 量化深度強化學習算法的泛化能力
量化深度強化學習算法的泛化能力
OpenAI近期發布了一個新的訓練環境 CoinRun,它提供了一個度量智能體將其學習經驗活學活用到新情況的能力指標,而且還可以解決一項長期存在于強化學習中的疑難問題——即使是廣受贊譽的強化算法在訓練過程中也總是沒有運用監督學習的技術,例如 Dropout 和 Batch Normalization。但是在 CoinRun的泛化機制中,OpenAI的研究人員們發現這些方法其實有用,并且他們更早開發的強化學習會對特定的 MDP過擬合。 CoinRun 在復雜性方面取得了令人滿意的平衡:這個環境比傳統平臺游戲如《刺猬索尼克》要簡單得多,但它仍是對現有算法的泛化性的有難度的挑戰。


泛化挑戰
任務間的泛化一直是當前深度強化學習(RL)算法的難點。雖然智能體經過訓練后可以解決復雜的任務,但他們很難將習得經驗轉移到新的環境中。即使人們知道強化學習智能體傾向于過擬合——也就是說,不是學習通用技能,而更依賴于他們環境的細節——強化學習智能體始終是通過評估他們所訓練的環境來進行基準測試。這就好比,在監督學習中對你的訓練集進行測試一樣!
之前的強化學習研究中已經使用了Sonic游戲基準、程序生成的網格世界迷宮,以及通用化設計的電子游戲 AI 框架來解決這個問題。在所有情況下,泛化都是通過在不同級別集合上的訓練和測試智能體來進行度量的。在OpenAI的測試中,在 Sonic游戲基準中受過訓練的智能體在訓練關卡上表現出色,但是如果不經過精細調節(fine-tuning)的話,在測試關卡中仍然會表現不佳。在類似的過擬合顯示中,在程序生成的迷宮中訓練的智能體學會了記憶大量的訓練關卡,而 GVG-AI 智能體在訓練期間未見過的難度設置下表現不佳。
游戲規則
CoinRun 是為現有算法而設計的一個有希望被解決的場景,它模仿了Sonic等平臺游戲的風格。CoinRun 的關卡是程序生成的,使智能體可以訪問大量且易于量化的訓練數據。每個 CoinRun 關卡的目標很簡單:越過幾個或靜止或非靜止的障礙物,并收集到位于關卡末尾的一枚硬幣。 如果碰撞到障礙物,智能體就會立即死亡。環境中唯一的獎勵是通過收集硬幣獲得的,而這個獎勵是一個固定的正常數。 當智能體死亡、硬幣被收集或經過1000個時間步驟后,等級終止。
每個關卡的 CoinRun 設置難度從 1 到 3 .上面顯示了兩種不同的關卡:難度-1(左)和難度-3(右)
評估泛化
OpenAI 訓練了 9個智能體來玩 CoinRun,每個智能體都有不同數量的可用訓練關卡。其中 8個智能體的訓練關卡數目從 100 到 16000 不等,最后一個智能體的關卡數目不受限制,因此它也永遠不會經歷相同的訓練關卡。OpenAI使用一個常見的 3 層卷積網絡架構(他們稱之為Nature-CNN),在其上訓練智能體的策略。他們使用近端策略優化(PPO)對智能體進行了訓練,總共完成了 256M 的時間步驟。由于每輪訓練平均持續 100 個時間步驟,具有固定訓練集的智能體將會看到每個相同的訓練級別數千到數百萬次。而最后那一個不受限制的智能體,經過不受限制的集合訓練,則會看到約 200 萬個不同的關卡,每個關卡一次。
OpenAI收集了數據并繪制出了下面的圖,每個點表示智能體在 10000輪訓練中的表現的平均值。在測試時使用智能體進行從未見過的關卡。他們發現,當訓練關卡數目低于 4000 時,就會出現嚴重的過擬合。事實上,即使有 16000 個關卡的訓練,仍會出現過擬合現象!不出所料,接受了不受限水平訓練的智能體表現最好,因為它可以訪問最多的數據。這些智能體用下圖中的虛線表示。
他們將 Nature-CNN 基線與 IMPALA 中使用的卷積網絡進行了比較,發現 IMPALA- cnn 智能體在任何訓練集下的泛化效果都要好得多,如下所示。
