 梳理數據庫故障恢復問題的本質及其發展優化方向
梳理數據庫故障恢復問題的本質及其發展優化方向
在數據庫系統發展的歷史長河中,故障恢復問題始終伴隨左右,也深刻影響著數據庫結構的發展變化。通過故障恢復機制,可以實現數據庫的兩個至關重要的特性:Durability of Updates以及Failure Atomic,也就是我們常說的的ACID中的A和D。磁盤數據庫由于其卓越的性價比一直以來都占據數據庫應用的主流位置。然而,由于需要協調內存和磁盤兩種截然不同的存儲介質,在處理故障恢復問題時也增加了很多的復雜度。隨著學術界及工程界的共同努力及硬件本身的變化,磁盤數據庫的故障恢復機制也不斷的迭代更新,尤其近些年來,隨著NVM的浮現,圍繞新硬件的研究也如雨后春筍出現。
本文希望通過分析不同時間點的關鍵研究成果,來梳理數據庫故障恢復問題的本質,其發展及優化方向,以及隨著硬件變化而發生的變化。文章將首先描述故障恢復問題本身;然后按照基本的時間順序介紹傳統數據庫中故障恢復機制的演進及優化;之后思考新硬件帶來的機遇與挑戰;并引出圍繞新硬件的兩個不同方向的研究成果;最后進行總結。
問題
數據庫系統運行過程中可能遇到的故障類型主要包括,Transaction Failure,Process Failure,System Failure以及Media Failure。其中Transaction Failure可能是應用程序的主動回滾,也可能是并發控制機制發現沖突后的強制Abort;Process Failure指的是由于各種原因導致的進程退出,進程內存內容會丟失;System Failure來源于操作系統或硬件故障,同樣會導致內存丟失;Media Failure則是存儲介質的不可恢復損壞。數據庫系統需要正確合理的處理這些故障,從而保證系統的正確性。為此需要提供兩個特性:
Durability of Updates:已經Commit的事務的修改,故障恢復后仍然存在;
Failure Atomic:失敗事務的所有修改都不可見。
因此,故障恢復的問題描述為:即使在出現故障的情況下,數據庫依然能夠通過提供Durability及Atomic特性,保證恢復后的數據庫狀態正確。然而,要解決這個問題并不是一個簡單的事情,由于內存及磁盤不同的數據組織方式及性能差異,為了不顯著犧牲數據庫性能,長久以來人們對故障恢復機制進行了一系列的探索。
Shadow Paging
