


對于智能車輛來說,多傳感器融合對于高精度和魯棒性的感知交通環(huán)境至關(guān)重要。在這篇論文中,我們提出了兩種有效的方法,即時空證據(jù)生成和獨立視覺通道,以改善多傳感器跟蹤水平對車輛環(huán)境感知的影響。時空證據(jù)包括即時證據(jù)、跟蹤證據(jù)和跟蹤匹配證據(jù),以改進存在融合。
獨立視覺通道利用視覺處理在物體識別上的特殊優(yōu)勢來改進分類融合。利用從實際交通環(huán)境中采集的多傳感器數(shù)據(jù)集對所提出的方法進行了評估。實驗結(jié)果表明,該方法在檢測精度和分類精度方面均可顯著提高多傳感器軌道級融合。
Ⅰ.介紹
交通環(huán)境中的物體感知的魯棒性對于自動駕駛和高級駕駛輔助系統(tǒng)( ADAS )都具有重要意義。物體感知可以通過不同類型的傳感器來實現(xiàn),例如激光雷達、雷達和攝相機。激光雷達和雷達是有源傳感器,可以測量物體的精確距離,但物體分類的能力較差。而攝像機在物體識別方面表現(xiàn)出優(yōu)異的性能,但是測量物體距離的能力較差。雷達對測量物體的速度更敏感,激光雷達更適合于感知物體的形狀。總之,這些傳感器各有優(yōu)缺點[ 1 ]。因此,融合不同的傳感器有望實現(xiàn)物體感知的高精度和魯棒性。
傳感器融合系統(tǒng)已經(jīng)被研究了幾十年。通常,傳感器融合方法可分為三類:低級、特征級和高級融合方法。
低級融合架構(gòu)不需要在傳感器級對原始數(shù)據(jù)進行預(yù)處理。盡管低級融合[ 2 ]對物體有很強的描述能力,但它需要很高的數(shù)據(jù)帶寬,并且在實踐中實施起來可能很復(fù)雜。
特征級融合[ 3 ]試圖在進行數(shù)據(jù)融合之前,通過預(yù)處理步驟從原始數(shù)據(jù)中提取某些特征。特征級融合可以降低復(fù)雜性,但在實踐中仍然難以實現(xiàn)。
在高級融合[ 4 ]中,每個傳感器獨立地執(zhí)行跟蹤算法并生成目標列表。高級融合可以產(chǎn)生最佳的感知性能,因為它具有模塊化、實用性和可擴展性。
因此,在本文中,我們將重點放在高級融合上,也稱為軌道級融合。軌道級融合的一個潛在缺點是它對物體的描述能力較差。因此,在軌道級融合設(shè)計中,我們應(yīng)該更加關(guān)注物體的完整描述,如分類、形狀等。
許多軌道級融合方法[ 5 ]–[ 7 ]已經(jīng)被提出,并對目標感知做出了巨大貢獻。在跟蹤目標時,我們主要關(guān)注三種信息:1 )目標的存在概率;2 )目標狀態(tài)的準確性,包括位置、速度和方向,反映在目標的全局軌跡上;3 )其他描述信息的完整性,如分類、形狀等。
因此,軌道級融合主要包括存在融合、軌道間融合和分類融合。參考文獻[ 5 ]和[ 6 ]使用基于證據(jù)理論(DST)的存在融合方法來估計物體的存在概率。然而,它們的存在證據(jù)只考慮瞬時的空間證據(jù),而忽略了時間證據(jù),因此會產(chǎn)生相對高的誤報率和誤報率,特別是在高度動態(tài)的交通環(huán)境下。參考[ 5 ]和[ 7 ]提出了使用信息矩陣融合( IMF )來估計物體狀態(tài)的軌道間融合方法。然而,它們像其他主動傳感器一樣融合圖像對象,同時忽略圖像對象的不準確位置,這導(dǎo)致相對高的假陰性率、檢測的假陽性率和相對低的正確識別率。
