 Adaboost算法總結
Adaboost算法總結
前言
集成學習的Boosting算法串行生成多個弱學習器并按一定的結合策略生成強學習器,AdaBoost算法是Boosting系列算法中的一種,本文詳細總結了AdaBoost算法的相關理論。
目錄
1. Boosting算法基本原理
2. Boosting算法的權重理解
3. AdaBoost的算法流程
4. AdaBoost算法的訓練誤差分析
5. AdaBoost算法的解釋
6. AdaBoost算法的正則化
7. AdaBoost算法的過擬合問題討論
8. 總結
Boosting的算法流程
Boosting算法是一種由原始數據集生成不同弱學習器的迭代算法,然后把這些弱學習器結合起來,根據結合策略生成強學習器。
如上圖,Boosting算法的思路:
(1)樣本權重表示樣本分布,對特定的樣本分布生成一個弱學習器。
(2)根據該弱學習器模型的誤差率e更新學習器權重α。
(3)根據上一輪的學習器權重α來更新下一輪的樣本權重。
(4)重復步驟(1)(2)(3),結合所有弱學習器模型,根據結合策略生成強學習器。
Boosting算法的權重理解
Boosting算法意為可提升算法,可提升方法具體表現在(一)改變訓練數據的概率分布(訓練數據的權值分布),(二)弱分類器權重的生成。理解這兩個原理是理解AdaBoost算法的基礎。
1. 訓練數據的權重理解
我們對癌癥病人和健康人作一個定性的分析,目的是理解Boosingt算法訓練數據權重更新的思想。
如下圖為分類器G(1)的分類情況,假設樣本數據的權重相等。
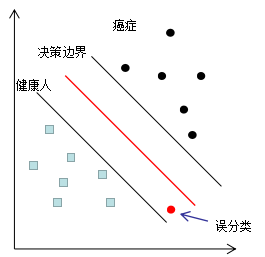
癌癥誤分類成健康人的結果很可能是喪失生命,因此這種誤分類情況肯定不能出現的,若我們對該誤分類點的權重增加一個極大值,以突出該樣本的重要性,分類結果如下圖:
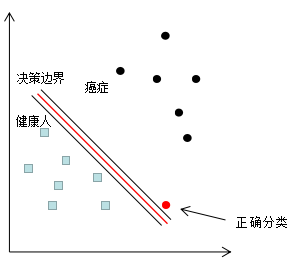
因此,增加誤分類樣本的權重,使分類器往該誤分類樣本的正確決策邊界方向移動,當權重增加到一定值時,誤分類樣本實現了正確分類,因為訓練樣本的權重和是不變的,增加誤分類樣本權重的同時,也降低了正確分類樣本的權重。這是Boosting算法的樣本權重更新思想。
2. 弱學習器的權重理解
Boosting算法通過迭代生成了一系列的學習器,我們給予誤差率低的學習器一個高的權重,給予誤差率高的學習器一個低的權重,結合弱學習器和對應的權重,生成強學習器。弱學習器的權重更新是符合常識的,弱學習器性能越好,我們越重視它,權重表示我們對弱學習器的重視程度,即權重越大,這是Boosting算法弱學習器權重的更新思想。
AdaBoost的算法流程
第一節描述了Boosting算法的流程,但是沒有給出具體的算法詳細說明:
(1)如何計算弱學習器的學習誤差;
(2)如何得到弱學習器的權重系數α;
(3)如何更新樣本權重D;
(4)使用何種結合策略;
我們從這四種問題的角度去分析AdaBoost的分類算法流程和回歸算法流程。第k輪的弱分類器為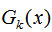

1. AdaBoost的分類算法流程
我們假設是二分類問題,輸出為{-1,1}。第K輪的弱分類器為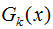
1) 計算弱分類器的分類誤差
在訓練集上的加權誤差率為:
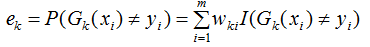
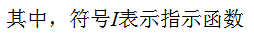
2) 弱學習權重系數α的計算
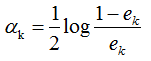
由上式可知,學習器誤差率越小,則權重系數越大。
3) 下一輪樣本的權重更新
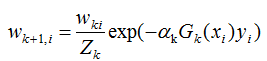
其中Zk是規范化因子,使每輪訓練數據集的樣本權重和等于1。
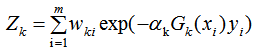
當樣本處于誤分類的情況,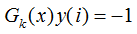 則
則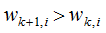 該誤分類樣本的權重增加;當樣本是處于正確分類的情況,
該誤分類樣本的權重增加;當樣本是處于正確分類的情況,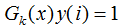 ,則
,則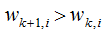 ,該正確分類樣本的權值減小。
,該正確分類樣本的權值減小。
4) 結合策略,構建最終分類器為:
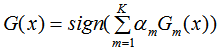
2. AdaBoost的回歸算法流程
1) 計算弱學習器的回歸誤差率:
a) 計算訓練集上的最大誤差:

b) 計算每個樣本的相對誤差:
如果是線性誤差,則
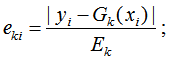
如果是平方誤差,則
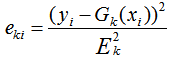
如果是指數誤差,則
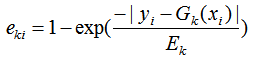
c) 計算回歸誤差率
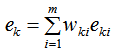
(2) 弱學習權重系數α的計算
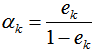
(3)下一輪樣本的權重更新
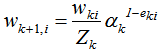
Zk是規范化因子,使樣本權重的和為1,
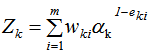
(4)結合策略,構建最終學習器為:
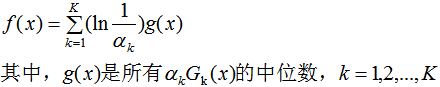
AdaBoost算法的訓練誤差分析
過程就不推倒了,可參考李航《統計學習方法》P142~P143,這里就只給出結論。
AdaBoost的訓練誤差界:
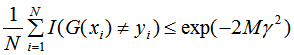
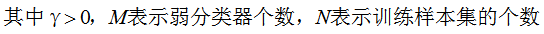
由上式可知,AdaBoost的訓練誤差是以指數速率下降的,即AdaBoost算法隨著迭代次數的增加,訓練誤差不斷減小,即模型偏差顯著降低 。
本文傾向于入門AdaBoost算法,下一篇文章會發散思維,介紹AdaBoost算法的相關性質,
-
算法
+關注
關注
23文章
4607瀏覽量
92840 -
數據結構
+關注
關注
3文章
573瀏覽量
40123
原文標題:比較全面的Adaboost算法總結(一)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Adaboost算法的Haar特征怎么進行并行處理?
一種基于AdaBoost的SVM分類器
Adaboost算法的FPGA實現與性能分析
基于Adaboost算法的駕駛員眨眼識別
AdaBoost算法流程和證明
基于主動學習不平衡多分類AdaBoost改進算法
一種多分類的AdaBoost算法
非線性AdaBoost算法
adaboost運行函數的算法怎么來的?基本程序代碼實現詳細
AdaBoost算法相關理論和算法介紹
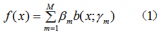
基于AdaBoost算法的復雜網絡鏈路預測






 工商網監
工商網監
評論