 劉鐵巖談機器學習:隨波逐流的太多
劉鐵巖談機器學習:隨波逐流的太多
人工智能正受到越來越多的關注,而這波人工智能浪潮背后的最大推手就是“機器學習”。機器學習從業者在當下需要掌握哪些前沿技術?展望未來,又會有哪些技術趨勢值得期待?
近期,AI科技大本營聯合華章科技特別邀請到了微軟亞洲研究院副院長劉鐵巖博士進行在線公開課分享,為我們帶來微軟研究院最新的研究成果,以及對機器學習領域未來發展趨勢的展望。
大家好,我是劉鐵巖,來自微軟亞洲研究院。今天非常榮幸,能跟大家一起分享一下微軟研究院在機器學習領域取得的一些最新研究成果。

大家都知道,最近這幾年機器學習非常火,也取得了很多進展。這張圖總結了機器學習領域的最新工作,比如 ResNet、膠囊網絡、Seq2Seq Model、Attention Mechanism 、GAN、Deep Reinforcement Learning 等等。

這些成果推動了機器學習領域的飛速發展,但這并不意味著機器學習領域已經非常成熟,事實上仍然存在非常大的技術挑戰。比如現在主流機器學習算法需要依賴大量的訓練數據和計算資源,才能訓練出性能比較好的機器學習模型。同時,雖然深度學習大行其道,但我們對深度學習的理解,尤其是理論方面的理解還非常有限。深度學習為什么會有效,深度學習優化的損失函數曲面是什么樣子?經典優化算法的優化路徑如何?最近一段時間,學者們在這個方向做了很多有益的嘗試,比如討論隨機梯度下降法在什么條件下可以找到全局最優解,或者它所得到的局部最優解跟全局最優解之間存在何種關系。
再比如,最近很多學者開始用自動化的方式幫助機器學習尤其是深度學習來調節超參數、搜尋神經網絡的結構,相關領域稱為元學習。其基本思想是用一個機器學習算法去自動地指導另一個機器學習算法的訓練過程。但是我們必須要承認,元學習其實并沒有走出機器學習的基本框架。更有趣的問題是,如何能夠讓一個機器學習算法去幫助另一個算法突破機器學習的現有邊界,讓機器學習的效果更好呢?這都是我們需要去回答的問題。沿著這些挑戰,在過去的這幾年里,微軟亞洲研究院做了一些非常有探索性的學術研究。
對偶學習解決機器學習對大量有標簽數據的依賴
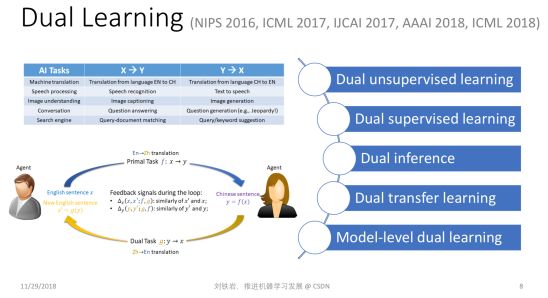
首先,我們看看對偶學習。對偶學習主要是為了解決現有深度學習方法對訓練數據過度依賴的問題。當我們沒有標注好的訓練數據時,是否還能做有意義的機器學習?在過去的幾年里,人們做了很多嘗試,比如無監督學習、半監督學習等等。但是無論如何,大家心里要清楚,只有有信號、有反饋、才能實現有效的學習,如果我們對這個世界一無所知,我們是不能進行有效的學習的。
沿著這個思路,我們在思考:除了人為提供的標簽以外,是不是存在其他有效的反饋信號,能夠形成學習的閉環?我們發現很多機器學習任務其實天然有結構對偶性,可以形成天然的閉環。
比如機器翻譯。一方面我們會關心從英文翻譯到中文,另一方面我們一定也關心從中文翻譯到英文,否則就無法實現兩個語種人群之間的無縫交流。再比如語音處理。我們關心語音識別的同時一定也關心語音合成,否則人和機器之間就沒有辦法實現真正的雙向對話。還有圖像理解、對話引擎、搜索引擎等等,其實它們都包含具有對偶結構的一對任務。
如何更加準確地界定人工智能的結構對偶性呢?我們說:如果第一個任務的輸入恰好是第二個任務的輸出,而第一個任務的輸出恰好是第二個任務的輸入,那么這兩個任務之間就形成了某種結構的“對偶性”。把它們放在一起就會形成學習的閉環 ,這就是“對偶學習”的基本思想。
有了這樣的思想以后,我們可以把兩個對偶任務放到一起學,提供有效的反饋信號。這樣即便沒有非常多的標注樣本,我們仍然可以提取出有效的信號進行學習。
對偶學習背后其實有著嚴格的數學解釋。當兩個任務互為對偶時,我們可以建立如下的概率聯系:

這里 X 和 Y 分別對應某個任務的輸入空間和輸出空間,在計算 X 和 Y 的聯合概率分布時有兩種分解方法,既可以分解成 P(x)P(y|x; f) ,也可以分解成 P(y)P(x|y; g)。這里,P(y|x; f) 對應了一個機器學習模型,當我們知道輸入 x 時,通過這個模型可以預測輸出 y 的概率,我們把這個模型叫主任務的機器學習模型,P(x|y; g) 則是反過來,稱之為對偶任務的機器學習模型。
有了這個數學聯系以后,我們既可以做有效的無監督學習,也可以做更好的有監督學習和推斷。比如我們利用這個聯系可以定義一個正則項,使得有監督學習有更好的泛化能力。再比如,根據 P(x)P(y|x; f) 我們可以得到一個推斷的結果,反過來利用貝葉斯公式,我們還可以得到用反向模型 g 做的推斷,綜合兩種推斷,我們可以得到更準確的結果。我們把以上提到的對偶學習技術應用在了機器翻譯上,取得了非常好的效果,在中英新聞翻譯任務上超過了普通人類的水平。
解決機器學習對大計算量的依賴
輕量級機器學習
最近一段時間,在機器學習領域有一些不好的風氣。有些論文里會使用非常多的計算資源,比如動輒就會用到幾百塊 GPU卡 甚至更多的計算資源。這樣的結果很難復現,而且在一定程度上導致了學術研究的壟斷和馬太效應。
那么人們可能會問這樣的問題:是不是機器學習一定要用到那么多的計算資源?我們能不能在計算資源少幾個數量級的情況下,仍然訓練出有意義的機器學習模型?這就是輕量級機器學習的研究目標。

在過去的幾年里,我們的研究組做了幾個非常有趣的輕量級機器學習模型。比如在 2015 發表的 lightLDA 模型,它是一個非常高效的主題模型。在此之前,世界上已有的大規模主題模型一般會用到什么樣的計算資源?比如 Google 的 LDA 使用上萬個 CPU cores,才能夠通過幾十個小時的訓練獲得 10 萬個主題。為了降低對計算資源的需求,我們設計了一個基于乘性分解的全新采樣算法,把每一個 token 的平均采樣復雜度降低到 O(1),也就是說采樣復雜度不隨著主題數的變化而變化。因此即便我們使用這個主題模型去做非常大規模的主題分析,它的運算復雜度也是很低的。例如,我們只使用了 300 多個 CPU cores,也就是大概 8 臺主流的機器,就可以實現超過 100 萬個主題的主題分析。
這個例子告訴大家,其實有時我們不需要使用蠻力去解決問題,如果我們可以仔細分析這些算法背后的機理,做算法方面的創新,就可以在節省幾個數量級計算資源的情況下做出更大、更有效的模型。
同樣的思想我們應用到了神經網絡上面,2016 年發表的 LightRNN算法是迄今為止循環神經網絡里面最高效的實現。當我們用 LigthtRNN 做大規模的語言模型時,得到的模型規模比傳統的 RNN 模型小好幾個數量級。比如傳統模型大小在100GB 時,LightRNN 模型只有50MB,并且訓練時間大幅縮短 。不僅如此,LightRNN模型的 perplexity比傳統RNN還要更好。
可能有些同學會產生疑問:怎么可能又小又好呢?其實,這來源于我們在循環神經網絡語言模型的算法上所做的創新設計。我們把對 vocabulary 的表達從一維變到了兩維,并且允許不同的詞之間共享某一部分的 embedding。至于哪些部分共享、哪些不共享,我們使用了一個二分圖匹配的算法來確定。

第三個輕量型機器學習的算法叫 LightGBM,這個工具是 GBDT 算法迄今為止最高效的實現。LightGBM的背后是兩篇 NIPS 論文,其中同樣包含了很多技術創新,比如 Gradient-based one-side sampling,可以有效減少對樣本的依賴; Exclusive feature bundling,可以在特征非常多的情況下,把一些不會發生沖突的特征粘合成比較 dense 的少數特征,使得建立特征直方圖非常高效。同時我們還提出了 Voting-based parallelization 機制,可以實現非常好的加速比。所有這些技巧合在一起,就成就了LightGBM的高效率和高精度。
分布式機器學習
雖然我們做了很多輕量級的機器學習算法,但是當訓練數據和機器學習模型特別大的時候,可能還不能完全解決問題,這時我們需要研究怎樣利用更多的計算節點實現分布式的機器學習。