1981年,JIM GRAY等人在《The Recovery Manager of the System R Database Manager》采用了一種非常直觀的解決方式Shadow Paging[1]。System R的磁盤數據采用Page為最小的組織單位,一個File由多個Page組成,并通過稱為Direcotry的元數據進行索引,每個Directory項紀錄了當前文件的Page Table,指向其包含的所有Page。采用Shadow Paging的文件稱為Shadow File,如下圖中的File B所示,這種文件會包含兩個Directory項,Current及Shawing。
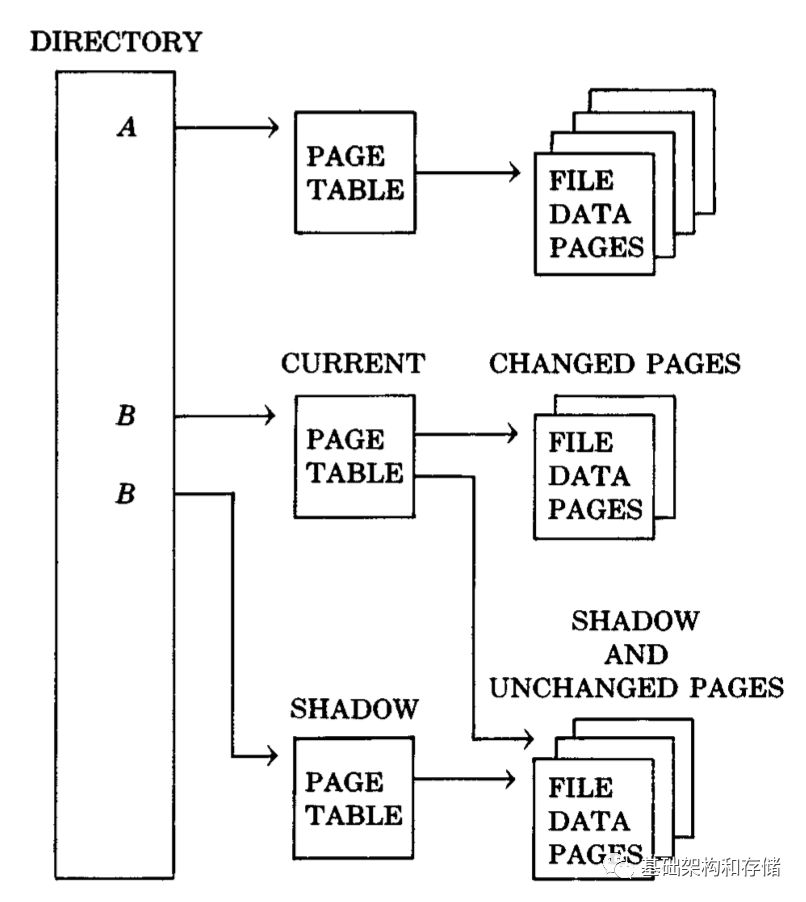
事務對文件進行修改時,會獲得新的Page,并加入Current的Page Table,所有的修改都只發生在Current Directory;事務Commit時,Current指向的Page刷盤,并通過原子的操作將Current的Page Table合并到Shadow Directory中,之后再返回應用Commit成功;事務Abort時只需要簡單的丟棄Current指向的Page;如果過程中發生故障,恢復時只需要恢復Shadow Directory,相當于對所有未提交事務的回滾操作。Shadow Paging很方便的實現了:
Durability of Updates:事務完成Commit后,所有修改的Page已經落盤,合并到Shadow后,其所有的修改可以在故障后恢復出來。
Failure Atomic:回滾的事務由于沒有Commit,從未影響Shadow Directory,因此其所有修改不可見。
雖然Shadow Paging設計簡單直觀,但它的一些缺點導致其并沒有成為主流,首先不支持Page內并發,一個Commit操作會導致其Page上所有事務的修改被提交,因此一個Page內只能包含一個事務的修改;其次不斷修改Page的物理位置,導致很難將相關的頁維護在一起,破壞局部性;另外,對大事務而言,Commit過程在關鍵路勁上修改Shadow Directory的開銷可能很大,同時這個操作還必須保證原子;最后,增加了垃圾回收的負擔,包括對失敗事務的Current Pages和提交事務的Old Pages的回收。
WAL
由于傳統磁盤順序訪問性能遠好于隨機訪問的特征,采用Logging的故障恢復機制意圖利用順序寫的Log來記錄對數據庫的操作,并在故障恢復后通過Log內容將數據庫恢復到正確的狀態。簡單的說,采用Log機制的數據庫需要在每次修改數據內容前先寫順序寫對應的Log,同時為了保證恢復時可以從Log中看到最新的數據庫狀態,要求Log先于對應的數據內容落盤,也就是常說的Write Ahead Log,WAL。除此之外,事務完成Commit前還需要在Log中記錄對應的Commit標記,以供恢復時通過Log了解當前的事務狀態,因此還需要關注Commit標記和事務中數據內容的落盤順序。根據Log中記錄的內容可以分為三類:Undo-Only,Redo-Only,Redo-Undo。