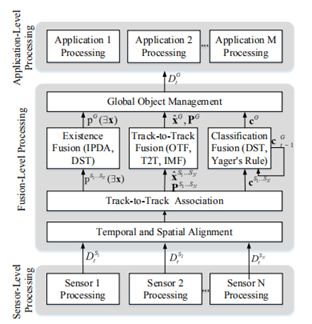
圖1 :最新軌道級融合的框架
為了解決上述兩個問題,我們提出了兩種方法,即時空證據(jù)生成( STEG )和獨立視覺通道( IVC ),以改進多傳感器軌道級融合。STEG方法提高了存在估計的準確性,從而提高了軌道級融合的檢測精度。IVC方法不僅提高了軌道融合的檢測率,而且提高了軌道融合的正確分類率。利用從實際交通環(huán)境中收集的多傳感器數(shù)據(jù)集對所提出的方法進行了評估。實驗結(jié)果清楚地證明了所提方法在軌道級融合中的有效性。與沒有STIG的方法相比,所提出的STIG方法在相似誤報率的情況下將目標檢測的誤報率降低了0.06,并且在相似誤報率的情況下與沒有STIG的方法相比將誤報率降低了0.08。同時,所提出的IVC方法將目標檢測的假陰性率降低了0.01,并將目標識別的正確分類率提高了0.19。
Ⅱ.軌道級融合的背景
為了正確檢測室外環(huán)境中的目標,并且大多數(shù)情況下不會因為進入和離開視場而丟失物體信息,多傳感器數(shù)據(jù)應(yīng)該在軌道級融合。如圖1所示,軌道級融合的框架包括傳感器級處理、融合級處理和應(yīng)用級處理。在傳感器級處理中,我們獨立地從每個傳感器獲得傳感器局部對象列表:
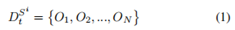
其中t是時間戳,Si表示傳感器i,Oj是對檢測對象的描述,包括狀態(tài)xˇ、狀態(tài)協(xié)方差Pˇ、存在概率p和分類c。在融合級處理中,來自不同傳感器的對象列表首先在空間和時間上與公共坐標系對齊。跟蹤到跟蹤關(guān)聯(lián)后,傳感器級對象會列出DtS1...SN通過存在融合、軌道融合和分類融合融合在一起,形成全局目標列表DtG。在應(yīng)用程序級處理中,全局對象列表DtG與特定應(yīng)用程序的其他數(shù)據(jù)源相結(jié)合。
存在融合是從獨立的傳感器級估計中融合目標存在概率,生成全局目標存在概率估計。這對提高目標跟蹤的魯棒性非常重要。對于單傳感器目標跟蹤,存在概率主要通過歸一化創(chuàng)新平方( NIS )來估計。最近還提出了幾種更先進的方法。例如,[ 8 ]提出了一種利用立體視覺和跟蹤過程中的幾個線索來估計物體存在概率的方法。對于多傳感器目標跟蹤,在綜合概率數(shù)據(jù)關(guān)聯(lián)( IPDA )框架中開發(fā)了目標存在概率估計,作為檢測目標的質(zhì)量度量[ 9 ]。參考文獻[ 6 ]提出了一種基于DST的目標存在概率估計的融合方法,其中組合了由每個傳感器估計的目標存在。
