 Facebook發布全卷積神經網絡語音識別模型,開源語音處理深度學習工具包
Facebook發布全卷積神經網絡語音識別模型,開源語音處理深度學習工具包
在語音識別領域先進的神經網絡一般使用rnn來構建聲學或者語言模型,并基于特征抽取的方式來進行抽取梅爾濾波器特征或者倒譜系數。但在最近的研究工作中,Facebook的研究人員提出了完全基于卷積神經網絡的全卷積語音識別模型,充分利用了在聲學模型和語言模型方面的最新進展。這一全卷積神經網絡通過端到端的訓練可以直接從原始波形預測出語言字符,移除了特征抽取的過程。同時利用一個外部的卷積語言模型來進行單詞解碼。這一模型在多個數據集上都取得了優異的表現。
模型
整個模型由四部分組成,分別是卷積前端、聲學模型、語言模型和集束搜索的解碼器(Beam-search)組成,如下圖所示。
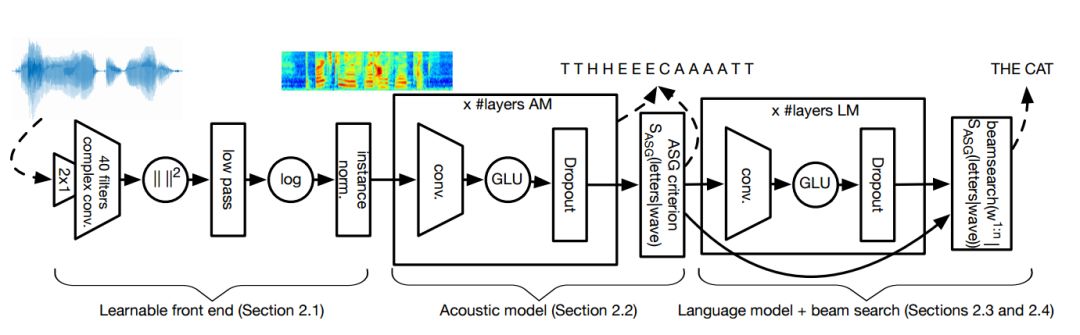
在可學習的前端中,原始音頻首先輸入到一個寬度為2的卷積中,用于模仿梅爾濾波器特征中的前處理步驟。隨后應用了寬度為25ms的k復卷積濾波器。隨后利用平方取絕對值并通過低通濾波器,其寬度為25ms步長為10ms。最后利用對數壓縮,并對每個通道進行了均方歸一化。緊隨其后的是聲學模型,包含了線性門的卷積神經網絡,同時使用了dropout來實現正則化。這一模型的目的在于直接預測出字母。在隨后的語言模型中,研究人員利用了GCNN-14B,其中包含了14個卷積殘差模塊和逐漸增長的通道數,并利用了線性門控單元作為激活函數。語言模型的主要目的在于為備選的句子輸出打分,這一模型允許更大的上下文。最后,基于集束搜索的解碼器用于生成最合適的句子輸出。
其工作的過程在于最大化上面的表達式。
工具
這一模型的實現使用了Facebook最新開源的兩個工具:其中使用了wav2letter建立聲學模型,fairseq建立了語言模型。
fairseq 原理圖
同時推出的升級版深度學習自動語音識別工具框架wav2letter++,在之前wav2letter的基礎上進行和很多的改進和優化。

wav2letter++ 工具包架構
這一版的工具箱由C++實現,并利用了ArrayFire張量庫來提高了運算效率。研究團隊表示,在某些情況下wav2letter++在訓練端到端的語音識別神經網絡時將提速2倍。

wav2letter++ 與其他語言工具的性能比較
端到端的語音識別使得其在多語言上的大規模應用變得可行。同時直接從原始音頻上進行學習可以充分發揮高質量音頻的效果。端到端的算法加上高效的工具框架,將有效促進這一領域的研究,希望全卷積神經網絡的語音識別和wav2letter工具為小伙伴們的研究帶來新的幫助。
-
神經網絡
+關注
關注
42文章
4789瀏覽量
101527 -
Facebook
+關注
關注
3文章
1432瀏覽量
55246 -
深度學習
+關注
關注
73文章
5527瀏覽量
121832
原文標題:新模型、新工具,Facebook在語音識別領域的新動作!
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論