 中文自然語言處理的語料集合及其構建現狀
中文自然語言處理的語料集合及其構建現狀
作者劉煥勇,語言學碩士,目前就職于中國科學院軟件研究所,主要從事信息抽取,知識圖譜,情感分析, 社會計算等自然語言處理研發工作,興趣包括:語言資源構建、信息抽取與知識圖譜、輿情監測與社會計算。
本項目包含中文自然語言處理的語料集合,包括語義詞、領域共時、歷時語料庫、評測語料庫等。本項目簡單談談自己對語言資源的感想以及目前自己進行語言資源構建的現狀。
介紹
語言資源,本身是一個寬泛的概念,即語言+資源,語言指的是資源的限定域,資源=資+源,是資料的來源或者匯總,加在一起,也就形成了這樣一種界定:任何語言單位形成的集合,都可以稱為語言資源。語言資源是自然語言處理任務中的一個必不可少的組成部分,一方面語言資源是相關語言處理任務的支撐,為語言處理任務提供先驗知識進行輔助,另一方面,語言處理任務也為語言資源提出了需求,并能夠對語言資源的搭建、擴充起到技術性的支持作用。因此,隨著自然語言處理技術的不斷發展,自然語言處理需求在各個領域的不斷擴張、應用,相關語言資源的構建占據了越來越為重要的地位。作者在碩士期間所在的研究機構為國家語言資源監測與研究平面媒體中心,深受導師所傳授的語言資源觀影響,畢業后在實際的學習、工作過程中,動手實踐,形成了自己的一些淺薄的語言資源認識,現在寫出來,供大家一起討論,主要介紹一些自己對語言資源的搜索,搭建過程中的一些心得以及自己目前在語言資源建設上的一些工作。
語言資源的分類
介紹中說到,任何語言單位的集合都可以稱為語言資源,比如我有一個個人的口頭禪集合,這個就可以稱為一個語言資源庫,在你實際生活中進行言語活動時,你其實就在使用這個語言資源庫。再比如說,一個班級中的學生名單,其實也可以當作是一種語言資源,這個語言資源在進行班級學生點名、考核的時候也大有幫助。當然,此處所討論的語言資源是從自然語言處理應用的角度上出發的。總的來說,我把它歸為以下兩種類型:
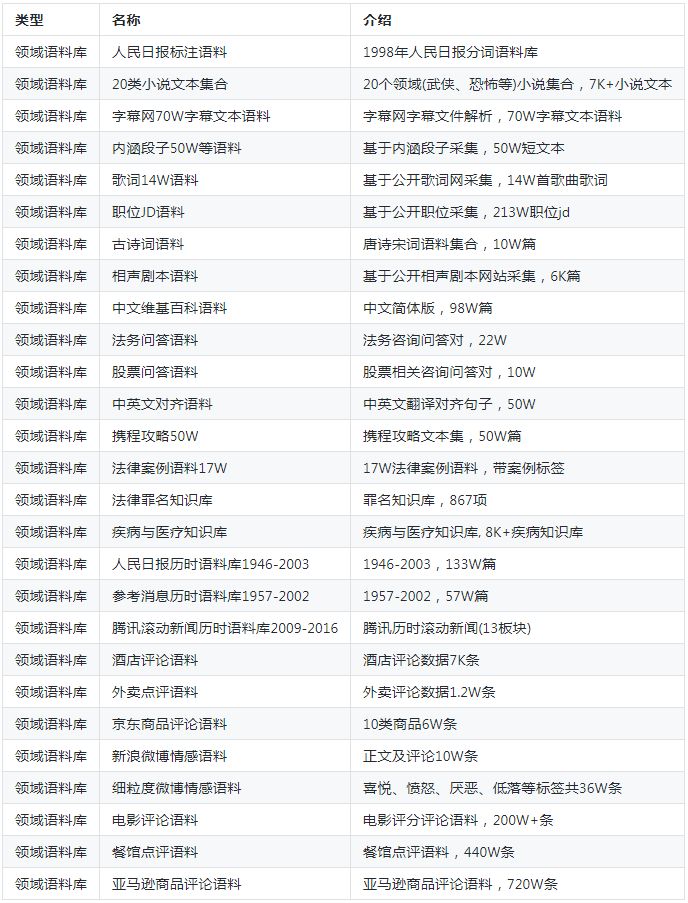
1、領域語料庫
領域語料庫,是從語料的這個角度來講的,這里的語料,界定成文本級別(以自然語句為基礎級別形成的文本集合,即可以是句子、段落、篇章等)。領域語料庫,可以根據不同的劃分規則而形成不同的語料類別:
1)根據所屬領域,可以進一步細化成不同領域的語料庫。包括金融領域語料、醫藥領域語料、教育領域語料、文學領域語料等等。
2)根據所屬目的,可以進一步細化為:評測語料(為自然語言處理技術pk而人工構造的一些評測語料,如ACE,MUC等國際評測中所出現的如semeval2014,snli等);工具語料(指供自然語言處理技術提供資源支撐的語料)
3)根據語料加工程度的不同,可進一步分為:熟語料(指在自然語言單位上添加人工的標簽標注,如經過分詞、詞性標注、命名實體識別、依存句法標注形成的語料),生語料(指直接收集而未經加工形成的語言資源集,如常見的微博語料,新聞語料等)
4)根據語料語種的不同,可進一步分為:單語語料和多語語料,多語語料指的是平行語料,常見于機器翻譯任務中的雙語對齊語料(漢-阿平行語料庫,漢-英平行語料庫)等。
5)根據語料規模的不同,可以進一步分為:小型語料庫,中型語料庫,大型語料庫。至于小型、中型、大型的界定,可根據實際領域語料的規模而動態調整。
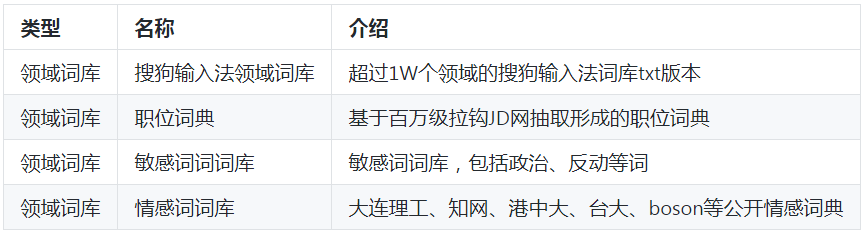
2、領域詞庫
領域詞庫,指以句級以下語言單位形成的語言資源庫,這個層級的語言單位可以是筆畫、偏旁部首、字、詞、短語等。同樣的,領域詞庫也可以進一步細分。
1)領域特征詞庫。這里所說的領域特征詞庫,指的是與領域強相關,具有領域區別能力形成的詞語集合,如體育領域中常見的“籃球”、“足球”等詞,文學領域常見的“令狐沖”、“魯迅”等詞,又如敏感詞庫等,這些詞常常可作為分類特征而存在。
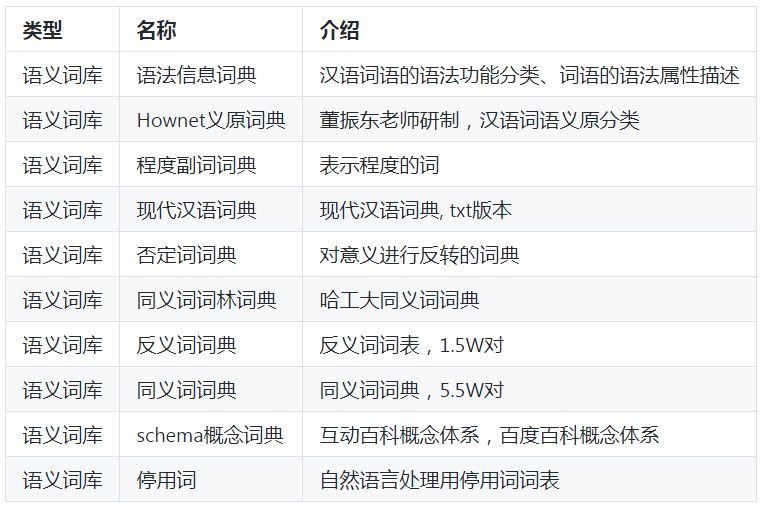
