") 邏輯回歸的對(duì)于數(shù)據(jù)學(xué)習(xí)的關(guān)鍵
邏輯回歸的對(duì)于數(shù)據(jù)學(xué)習(xí)的關(guān)鍵
在幾年之前,我踏進(jìn)了數(shù)據(jù)科學(xué)的大門。之前還是軟件工程師的時(shí)候,我是最先開始在網(wǎng)上自學(xué)的(在開始我的碩士學(xué)位之前)。我記得當(dāng)我搜集網(wǎng)上資源的時(shí)候,我看見的只有玲瑯滿目的算法名稱—線性回歸,支持向量機(jī)(SVM),決策樹(DT),隨即森林(RF),神經(jīng)網(wǎng)絡(luò)等。對(duì)于剛剛開始學(xué)習(xí)的我來說,這些算法都是非常有難度的。但是,后來我才發(fā)現(xiàn):要成為一名數(shù)據(jù)科學(xué)家,最重要的事情就是了解和學(xué)習(xí)整個(gè)的流程,比如,如何獲取和處理數(shù)據(jù),如何理解數(shù)據(jù),如何搭建模型,如何評(píng)估結(jié)果(模型和數(shù)據(jù)處理階段)和優(yōu)化。為了達(dá)到這個(gè)目的,我認(rèn)為從邏輯回歸開始入門是非常不錯(cuò)的選擇,這樣不但可以讓我們很快熟悉這個(gè)流程,而且不被那些高大上的算法所嚇倒。
因此,下面將要列出5條原因來說明為什么最開始學(xué)習(xí)邏輯回歸是入門最好的選擇。當(dāng)然,這只是我個(gè)人的看法,對(duì)于其他人可能有更快捷的學(xué)習(xí)方式。
1. 因?yàn)槟P退惴ㄖ皇钦麄€(gè)流程的一部分
像我之前提到的一樣,數(shù)據(jù)科學(xué)工作不僅僅是建模,它還包括以下的步驟:
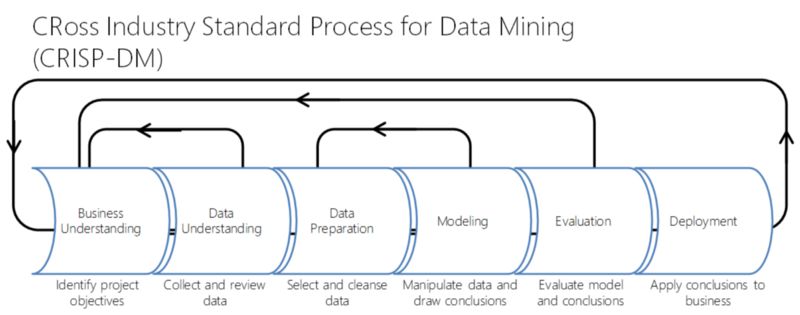
可以看到,“建模” 只是這個(gè)重復(fù)過程的一部分而已。當(dāng)開展一個(gè)數(shù)據(jù)產(chǎn)品的時(shí)候,一個(gè)非常好的實(shí)踐就是首先建立你的整個(gè)流程,讓它越簡(jiǎn)單越好,清楚地明白你想要獲得什么,如何進(jìn)行評(píng)估測(cè)試,以及你的baseline是什么。隨后在這基礎(chǔ)上,你就可以加入一些比較炫酷的機(jī)器學(xué)習(xí)算法,并知道你的效果是否變得更好。
順便說下,邏輯回歸(或者任何ML算法)可能不只是在建模部分所使用,它們也可能在數(shù)據(jù)理解和數(shù)據(jù)準(zhǔn)備的階段使用,填補(bǔ)缺失值就是一個(gè)例子。
2. 因?yàn)槟銓⒁玫乩斫鈾C(jī)器學(xué)習(xí)
我想當(dāng)大家看到本篇的時(shí)候,第一個(gè)想要問的問題就是:為什么是邏輯回歸,而不是線性回歸。真相其實(shí)是都無所謂,理解了機(jī)器學(xué)習(xí)才是最終目的。說到這個(gè)問題,就要引出監(jiān)督學(xué)習(xí)的兩個(gè)類型了,分類(邏輯回歸)和回歸(線性回歸)。當(dāng)你使用邏輯回歸或者線性回歸建立你整個(gè)流程的時(shí)候(越簡(jiǎn)單越好),你會(huì)慢慢地熟悉機(jī)器學(xué)習(xí)里的一些概念,例如監(jiān)督學(xué)習(xí)v.s非監(jiān)督學(xué)習(xí),分類v.s回歸,線性v.s非線性等,以及更多問題。你也會(huì)知道如何準(zhǔn)備你的數(shù)據(jù),以及這過程中有什么挑戰(zhàn)(比如填補(bǔ)缺失值和特征選擇),如何度量評(píng)估模型,是該使用準(zhǔn)確率,還是精準(zhǔn)率和召回率,RUC AUC?又或者可能是 “均方差”和“皮爾遜相關(guān)”?所有的概念都都是數(shù)據(jù)科學(xué)學(xué)習(xí)過程中非常重要的知識(shí)點(diǎn)。等慢慢熟悉了這些概念以后,你就可以用更復(fù)雜的模型或者技巧(一旦你掌握了之后)來替代你之前的簡(jiǎn)單模型了。
3. 因?yàn)檫壿嫽貧w有的時(shí)候,已經(jīng)足夠用了
邏輯回歸是一個(gè)非常強(qiáng)大的算法,甚至對(duì)于一些非常復(fù)雜的問題,它都可以做到游刃有余。拿MNIST舉例,你可以使用邏輯回歸獲得95%的準(zhǔn)確率,這個(gè)數(shù)字可能并不是一個(gè)非常出色的結(jié)果,但是它對(duì)于保證你的整個(gè)流程工作來說已經(jīng)足夠好了。實(shí)際上,如果說能夠選擇正確且有代表性的特征,邏輯回歸完全可以做的非常好。
當(dāng)處理非線性的問題時(shí),我們有時(shí)候會(huì)用可解釋的線性方式來處理原始數(shù)據(jù)。可以用一個(gè)簡(jiǎn)單的例子來說明這種思想:現(xiàn)在我們想要基于這種思想來做一個(gè)簡(jiǎn)單的分類任務(wù)。