我們剛剛出版了一本新書——《分布式機器學習:算法、理論與實踐》,對分布式機器學習做了非常好的總結,也把我們很多研究成果在這本書里做了詳盡的描述。下面,我挑其中幾個點,跟大家分享。
分布式機器學習的關鍵是怎樣把要處理的大數據或大模型進行切分,在多個機器上做并行訓練。一旦把這些數據和模型放到多個計算節點之后就會涉及到兩個基本問題:首先,怎樣實現不同機器之間的通信和同步,使得它們可以協作把機器學習模型訓練好。其次,當每個計算節點都能夠訓練出一個局部模型之后,怎樣把這些局部模型做聚合,最終形成一個統一的機器學習模型。
數據切分
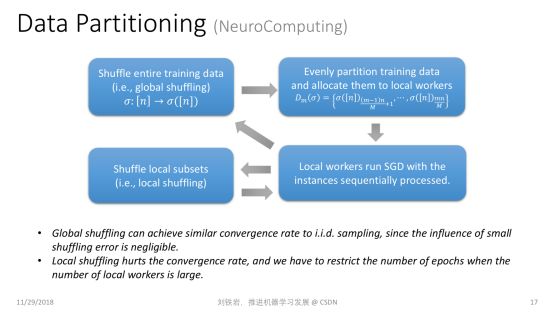
數據切分聽起來很簡單,其實有很多門道。舉個例子,一個常見的方式就是把數據做隨機切分。比如我們有很多訓練數據,隨機切分成 N 份,并且把其中一份放到某個局部的工作節點上去訓練。這種切分到底有沒有理論保證?
我們知道機器學習有一個基本的假設,就是學習過程中的數據是獨立同分布采樣得來的,才有理論保證。但是前面提到的數據切分其實并不是隨機的數據采樣。從某種意義上講,獨立同分布采樣是有放回抽樣,而數據切分對應于無放回抽樣。一個很有趣的理論問題是,我們在做數據切分時,是不是可以像有放回抽樣一樣,對學習過程有一定的理論保證呢?這個問題在我們的研究發表之前,學術界是沒有完整答案的。
我們證明了:如果我先對數據進行全局置亂,然后再做數據切分,那么它和有放回的隨機采樣在收斂率上是基本一致的。但是如果我們只能做局部的數據打亂,二者之間的收斂率是有差距的。所以如果我們只能做局部的數據打亂,就不能訓練太多 epoch,否則就會與原來的分布偏離過遠,使得最后的學習效果不好。
異步通信

