 如何將語音識別、計算機視覺和自然語言處理結合起來幫助精神健康患者
如何將語音識別、計算機視覺和自然語言處理結合起來幫助精神健康患者
本文作者Albert Haque,Michelle Guo,Adam S Miner和Li Fei-Fei。文章主要介紹了李飛飛團隊的最新研究成果:一種基于機器學習的抑郁癥癥狀嚴重程度測量方法,該方法使用了視頻、音頻和文本數據集,以及因果卷積神經網絡模型,準確率超過80%。
抑郁癥現在是一個全球性問題:已經有3億多人患有抑郁癥,嚴重時可導致自殺。
由于社會輿論、高昂成本和治療缺位,60%的精神性疾病患者沒有獲得任何精神健康服務。就抑郁癥來說,有效且高效的診斷服務依賴于臨床癥狀檢測,但是,抑郁癥癥狀的自動檢測正在打破這一傳統,無需臨床檢測也可以潛在地提高診斷準確性和有效性,從而帶來更快速的干預治療。
在本文中,我們提出了一種機器學習方法來測量抑郁癥癥狀的嚴重程度。此多模態方法使用了3D面部表情和口語,這些數據在現在的手機上很常見。結果顯示,在經過臨床驗證過的病人健康問卷(PHQ, Patient Health Questionnaire)水平上,它的的平均誤差僅有3.67分(相對誤差為15.3%);對于檢測重度抑郁癥,模型則顯示出了83.3%的敏感性和82.6%的特異性。
總的來說,本文展示了如何將語音識別、計算機視覺和自然語言處理結合起來幫助精神健康患者,以及相關的從業人員。這項技術還可以應用到手機上,并促進低成本和普惠精神健康服務發展。
1 介紹
一般來說,精神障礙患者會由基礎醫療服務醫生等人員進行檢查,包括基礎醫療服務醫生。然而,相比身體疾病,精神障礙更難被發現。而且,諸如社會輿論、經濟成本和治療缺位等治療障礙又加劇了精神健康的負擔。為了解決醫療服務中這些根深蒂固的障礙,人們呼吁采取可推廣的方法來檢測精神健康癥狀。如果成功了,早期檢測可能影響到60%未接受治療的精神病成年人,并讓他們有機會獲得治療。
在臨床實踐中,醫生首先通過面對面臨床問診測量抑郁癥癥狀的嚴重程度,以此來甄別患者的抑郁癥癥狀。在這些問診中,臨床醫生同時評估抑郁癥癥狀的語言和非語言指標:包括音高單調、語速降低、音量降低、手勢較少和總向下看,如果這些癥狀持續了兩周,可以認為患者重度抑郁癥發作。
在臨床人群中,結構化問卷早已用來評估抑郁癥狀的嚴重程度。最常見的問卷就是病人健康問卷(PHQ)。這種已被臨床驗證的工具會在多個個人維度上測量抑郁癥癥狀的嚴重程度。評估癥狀的嚴重性雖然需要很多時間,但這對于初步診斷和進一步改善治療服務都至關重要。
而基于人工智能的解決方案可以解決這些獲得治療的重重障礙。
圖1:多模態數據。對于每個臨床問診,我們使用:(a)3D面部掃描的視頻,(b)音頻錄音,可轉化為可視化的log-mel聲譜圖,以及(c)患者講話的轉錄文本。我們的模型使用了這三種模式預測抑郁癥癥狀的嚴重程度。
我們設想了一種基于人工智能的解決方案:其中的抑郁個體們可以接受循證精神健康服務,同時又避免了現有的治療獲取障礙。這種解決方案可以利用多模態傳感器或者文本消息(就是現代智能手機上常見的那些)來增多及時和效率高的癥狀篩查。對話式AI是另一種潛在的解決方案。我們的希望是自動化反饋將(i)為可能抑郁的個體提供可操作的反饋,并(ii)通過包括視覺、音頻和語言信號來改進臨床醫生的抑郁自動化篩查工具。