軌道間融合來自獨立傳感器級估計的目標狀態(tài)及其協(xié)方差,以生成全局目標狀態(tài)估計。參考[ 10 ]提出了目標軌道融合( OTF )方法,其中傳感器級軌跡被視為對全局目標軌跡的測量,忽略了相關(guān)性和信息冗余。參考文獻[ 11 ]介紹了軌道到軌道融合( T2T )方法,該方法通過近似技術(shù)計算互相關(guān)度,這種方法存在缺陷。IMF在用于將多傳感器各自的目標軌跡融合成全局軌跡,并顯示出出色的性能。基于IMF的方法在[ 7 ]中提出,該方法使用IMF來處理速度相關(guān)性,實現(xiàn)了集中式架構(gòu)的可比性能。[ 12 ]對現(xiàn)有的用于物體狀態(tài)估計的軌道間融合方法進行了精度比較。它表明IMF對過程噪聲最魯棒,在過程模型偏差期間最準確和一致。
分類融合旨在改進全局對象的分類估計。大多數(shù)分類融合方法基于證據(jù)理論,這是一種基于不完全和不確定信息的決策工具。對于全局對象分類融合,找到合適的證據(jù)至關(guān)重要。參考[ 13 ]–[ 15 ]使用基于DST的方法來估計全局目標軌跡的分類。[ 13 ]提議的基于DST的融合方法依賴于兩個主要證據(jù):瞬時融合證據(jù),從當前每個物體的單個傳感器提供的證據(jù)組合中獲得;以及動態(tài)融合證據(jù),其將來自先前結(jié)果的證據(jù)與瞬時融合結(jié)果相結(jié)合。在[ 14 ]中,作者提出了一種基于證據(jù)理論的目標柵格地圖融合,以決定是否占據(jù)柵格。提出了一種基于DST的分類方法[ 15 ]來融合全局軌跡的瞬時分類結(jié)果和先前的分類結(jié)果。參考[ 16 ]和[ 17 ]使用Yager規(guī)則組合來自不同傳感器的物體分類證據(jù),進一步用于關(guān)聯(lián)來自不同傳感器的物體。
III.軌道級融合
A.總體框架
圖2示出了我們所提出的軌道級融合的框架。整體框架非常類似于最先進的軌道級融合框架。特別是,對于時間和空間對齊,我們采用了我們先前工作[ 8 ]中介紹的相同方法,將獨立的傳感器級對象列表同步并校準到公共坐標系。然后,我們使用匈牙利算法來關(guān)聯(lián)來自多個傳感器的時間和空間對齊的對象列表。我們將DST用于存在融合和分類融合,以及IMF用于軌道到軌道融合。主要原因是DST和IMF分別是最有效的方法。
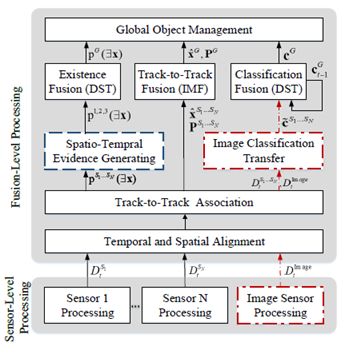
圖2 :軌道級融合框架
本文提出的框架和最新框架之間的主要區(qū)別可以描述如下。
我們提出了一種基于DST的存在融合時空證據(jù)生成方法。我們同時考慮空間瞬時證據(jù)、時間跟蹤證據(jù)和跟蹤匹配證據(jù),以改進存在融合。
我們使用獨立的視覺通道將圖像對象信息融合到全局軌道中。IVC的使用不僅可以改進分類融合,還可以避免對航跡融合的負面影響。
B.時空證據(jù)生成