說完數據切分,我們再講講各個工作節點之間的通信問題。大家知道,有很多流行的分布式框架,比如 MapReduce,可以實現不同工作節點之間的同步計算。但在機器學習過程中,如果不同機器之間要做同步通信,就會出現瓶頸:有的機器訓練速度比較快,有的機器訓練速度比較慢,而整個集群會被這個集群里最慢的機器拖垮。因為其他機器都要跟它完成同步之后,才能往前繼續訓練。
為了實現高效的分布式機器學習,人們越來越關注異步通信,從而避免整個集群被最慢的機器拖垮。在異步通信過程中,每臺機器完成本地訓練之后就把局部模型、局部梯度或模型更新推送到全局模型上去,并繼續本地的訓練過程,而不去等待其他的機器。
但是人們一直對異步通信心有余悸。因為做異步通信的時候,同樣有一些機器運算比較快,有一些機器運算比較慢,當運算比較快的機器將其局部梯度或者模型更新疊加到全局模型上以后,全局模型的版本就被更新了,變成了很好的模型。但是過了一段時間,運算比較慢的機器又把陳舊的梯度或者模型更新,疊加到全局模型上,這就會把原來做得比較好的模型給毀掉。人們把這個問題稱為“延遲更新”。不過在我們的研究之前,沒有人定量地刻畫這個延遲會帶來多大的影響。
在去年 ICML 上我們發表了一篇論文,用泰勒展開式定量刻畫了標準的隨機梯度下降法和異步并行隨機梯隊下降法的差距,這個差距主要是由于延遲更新帶來的。如果我們簡單粗暴地使用異步 SGD,不去處理延遲更新,其實就是使用泰勒展開里零階項作為真實的近似。既然它們之間的差距在于高階項的缺失,如果我們有能力把這些高階項通過某種算法補償回來,就可以使那些看起來陳舊的延遲梯度煥發青春。這就是我們提出的帶有延遲補償的隨機梯度下降法。
這件事說起來很簡單,但實操起來有很大的難度。因為在梯度函數的泰勒展開中的一階項其實對應于原損失函數的二階項,也就是所謂的海森矩陣(Hessian Matrix)。當模型很大時,計算海森矩陣要使用的內存和計算量都會非常大,使得這個算法并不實用。在我們的論文里,提出了一個非常高效的對海森矩陣的近似。我們并不需要真正去計算非常高維的海森矩陣并存儲它,只需要比較小的計算和存儲代價就可以實現對海參矩陣相當精確的近似。 在此基礎上,我們就可以利用泰勒展開,實現對原來的延遲梯度的補償。我們證明了有延遲補償的異步隨機梯度下降法的收斂率比普通的異步隨機梯度下降法要好很多,而且各種實驗也表明它的效果確實達到了我們的預期。
模型聚合
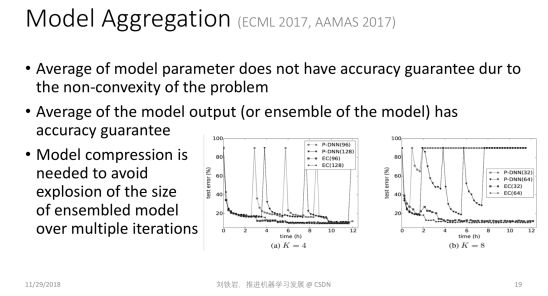
除了異步通信以外,每個局部節點計算出一個局部模型之后,怎樣聚合在一起也是一個值得思考的問題。在業界里最常用的方式是把各個不同的局部模型做簡單的參數平均。但是,從理論上講,參數平均僅在凸問題上是合理的。如果大家對凸函數的性質有一些了解,就知道如果模型是凸的,那么我們對凸模型參數進行平均后得到的模型的性能,不會比每個模型性能的平均值差。
但是當我們用這樣的方式去處理深層神經網絡這類嚴重非凸的模型時,就不再有理論保證了。我們在 2017 年這幾篇論文里指出了這個理論的缺失,并指出我們不應該做模型參數的平均,而是應該做模型輸出的平均,這樣才能獲得性能的保障,因為雖然神經網絡模型是非凸的,但是常用的損失函數本身是凸的。
但是模型輸出的平均相當于做了模型的集成,它會使模型的尺寸變大很多倍。當機器學習不斷迭代時,這種模型的集成就會導致模型尺寸爆炸的現象。為了保持凸性帶來的好處,同時又不會受到模型尺寸爆炸的困擾,我們需要在整個機器學習流程里不僅做模型集成,還要做有效的模型壓縮。
這就是我們提出的模型集成-壓縮環路。通過模型集成,我們保持了凸性帶來的好處,通過模型壓縮,我們避免了模型尺寸的爆炸,所以最終會取得一個非常好的折中效果。
深度學習理論探索
接下來我們講講如何探索深度學習的理論邊界。我們都知道深度學習很高效,任意一個連續函數,只要一個足夠復雜的深度神經網絡都可以逼近得很好。但是這并不表示機器就真能學到好的模型。因為當目標函數的界面太復雜時,我們可能掉入局部極小值的陷阱,無法得到我們想要的最好模型。當模型太復雜時,還容易出現過擬合,在優化過程中可能做的不錯,可是當你把學到的模型應用到未知的測試數據上時,效果不一定很好。因此對于深度學習的優化過程進行深入研究是很有必要的。
g-Space


