 北大開源了一個中文分詞工具包,名為——PKUSeg
北大開源了一個中文分詞工具包,名為——PKUSeg
分詞技術是一種比較基礎的模塊,就英文而言,詞與詞之間通常由空格分開,因此英文分詞則要簡單的多,但中文和英文的詞是有區別的,再加上中國文化的博大精深,分詞的時候要考慮的情況比英文分詞要復雜的多,如果處理不好就會直接影響到后續詞性標注、句法分析等的準確性,
目前,我們最常用的分詞工具大概有四種哈工大LTP、中科院計算所NLPIR、清華大學THULAC和jieba。
不過最近,北大開源了一個中文分詞工具包,名為 ——PKUSeg,基于Python。據介紹其準確率秒殺THULAC和結巴分詞等工具。
一經開源,pkuseg已經在GitHub上獲得1738個Star,244個Fork(GitHub地址:https://github.com/lancopku/PKUSeg-python)
pkuseg具有如下幾個特點:
多領域分詞:不同于以往的通用中文分詞工具,此工具包同時致力于為不同領域的數據提供個性化的預訓練模型。根據待分詞文本的領域特點,用戶可以自由地選擇不同的模型。 我們目前支持了新聞領域,網絡文本領域和混合領域的分詞預訓練模型,同時也擬在近期推出更多的細領域預訓練模型,比如醫藥、旅游、專利、小說等等。
更高的分詞準確率:相比于其他的分詞工具包,當使用相同的訓練數據和測試數據,pkuseg可以取得更高的分詞準確率。
支持用戶自訓練模型:支持用戶使用全新的標注數據進行訓練。
各類分詞工具包的性能對比
前面有提到說pkuseg的準確率遠超其他分詞工具包,現在就是用數據說話的時候了,下面就是在 Linux 環境下,各工具在新聞數據 (MSRA) 和混合型文本 (CTB8) 數據上的準確率測試情況
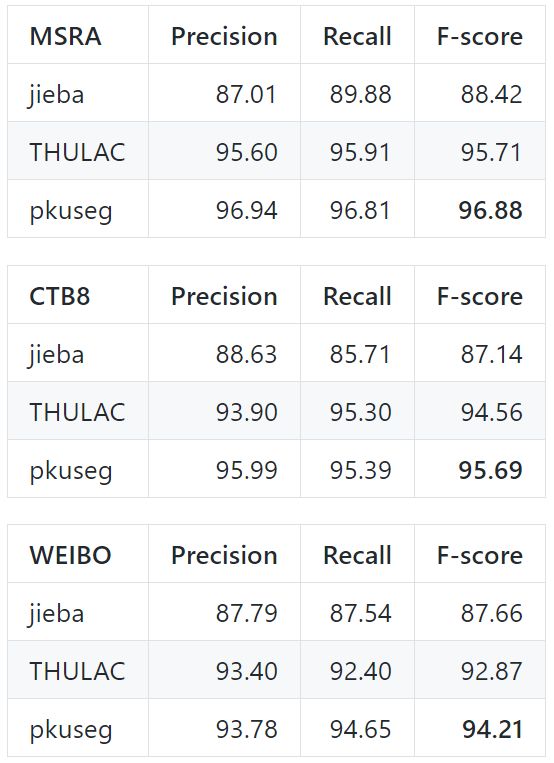
測試使用的是第二屆國際漢語分詞評測比賽提供的分詞評價腳本,從上圖看出結巴分詞準確率最低,
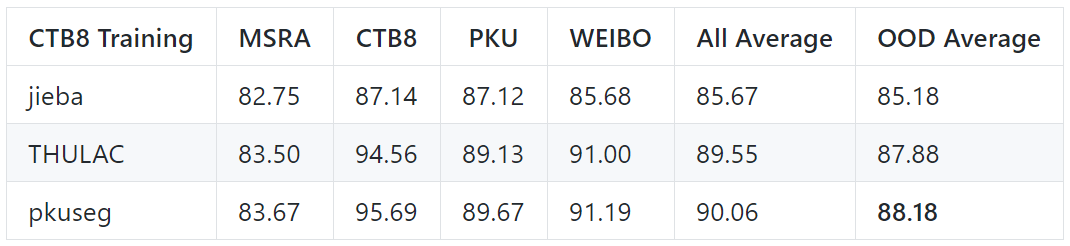
跨領域測試結果
以下是在其它領域進行測試,以模擬模型在“黑盒數據”上的分詞效果。
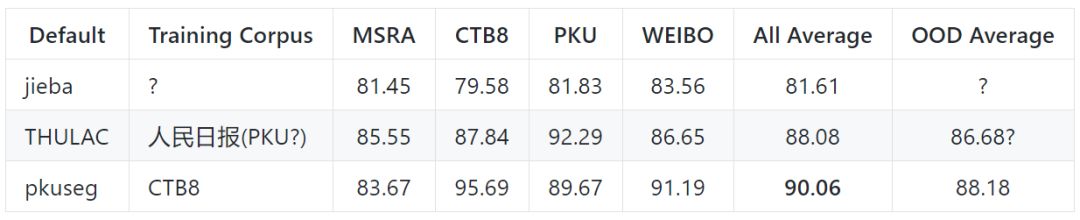
默認模型在不同領域的測試效果
以下是各個工具包的默認模型在不同領域的測試效果
使用方式
代碼示例1:使用默認模型及默認詞典分詞
importpkusegseg=pkuseg.pkuseg()#以默認配置加載模型text=seg.cut('我愛北京***')#進行分詞print(text)
代碼示例2:設置用戶自定義詞典
importpkuseglexicon=['北京大學','北京***']#希望分詞時用戶詞典中的詞固定不分開seg=pkuseg.pkuseg(user_dict=lexicon)#加載模型,給定用戶詞典text=seg.cut('我愛北京***')#進行分詞print(text)
代碼示例3:使用其它模型
importpkusegseg=pkuseg.pkuseg(model_name='./ctb8')#假設用戶已經下載好了ctb8的模型#并放在了'./ctb8'目錄下,通過設置model_name加載該模型text=seg.cut('我愛北京***')#進行分詞print(text)
代碼示例4:對文件分詞