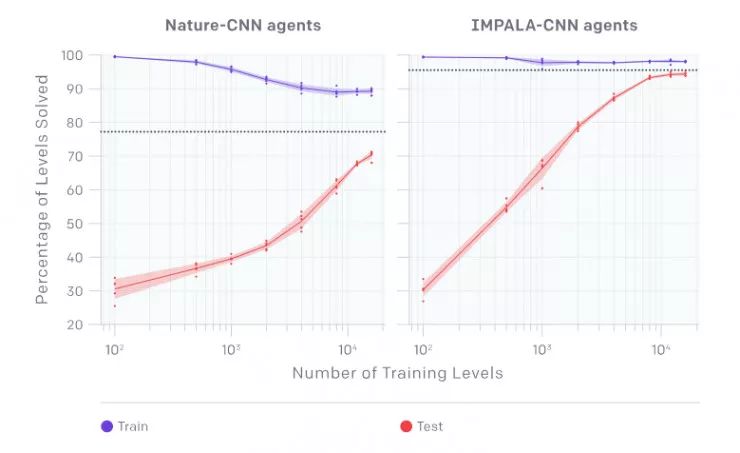
(左)最終訓練和測試cnn - nature agent的性能,經過256M的時間步長,橫軸是訓練關卡數目。
(右)最終訓練并測試IMPALA-CNN agent的性能,經過256M的時間步長,橫軸是訓練關卡數目
提高泛化性能
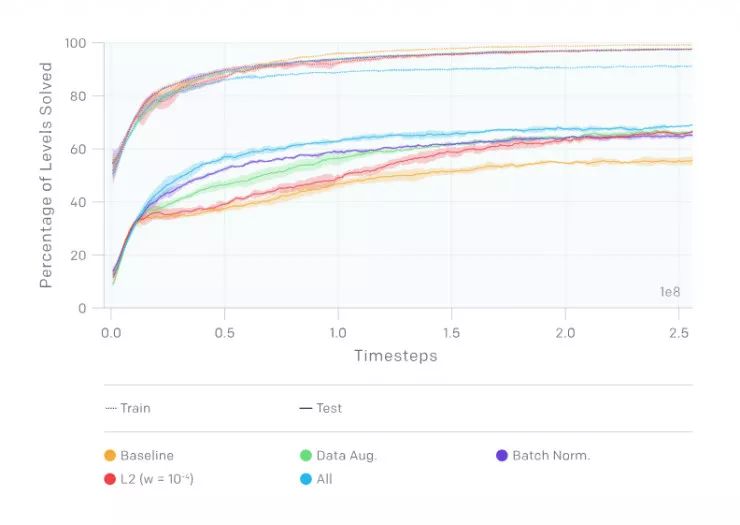
在接下來的實驗中,OpenAI 使用了 500 個CoinRun級別的固定訓練集。OpenAI的基準智能體在如此少的關卡數目上泛化,這使它成為一個理想的基準訓練集。他們鼓勵其他人通過在相同的 500 個關卡上進行訓練來評估他們自己的方法,直接比較測試時的性能。 利用該訓練集,他們研究了幾種正則化技術的影響:
dropout (當一個復雜的前饋神經網絡在小的數據集上訓練時容易造成過擬合。為了防止這種情況的發生,可以通過在不同的時候讓不同的特征檢測器不參與訓練的做法來提高神經網絡的性能)和 L2批量正則化(就是在深度神經網絡訓練過程中,讓每一層神經網絡的輸入都保持相同分布的批標準化):兩者都帶來了更好的泛化性能,而 L2 正則化的影響更大
數據增強和批量標準化:數據增強和批量標準化都顯著改善了泛化。
環境隨機性:與前面提到的任何一種技術相比,具有隨機性的訓練在更大程度上改善了泛化(詳見論文https://arxiv.org/abs/1812.02341)。
額外的環境
OpenAI 還開發了另外兩個環境來研究過擬合:一個名為 CoinRun-Platforms的 CoinRun 變體和一個名為 RandomMazes 的簡單迷宮導航環境。 在這些實驗中,他們使用了原始的 IMPALA-CNN 架構和 LSTM,因為他們需要足夠的內存來保證在這些環境中良好地運行。
在 CoinRun-Platforms 中,智能體試圖在 1000 步時限內收集幾個硬幣。硬幣被隨機地分散在關卡的不同平臺上。在 CoinRun-Platforms 中,關卡更大、更固定,因此智能體必須更積極地探索,偶爾還要回溯其步驟。
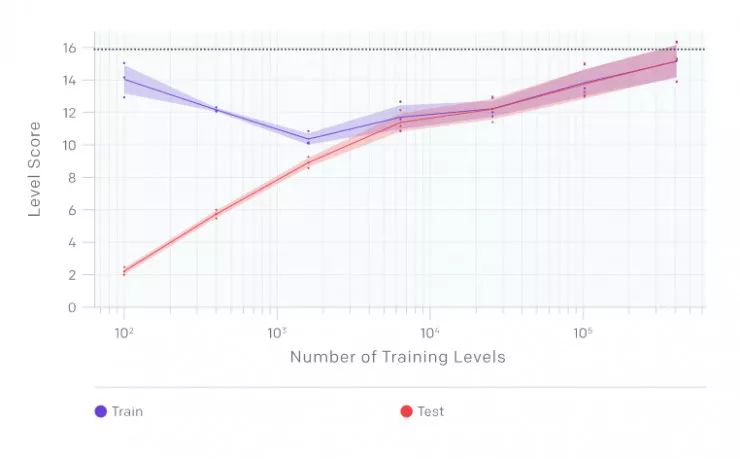
在 CoinRun-Platforms 上經過 20 億個時間步驟后的最終訓練和測試性能,橫軸是訓練關卡數目
當他們在基線智能體實驗中測試運行 CoinRun-Platforms和 RandomMazes 時,智能體在所有情況下都非常嚴重過擬合。在 RandomMazes中,他們觀察到特別強的過擬合,因為即使使用 20,000 個訓練關卡是,仍然與無限關卡的智能體存在相當大的泛化差距。
RandomMazes中的一個級別,顯示智能體的觀察空間(左)。橫軸是訓練關卡數目
下一步
OpenAI 的結果再次揭示了強化學習中潛在的問題。使用程序生成的 CoinRun 環境可以精確地量化這種過擬合。有了這個度量,研究人員們可以更好地評估關鍵的體系結構和算法決策。他相信,從這個環境中吸取的經驗教訓將適用于更復雜的環境,他們希望使用這個基準,以及其他類似的基準,向具有通用泛化能力的智能體迭代前進。
-
學習算法
+關注
關注
0文章
15瀏覽量
7467
原文標題:學界 | 量化深度強化學習算法的泛化能力
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度學習DeepLearning實戰
深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
機器學習中的無模型強化學習算法及研究綜述

模型化深度強化學習應用研究綜述








 工商網監
工商網監
評論