這個方向上,今年我們做了一個蠻有趣的工作,叫 g-Space Deep Learning。
這個工作研究的對象是圖像處理任務里常用的一大類深度神經網絡,這類網絡的激活函數是ReLU函數。ReLU是一個分段線性函數,在負半軸取值為0,在正半軸則是一個線性函數。ReLU Network 有一個眾所周知的特點,就是正尺度不變性,但我們對于這個特點對神經網絡優化影響的理解非常有限。
那么什么是正尺度不變性呢?我們來舉個例子。這是一個神經網絡的局部,假設中間隱節點的激活函數是ReLU函數。當我們把這個神經元兩條輸入邊上面的權重都乘以一個正常數 c,同時把輸出邊上的權重除以同樣的正常數 c,就得到一個新的神經網絡,因為它的參數發生了變化。但是如果我們把整個神經網絡當成一個整體的黑盒子來看待,這個函數其實沒有發生任何變化,也就是無論什么樣的輸入,輸出結果都不變。這就是正尺度不變性。
這個不變性其實很麻煩,當激活函數是 ReLu函數時,很多參數完全不一樣的神經網絡,其實對應了同一個函數。這說明當我們用神經網絡的原始參數來表達神經網絡時,參數空間是高度冗余的空間,因為不同的參數可能對應了同一個網絡。這種冗余的空間是不能準確表達神經網絡的。同時在這樣的冗余空間里可能存在很多假的極值點,它們是由空間冗余帶來的,并不是原問題真實的極值點。我們平時在神經網絡優化過程中遇到的梯度消減、梯度爆炸的現象,很多都跟冗余的表達有關系。
既然參數空間冗余有這么多缺點,我們能不能解決這個問題?如果不在參數空間里做梯度下降法,而是在一個更緊致的表達空間里進行優化,是不是就可以解決這些問題呢?這個愿望聽起來很美好,但實際上做起來非常困難。因為深度神經網絡是一個非常復雜的函數,想對它做精確的緊致表達,需要非常強的數學基礎和幾何表達能力。我們組里的研究員們做了非常多的努力,經過了一年多的時間,才對這個緊致的空間做了一個完整的描述,我們稱其為 g-Space 。
g-Space 其實是由神經網絡中一組線性無關的通路組成的,所謂通路就是從輸入到輸出所走過的一條不回頭的通路,也就是其中一些邊的連接集合。我們可以證明,如果把神經網絡里的這些通路組成一個空間,這個空間里的基所組成的表達,其實就是對神經網絡的緊致表達。

有了 g-Space 之后,我們就可以在其中計算梯度,同時也可以在 g-Space 里計算距離。有了這個距離之后,我們還可以在 g-Space 里定義一些正則項,防止神經網絡過擬合。
我們的論文表明,在新的緊致空間里做梯度下降的計算復雜度并不高,跟在參數空間里面做典型的 BP 操作復雜度幾乎是一樣的。換言之,我們設計了一個巧妙的算法,它的復雜度并沒有增加,但卻回避了原來參數空間里的很多問題,獲得了對于 ReLU Network 的緊致表達,并且計算了正確的梯度,實現了更好的模型優化。
有了這些東西之后,我們形成了一套新的深度學習優化框架。這個方法非常 general,它并沒有改變目標函數,也沒改變神經網絡的結構,僅僅是換了一套優化方法,相當于整個機器學習工具包里面只換了底層,就可以訓練出效果更好的模型來。
元學習的限制

第四個研究方向也非常有趣,我們管它叫 Learning to Teach,中文我沒想到特別好的翻譯,現在權且叫做“教學相長”。
我們提出 Learning to Teach 這個研究方向,是基于對現在機器學習框架的局限性的反思。這個式子雖然看起來很簡單,但它可以描述一大類的或者說絕大部分機器學習問題。這個式子是什么意思?首先 (x, y) 是訓練樣本,它是從訓練數據集 D 里采樣出來的。 f(ω) 是模型,比如它可能代表了某一個神經網絡。我們把 f(ω)作用在輸入樣本 x 上,就會得到一個對輸入樣本的預測。然后,我們把預測結果跟真值標簽 y 進行比較,就可以定義一個損失函數 L。
現在絕大部分機器學習都是在模型空間里最小化損失函數。所以這個式子里有三個量,分別是訓練數據 D,損失函數 L,還有模型空間 Ω。 這三個量都是超參數,它們是人為設計好的,是不變的。絕大部分機器學習過程,是在這三樣給定的情況下去做優化,找到最好的 ω,使得我們在訓練數據集上能夠最小化人為定義的損失函數。即便是這幾年提出的 meta learning 或者 learning2learn,其實也沒有跳出這個框架。因為機器學習框架本身從來就沒有規定最小化過程只能用梯度下降的方法,你可以用任何方法,都超不出這個這個式子所表達的框架。
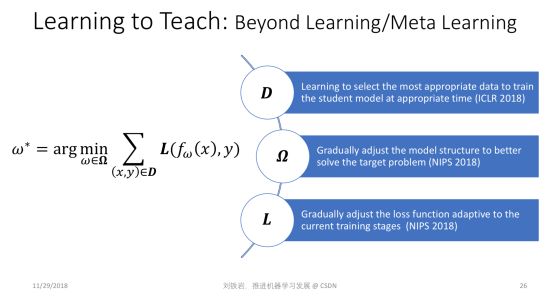
但是為什么訓練數據集 D、損失函數 L 和模型參數空間 Ω 必須人為預先給定?如果不實現給定,而是在機器學習過程中動態調整,會變成什么樣子?這就是所謂的 Learning to Teach。我們希望通過自動化的手段,自動調節訓練數據集 D、損失函數 L 和模型參數空間 Ω,以期拓展現有機器學習的邊界,幫助我們訓練出更加強大的機器學習模型。
要實現這件事情其實并不簡單,我們需要用全新的思路和視角。我們在今年連續發表了三篇文章,對于用自動化的方式去確定訓練數據、函數空間和損失函數,做了非常系統的研究。

