 清華大學人工智能研究院宣布成立知識智能研究中心
清華大學人工智能研究院宣布成立知識智能研究中心
清華大學人工智能研究院今天宣布成立知識智能研究中心,由李涓子教授擔任中心主任。中心旨在開展理論研究、促進交流合作,最終構建包含語言知識、常識知識、世界知識、認知知識的大規模知識圖譜以及典型行業知識庫的清華大學知識計算開放平臺。
2019年1月21日,清華大學人工智能研究院在清華大學FIT樓舉行知識智能研究中心成立儀式暨知識計算開放平臺發布會,清華大學副校長、清華大學人工智能研究院管委會主任尤政院士,人工智能研究院院長張鈸院士、常務副院長孫茂松教授出席儀式并致辭。
知識智能研究中心(Knowledge Intelligence Research Center, KIRC)是清華人工智能研究院自2018年6月建院以來成立的首個研究中心(點擊“閱讀原文”訪問網站),是研究院整合校內優勢研究力量、推動人工智能原始創新的一個重要舉措,也是人工智能研究院發展的一個新的里程碑。”尤政院士在致辭中說。
知識中心主任由我國知識計算領域專家、清華大學長聘教授李涓子擔任。李涓子教授表示,知識中心將以促進清華和國家知識智能研究與發展為宗旨,打造具有廣泛影響力的學術研究、知識計算平臺與學術交流中心。
知識智能研究中心揭牌儀式上,清華大學人工智能研究院院長張鈸院士(左),清華大學副校長、清華大學人工智能研究院管委會主任尤政院士(右),為李娟子教授頒發知識中心主任聘書。
李涓子,清華大學長聘教授,博士生導師。中國中文信息學會語言與知識計算專委會主任。研究方向為知識工程、語義Web和文本挖掘。近年來在重要國際會議和學術期刊上發表論文100余篇,編著出版《Mining User Generated Content》,《Semantic Mining in Social Networks》。主持國家自然科學基金重點課題、歐盟第七合作框架等多項國家、國際和部委項目。獲得2017年北京市科技進步一等獎、2013年人工智能學會科技創新一等獎等多個獎項。
董振東先生被聘任為知識中心學術顧問(由董強先生[中]代領)
清華大學知識計算開放平臺發布,讓知識為AI賦能
讓計算機擁有大規模高質量的知識是實現人工智能的一項重要任務。知識表示、獲取、推理與計算等問題,一直處于人工智能的研究核心。
“很多人以為現在這波深度學習掀起的浪潮已經讓我們進入了新一代人工智能的時代,”張鈸院士:“這種看法是錯誤的。”
張鈸院士指出,新一代人工智能指向的必須是安全可信的人工智能,深度學習技術由于數據驅動的特性,存在可解釋性和魯棒性的局限性,亟需大規模知識的支持,以實現有理解能力的人工智能,這也是清華人工智能研究院成立知識中心的初衷。
