 tf.data API的功能和最佳實踐操作
tf.data API的功能和最佳實踐操作
GPU 和 TPU 可以從根本上縮短執行單個訓練步驟所需的時間。欲將性能提高到極致,則需要有一個高效的輸入管道,能夠在當前步驟完成之前為下一步提供數據。tf.data API 有助于構建靈活高效的輸入管道。本文介紹了 tf.data API 的功能和最佳實踐操作,用于在各種模型和加速器上構建高性能 TensorFlow 輸入管道。
本文將主要介紹下列內容:
描述 tf.dataAPI 上下文中的常見性能優化
討論應用轉換順序的性能影響
總結設計高性能 TensorFlow 輸入管道的最佳實踐操作。
輸入數據管道的結構
一個典型的 TensorFlow 訓練輸入管道可以構建為 ETL 過程:
提取:從持久存儲中讀取數據 - 本地(例如 HDD 或 SSD)或遠程(例如 GCS 或 HDFS)
轉換:使用 CPU 內核對數據進行解析和執行預處理操作,例如圖像解壓縮,數據擴充轉換(例如隨機裁剪,翻轉和顏色失真),隨機洗牌和批處理
加載:將變換后的數據加載到執行機器學習模型的加速器設備(例如,GPU 或 TPU)上。
這種模式有效地利用了 CPU,與此同時為了模型訓練這種繁重的工作,還保留了加速器。此外,將輸入管道視為 ETL 過程提供了便于性能優化應用的結構。
使用 tf.estimator.EstimatorAPI 時,前兩個階段(提取和轉換)將在傳遞給 tf.estimator.Estimator 的 input_fn 中捕獲。在代碼中,這可能會看起來像以下(naive, sequential)執行情況:
defparse_fn(example): "Parse TFExample records and perform simple data augmentation." example_fmt = { "image": tf.FixedLengthFeature((), tf.string, ""), "label": tf.FixedLengthFeature((), tf.int64, -1) } parsed = tf.parse_single_example(example, example_fmt) image = tf.image.decode_image(parsed["image"]) image = _augment_helper(image) # augments image using slice, reshape, resize_bilinear returnimage, parsed["label"]definput_fn(): files = tf.data.Dataset.list_files("/path/to/dataset/train-*.tfrecord") dataset = files.interleave(tf.data.TFRecordDataset) dataset = dataset.shuffle(buffer_size=FLAGS.shuffle_buffer_size) dataset = dataset.map(map_func=parse_fn) dataset = dataset.batch(batch_size=FLAGS.batch_size) returndataset
下一部分將基于此輸入管道構建,添加性能優化。
性能優化
首先,我們定義要使用的模型種類。主智能體會擁有全局網絡,且每個本地工作器智能體在自己的進程中都會擁有此網絡的副本。我們會使用模型子類化對模型進行實例化。雖然模型子類化會使進程更冗長,但卻為我們提供了最大的靈活性。
正如您從我們的正向傳遞中看到的,我們的模型會采用輸入和返回策略概率的分對數和值。
隨著新的計算設備(諸如 GPU 和 TPU)不斷問世,訓練神經網絡的速度變得越來越快,這種情況下 CPU 處理很容易成為瓶頸。tf.dataAPI 為用戶提供構建塊,以設計有效利用 CPU 的輸入管道,優化 ETL 過程的每個步驟。
Pipelining