我給大家形象地描述一下我們的研究。 比如我們怎么用自動化的方式去選擇合適的數據?其實很簡單。除了原來的機器學習的模型以外,我們還有一個教學模型 teacher model。這個模型會把原來的機器學習的過程、所處的階段、效果好壞等作為輸入,輸出對下一階段訓練數據的選擇。這個 teacher model 會根據原來的機器學習模型的進展過程,動態選擇最適合的訓練數據,最大限度提高性能。同時teacher model也會把機器學習在交叉驗證集上的效果作為反饋,自我學習,自我提高。

同樣 model teaching 的環路中也存在一個 teacher model ,它會根據原來的機器學習過程所處的階段、訓練的效果,選擇合適的函數空間,讓原來的機器學習擴大自己的搜索范圍,這個過程也是自適應的、動態的。原來的機器學習模型我們叫 student model,和我們引入的教學模型 teacher model 之間進行互動,就可以將學習過程推向一個新的高度。

同樣,teacher model也可以動態調整原來student model 所要優化的目標。 比如,我們的學習目標可以從簡到難,最開始的時候,一個簡單的學習目標會讓我們很快學到一些東西,但是這個學習目標可能和我們最終問題的評價準則相差很遠。我們不斷把簡單平滑的目標,向著問題評價的復雜的非連續函數逼近,就會引導 student model 不斷提高自己的能力,最后實現很好的學習效果。
總結一下,當我們有一個 teacher model,它可以動態地設計訓練數據集、改變模型空間、調整目標函數時,就會使得原來“student model”的訓練更寬泛、更有效,它的邊界就會被放大。 我們在三篇論文里面分別展示了很多不同數據集上的實驗結果。

我自己認為 Learning to Teach 非常有潛力,它擴大了傳統機器學習的邊界。我們的三篇論文僅僅是拋磚引玉,告訴大家這件事情可以做,但前面路還很長。
到此為止,我把最近這一兩年微軟亞洲研究院在機器學習領域所做的一些研究成果跟大家做了分享,它們只是我們研究成果的一個小小的子集,但是我覺得這幾個方向非常有趣,希望能夠啟發大家去做更有意義的研究。
展望未來
現在機器學習領域的會議越來越膨脹,有一點點不理智。每一年那么多論文,甚至都不知道該讀哪些。人們在寫論文、做研究的時候,有時也不知道重點該放在哪里。比如,如果整個學術界都在做 learning2learn,是不是我應該做一篇 learning2learn 的論文?大家都在用自動化的方式做 neural architecture search,我是不是也要做一篇呢?現在這種隨波逐流、人云亦云的心態非常多。
我們其實應該反思:現在大家關注的熱點是不是涵蓋了所有值得研究的問題?有哪些重要的方向其實是被忽略的?我舉個例子,比如輕量級的機器學習,比如 Learning to Teach,比如對于深度學習的一些理論探索,這些方面在如今火熱的研究領域里面涉及的并不多,但這些方向其實非常重要。只有對這些方向有非常深刻的認識,我們才能真正推動機器學習的發展。希望大家能夠把心思放到那些你堅信重要的研究方向上,即便當下它還不是學術界關注的主流。
接下來我們對機器學習未來的發展做一些展望,這些展望可能有些天馬行空,但是卻包含了一些有意義的哲學思考,希望對大家有所啟發。
量子計算
第一個方面涉及機器學習和量子計算之間的關系。量子計算也是一個非常火的研究熱點,但是當機器學習碰到量子計算,會產生什么樣的火花?其實這是一個非常值得我們思考的問題。
目前學術界關注的問題之一是如何利用量子計算的計算力去加速機器學習的優化過程,這就是所謂的quantum speedup。但是,這是否是故事的全部呢?大家應該想一想,反過來作為一名機器學習的學者,我們是不是有可能幫助量子計算呢?或者當機器學習和量子計算各自往前走,碰到一起的時候會迸發出怎樣的新火花?