貢獻:我們提出了一種機器學習方法通過去識別化的多模態數據來測量抑郁癥癥狀的嚴重程度。我們模型的輸入是面部關鍵點的音頻、3D視頻以及患者在臨床問診中的說話轉錄文本。我們的模型的輸出要么是PHQ評分,要么是表明重度抑郁癥的分類標簽。我們的方法利用了因果卷積網絡(C-CNN),將句子們“概括”為單個嵌入,然后使用這個嵌入來預測抑郁癥癥狀的嚴重程度。在我們的實驗中,我們展示了我們基于句子的模型是如何與單詞級嵌入以及前人的工作發生相互關系的。
2 數據集
我們使用了DAIC-WOZ數據集,其中包含了抑郁癥和非抑郁癥患者的音頻和3D面部掃描。對于每一個患者,我們都提供了PHQ-8評分。這個語料庫是用半結構化臨床問診數據創建的。在半結構化臨床問診中,病人與遙控數字助理對話,臨床醫生會通過數字助理詢問一系列專門針對抑郁癥癥狀的問題。數字助理用查詢的方式提問每一個病人(例如,“你多久去一次你的家鄉?”),并得到對話反饋(例如“酷”)。我們一共收集了來自142名患者的189次臨床問診的共50小時的數據。我們論文的結果來自驗證集。更多的細節可以在附錄中找到。這項工作中使用的數據不包含受保護的健康信息(PHI)。數據集管理員從音頻錄音和轉錄中刪除了對個人姓名、具體日期和地點的信息。3D面部掃描是低分辨率的(68像素),并不包含足夠的信息來識別出個人,只包含足夠的信息來測量面部運動,比如眼睛、嘴唇和頭部運動。雖然數據集是公開可用的,但是在未來,將此方法應用于其他數據集的研究人員可能會遇到PHI,那時他們應該合理的設計實驗。
3 模型
我們的模型由兩個技術部分組成:(i)一個句子級的“概要”嵌入(嵌入的目的是“概括”一個可變長度的序列,將它變為固定大小的數字向量。)和(ii)一個因果卷積網絡(C-CNN)。概覽如圖2所示。
句子級嵌入:幾十年來,單詞和音素級嵌入一直是編碼文本和語音的必備因素。雖然這些嵌入在某些任務中表現不錯,但它們的句子級建模能力有限。這是因為單詞和音素級嵌入智能捕獲一個狹窄的時間范圍,通常最多有幾百毫秒。在這項工作中,我們提出了一種新的多模態句子級嵌入,這使得我們能夠捕獲更長期的聲音、視覺和語言元素。
圖2:我們的方法:學習一個多模態句子級嵌入。總的來說,我們的模型是因果卷積神經網絡。輸入到我們的模型是:音頻,3D面部掃描和文本。多模態句子級嵌入被裝到了抑郁癥分類器和PHQ回歸模型里(上面沒有顯示)。
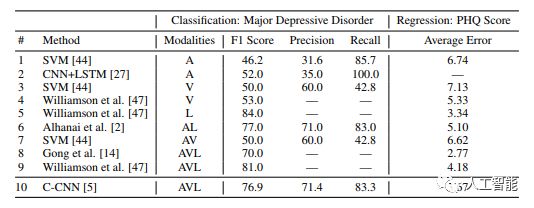
表1:檢測抑郁癥的機器學習方法的比較。評估了兩項任務:(i)重度抑郁癥的二元分類和(ii)PHQ評分回歸。模態:A:音頻,V:視覺,L:語言(文本),AVL:三者組合。對于前人的工作,數字來源于原始出版物中的報告。破折號表示未被報告度量。
因果卷積網絡:在臨床問診中,患者可能會結巴,并且經常在說話時停頓。這導致了抑郁癥患者視聽錄像比非抑郁癥患者時間更長。近來,因果卷積網絡(C-CNN)在長序列上的表現優于遞歸神經網絡(RNNs)。有作者甚至表明,RNNs可以由完全前反饋網絡(即CNNs)來近似。結合擴張性卷積,C-CNN已經可以為抑郁癥篩查問診建立長序列模型。為了更全面地比較C-CNN和RNN,我們建議請讀者查閱Bai et al。