目前,中國在知識表示、知識推理方面積累不足,從最近的相關文獻看,少見中國學者在這一領域發表論文,而多樣化的研究和基礎性研究是人工智能探索必須的。因此,“清華大學在這個時間點成立知識中心還是非常及時的”,張鈸院士說。
作為清華大學人工智能研究院成立的首個研究中心,李涓子教授表示,知識智能研究中心旨在:
開展理論研究。研究支持魯棒可解釋人工智能的大規模知識的表示、獲取、推理與計算的基礎理論和方法,尤其是原創性研究;
構建知識平臺。建設包含語言知識、常識知識、世界知識、認知知識的大規模知識圖譜以及典型行業知識庫,建成清華大學知識計算開放平臺;
促進交流合作。舉辦開放的、國際化的與知識智能相關的學術活動,增進學術交流;普及知識智能技術,促進產學合作。
會上,知識中心隆重發布了清華大學知識計算開放平臺(THUKC),清華大學計算機系副教授劉知遠對平臺做了介紹,包括中英文跨語言百科知識圖譜XLORE、大規模開放語言知識庫OpenHowNet、科技知識挖掘平臺AMiner、清華大學人工智能技術系列報告THUAITR等。
劉知遠副教授表示,深度學習 (數據) 與知識的結合是人工智能發展的必然趨勢,人工智能本身也渴求世界知識、常識知識等知識智能的支撐。
劉知遠告訴新智元,目前平臺以清華團隊為主,未來希望匯聚更多學界和產業界力量,這也是平臺冠名“開放”之意義所在。
知識中心將在清華大學和人工智能研究院的支持下,以這次發布的知識計算平臺為起點,堅持做好做強知識計算平臺,讓知識為AI賦能。
清華大學知識計算開放平臺(THUKC)詳介
會上,知識計算開放平臺現有項目團隊代表分別做了學術報告,詳細介紹了清華發布的知識資源和計算平臺。
知網(HowNet)知識系統共同發明人董強發表《THUKC語言與常識知識庫——OpenHowNet》的學術報告。
OpenHowNet:基于義原的開放語言知識庫
網址:openhownet.thunlp.org
知網HowNet是由董振東先生、董強先生父子畢三十年之功建立的一個以漢語和英語的詞語所代表的概念為描述對象,以揭示概念與概念之間、以及概念所具有的屬性之間的關系為基本內容的語言和常識知識庫。
HowNet秉承還原論思想,認為詞義概念可以用更小的語義單位來描述,這種語義單位被稱為“義原”(Sememe),是最基本的、不易于再分割的意義的最小單位。在不斷標注的過程中,HowNet逐漸構建出了一套精細的義原體系(約2000個義原)。
HowNet基于該義原體系累計標注了數十萬詞匯/詞義的語義信息,自1999年正式發布以來引起了中文信息處理領域極大的研究熱情,在詞匯相似度計算、文本分類、信息檢索等方面探索了HowNet的重要應用價值,建立了廣泛而深遠的學術影響力。