其實在量子計算里有一些非常重要的核心問題,比如我們要去評估或者或者預測 quantum state(量子態),然后才能把量子計算的結果取出來。這個過程在傳統理論里面已經證明,在最壞情況下,我們就需要指數級的采樣,才能對 quantum state 做比較好的估計。但這件事情會帶來負面影響,量子計算雖然很快,但是如果探測量子態耗費了大量時間來做采樣,就會拖垮原來的加速效果,最后合在一起,并沒有實現任何加速。
我們知道很多最壞情況下非常復雜的問題,比如 NP Complete問題,用機器學習的方法去解,其實可以在平均意義上取得非常好的效果。我們今年在ACML上獲得最佳論文的工作就是用機器學習的方法來解travelling salesman問題,取得了比傳統組合優化更高效的結果。沿著這個思路,我們是不是可以用機器學習幫助處理量子計算里的問題,比如quantum state prediction,是不是根本不需要指數級的采樣,就可以得到一個相當好的估計?在線學習、強化學習等都能在這方面有所幫助。
同時,量子和機器學習理論相互碰撞時,會發生一些非常有趣的現象。我們知道,量子有不確定性,這種不確定性有的時候不見得是件壞事,因為在機器學習領域,我們通常希望有不確定性,甚至有時我們還會故意在數據里加噪聲,在模型訓練的過程中加噪聲,以期獲得更好的泛化性能。
從這個意義上講,量子計算的不確定性是不是反而可以幫助機器學習獲得更好的泛化性能?如果我們把量子計算的不確定性和機器學習的泛化放在一起,形成一個統一的理論框架,是不是可以告訴我們它的 Trade-off 在哪里?是不是我們對量子態的探測就不需要那么狠?因為探測得越狠可能越容易 overfit。是不是有一個比較好的折中?其實這些都是非常有趣的問題,也值得量子計算的研究人員和機器學習的研究人員共同花很多年的時間去探索。
以簡治繁
第二個方向也很有趣,它涉及到我們應該以何種方式來看待訓練數據。深度學習是一個以繁治繁的過程,為了去處理非常復雜的訓練數據,它使用了一個幾乎更復雜的模型。但這樣做真的值得嗎?跟我們過去幾十年甚至上百年做基礎科學的思路是不是一致的?

在物理、化學、生物這些領域,人們追求的是世界簡單而美的規律。不管是量子物理,還是化學鍵,甚至經濟學、遺傳學,很多復雜的現象背后其實都是一個二階偏微分方程,比如薛定諤方程,比如麥克斯韋方程組,等等。這些方程都告訴我們,看起來很復雜的世界,其實背后的數學模型都是簡單而美的。這些以簡治繁的思路,跟深度學習是大相徑庭的。
機器學習的學者也要思考一下,以繁治繁的深度學習真的是對的嗎?我們把數據看成上帝,用那么復雜的模型去擬合它,這樣的思路真的對嗎?是不是有一點舍本逐末了?以前的這種以簡治繁的思路,從來都不認為數據是上帝,他們認為背后的規律是上帝,數據只是一個表象。
我們要學的是生成數據的規律,而不是數據本身,這個方向其實非常值得大家去思考。要想沿著這個方向做很好的研究,我們需要機器學習的學者擴大自己的知識面,更多地去了解動態系統或者是偏微分方程等,以及傳統科學里的各種數學工具,而不是簡單地使用一個非線性的模型去做數據擬合。
Improvisational Learning