X1x2|Y==================-201201-100100
如果我們將數(shù)據(jù)可視化,我們可以看到?jīng)]有一條直線可以將它們分開。
在這種情況下,如果不對(duì)數(shù)據(jù)做一些處理的話,邏輯回歸是無法幫到我們的,但是如果我們不用x2特征,而使用x12來代替,那么數(shù)據(jù)將會(huì)變成這樣:
X1x1^2|Y==================-241241-110110
現(xiàn)在,就存在一條直線可以將它們分開了。當(dāng)然,這個(gè)簡(jiǎn)單的例子只是為了說明這種思想,對(duì)于現(xiàn)實(shí)世界來講,很難發(fā)現(xiàn)或找到如何改變數(shù)據(jù)的方法以可以使用線性分類器來幫助你。但是,如果你可以在特征工程和特征選擇上多花些時(shí)間,那么很可能你的邏輯回歸是可以很好的勝任的。
4. 因?yàn)檫壿嫽貧w是統(tǒng)計(jì)中的一個(gè)重要工具
線性回歸不僅僅可以用來預(yù)測(cè)。如果你有了一個(gè)訓(xùn)練好的線性模型,你可以通過它學(xué)習(xí)到因變量和自變量之間的關(guān)系,或者用更多的ML語言來說,你可以學(xué)習(xí)到特征變量和目標(biāo)變量的關(guān)系。一個(gè)簡(jiǎn)單的例子,房?jī)r(jià)預(yù)測(cè),我們有很多房屋特征,還有實(shí)際的房?jī)r(jià)。我們基于這些數(shù)據(jù)訓(xùn)練一個(gè)線性回歸模型,然后得到了很好的結(jié)果。通過訓(xùn)練,我們可以發(fā)現(xiàn)模型訓(xùn)練后會(huì)給每個(gè)特征分配相應(yīng)的權(quán)重。如果某個(gè)特征權(quán)重很高,我們就可以說這個(gè)特征比其它的特征更重要。比如房屋大小特征,對(duì)于房?jī)r(jià)的變化會(huì)有50%的權(quán)重,因?yàn)榉课荽笮∶吭黾右黄矫追績(jī)r(jià)就會(huì)增加10k。線性回歸是一個(gè)了解數(shù)據(jù)以及統(tǒng)計(jì)規(guī)律的非常強(qiáng)的工具,同理,邏輯回歸也可以給每個(gè)特征分配各自的權(quán)重,通過這個(gè)權(quán)重,我們就可以了解特征的重要性。
5. 因?yàn)檫壿嫽貧w是學(xué)習(xí)神經(jīng)元網(wǎng)絡(luò)很好的開始
當(dāng)學(xué)習(xí)神經(jīng)元網(wǎng)絡(luò)的時(shí)候,最開始學(xué)習(xí)的邏輯回歸對(duì)我?guī)椭艽蟆D憧梢詫⒕W(wǎng)絡(luò)中的每個(gè)神經(jīng)元當(dāng)作一個(gè)邏輯回歸:它有輸入,有權(quán)重,和閾值,并可以通過點(diǎn)乘,然后再應(yīng)用某個(gè)非線性的函數(shù)得到輸出。更多的是,一個(gè)神經(jīng)元網(wǎng)絡(luò)的最后一層大多數(shù)情況下是一個(gè)簡(jiǎn)單的線性模型,看一下最基本的神經(jīng)元網(wǎng)絡(luò):
如果我們更深入地觀察一下output層,可以看到這是一個(gè)簡(jiǎn)單的線性(或者邏輯)回歸,有hidden layer 2作為輸入,有相應(yīng)的權(quán)重,我們可以做一個(gè)點(diǎn)乘然后加上一個(gè)非線性函數(shù)(根據(jù)任務(wù)而定)。可以說,對(duì)于神經(jīng)元網(wǎng)絡(luò),一個(gè)非常好的思考方式是:將NN劃分為兩部分,一個(gè)是代表部分,一個(gè)是分類/回歸部分。
第一部分(左側(cè))嘗試從數(shù)據(jù)中學(xué)習(xí)并具有很好的代表性,然后它會(huì)幫助第二個(gè)部分(右側(cè))來完成一個(gè)線性的分類或者回歸任務(wù)。
總結(jié)
成為一個(gè)數(shù)據(jù)科學(xué)家你可能需要掌握很多知識(shí),第一眼看上去,好像學(xué)習(xí)算法才是最重要的部分。實(shí)際的情況是:學(xué)習(xí)算法確實(shí)是所有情況中最復(fù)雜的部分,需要花費(fèi)大量的時(shí)間和努力來理解,但它也只是數(shù)據(jù)科學(xué)中的一個(gè)部分,把握整體更為關(guān)鍵。
-
算法
+關(guān)注
關(guān)注
23文章
4629瀏覽量
93193 -
人工智能
+關(guān)注
關(guān)注
1794文章
47642瀏覽量
239644