2017年以來,清華大學研究團隊系統探索HowNet知識庫在深度學習時代的應用價值,并在詞匯語義表示、句子語義表示、詞典擴展等任務上均得到了驗證。研究發現,HowNet通過統一的義原標注體系直接精準刻畫語義信息,一方面能夠突破詞匯屏障,深入了解詞匯背后豐富語義信息;另一方面每個義原含義明確固定,可被直接作為語義標簽融入機器學習模型,使自然語言處理深度學習模型具有更好的魯棒可解釋性。相關成果均發表在AAAI、IJCAI、ACL、EMNLP等人工智能和自然語言處理領域頂級國際會議上。
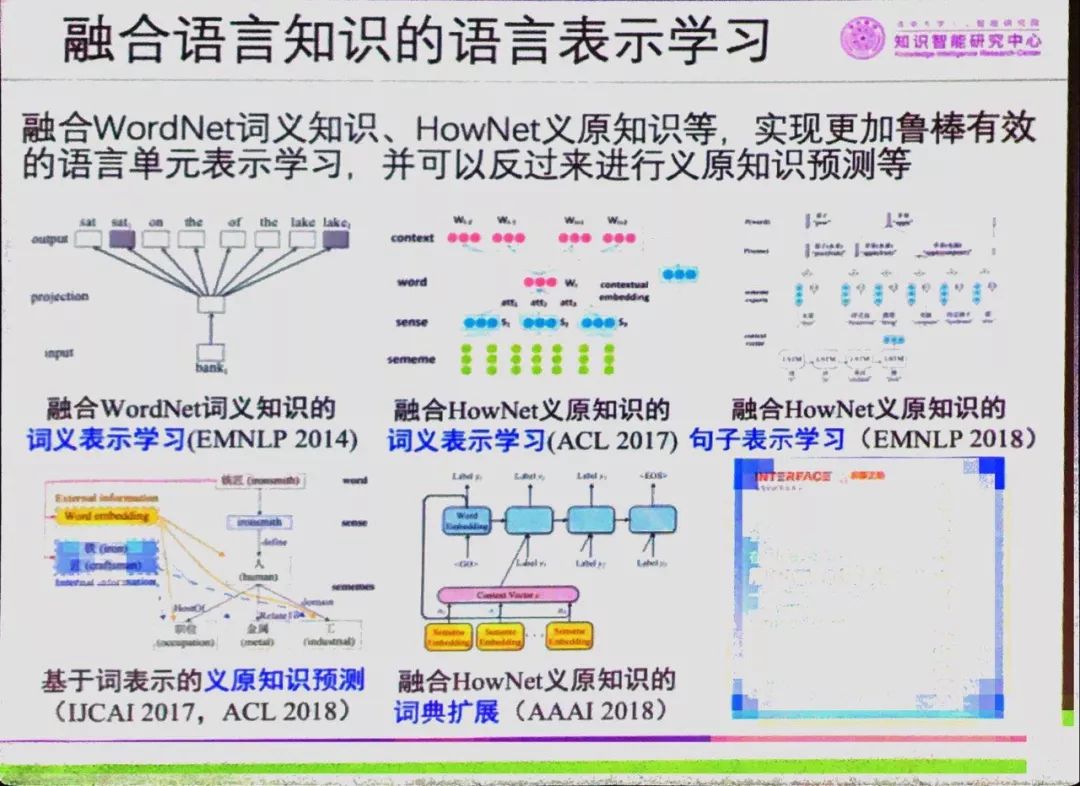
為了讓HowNet知識庫及其學術思想得到更廣泛的應用,知識中心聯合董氏父子共同開源HowNet知識庫核心數據,研制了知識庫的訪問與計算工具包,并將在清華大學知識計算平臺上持續地維護、更新和擴展。
XLORE:千萬級概念實體和億級實體大規模跨語言知識圖譜
網址:https://xlore.org/
李涓子教授介紹XLORE,融合百度百科、中英文維基百科等多語言融合的知識圖譜
接下來,李涓子教授介紹了THUKC世界知識圖譜——XLORE。
XLORE是中英文知識規模平衡的大規模跨語言百科知識圖譜。該圖譜通過融合中文、英文的維基百科和百度百科,并對百科知識進行結構化和跨語言鏈接構建而成。
該圖譜以結構化形式描述客觀世界中的概念、實例、屬性及其豐富語義關系。XLORE目前包含約247萬概念、44.6萬屬性/關系、1628萬實例和260萬跨語言鏈接。XLORE作為世界知識圖譜,將為包括搜索引擎、智能問答等人工智能應用提供有力支撐。現在全部內容都可以用網站下載使用。
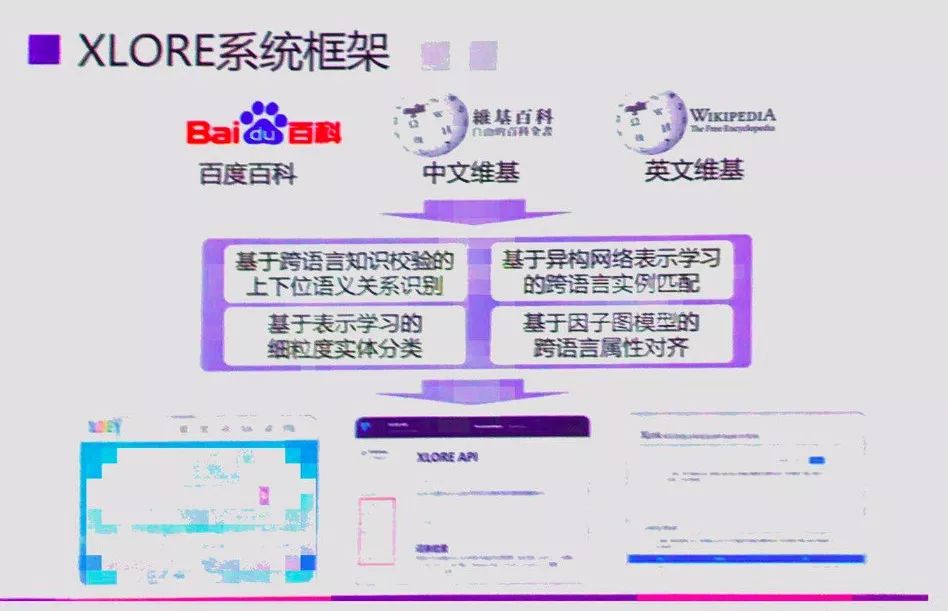
XLORE集成了多項創新研究成果:
利用基于鏈接因子圖模型的知識鏈接方法,實現對不同語言知識資源之間的實體知識關聯;
利用跨語言概念層次關系的驗證保證生成跨語言本體中概念關系的質量,并進一步研究了跨語言知識圖譜的概念層次剪枝和優化算法以規范知識分類體系;
利用因子圖模型建立跨語言屬性間的對應關系,減少知識圖譜的冗余;
聯合使用DBpedia分類樹、維基分類體系、百度百科詞條標簽對未分類實體進行類別標注。相關成果發表在WWW、IJCAI、ACL、EMNLP等人工智能和自然語言處理領域重要國際會議上。
與著名知識圖譜DBpedia相比,XLORE的中文實體數量是其的3.6倍,中英文跨語言鏈接增加39%。XLORE還提供多樣化數據API服務,系統累計訪問次數過億次,訪問來自53個不同國家或地區;2018年API響應調用160萬余次。XLORE項目計劃于2019年正式發布跨語言實體鏈接服務XLINK。