1 )即時證據(jù)生成:當一個物體出現(xiàn)在感知范圍內(nèi)時,我們需要證據(jù)來即時支持存在融合。單個傳感器存在估計的魯棒性實際上非常低。因此,直接使用單傳感器存在估計[ 6 ]進行存在融合是不合適的。為了提高目標檢測的魯棒性,我們使用瞬時測量的匹配信息作為證據(jù)來支持目標存在估計。我們使用匈牙利算法從不同傳感器獲取不同目標列表的瞬時匹配信息,其中我們計算不同列表中目標之間的歐氏距離作為權(quán)重矩陣。
我們將臨界距離定義為d1max,并將兩個獨立傳感器的距離定義為di,j。如果di,j小于d1max且對象i與對象j匹配,則定義瞬時證據(jù)質(zhì)量,利用Sigmod函數(shù)將di,j映射到質(zhì)量集[a,b]。Sigmod函數(shù)定義為
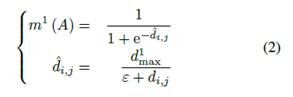
其中ε是接近于零的正常量。
2 )跟蹤證據(jù)生成:當一個物體在一段時間內(nèi)只被一個傳感器檢測到時,我們無法從多個傳感器獲得證據(jù)。由于單個傳感器對目標的瞬時測量不穩(wěn)定,我們將目標跟蹤歷史作為存在融合的證據(jù)。
我們計算一段時間內(nèi)同一軌道上當前幀和前一幀的對象之間的平均歐氏距離,以獲得支持存在估計的質(zhì)量。大量證據(jù)被定義為
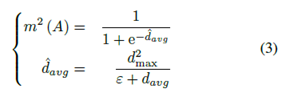
其中ε是如B1小節(jié)中提到的常數(shù),d2max是與物體速度相關(guān)聯(lián)的臨界距離。davg由軌道的長度和平滑度估計,定義為
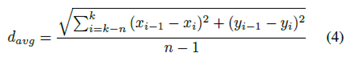
其中k是當前時間戳,n - 1是軌道的選定長度。
3 )跟蹤匹配證據(jù)生成:如果一個物體在一段時間內(nèi)被幾個傳感器同時觀察到,這意味著這個物體幾乎肯定存在。這是物體存在融合的有力證據(jù)。
在本文中,我們計算來自不同傳感器的兩個目標軌道的平均歐幾里德距離,以獲得支持存在估計的質(zhì)量。大量有力的證據(jù)被定義為
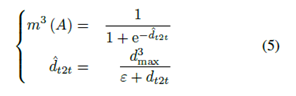
其中ε是接近零的正常數(shù),dt2t是兩條軌道之間的平均距離。Dt2t定義為
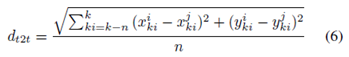
其中ki是時間戳,而i,j代表不同的傳感器,n是軌道長度。
4 )基于DST的存在融合:對于目標存在概率融合,我們獲得了上述三種證據(jù),即瞬時證據(jù)、跟蹤證據(jù)和跟蹤匹配證據(jù)。
存在概率識別框架定義為

其中彐代表存在。實際上,我們計算質(zhì)量m(彐 )和質(zhì)量m(θ),其中θ是未知的命題。在[ 6 ]中,如果一個物體在傳感器的范圍內(nèi),而傳感器未能檢測到該物體,它們定義了m(彐 )的質(zhì)量。由于遮擋問題和傳感器的不可靠性,這是不合適的。因此,假設(shè)A代表存在或未知的命題,我們有三個質(zhì)量值來支持如上計算的命題A、m1(A )、m2(A )和m3(A )。我們使用[ 6 ]中提出的組合和判別規(guī)則計算融合存在概率,該規(guī)則定義為