要執行訓練步驟,您必須首先提取并轉換訓練數據,然后將其提供給在加速器上運行的模型。然而,在一個簡單的同步執行中,當 CPU 正在準備數據時,加速器則處于空閑狀態。相反,當加速器正在訓練模型時,CPU 則處于空閑狀態。因此,訓練步驟時間是 CPU 預處理時間和加速器訓練時間的總和。
Pipelining 將一個訓練步驟的預處理和模型執行重疊。當加速器正在執行訓練步驟 N 時,CPU 正在準備步驟 N + 1 的數據。這樣做的目的是可以將步驟時間縮短到極致,包含訓練以及提取和轉換數據所需時間(而不是總和)。
如果沒有使用 pipelining,則 CPU 和 GPU / TPU 在大部分時間處于閑置狀態:
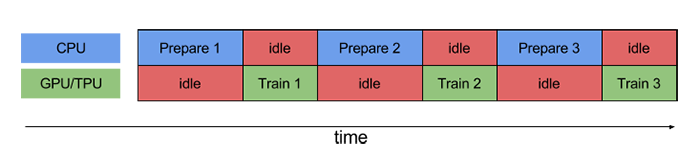
而使用 pipelining 技術后,空閑時間顯著減少:
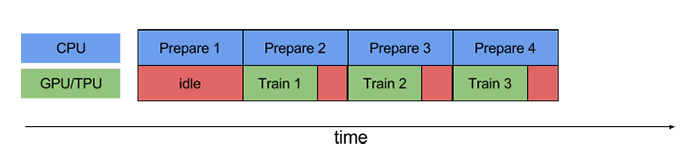
tf.dataAPI 通過 tf.data.Dataset.prefetch 轉換提供了一個軟件 pipelining 操作機制,該轉換可用于將數據生成的時間與所消耗時間分離。特別是,轉換使用后臺線程和內部緩沖區,以便在請求輸入數據集之前從輸入數據集中預提取元素。因此,為了實現上面說明的 pipelining 效果,您可以將 prefetch(1) 添加為數據集管道的最終轉換(如果單個訓練步驟消耗 n 個元素,則添加 prefetch(n))。
要將此更改應用于我們的運行示例,請將:
dataset = dataset.batch(batch_size=FLAGS.batch_size)returndataset
更改為:
dataset = dataset.batch(batch_size=FLAGS.batch_size)dataset = dataset.prefetch(buffer_size=FLAGS.prefetch_buffer_size)returndataset
請注意,在任何時候只要有機會將 “制造者” 的工作與 “消費者” 的工作重疊,預取轉換就會產生效益。前面的建議只是最常見的應用程序。
將數據轉換并行化
準備批處理時,可能需要預處理輸入元素。為此,tf.dataAPI 提供了 tf.data.Dataset.map 轉換,它將用戶定義的函數(例如,運行示例中的 parse_fn)應用于輸入數據集的每個元素。由于輸入元素彼此獨立,因此可以跨多個 CPU 內核并行化預處理。為了實現這一點,map 轉換提供了 thenum_parallel_calls 參數來指定并行度。例如,下圖說明了將 num_parallel_calls = 2 設置為 map 轉換的效果:
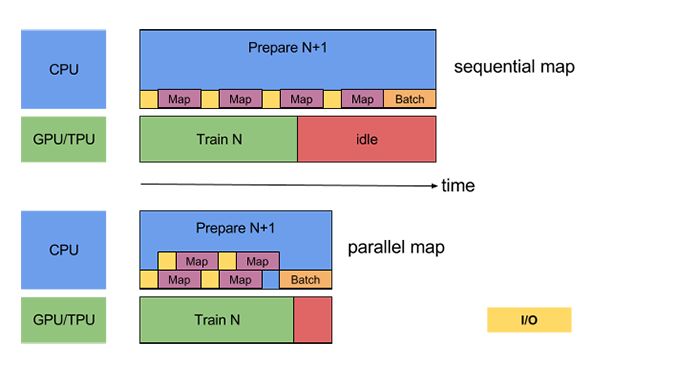
為 num_parallel_calls 參數選擇最佳值取決于您的硬件,訓練數據的特征(例如其大小和形狀),Map 功能的成本以及在 CPU 上同時進行的其他處理;一個簡單的啟發式方法是使用可用的 CPU 內核數。例如,如果執行上述示例的機器有 4 個內核,則設置 num_parallel_calls = 4 會更有效。另一方面,將 num_parallel_calls 設置為遠大于可用 CPU 數量的值可能會導致調度效率低下,從而導致速度減慢。
要將此更改應用于我們的運行示例,請將:
dataset = dataset.map(map_func=parse_fn)
變更為:
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)
此外,如果您的批處理大小為數百或數千,您的 pipeline 可能還可以通過并行化批處理創建而從中獲益。為此,tf.dataAPI 提供了 tf.contrib.data.map_and_batch 轉換,它有效地 “融合” 了 map 和批處理的轉換。
要將此更改應用于我們的運行示例,請將:
dataset = dataset.map(map_func=parse_fn, num_parallel_calls=FLAGS.num_parallel_calls)dataset = dataset.batch(batch_size=FLAGS.batch_size)
更改為:
dataset = dataset.apply(tf.contrib.data.map_and_batch( map_func=parse_fn, batch_size=FLAGS.batch_size))
將數據提取并行化
在實際環境中,輸入數據可能被遠程存儲(例如,GCS 或 HDFS),因為輸入數據不適合本地,或者因為訓練是分布式的,因此在每臺機器上復制輸入數據是沒有意義的。在本地讀取數據時運行良好的數據集管道在遠程讀取數據時可能會成為 I / O 的瓶頸,因為本地存儲和遠程存儲之間存在以下差異:
首字節時間:從遠程存儲中讀取文件的第一個字節可能比本地存儲長幾個數量級
讀取吞吐量:雖然遠程存儲通常提供較大的聚合帶寬,但讀取單個文件可能只能使用此帶寬的一小部分。
另外,一旦將原始字節讀入存儲器,也可能需要對數據進行反序列化或解密(例如,protobuf),這就增加了額外的系統開銷。無論數據是本地存儲還是遠程存儲,都存在這種開銷,如果數據未被有效預取,則在遠程情況下情況可能更糟。
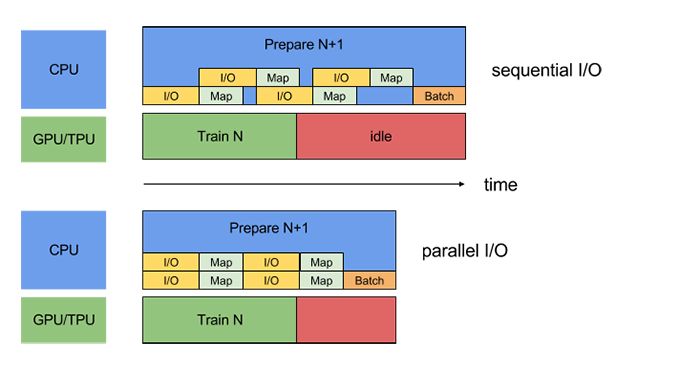
為了減輕各種數據提取開銷的影響,tf.dataAPI 提供了 tf.contrib.data.parallel_interleave 轉換。使用此轉換可以將其他數據集(例如數據文件讀取器)的內容執行和交錯并行化。可以通過 cycle_length 參數指定要重疊的數據集的數量。
為 parallel_interleavetransformation 提供 cycle_length = 2 的效果如下圖所示:
要將此更改應用于我們的運行示例,請將:
dataset = files.interleave(tf.data.TFRecordDataset)
更改為:
dataset = files.apply(tf.contrib.data.parallel_interleave( tf.data.TFRecordDataset, cycle_length=FLAGS.num_parallel_readers))
由于負載或網絡事件,遠程存儲系統的吞吐量可能會隨時間而變化。為了解釋這種差異,parallel_interleave 轉換可以選擇使用預取。(請參考 tf.contrib.data.parallel_interleave 了解詳情 https://tensorflow.google.cn/api_docs/python/tf/contrib/data/parallel_interleave?hl=zh-CN)。
默認情況下,parallel_interleave 轉換提供了元素的確定性排序使之重現。作為預取的替代方法(在某些情況下可能無效),parallel_interleave 轉換還提供了一個選項,能夠以保證排序作為代價來提高性能。尤其是如果 sloppy 參數設置為 true,則轉換可能會偏離其確定的排序,在請求下一元素時那些不可用文件將會暫時跳過。
性能注意事項
tf.dataAPI 圍繞可組合轉換而設計,為用戶提供了靈活性。雖然這些轉換中的許多都是可交換的,但某些轉換的排序具有性能上的影響。
Map 和 batch
調用傳遞給 map 轉換的用戶定義函數會帶來與調度和執行用戶定義函數相關的系統開銷。通常,與函數執行的計算量相比,這種系統開銷很小。但是,如果 map 幾乎沒有使用,那么這種開銷可能會占據總成本的大多數。在這種情況下,我們建議對用戶定義的函數進行矢量化(即,讓它一次對一批輸入進行操作),并在 map 轉換之前應用 batch 轉換。
Map 和 cache
tf.data.Dataset.cache 轉換可以在內存或本地存儲中緩存數據集。如果傳遞給 map 轉換的用戶定義函數非常高,只要結果數據集仍然適合內存或本地存儲,就可以在 map 轉換后應用緩存轉換。如果用戶定義的函數增加了存儲數據集所需的空間超出緩存容量,請考慮在訓練作業之前預處理數據以減少資源使用。