原文標(biāo)題:5個(gè)原因告訴你:為什么在成為數(shù)據(jù)科學(xué)家之前,“邏輯回歸”是第一個(gè)需要學(xué)習(xí)的
文章出處:【微信號(hào):AI_shequ,微信公眾號(hào):人工智能愛好者社區(qū)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
機(jī)器學(xué)習(xí)實(shí)戰(zhàn)之logistic回歸
回歸預(yù)測(cè)之入門
回歸算法有哪些,常用回歸算法(3種)詳解
TensorFlow邏輯回歸處理MNIST數(shù)據(jù)集
TensorFlow邏輯回歸處理MNIST數(shù)據(jù)集
Edge Impulse的回歸模型
使用KNN進(jìn)行分類和回歸
Python機(jī)器學(xué)習(xí)回歸部分的應(yīng)用與教程
對(duì)于機(jī)器學(xué)習(xí)/數(shù)據(jù)科學(xué)初學(xué)者 應(yīng)該掌握的七種回歸分析方法
DNN與邏輯回歸效果一樣?

機(jī)器學(xué)習(xí)的回歸分析和回歸方法
機(jī)器學(xué)習(xí):線性回歸與邏輯回歸的理論與實(shí)戰(zhàn)
Python 梯度計(jì)算模塊如何實(shí)現(xiàn)一個(gè)邏輯回歸模型
- 設(shè)計(jì)技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測(cè)量?jī)x表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動(dòng)
- 處理器/DSP
- EDA/IC設(shè)計(jì)
- 存儲(chǔ)技術(shù)
- 光電顯示
- EMC/EMI設(shè)計(jì)
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實(shí)
- 可穿戴設(shè)備
- 機(jī)器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動(dòng)通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測(cè)
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計(jì)資源
- 設(shè)計(jì)技術(shù)
- 電子百科
- 電子視頻
- 元器件知識(shí)
- 工具箱
- VIP會(huì)員
- 最新技術(shù)文章
- 社區(qū)
- 小組
- 論壇
- 問答
- 評(píng)測(cè)試用
- 企業(yè)服務(wù)
- 產(chǎn)品
- 資料
- 文章
- 方案
- 企業(yè)
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會(huì)
- 活動(dòng)策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測(cè)驗(yàn)
- 設(shè)計(jì)大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動(dòng)態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報(bào)投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動(dòng)端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:wangwanzhu@elecfans.com
- 內(nèi)容合作
- 黃晶晶:huangjingjing@elecfans.com
- 內(nèi)容合作(海外)
- 張迎輝:mikezhang@elecfans.com
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:lanhu@huaqiu.com
- 投資合作
- 曾海銀:zenghaiyin@huaqiu.com
- 社區(qū)合作
- 劉勇:liuyong@huaqiu.com
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長(zhǎng)沙市望城經(jīng)濟(jì)技術(shù)開發(fā)區(qū)航空路6號(hào)手機(jī)智能終端產(chǎn)業(yè)園2號(hào)廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號(hào)-1
評(píng)論