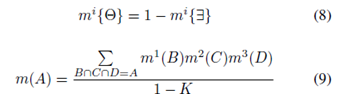
其中K定義為
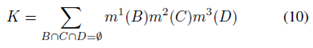
C.獨立視覺通道
在所有傳感器中,攝像機傳感器的識別能力是最出色的。因此,必須融合圖像信息,以實現(xiàn)全面的物體感知。然而,由圖像傳感器檢測到的物體的真實位置并不像其他有源傳感器那樣精確,因為攝像機校準參數(shù)不能適應(yīng)室外交通環(huán)境的所有條件。例如,安裝在車輛上的攝像機可能會隨著車輛在不平的道路上行駛而晃動。如果IMF方法使用與其他傳感器相同的圖像對象列表,將導(dǎo)致相對較高的對象檢測假陰性和假陽性率,從而導(dǎo)致相對較低的對象識別正確分類率。參考[ 19 ]指出了圖像對象的不準確位置,因此提出了一種融合圖像信息的方法。然而,該方法要求其他傳感器必須獲得幾何信息以匹配圖像對象的形狀,這對于沒有感知形狀信息能力的傳感器來說通常是不可用的。
為了解決上述問題,我們提出了一種獨立的視覺通道方法來更恰當?shù)厝诤蠄D像對象信息。提出的獨立視覺通道獨立處理圖像對象列表,避免了對軌道融合的負面影響。此外,獨立的視覺通道將圖像信息傳遞給有源傳感器的目標,因此也可以改進軌道級融合的分類估計。我們首先使用A3小節(jié)中提到的軌道匹配算法將圖像對象的軌道與其他傳感器的軌道進行匹配。當當前時間戳或先前時間戳的dt2t小于d3max時,我們將圖像對象信息(如分類)傳輸?shù)搅硪粋€活動傳感器的對象。之后,我們首先使用DST作為等式( 12 ),將轉(zhuǎn)移的分類c~i和自含分類cSj融合為c~Sj。然后,我們使用DST作為等式( 13 ),將當前分類和先前分類進行融合。
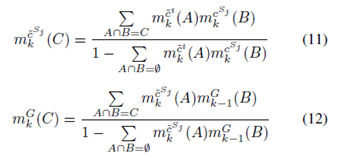
Ⅳ.實驗結(jié)果
A.實驗裝置
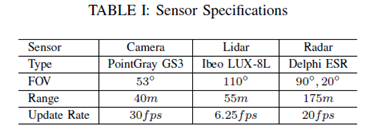
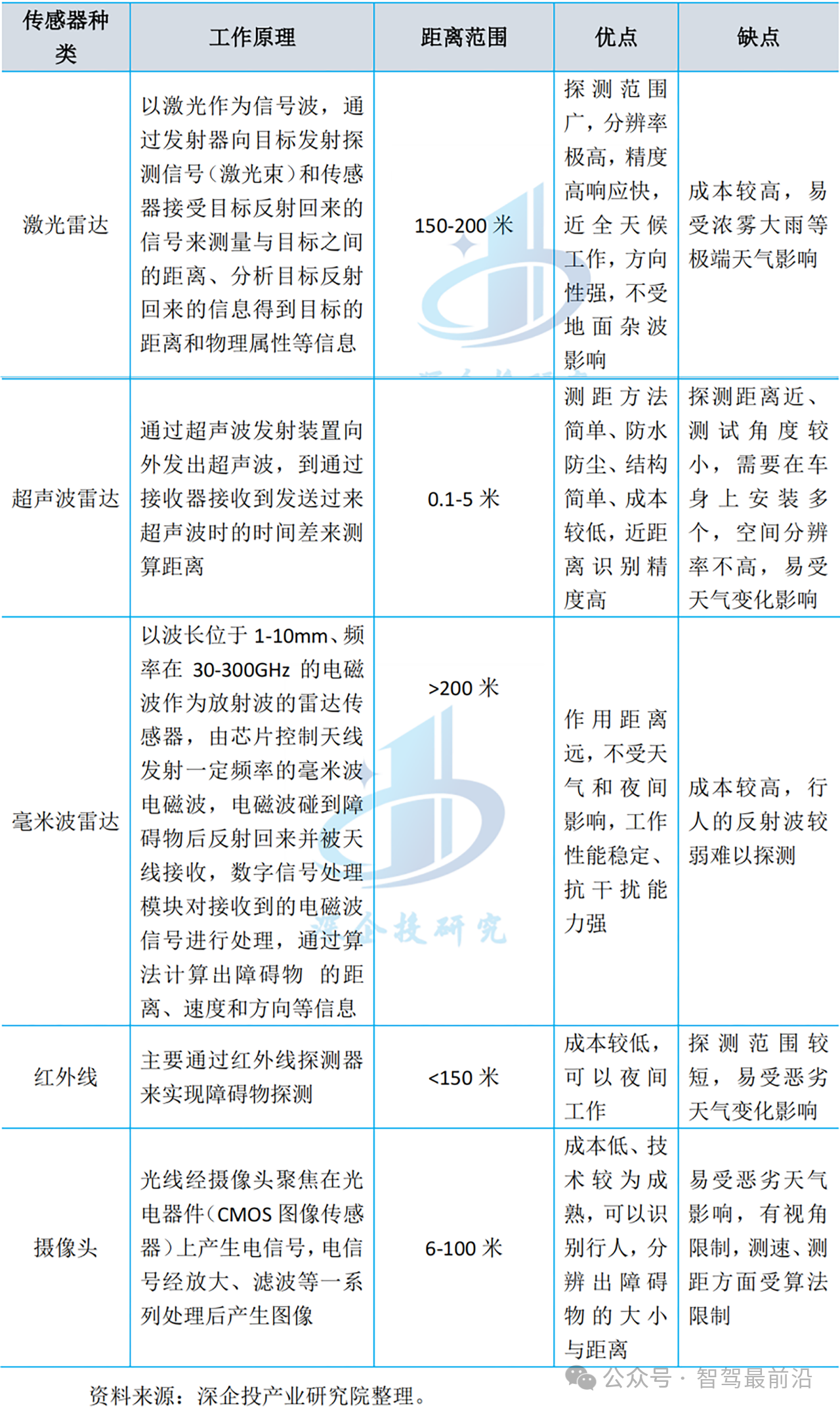
所有物體感知實驗都在西安交通大學(xué)開發(fā)的“發(fā)現(xiàn)號”自動駕駛車輛研究平臺上進行。該平臺旨在滿足一般自主駕駛研究的要求,同時也在努力應(yīng)對環(huán)境感知的挑戰(zhàn)。“發(fā)現(xiàn)”在2017年贏得了中國智能車輛未來挑戰(zhàn)( IVFC )。如圖3 ( a )所示,“發(fā)現(xiàn)號”安裝有一臺德爾菲ESR MMW雷達、一臺單目點灰色攝像機和一臺ibeo LUX - 8L。圖3 ( b )示出了三個傳感器的具體感知范圍。表I列出了這三種傳感器的類型、視場( FOV )、范圍和更新速率。
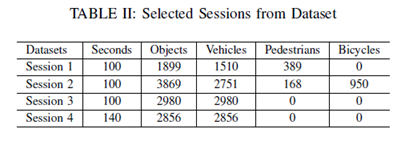