Map 和Interleave / Prefetch / Shuffle
許多轉換(包括 Interleave,prefetch 和 shuffle)會保留元素的內部緩沖區。如果傳遞給 map 變換的用戶定義函數改變了元素的大小,那么 map 變換的順序和緩沖元素的變換會影響內存使用。通常來說,除非由于性能需要不同的排序(例如,啟用 map 和 batch 轉換的融合)的情況,否則我們建議選擇帶來較低內存占用的順序。
Repeat 和 Shuffle
tf.data.Dataset.repeat 轉換以有限(或無限)次數重復輸入數據; 每次數據重復通常稱為 epoch。
tf.data.Dataset.shuffle 轉換隨機化數據集示例的順序。
如果在 shuffle 變換之前應用 repeat 變換,則 epoch 的邊界模糊。也就是說,某些元素可以在其他元素出現之前重復一次。另一方面,如果在 repeat 變換之前應用 shuffle 變換,則性能可能在與 shuffle 轉換的內部狀態的初始化相關的每個 epoch 時期的開始時減慢。換句話說,前者(repeat before shuffle)提供更好的性能,而后者(shuffle before repeat)提供更強的排序保證。
如果可能,我們推薦使用融合的 tf.contrib.data.shuffle_and_repeat 轉換,它結合了兩方面的優點(良好的性能和強大的排序保證)。否則,我們建議在 repeating 之前進行 shuffling。
最佳的實踐操作摘要
以下是設計輸入管道的最佳實踐操作摘要:
使用 prefetch 轉換重疊 “制造者” 和 “消費者” 的工作。特別是,我們建議將 prefetch(n)(其中 n 是訓練步驟消耗的元素 / 批次數)添加到輸入管道的末尾,以便在 CPU 上執行的轉換與加速器上的訓練重疊
通過設置 num_parallel_calls 參數來并行化 map 轉換。我們建議使用可用 CPU 內核數作為其參數值
如果使用 batch 轉換將預處理元素組合成批處理,我們建議使用融合的 map_and_batch 轉換,特別是在您使用大型批處理的情況下
如果您正在處理遠程存儲的數據和 / 或需要反序列化,我們建議使用 parallel_interleave 轉換來重疊來自不同文件的數據的讀取(和反序列化)
向傳遞到 map 轉換的廉價用戶定義函數進行向量化,以分攤與調度和執行函數相關的系統開銷
如果您的數據可以存儲于內存中,請使用 cache 轉換在第一個 epoch 期間將其緩存在內存中,以便后續 epoch 期間避免發生與讀取,解析和轉換相關的系統開銷
如果預處理增加了數據的大小,我們建議您首先應用 interleave,prefetch 和 shuffle(如果可能的話)以減少內存使用量
我們建議在 repeat 轉換之前應用 shuffle 轉換,理想情況下使用融合的 shuffle_and_repeat 轉換。
-
加速器
+關注
關注
2文章
796瀏覽量
37839 -
神經網絡
+關注
關注
42文章
4771瀏覽量
100714 -
管道
+關注
關注
3文章
145瀏覽量
17961
原文標題:tf.data API,構建高性能 TensorFlow 輸入管道
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
PyODPS開發中的最佳實踐
6行代碼如何實現對TF卡的讀寫功能
虛幻引擎的紋理最佳實踐
構建簡單數據管道,為什么tf.data要比feed_dict更好?
TensorFlow 2.0將專注于簡單性和易用性
6行代碼實現對TF卡的讀寫功能

支持動態并行的CUDA擴展功能和最佳應用實踐
local-data-api-gateway本地數據API網關





 工商網監
工商網監
評論