Undo-Only Logging
Undo-Only Logging的Log記錄可以表示未
Durability of Updates:Data強制刷盤保證,已經Commit的事務由于其所有Data都已經在Commit標記之前落盤,因此會一直存在;
Failure Atomic:Undo Log內容保證,失敗事務的已刷盤的修改會在恢復階段通過Undo日志回滾,不再可見。
然而Undo-Only依然有Page內并發的問題,如果兩個事務的修改落到一個Page中,一個事務提交前需要的強制Flush操作會導致同Page所有事務的Data落盤,可能會早于對應的Log項從而損害WAL。同時,Commit前的強制數據刷盤會導致關鍵路徑上過于頻繁的磁盤隨機訪問。
Redo-Only Logging
不同于Undo-Only,采用Redo-Only的Log中記錄的是修改后的新值。對應地,Commit時需要保證Log中的Commit標記需要在事務的任何事務羅盤前落盤,即落盤順序為Log記錄->Commit標記->Data。恢復時同樣根據Commit標記判斷事務狀態,并通過Redo Log中記錄的新值將已經Commit,但數據沒有落盤的事務修改重放。
Durability of Updates:Redo Log內容保證,已提交事務的未刷盤的修改,利用Redo Log中的內容重放,之后可見;
Failure Atomic:阻止Commit前Data落盤保證,失敗事務的修改不會出現在磁盤上,自然不可見。
Redo-Only同樣有Page內并發的問題,同Page中的多個不同事務,只要有一個未提交就不能刷盤,這些數據全部都需要維護在內存中,會造成較大的內存壓力。
Redo-Undo Logging
可以看出的只有Undo或Redo的Logging方式的問題主要來自與對Commit標記及Data落盤順序的限制,而這種限制歸根結底來源于Log信息中對新值或舊值的缺失。因此Redo-Undo采用同時記錄新值和舊值的方式來取消對刷盤順序的限制。
Durability of Updates:Redo 內容保證,已提交事務的未刷盤的修改,利用Redo Log中的內容重放,之后可見;
Failure Atomic:Undo內容保證,失敗事務的已刷盤的修改會在恢復階段通過Undo日志回滾,不再可見。
如此一來,同Page的不同事務提交就變得很簡單。同時可以將連續的數據攢著進行批量的刷盤已利用磁盤較高的順序寫性能。