4 實驗
我們的實驗分為兩部分。首先,將我們的方法與現有測量抑郁癥癥狀嚴重程度的工作進行了比較(表1)。我們預測PHQ評分,并輸出關于患者是否患有重度抑郁癥的二元分類,通常PHQ評分大于或等于10。其次,我們對我們的模型進行消融研究,以更好地理解多模態和句子級嵌入的效果(表2)。數據格式、神經網絡結構和關鍵超參數可以在附錄中找到。
4.1 抑郁癥癥狀嚴重程度的自動測量
在表1中,我們將我們的方法與前人在測量抑郁癥癥狀嚴重程度方面的工作進行了比較。我們的方法與前人工作的一個區別在于我們的方法不依賴于問診情景。前人的工作在很大程度上取決于問診情境,比如所問問題的類型,而我們的方法接受沒有這種元數據的句子。雖然額外的上下文通常對模型有幫助,但是它可能引入技術性挑戰,比如每個上下文分類的訓練樣本太少。我們方法的另一個區別是使用原始輸入模態:音頻、視覺和文本。前人的工作使用的是工程化的特征,比如最小/最大音調和詞頻。
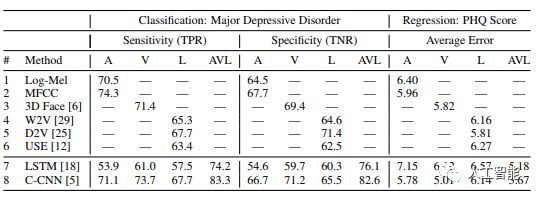
表2:消融研究。1-2行是手工制作的嵌入,3-6行是前期訓練的嵌入,7-8行表示我們學習的句子級嵌入。模態:A:音頻,V:視覺,L:語言(文本),AVL:三者組合。TPR和TNR分別表示真陽性率和真陰性率。輸入到7-8行的是log-mel聲譜圖、3D面部和Word2Vecs的序列。
4.2 消融研究
在表2中,1-6行表示手工制作的或前期訓練的句子級嵌入。也就是說,整個輸入語句(音頻、3D面部掃描和轉錄)被概括為一個向量。然而,我們建議通過輸入學習一個句子級嵌入。這些顯示在7和8行里。要注意,我們的方法確實使用了手工制作和前期訓練的單詞級嵌入作為輸入。然而,在內部,我們的模型學習句子級嵌入。在前期的句子級嵌入工作之后,再簡單計算1-6行的平均值。為了學習句子級嵌入,我們評估了:(i)長短期記憶和(i i)因果卷積網絡。
5 討論
在我們的工作適用于未來的研究之前,有一些問題需要考慮。
首先,雖然一個人控制著數字助理,但是數據是從人與計算機的訪談中收集的,而不是人與人之間。研究顯示,與真人相比,患者與助理交談時對公開秘密的恐懼更小,并且表現出更高的情感強度。人們通過向聊天機器人表露情感還可以體驗到心理上的安慰。
第二,雖然它通常用于治療方案設置和臨床試驗,但癥狀嚴重程度評分(PHQ)與抑郁癥的正式診斷不同。我們的工作旨在加強現有的臨床方法,而不是發布一個正式的診斷。
最后,雖然預先存在的嵌入方便使用,但是最近的研究表明這些向量可能包含由于基礎訓練數據引起的誤差。減小誤差超出了我們的工作范圍,但對于提供敏感的診斷和治療至關重要。
未來的工作可以更好地利用縱向和時間信息,例如相隔數周或數月的問診中的抑郁癥評分。搞清楚為什么模型會做出某些預測也是很有價值的。諸如3D人臉上的置信度圖譜和音頻片段的“有用性”評分等可視化技術也可能會帶來新的見解。
總的來說,我們提出了一種結合語音識別、計算機視覺和自然語言處理技術的多模態機器學習方法。我們希望這項工作將激勵其他人建立基于人工智能并用來了解抑郁癥以外的心理健康障礙的工具。
致謝
這項研究得到了美國國立衛生研究院、國家高級轉化科學中心、臨床和轉化科學促進中心的支持。本文內容僅由作者負責,并不一定代表NIH的官方觀點。
