 機器學習的logistic函數和softmax函數總結
機器學習的logistic函數和softmax函數總結
前言
本文簡單總結了機器學習最常見的兩個函數,logistic函數和softmax函數。首先介紹兩者的定義和應用,最后對兩者的聯系和區別進行了總結。
目錄
1. logisitic函數
2. softmax函數
3. logistic函數和softmax函數的關系
4. 總結
logistic函數
1.1 logistic函數定義
logsitic函數也就是經常說的sigmoid函數,幾何形狀也就是一條sigmoid曲線。
logistic函數的定義如下:
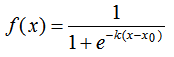
其中,x0表示了函數曲線的中心(sigmoid midpoint),k是曲線的坡度,表示f(x)在x0的導數。
對應的幾何形狀:
1.2 logistic函數的應用
logistic函數在統計學和機器學習領域應用最為廣泛或最為人熟知的肯定是邏輯斯蒂回歸模型,邏輯斯蒂回歸(Logisitic Regression,簡稱LR)作為一種對數線性模型被廣泛地應用于分類和回歸場景中,此外,logistic函數也是神經網絡中最為常用的激活函數,即sigmoid函數 。
logistic函數常用作二分類場景中,表示輸入已知的情況下,輸出為1的概率:
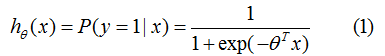
其中,為分類的決策邊界。另一類的生成概率:
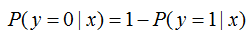
softmax函數
2.1 softmax函數的定義
softmax函數是logistic函數的一般形式,本質是將一個K維的任意實數向量映射成K維的實數向量,其中向量中的每個元素取值都介于(0,1)之間,且所有元素的和為1。
softmax函數的表達式:
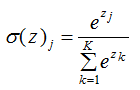
2.2 softmax函數的應用
softmax函數經常用在神經網絡的最后一層,作為輸出層,進行多分類。公式如下:
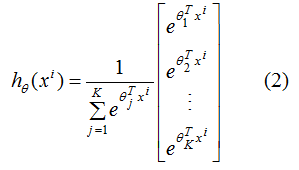
(2)式含義:輸入樣本為,輸出向量的每個元素為K個類別中每個類的生成概率,其中為第 j類的模型參數,為歸一化項,使得所有概率之和為1。
2.3 softmax回歸模型的參數冗余
我們對(2)式減去向量,此時,輸入樣本為,輸出為第j類的生成概率:
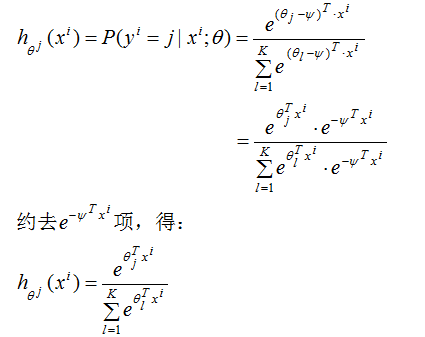
由上式可得,從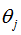 中減去
中減去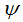 完全不影響假設函數的預測結果,表明softmax回歸模型存在冗余的參數,模型最優化結果存在多個參數解。
完全不影響假設函數的預測結果,表明softmax回歸模型存在冗余的參數,模型最優化結果存在多個參數解。
解決辦法:對softmax回歸模型的損失函數引入正則化項(懲罰項),就可以保證得到唯一的最優解。
logistic函數和softmax函數的關系
相同點:
(1)最優模型的學習方法