實驗中使用的數(shù)據(jù)集是由安裝在西安市城市道路“發(fā)現(xiàn)號”上的多個傳感器收集的。攝像機和雷達的捕獲速率為10fps,激光雷達的捕獲速率為6.25fps。我們已經(jīng)同時捕獲了45287幀的同步數(shù)據(jù)集,包括相機、激光雷達和雷達數(shù)據(jù)。從數(shù)據(jù)集中,我們選擇4個會話來測試建議的方法,如表所示
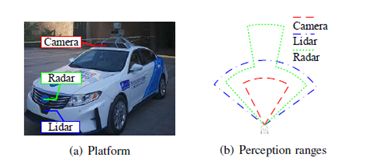
圖3 : XJTU自動駕駛車輛研究平臺“發(fā)現(xiàn)號”的傳感器配置
我們已經(jīng)預(yù)處理了4個選定的會話。MMW雷達目標直接從雷達傳感器讀取,圖像目標由單鏡頭多盒檢測器( SSD ) [ 20 ]模型檢測,激光雷達數(shù)據(jù)由基于密度的帶噪聲應(yīng)用空間聚類( DBSCAN ) [ 21 ]處理。雷達和激光雷達的目標分別被卡爾曼濾波器跟蹤。
B.時空證據(jù)生成的結(jié)果
與文獻[6]中提出的時空證據(jù)生成方法相比,本文提出的時空證據(jù)生成方法從目標檢測的假陰性率和假陽性率兩方面對該方法進行了評價。如果存在一個對象,則將其與全局軌道相融合。因此,為了評估存在性融合的性能,我們分別計算了目標檢測的全局假陰性率和假陽性率。
在我們的工作中,我們?yōu)镾teg方法選擇了一組參數(shù),d1max=d2max=d3max=2.2m;ε=0:0001。該方法可以通過改變目標檢測的參數(shù)來調(diào)整目標檢測的假陰性率和假陽性率。因此,我們選擇了兩組參數(shù),即不帶STEG 1的參數(shù),與STEG方法相似的假陽性率參數(shù)和不帶步驟2的參數(shù),與STEG方法的假陰性率相似。表三列出了前面方法的兩組參數(shù)。雷達信任度是激光雷達傳感器的感知范圍。在感知范圍內(nèi),如果雷達傳感器檢測到目標,而激光雷達傳感器出現(xiàn)故障,則導(dǎo)致目標的不存在。
如圖4所示,在類似假陽性率的情況下,所提出的STEP方法比不帶STG的方法降低了目標檢測的假陰性率0.06;在類似假陰性率的情況下,與沒有STIG的方法相比,該方法降低了0.08%的假陽性率。
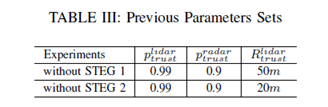
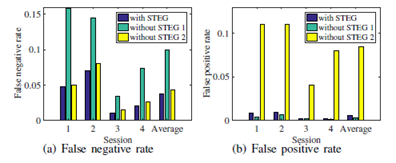
圖4:STEG檢測精度比較
C.獨立視覺通道的結(jié)果
圖5 :對象ID變化比較的示例
較高的誤檢率會導(dǎo)致全局目標軌跡的識別號(ID)發(fā)生較大的變化。IVC方法可以減少假陰性率和ID變化次數(shù)。圖5(A)示出交通場景,其中正面汽車(標記為紅色邊框)正在移動。圖5(B)分別示出了該方法與IVC提供的汽車軌道的ID變化比較,以及不使用IVC的方法,其中每種顏色代表一個ID。所提出的IVC方法提供的軌跡ID在20秒內(nèi)不發(fā)生變化,但在沒有IVC的情況下,該方法提供的ID變化了兩次。圖6示出了目標檢測的假陰性率和假陽性率的比較。比較結(jié)果表明,與不含IVC的方法相比,采用IVC的方法可使假陰性率降低0.01。雖然對目標檢測的假陰性率的提高相對較小,但可以減少ID的平均變化次數(shù),從而有效地提高了分類融合的效果。