A 附錄
A.1 數據格式
完整的數據細節可以在原始數據集網站找到。音頻是用16kHz的頭戴式麥克風記錄。視頻被微軟Kinect以每秒30幀的速度記錄。使用OpenFace提取了總共68個三維面部關鍵點。音頻被數據集管理員轉錄并被分成具有毫秒級時間戳的句子和短語。我們使用數據集的train-val分割:訓練(107名患者),驗證(35名患者)。注意,當一個測試集存在時,標簽不是公開的。我們規范了轉錄中的俚語。比如,bout被翻譯成about,till被翻譯成until,lookin被翻譯成looking。所有文本都被小寫,數字也規范化(例如,24代表二十四)。
A.2 實現細節
A.2.1 實驗1:自動測量抑郁癥癥狀的嚴重程度
輸入“我們的方法”,比如如下的因果卷積神經網絡:
? 音頻:帶有80個mel過濾器的log-mel聲譜圖。
? 視覺:68個三維面部特征點。
? 語言:Word2VEC嵌入。
網絡結構是一個10層的因果卷積網絡,內核大小為5,每層有128個隱藏節點。對于所有非線性層,歸零概率為0.5。損失目標是用于分類的二元交叉熵,以及用于回歸的平均方差。模型采用Adam優化器進行優化,β1=0.9,β2=0.999,L2的權重衰減是1e-4。最初的學習率為1e-3和1e-5,分別用來分類和回歸。使用的批量大小為16。該模型在一塊NVIDIA V100 GPU上訓練,它的最大訓練次數為100。我們的模型用Pytorch實現。
A.2.2 實驗2:消融研究
對于表2,每一行的詳細信息如下:
1.用80個mel過濾器計算log-mel聲譜圖。
2.用13個結果值計算mel-frequency倒譜系數。
3.數據集總共提供了68個三維面部關鍵點,它們是用OpenFace提取的。
4.Word2VEC向量使用谷歌公開的Word2VEC模型和Gensim Python庫計算,每個向量的長度為300。
5.Doc2Vec向量也使用Gensim計算,每個向量的長度為300。
6.通用句子級嵌入使用公開發行版的Tensorflow計算,每個向量的長度為512。
7.LSTM由10層和128個隱藏單元組成,并且還用附錄A.2.1中所述的相同批量大小,優化器等進行優化。
8.我們的因果卷積神經網絡模型與附錄A.2.1中所概述的模型相同。公共代碼用于實現LSTM和因果CNN的核心網絡結構的構建。
-
語音識別
+關注
關注
38文章
1739瀏覽量
112635 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13553
原文標題:李飛飛團隊最新成果:通過口語和3D面部表情評估抑郁癥嚴重程度
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
自然語言處理包括哪些內容 自然語言處理技術包括哪些
四軸姿態怎么和電機結合起來
如何把庫函數寫的文件和寄存器寫的文件結合起來用?
【推薦體驗】騰訊云自然語言處理
將微機原理與單片機結合起來
什么是人工智能、機器學習、深度學習和自然語言處理?
AI:計算機視覺與自然語言處理融合的研究進展





 工商網監
工商網監
評論