Force and Steal
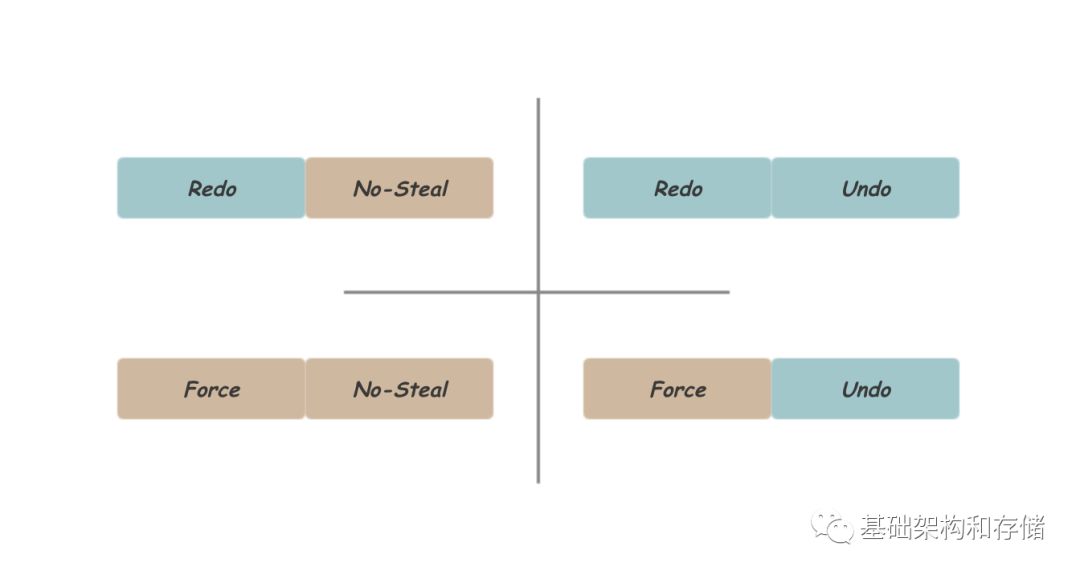
從上面看出,Redo和Undo內容分別可以保證Durability和Atomic兩個特性,其中一種信息的缺失需要用嚴格的刷盤順序來彌補。這里關注的刷盤順序包含兩個維度:
Force or No-Force:Commit時是否需要強制刷盤,采用Force的方式由于所有的已提交事務的數據一定已經存在與磁盤,自然而然地保證了Durability。
No-Steal or Steal,Commit前數據是否可以提前刷盤,采用No-Steal的方式由于保證事務提交前修改不會出現在磁盤上,自然而然地保證了Atomic
總結一下,實現Durability可以記錄Redo信息或要求Force刷盤順序,實現Atomic需要記錄Undo信息或要求No-Steal刷盤順序,組合得到如下四種模式,如下圖所示:
ARIES,一統江湖
1992年,IBM的研究員們發表了《ARIES: a transaction recovery method supporting fine-granularity locking and partial rollbacks using write-ahead logging》[2],其中提出的ARIES逐步成為磁盤數據庫實現故障恢復的標配,ARIES本質是一種Redo-Undo的WAL實現。Normal過程:修改數據之前先追加Log記錄,Log內容同時包括Redo和Undo信息,每個日志記錄產生一個標記其在日志中位置的遞增LSN(Log Sequence Number);數據Page中記錄最后修改的日志項LSN,以此來判斷Page中的內容的新舊程度,實現冪等。故障恢復階段需要通過Log中的內容恢復數據庫狀態,為了減少恢復時需要處理的日志量,ARIES會在正常運行期間周期性的生成Checkpoint,Checkpoint中除了當前的日志LSN之外,還需要記錄當前活躍事務的最新LSN,以及所有臟頁,供恢復時決定重放Redo的開始位置。需要注意的是,由于生成Checkpoint時數據庫還在正常提供服務(Fuzzy Checkpoint),其中記錄的活躍事務及Dirty Page信息并不一定準確,因此需要Recovery階段通過Log內容進行修正。