importpkusegpkuseg.test('input.txt','output.txt',nthread=20)#對input.txt的文件分詞輸出到output.txt中,#使用默認模型和詞典,開20個進程
代碼示例5:訓練新模型
importpkuseg#訓練文件為'msr_training.utf8'#測試文件為'msr_test_gold.utf8'#模型存到'./models'目錄下,開20個進程訓練模型pkuseg.train('msr_training.utf8','msr_test_gold.utf8','./models',nthread=20)
此外,pkuseg提供了三種在不同類型數據上訓練得到的模型,根據具體需要,用戶可以選擇不同的預訓練模型:
MSRA:在MSRA(新聞語料)上訓練的模型。
下載地址:https://pan.baidu.com/s/1twci0QVBeWXUg06dK47tiA
CTB8:在CTB8(新聞文本及網絡文本的混合型語料)上訓練的模型。隨pip包附帶的是此模型。
下載地址:https://pan.baidu.com/s/1DCjDOxB0HD2NmP9w1jm8MA
WEIBO:在微博(網絡文本語料)上訓練的模型。
下載地址:https://pan.baidu.com/s/1QHoK2ahpZnNmX6X7Y9iCgQ
最后附上前面提到的另外四大分詞工具的GitHub地址:
1、LTP:https://github.com/HIT-SCIR/ltp
2、NLPIR:https://github.com/NLPIR-team/NLPIR
3、THULAC:https://github.com/thunlp/THULAC
4、jieba:https://github.com/yanyiwu/cppjieba
-
Linux
+關注
關注
87文章
11312瀏覽量
209702 -
開源
+關注
關注
3文章
3363瀏覽量
42535 -
python
+關注
關注
56文章
4797瀏覽量
84752
原文標題:準確率秒殺結巴分詞,北大開源全新中文分詞工具包PKUSeg
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數據技術】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
TSP工具包軟件的應用說明
最新Simplicity SDK軟件開發工具包發布
基于EasyGo Vs工具包和Nl veristand軟件進行的永磁同步電機實時仿真
FPGA仿真工具包軟件EasyGo Vs Addon介紹

蘋果推出全新開源Swift軟件包
使用freeRTOS開發工具包時,在哪里可以找到freeRTOS的版本?
新加坡推出Project Moonshot -- 這是一款生成式人工智能測試工具包,用于應對LLM安全和安保挑戰

Hugging Face推出開源機器人代碼庫LeRobot
QE for Motor V1.3.0:汽車開發輔助工具解決方案工具包

labview工具包下載
利用ProfiShark 構建便攜式網絡取證工具包

Torch TensorRT是一個優化PyTorch模型推理性能的工具






 工商網監
工商網監
評論