本文采用基于DST的分類融合方法,利用現(xiàn)有的傳感器證據(jù)和以往的全局分類證據(jù)來確定目標的分類。因此,當對象ID發(fā)生變化時,會丟失以前的分類證據(jù),從而導(dǎo)致分類正確率較低。圖7示出了對象id的平均變化時間和正確的分類率。結(jié)果表明,該方法的平均變化次數(shù)為0.67,比無IVC的方法低3倍以上。該方法的正確分類率為0.78,比不含IVC的方法高0.19。
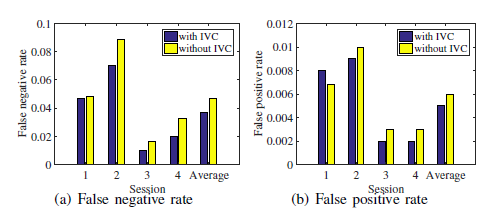
圖6:IVC檢測精度比較
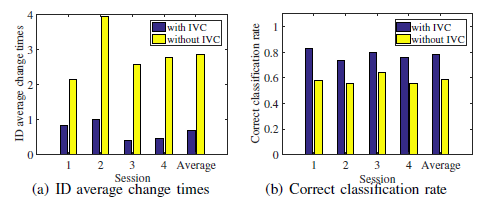
圖7 : IVC分類精度比較
V.結(jié)論
在這篇論文中,我們提出了兩種方法來改進用于目標感知的軌道級融合。首先,我們提出了一種時空證據(jù)生成方法,用于目標存在概率融合,以降低誤報率和誤報率。其次,我們提出了一種獨立的視覺通道方法來改進跟蹤-跟蹤融合和分類融合。最后,通過從實際交通環(huán)境中采集的多傳感器數(shù)據(jù)集對所提出的方法進行了評估。實驗結(jié)果表明,該方法在檢測精度和分類精度方面均可顯著提高多傳感器軌道級融合。在未來的工作中,我們將考慮使用攝像機對道路場景的理解來幫助物體融合感知。
-
傳感器
+關(guān)注
關(guān)注
2567文章
53068瀏覽量
768125 -
智能
+關(guān)注
關(guān)注
8文章
1733瀏覽量
120559 -
軌道
+關(guān)注
關(guān)注
0文章
40瀏覽量
11157
原文標題:利用時空證據(jù)和獨立視覺通道改善車輛環(huán)境感知的多傳感器融合
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
隧道管廊振動溫度傳感器:構(gòu)筑地下空間安全感知網(wǎng)絡(luò)

AGV機器人如何實現(xiàn)毫秒級避障?深度解析多傳感器融合的核心技術(shù)
仿生傳感器:讓機器擁有“生命感知”的神奇科技
融合視覺傳感器廠商銳思智芯完成B輪融資
從安防到元宇宙:RK3588如何重塑視覺感知邊界?
BEVFusion —面向自動駕駛的多任務(wù)多傳感器高效融合框架技術(shù)詳解

如何利用傳感器融合改進工業(yè) 4.0 生產(chǎn)的流程和物流
多通道傳感器接入集中控制頻率溫度 傳感器集線器帶來更多方便

如何用SS1系列顏色傳感器示教多通道顏色?

多傳感器融合在自動駕駛中的應(yīng)用趨勢探究
感知融合為自動駕駛與機器視覺解開當前無解場景之困
只有一個uart串口,如何接多個傳感器
精密制造的革新:光譜共焦傳感器與工業(yè)視覺相機的融合
計算機視覺中的圖像融合






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評論