Recover過程:故障恢復包含三個階段:Analysis,Redo和Undo。Analysis階段的任務主要是利用Checkpoint及Log中的信息確認后續Redo和Undo階段的操作范圍,通過Log修正Checkpoint中記錄的Dirty Page集合信息,并用其中涉及最小的LSN位置作為下一步Redo的開始位置RedoLSN。同時修正Checkpoint中記錄的活躍事務集合(未提交事務),作為Undo過程的回滾對象;Redo階段從Analysis獲得的RedoLSN出發,重放所有的Log中的Redo內容,注意這里也包含了未Commit事務;最后Undo階段對所有未提交事務利用Undo信息進行回滾,通過Log的PrevLSN可以順序找到事務所有需要回滾的修改。
除此之外,ARIES還包含了許多優化設計,例如通過特殊的日志記錄類型CLRs避免嵌套Recovery帶來的日志膨脹,支持細粒度鎖,并發Recovery等。[3]認為,ARIES有兩個主要的設計目標:
Feature:提供豐富靈活的實現事務的接口:包括提供靈活的存儲方式、提供細粒度的鎖、支持基于Savepoint的事務部分回滾、通過Logical Undo以獲得更高的并發、通過Page-Oriented Redo實現簡單的可并發的Recovery過程。
Performance:充分利用內存和磁盤介質特性,獲得極致的性能:采用No-Force避免大量同步的磁盤隨機寫、采用Steal及時重用寶貴的內存資源、基于Page來簡化恢復和緩存管理。
NVM帶來的機遇與挑戰
從Shadow Paging到WAL,再到ARIES,一直圍繞著兩個主題:減少同步寫以及盡量用順序寫代替隨機寫。而這些正是由于磁盤性能遠小于內存,且磁盤順序訪問遠好于隨機訪問。然而隨著NVM磁盤的出現以及對其成為主流的預期,使得我們必須要重新審視我們所做的一切。相對于傳統的HDD及SSD,NVM最大的優勢在于:
接近內存的高性能
順序訪問和隨機訪問差距不大
按字節尋址而不是Block
在這種情況下,再來看ARIES的實現:
No-force and Steal:同時維護Redo, Undo和數據造成的三倍寫放大,來換取磁盤順序寫的性能,但在NVM上這種取舍變得很不劃算;
Pages:為了遷就磁盤基于Block的訪問接口,采用Page的存儲管理方式,而內存本身是按字節尋址的,因此,這種適配也帶來很大的復雜度。在同樣按字節尋址的NVM上可以消除。
近年來,眾多的研究嘗試為NVM量身定制更合理的故障恢復機制,我們這幾介紹其中兩種比較有代表性的研究成果,MARS希望充分利用NVM并發及內部帶寬的優勢,將更多的任務交給硬件實現;而WBL則嘗試重構當前的Log方式。
MARS
發表在2013年的SOSP上的《"From ARIES to MARS: Transaction support for next-generation, solid-state drives." 》提出了一種盡量保留ARIES特性,但更適合NVM的故障恢復算法MARS[3]。MARS取消了Undo Log,保留的Redo Log也不同于傳統的Append-Only,而是可以隨機訪問的。如下圖所示,每個事務會占有一個唯一的TID,對應的Metadata中記錄了Log和Data的位置。

