 工業互聯網時代,我們為什么需要一個時序數據庫?
工業互聯網時代,我們為什么需要一個時序數據庫?
時間是公平的,時間也是不公平的。
公平在于時間對于所有人都是一樣,不偏不倚;不公平在于隨著時間的推移,事物發展的結果有可能大不相同。摩爾定律告訴我們,當事物進入正常軌道后,其發展的速度將呈現出指數級的增長。芯片如此,網絡如此,數據亦如此。

于是,當互聯網進入下半場:工業互聯網or產業互聯網時代后,聯所能連,萬物互聯,同一時間,諸多因素爭相進入指數級發展軌道,形成了互聯網不能承受又不能不承受之重。
人生若只如初見,何事秋風悲畫扇。
對于格創東智所處的工業互聯網領域來說,一個非常明顯的特點就是匯聚大量工業數據,而工業數據的一個非常明顯的特點就是和時間有關。
一般而言,工業數據的典型特點包括:
>>>>
產生頻率快
工業數據采集基本為秒級,部分高頻數據采集為毫秒or微秒級,每一個采集點一秒鐘內可產生多條數據
>>>>
嚴重依賴于采集時間
每一條數據均要求對應唯一的時間
>>>>
測點多、信息量大、數據結構相對簡單
常規的實時監測系統均有成千上萬的監測點,監測點每秒鐘都產生數據,每天產生幾十GB的數據量
工業數據是IT界“只如初見”的新問題,但是,在工業界,這早就不是問題。
在傳統的工業數據采集和工業監控領域(SCADA),都需要對聯網的設備進行監控,并對監控采樣到的數據進行持久化。在工業領域早就有專門的數據庫來完成這個任務了。
這個專門的數據庫就叫做:實時數據庫(此處應有掌聲)。工業領域的實時數據庫具有數據采集、實時數據緩存、數據回寫(向設備發送指令)、采樣數據歸檔存盤等主要功能。目前工業領域實時數據庫基本上被國外廠家所壟斷,價格昂貴。以著名的PI數據庫為例,基礎版本(只有5000個測點)就需要大約10萬美元,每個數據采集接口需要6000美元。于是,不知道有多少工業版的IoT項目都被扼殺在“搖籃中”,被“秋風悲畫扇”了……
上帝關門,必然開窗。
所幸,接物聯網的東風,時序數據庫(Time Series Database,TSDB)應運而“升”。
先看看維基百科上的解釋:

勉強翻譯一下:“時序列數據庫就是用來存儲時序列(time-series)數據并以時間(時間點或時間區間)建立索引的軟件。”
簡而言之,時序數據庫全稱為時間序列數據庫。時間序列數據庫主要用于指處理帶時間標簽(按照時間的順序變化,即時間序列化)的數據,帶時間標簽的數據也稱為時間序列數據。
規范言之,時間序列數據(Time Series Data,TSD)可以用一個二元函數來表示:
TSD =Metric(Timestamp,Measurement),其中:
Metric代表可以唯一標識的數據序列;
Timestamp代表時間戳;
Measurement代表被測量;
簡單的說,就是這類數據描述了某個被測量的主體在一個時間范圍內的每個時間點上的測量值。它普遍存在于電力、化工行業等行業以及IT基礎設施、運維監控系統和物聯網等各類型實時監測中。
用來存儲、管理、查詢、處理上述二元函數數據的數據庫,則可以稱之為時序數據庫。
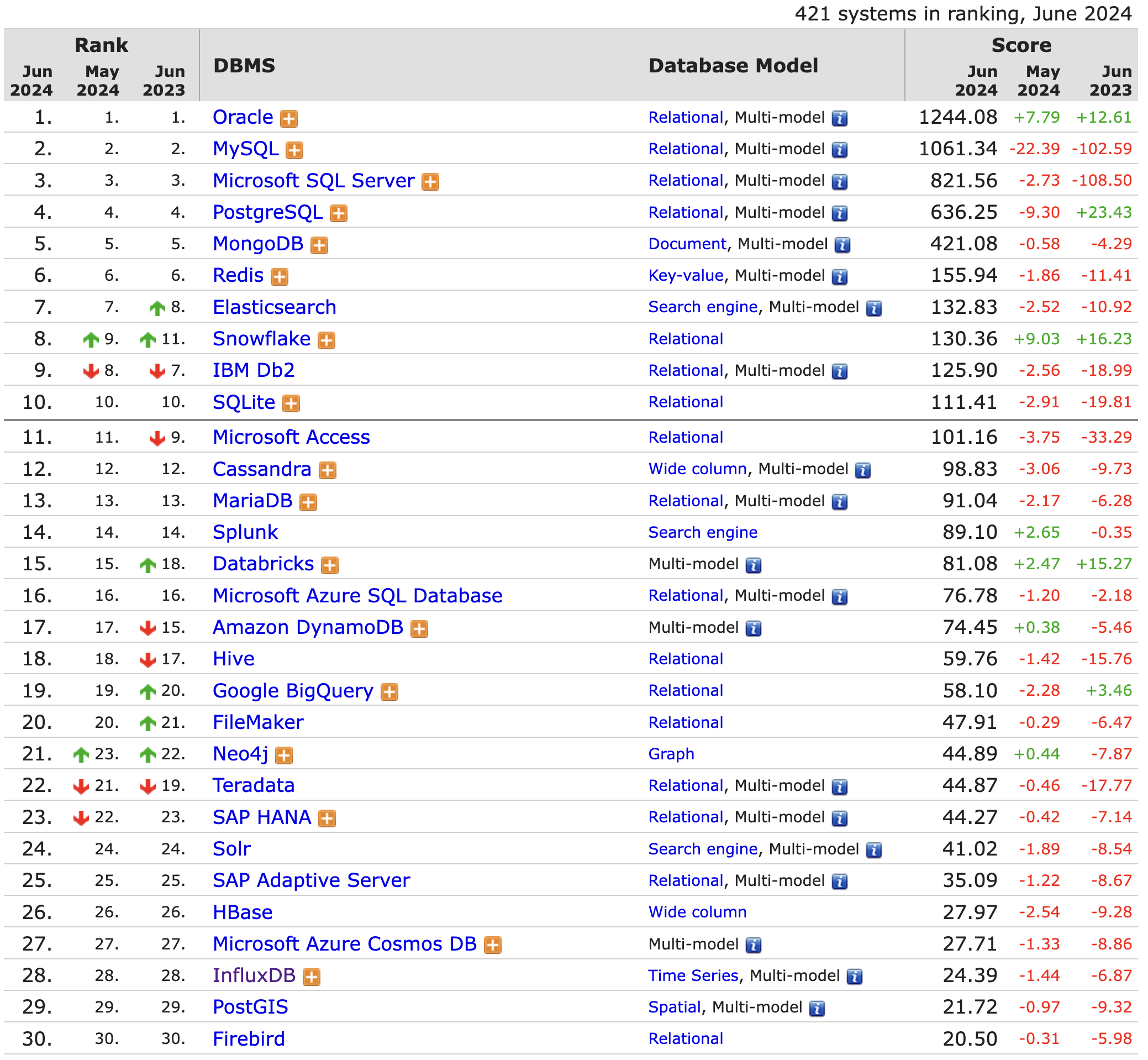
時序數據庫主要以解決下面幾個問題:
時序數據的寫入:如何支持每秒鐘上千萬上億數據點的寫入。
時序數據的查詢:又如何支持在秒級對上億數據的分組聚合運算。
時序數據的存儲:解決由海量數據存儲帶來的成本敏感問題。
時序數據的生命周期管理:工業數據的價值主要體現在及時性,因此,工業數據的生命周期管理是時序數據庫的核心使命。
各位看官,麻煩度娘一下,關鍵字:互聯網監控系統,大家就會發現小米、餓了嗎等互聯網巨頭也都在用時序數據庫實現企業級的互聯網監控系統。更別提目前所有國內外主流工業互聯網平臺了,幾乎都是采用時序數據庫來承接海量涌入的工業數據。
看到這里,估計已經有很多“杠精”躍躍欲試了:憑什么強大的Oracle、PostgreSQL 等傳統關系型數據庫搞不定時序數據?憑什么不用HBase、MongoDB、Cassandra等先進的分布式數據庫來解決工業數據問題?有什么深刻技術理由非要用這個2017年才火爆起來的時序數據庫呢?請繼續關注格物匯的后續精彩文章!
本文作者:格創東智首席架構師王錦博士(轉載請注明作者及來源)
-
實時數據庫
+關注
關注
0文章
39瀏覽量
10907 -
智能制造
+關注
關注
48文章
5549瀏覽量
76314 -
工業互聯網
+關注
關注
28文章
4320瀏覽量
94096 -
工業大數據
+關注
關注
0文章
72瀏覽量
7837
發布評論請先 登錄
相關推薦
數據庫數據恢復—通過拼接數據庫碎片恢復SQLserver數據庫

有云服務器還需要租用數據庫嗎?
數字化時代的數據管理:多樣化數據庫選型指南





 工商網監
工商網監
評論