我們常用梯度下降算法來求模型損失函數的最優解,因為softmax回歸是logistic回歸的一般形式,因此最優模型的學習方法相同。
logistic回歸的損失函數的偏導數:
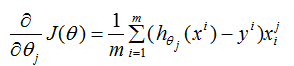
參數更新:
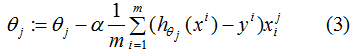
由(3)式可知,當樣本實際標記值為1時,則會以增大的方向更新;樣本實際標記值為-1時,則會以減小的方向更新。同理,softmax回歸參數的思想也大致相同,使得模型實際標記的第K類的生成概率接近于1。
(2)二分類情況
logistic回歸針對的是二分類情況,而softmax解決的是多分類問題,若softmax回歸處理的是二分類問題,則表達式如下:
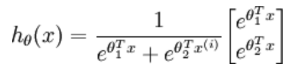
利用2.3節的softmax回歸的參數冗余特點,參數向量減去向量 ,得到:
,得到:
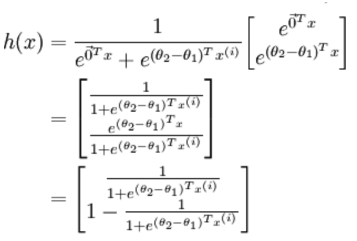
令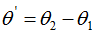 ,上式可表示為:
,上式可表示為:
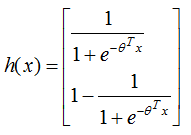
與logistic二分類的表達式一致,因此,softmax回歸與logistic回歸的二分類算法相同 。
不同點:
多分類情況
logistic回歸是二分類,通過“1對1(one vs one)“分類器和”1對其他(one vs the rest)“分類器轉化為多分類。但是,這兩種方法會產生無法分類的區域,該區域屬于多個類,如下圖:
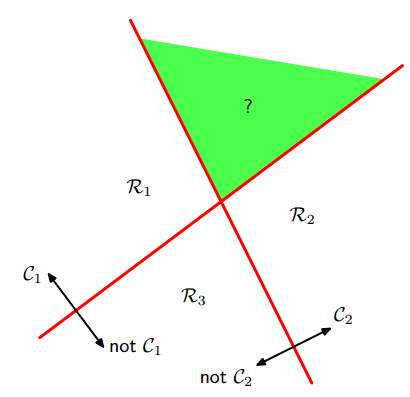
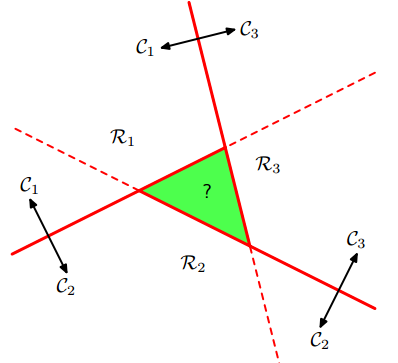
左圖是1對多的分類情況,右圖是1對1的分類情況,綠色為無法分類的區域。
softmax回歸進行的多分類,輸出的類別是互斥的,不存在無法分類的區域,一個輸入只能被歸為一類;
logistic多分類的解決辦法:若構建K類的分類器,通過創建K類判定函數來解決無法分類的問題。假定K類判定函數為,對于輸入樣本x,

則樣本屬于第k類。
總結
logisitc函數常用于二分類和神經網絡的激活函數,softmax函數常用于神經網絡的輸出層,進行多分類。logistic多分類回歸可通過設置與類數相同的判別函數來避免無法分類的情況。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100715 -
機器學習
+關注
關注
66文章
8406瀏覽量
132565
原文標題:淺談logistic函數和softmax函數
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習實戰之logistic回歸
WinCC標準函數總結

機器學習算法之一:Logistic 回歸算法的優缺點
機器學習經典損失函數比較
C語言入門教學之函數資料總結免費下載
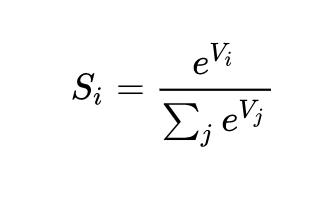
機器學習和深度學習中分類與回歸常用的幾種損失函數
c++中構造函數學習的總結(一)
機器學習中若干典型的目標函數構造方法
vc++-CDC常用函數總結






 工商網監
工商網監
評論