第三個方向關乎的是我們人類到底是如何學習的。到今天為止,深度學習在很多領域的成功,其實都是做模式識別。模式識別聽起來很神奇,其實是很簡單的一件事情。幾乎所有的動物都會模式識別。人之所以有高的智能,并不是因為我們會做模式識別,而是因為我們有知識,有常識。基于這個理念,Yann LeCun 一個新的研究方向叫 Predictive Learning(預測學習)。它的思想是什么?就是即便我們沒有看到事物的全貌,因為我們有常識,有知識,我們仍然可以做一定程度的預測,并且基于這個預測去做決策。這件事情已經比傳統的模式識別高明很多,它會涉及到人利用知識和常識去做預測的問題。
但是,反過來想一想,我們的世界真的是可以預測的嗎?可能一些平凡的規律是可以預測的,但是我們每個人都可以體會到,我們的生活、我們的生命、我們的世界大部分都是不可預測的。所以這句名言很好,The only thing predictable about life is its unpredictability(人生中唯一能預測的就是其不可預測性)。
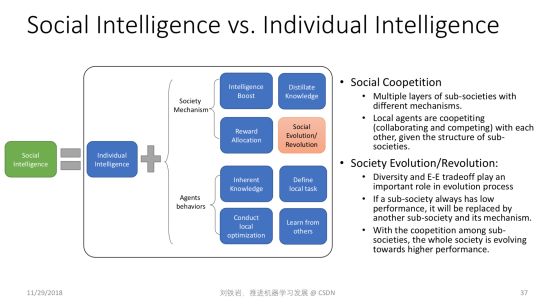
我們既然活在一個不可預測的世界里,那么我們到底是怎樣從這個世界里學習,并且越來越強大?以下只是一家之言,我們猜測人類其實在做一件事情,叫 Improvisation,什么意思?就是我們每個人其實是為了生存在跟這個世界抗爭。我們每天從世界里面學習的東西,都是為了應付將來未知的異常。當一件不幸的事情發生的時候,我們如何才能生存下來?其實是因為我們對這個世界有足夠的了解,于是會利用已有的知識,即興制定出一個方案,讓我們規避風險,走過這個坎。
我們希望在我們的眼里,世界的熵在降低。我們對它了解越多,它在我們的眼里的熵越低。同時,我們希望當環境發生變化時,比如意外發生時,我們有能力即興地去處理。這張PPT 里面描述的即興學習框架就是我們在跟環境互動,以及在做各種思想實驗,通過無監督的方式自我學習應對未知異常的能力。
從這個意義上講,這個過程其實跟 Predictive Learning 不一樣,跟強化學習也不一樣,因為它沒有既定的學習規律和學習目標,并且它是跟環境做交互,希望能夠處理未來的未知環境。這其實就跟我們每個人積累一身本事一樣,為的就是養兵千日用兵一時。當某件事情發生時,我怎么能夠把一身的本事使出來,活下去。這個過程能不能用數學的語言描述? Improvisational Learning 能不能變成一個新的機器學習研究方向?非常值得我們思考。
群體智慧
最后一個展望涉及到一個更哲學的思辨:人類的智能之所以這么高,到底是因為我們個體非常強大,還是因為我們群體非常強大?今天絕大部分的人工智能研究,包括深度學習,其實都在模仿人類個體的大腦,希望學會人類個體的學習能力。可是捫心自問,人類個體的學習能力真的比大猩猩等人類近親高幾個數量級嗎?答案顯然不是,但是今天人類文明發展的程度,跟猴子、跟大猩猩他們所處社區的文明的發展程度相比卻有天壤之別。
所以我們堅信人類除了個體聰明以外,還有一些更加特殊的東西,那就是社會結構和社會機制,使得我們的智能突飛猛進。比如文字的產生,書籍的產生,它變成了知識的載體,使得某一個人獲得的對世界的認知,可以迅速傳播給全世界其他人,這個社會機制非常重要,會加速我們的進化。
再者,社會分工不同會使得每個人只要優化自己的目標,讓自己變強大就可以了。各個領域里有各自的大師,而這些大師的互補作用,使得我們社會蓬勃發展。
所以社會的多樣性,社會競爭、進化、革命、革新,這些可能都是人類有今天這種高智能的原因。而這些東西在今天的機器學習領域,鮮有人去做非常好的建模。我們堅信只有對這些事情做了非常深入的研究,我們才能真正了解了人的智能,真的了解了機器學習,把我們的研究推向新的高度。
-
機器
+關注
關注
0文章
784瀏覽量
40757 -
模型
+關注
關注
1文章
3261瀏覽量
48914 -
機器學習
+關注
關注
66文章
8424瀏覽量
132765
原文標題:劉鐵巖談機器學習:隨波逐流的太多,我們需要反思
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
傳統機器學習方法和應用指導

如何選擇云原生機器學習平臺
什么是機器學習?通過機器學習方法能解決哪些問題?

NPU與機器學習算法的關系
具身智能與機器學習的關系
人工智能、機器學習和深度學習存在什么區別

【「時間序列與機器學習」閱讀體驗】+ 簡單建議
人工智能、機器學習和深度學習是什么
機器學習算法原理詳解
機器學習在數據分析中的應用
深度學習與傳統機器學習的對比
機器學習的經典算法與應用
請問PSoC? Creator IDE可以支持IMAGIMOB機器學習嗎?
機器學習8大調參技巧
大牛談如何學習機器視覺?





 工商網監
工商網監
評論