正常訪問時,所有的數據修改都在對應的Redo Log中進行,不影響真實數據,由于沒有Undo Log,需要采用No-Steal的方式,阻止Commit前的數據寫回;Commit時會先設置事務狀態為COMMITTED,之后利用NVM的內部帶寬將Redo中的所有內容并發拷貝回Metadata中記錄的數據位置。如果在COMMITED標記設置后發生故障,恢復時可以根據Redo Log中的內容重放。其本質是一種Redo加No-Steal的實現方式:
Durability of Updates: Redo實現,故障后重放Redo;
Failure Atomic:未Commit事務的修改只存在于Redo Log,重啟后會被直接丟棄。
可以看出,MARS的Redo雖然稱之為Log,但其實已經不同于傳統意義上的順序寫文件,允許隨機訪問,更像是一種臨時的存儲空間,類似于Shadow的東西。之所以在Commit時進行數據拷貝而不是像Shadow Paging一樣的元信息修改,筆者認為是為了保持數據的局部性,并且得益于硬件優異的內部帶寬。
WBL
不同于MARS保留Redo信息的思路,2016年VLDB上的《 "Write Behind Logging" 》只保留了Undo信息。筆者認為這篇論文中關于WBL的介紹里,用大量筆墨介紹了算法上的優化部分,為了抓住其本質,這里先介紹最基本的WBL算法,WBL去掉了傳統的Append Only的Redo和Undo日志,但仍然需要保留Undo信息用來回滾未提交事務。事務Commit前需要將其所有的修改強制刷盤,之后在Log中記錄Commit標記,也就是這里說的Write Behind Log。恢復過程中通過分析Commit標記將為提交的事務通過Undo信息回滾。可以看出WBL算法本身非常簡單,在這個基礎上,WBL做了如下優化:
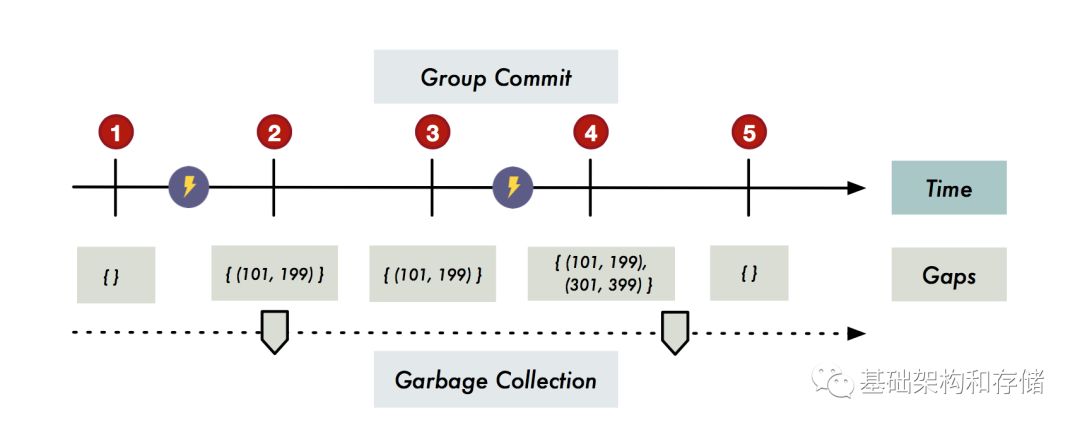
Group Commit:周期性的檢查內存中的修改,同樣先將所有修改刷盤后寫Log,Log項中記錄最新Commit并落盤的最大事務TimeStamp cp,保證早于cp的所有事務修改都已經落盤;同時記錄當前分配出去的最大TimeStamp cd;也就是說此時所有有修改但未提交的事務Timestamp都落在cp和cd之間。Reovery的時候只需對這部分數據進行回滾;