2)語法語義詞庫。語義詞庫的側重點在與語言的語法層面和語義層面:
語法詞庫:北大的語法信息詞典,北大的實體概念詞典、Hownet語義詞典這三類詞典,這幾個語法詞庫,在對詞的語法功能上都做了不同的工作,對詞的內部結構信息進行了詳細的標注,如北大的語法信息詞典,以詞類為劃分標準講漢語的常用詞進行了劃分,并對詞性、搭配(前接成分和后接成分)進行了詳細的標注;Hownet語義詞典從義項的角度對詞的義元進行了分解和注釋。
語義詞庫:這類語義詞,側重點不在詞語的內部語法結構,而在詞語的整體語義上。這類詞庫,常見的詞庫有哈工大發布的同義詞詞林擴展版,這個詞庫將同義詞按照語義的相近程度進行了不同層次的聚類,可以作為同義詞擴展提供幫助。另一個是情感分析任務中常用的情感詞典,這類詞典主要公開的詞典包括大連理工大學信息檢索實驗室公開的情感本體詞庫、hownet、香港中文大學、***清華大學公開的情感詞庫(具體包括情感詞庫、否定詞庫、強度詞庫)等。另外,工業界,有boson公開的微博情感詞庫(詞的規模比較大,但標注信息不是很精準)。還有的,則是中文的反義詞庫等,這個可以參考我的github項目,里面對這些詞庫也有一些涉及。
語言資源的問題
語言資源的搭建,指的是語言資源的整個搭建過程。其實是要解決四個問題,一個是語言資源的收集問題;二是語言資源的融合標準化問題;三是語言資源的動態更新問題;四是語言資源的共享與聯盟問題。下面就這四點展開闡述:
1、語言資源收集的問題。語言資源搜索過程中有三步走策略,在這個步驟完成之后,會得到一系列的詞庫。這些詞庫可能初期不會特別完善,往往還需要人工使用啟發式規則進行人工去噪的工作。
2、語言資源的融合標準化問題。通過不同方式收集起來的語言資源,往往會存在一個格式不對稱的問題,這有點像知識圖譜中的知識融合問題。因此,為了解決這個問題,我們通常需要制定一個標準化的語言資源格式,例如,在構建情感詞表的過程當中,有的情感詞表沒有強度標記,有的強度值范圍不一樣,有的情感詞表的標記不一,這個時候往往需要標準化,給定一個標準化的樣式,再將不同來源的情感詞按照這個標記做相應的調整。我在實際的工作過程中,常常把這種問題類別成知識圖譜構建過程中的schema搭建問題,信息抽取過程中的slot-definition問題。先把規范和標準搭好,再去統一標準化。
3、語言資源的動態更新問題。知識和信息的價值,在很大程度上都在于它的一種實時性,語言資源作為一種常識性知識庫,能夠保證自身的一種與時俱進,將能夠最大限度地發揮自身的價值。而從實踐的角度上來說,語言資源的動態更新,可以靠人工去維持,去動態及時更新,也可以建立一種動態監測和更新機制,讓機器自動地去更新。這類其實可以參考知識圖譜更新的相關工作。
4、語言資源的共享與聯盟問題。語言資源是否共享,其實是一個與業務敏感以及開源意識想結合的一種決策,有的資源因為某種業務敏感或者開源意識不夠open而無法共享,當然還有其他因素成分在,不過,語言資源最好是需要共享的,這樣能夠最大力度的發揮語言資源在各個領域的應用。語言資源的聯盟問題,更像是對開源語言資源的一種鏈接與互聯。這類問題是對當前的資源零散、碎片化問題的一個思考,前面也說到,目前情感分析的詞表有很多個,語法和語義詞庫也有很多個,但每個人在構建時的出發點不同,構建者也分布在不同的高校或機構當中,這些資源雖然在個數上會有增長,但隨著時間的推移,這種零散化的現象將會越來越嚴重。
語言資源的實踐
本項目以采集公開的人民日報與參考消息為例進行歷時的新聞采集為例, 公開網站中公開了1946-2003年的人民日報語料,1957-2002年的參考消息語料, 采集這種具有長遠歷史信息的語料對于歷史人文研究以及語言演變有重大意義,本項目放在newspaper目錄下。
運行方式: scrapy crawl travel
主要函數包括:
classTravelSpider(scrapy.Spider):name='travel''''資訊采集主控函數'''defstart_requests(self):Data=BuildData()date_list=Data.create_dates()fordateindate_list:print(date)date_url='http://www.laoziliao.net/ckxx/%s'%dateparam={'url':date_url,'date':date}yieldscrapy.Request(url=date_url,meta=param,callback=self.get_urllist,dont_filter=True)'''獲取頁面新聞列表'''defget_urllist(self,response):selector=etree.HTML(response.text)date_url=response.meta['url']urls=[i.split('#')[0]foriinselector.xpath('//ul/li/a/@href')ifdate_urlini]forurlinset(urls):param={'url':url,'date':response.meta['date']}yieldscrapy.Request(url=url,meta=param,callback=self.page_parser,dont_filter=True)'''新聞字段內容解析'''defpage_parser(self,response):selector=etree.HTML(response.text)articles=selector.xpath('//div[@class="article"]')titles=selector.xpath('//h2/text()')contents=[]forarticleinarticles:content=article.xpath('string(.)')contents.append(content)papers=zip(titles,contents)foriinpapers:item=TravelspiderItem()item['url']=response.meta['url']item['date']=response.meta['date']item['title']=i[0]item['content']=i[1]yielditemreturn
語言資源構建現狀
作者在學習和工作之余,根據語言資源搭建策略,構建起了語義詞庫、領域詞庫、領域語料庫、評測語料庫。種類約53種,具體如下:
語義知識庫
領域詞庫
領域語料庫
評測語料庫

總結
1、本項目闡述了語言資源的相關感想,并給出了目前語言資源的構建現狀,目前為止收集了四個大類共53小類的語言資源數據集。
2、本項目中所涉及到的報告內容均來源于網上公開資源,對此免責聲明。
3、如果有需要用到以上作者收集到的這些語料庫,可以聯系作者獲取。
4、自然語言處理,是人工智能皇冠上的一顆明珠,懂語言者得天下,語言資源在自然語言處理中扮演著舉足輕重的作用,懂語言資源者,分得天下。目前開放的網絡環境,對語言資源的大繁榮提供了很大的契機。語言資源構建是一門學問,也是一種手段,現在自然語言處理技術也對語言資源的構建提供了技術上的支持,如何把握語言資源搜索策略,搭建策略,重點解決語言資源的動態更新、共享與聯盟問題,將是語言資源建設未來需要解決的問題。
-
數據集
+關注
關注
4文章
1208瀏覽量
24690 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13553 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:最全NLP語料資源集合及其構建現狀
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論