
相關性并不意味著因果關系這一點被頻繁提起,以至于都不值得再批評。但是,我們討論的某類模型可能只學習相關性,但是它們的結果通常被看作是表征因果關系。有問題嗎?如果有,那么大家為何還這么做?
通常是不對的,預測模型學習的目標是用它們作為行動的指南。當發現人們在買啤酒的時候也會買紙尿布,那么把啤酒放在紙尿布旁邊或許會提高銷量。
但如果不實際進行實驗則很難驗證。機器學習通常用于處理觀測數據,其中預測變量不受模型的控制,和實驗數據相反(可控的)。一些學習算法也許可以通過觀測數據挖掘潛在的因果關系,但是實用性很差。另一方面,相關性只是潛在的因果關系的標識,我們可以用它指導進一步的研究。
-
計算機
+關注
關注
19文章
7513瀏覽量
88162 -
機器學習
+關注
關注
66文章
8423瀏覽量
132752
發布評論請先 登錄
相關推薦
哪些專業適合學習嵌入式開發?
求問帖!靜電消除器在電子半導體領域的具體應用與需求!
【「大話芯片制造」閱讀體驗】+內容概述,適讀人群
東方通聯合openEuler社區即將開啟云原生開源中間件 Meetup北京站
學嵌入式好找工作嗎?
什么是機器學習?通過機器學習方法能解決哪些問題?

名單公布!【書籍評測活動NO.50】親歷芯片產線,輕松圖解芯片制造,揭秘芯片工廠的秘密
AI干貨補給站 | 深度學習與機器視覺的融合探索

大數據從業者必知必會的Hive SQL調優技巧
半導體封裝材料全解析:分類、應用與發展趨勢!






 工商網監
工商網監
評論