針對多版本數據庫,多版本信息已經起到了undo的作用,因此不需要再額外記錄undo信息;
延遲回滾:Recovery后不急于對未提交事務進行回滾,而是直接提供服務,一組(cp, cd)稱為一個gap,每一次故障恢復都可能引入新的gap,通過對比事務Timestamp和gap集合,來判斷數據的可見性,需要依靠后臺垃圾回收線程真正的進行回滾和對gap的清理,如下圖所示
可以看出,WBL本質并沒有什么新穎,是一個Force加Undo的實現方式,其正確性保證如下:
Durability of Updates:Commit事務的數據刷盤后才進行Commit,因此Commit事務的數據一定在Recovery后存在
Failure Atomic:通過記錄的Undo信息或多版本時的歷史版本信息,在Recovery后依靠后臺垃圾回收線程進行回滾。
總結
數據庫故障恢復問題本質是要在容忍故障發生的情況下保證數據庫的正確性,而這種正確性需要通過提供Durability of Updates和Failure Atomic來保證。其中Duribility of Update要保證Commit事務數據在恢復后存在,可以通過Force機制或者通過Redo信息回放來保證;對應的,Failure Atomic需要保證未Commit事務的修改再恢復后消失,可以通過No-Steal機制或者通過Undo信息回滾來保證。可以保證Durability和Atomic的方式,對本文提到的算法進行分類,如下:
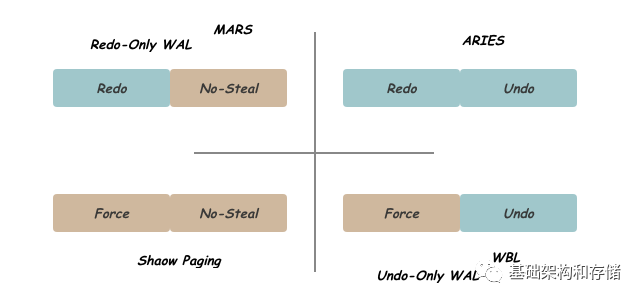
Shadow Paging可以看做是采用了Force加No-Steal的方式,沒有Log信息,在Commit時,通過原子的修改Directory元信息完成數據的持久化更新,但由于其對Page內并發的限制,以及對數據局部性的破壞等原因,沒有成為主流;
Logging的實現方式增加了Redo或Undo日志,記錄恢復需要的信息,從而放松Force或No-Steal機制對刷盤順序的限制,從而盡量用磁盤順序寫代替隨機寫獲得較好的性能。ARIES算法是在這一方向上的集大成者,其對上層應用提供了豐富靈活的接口,采用了No-Force加Steal機制,將傳統磁盤上的性能發揮到極致,從而成為傳統磁盤數據故障恢復問題的標準解決方案;
隨著NVM設備的逐步出現,其接近內存的性能、同樣優異的順序訪問和隨機訪問性能,以及基于字節的尋址方式,促使人們開始重新審視數據庫故障恢復的實現。其核心思路在于充分利用NVM硬件特性,減少Log機制導致的寫放大以及設計較復雜的問題;
MARS作為其中的佼佼者之一,在NVM上維護可以隨機訪問的Redo日志,同時采用Force加Steal的緩存策略,充分利用NVM優異的隨機寫性能和內部帶寬。
WBL從另一個方向進行改造,保留Undo信息,采用No-Force加No-Steal的緩存策略,并通過Group Commit及延遲回滾等優化,減少日志信息,縮短恢復時間。
本文介紹了磁盤數據庫一路走來的核心發展思路,但距離真正的實現還有巨大的距離和眾多的設計細節,如對Logical Log或Physical Log的選擇、并發Recovery、Fuzzy Checkpoing、Nested Top Actions等,之后會用單獨的文章以InnoDB為例來深入探究其設計和實現細節。
-
硬件
+關注
關注
11文章
3315瀏覽量
66203 -
數據庫
+關注
關注
7文章
3795瀏覽量
64364
原文標題:數據庫故障恢復機制的前世今生
文章出處:【微信號:inf_storage,微信公眾號:數據庫和存儲】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
數據庫數據恢復—Mysql數據庫表記錄丟失的數據恢復流程

數據庫數據恢復—MYSQL數據庫ibdata1文件損壞的數據恢復案例
Sybase數據恢復—Sybase數據庫無法啟動怎么恢復數據?
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

數據庫數據恢復—Oracle ASM實例無法掛載的數據恢復案例
Oracle數據恢復—異常斷電后Oracle數據庫啟庫報錯的數據恢復案例
數據庫數據恢復—Oracle數據庫文件system01.dbf損壞的數據恢復案例
數據庫數據恢復—SQL Server數據庫出現823錯誤的數據恢復案例

數據庫數據恢復—SQL Server數據庫所在分區空間不足報錯的數據恢復案例
數據庫數據恢復—數據庫所在分區空間不足導致sqlserver故障的數據恢復案例
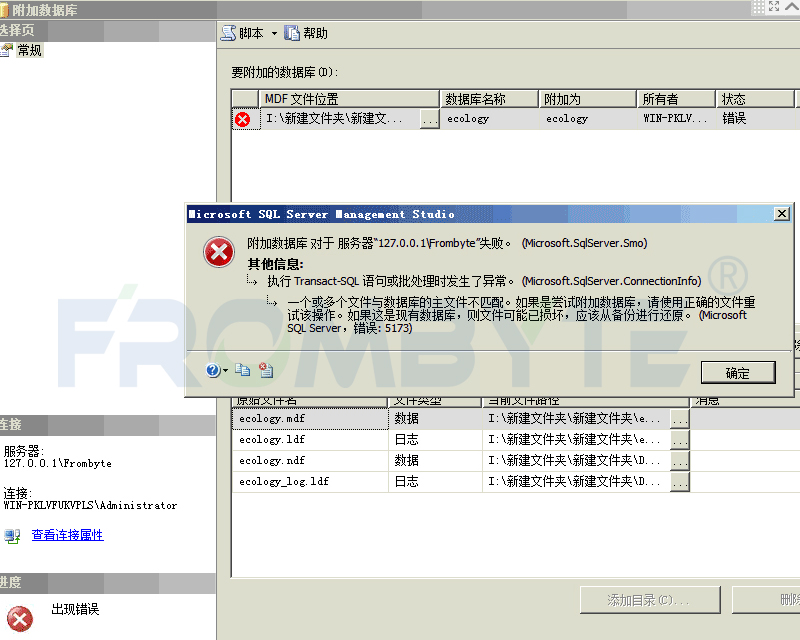
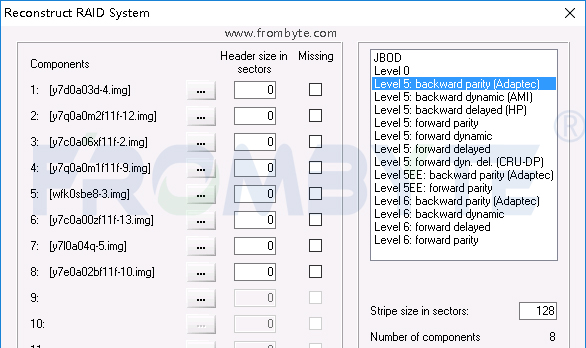
數據庫數據恢復—raid5陣列上層Sql Server數據庫數據恢復案例

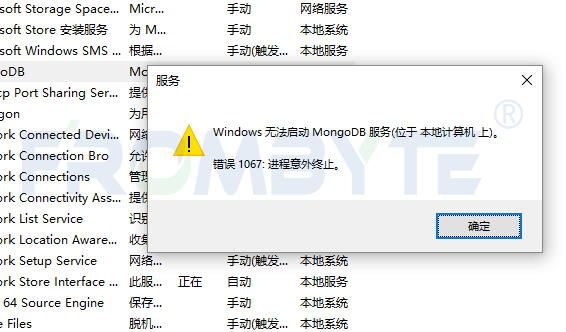
MongoDB數據恢復—MongoDB數據庫文件損壞的數據恢復案例
數據庫數據恢復—Sql Server數據庫文件丟失的數據恢復案例
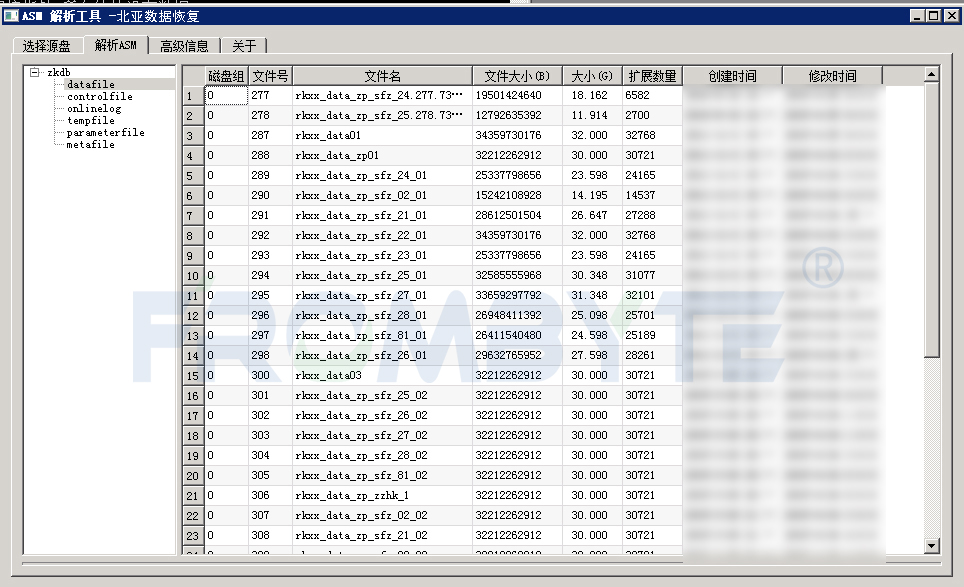
【數據庫數據恢復】Oracle數據庫ASM實例無法掛載的數據恢復案例






 工商網監
工商網監
評論