在世界知識的獲取、表示與計算方面,中心還研制發布了很多開源工具和評測數據集,如知識表示學習工具包OpenKE、神經網絡關系抽取工具包OpenNRE、Few shot learning關系抽取數據集FewRel等,自發布以來獲得學術界與產業界廣泛使用。

AMiner:大規模科技知識挖掘平臺
網址:https://aminer.cn/
清華大學計算機系教授唐杰詳細介紹了科技知識挖掘平臺AMiner和清華大學人工智能技術系列報告THUAITR
AMiner作為科技情報網絡大數據挖掘平臺,包含超過2億篇學術論文和專利以及1.36億科研人員學術網絡。該平臺于2006年上線,已經累計吸引全球220個國家和地區的800多萬獨立IP訪問,數據下載量230萬次,年度訪問量超過1000萬,成為學術搜索和社會網絡挖掘研究的重要數據和實驗平臺。
AMiner項目團隊與中國工程科技知識中心、微軟學術搜索、ACM、IEEE、DBLP、美國艾倫研究所、英國南安普頓大學等機構建立了良好的合作關系,項目成果及核心技術應用于中國工程院、科技部、國家自然科學基金委、華為、騰訊、阿里巴巴等國內外20多家企事業單位,為各單位的專家系統建設及產品升級提供了重要數據及技術支撐。
唐杰教授還介紹了清華大學人工智能技術系列報告THUAITR,并新發布了“知識圖譜研究報告”和“數據挖掘研究報告”兩份新報告。
THUAITR:清華大學人工智能技術系列報告
網站:https://reports.aminer.cn/
THUAITR以AMiner全球科技情報大數據挖掘服務平臺為基礎,聘請領域專家作為顧問,結合人工智能自動生成技術,以嚴謹、嚴肅、負責的態度制作發布的人工智能技術評論及人才分析。報告內容涵蓋技術趨勢、前沿預測、人才分布、實力對比、以及洞察情報等。
2018年,THUAITR共發布14份技術報告,主題包括:自動駕駛(基礎版)、機器人、區塊鏈、行為經濟學、機器翻譯、通信與人工智能、自動駕駛、自然語言處理、計算機圖形學、超級計算機、3D打印、智能機器人、人臉識別、人工智能芯片,累計閱讀量超過120萬人次。
此外,清華大學計算機系副教授黃民烈還在會上做了報告《知識計算典型案例——常識知識感知的語言生成初探》,主要介紹了兩項工作:一是結合常識進行對話生成,一是符合邏輯的故事結局的生成。
-
人工智能
+關注
關注
1791文章
47186瀏覽量
238267 -
數據驅動
+關注
關注
0文章
127瀏覽量
12333 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:清華大學AI研究院成立知識智能研究中心,知識計算開放平臺重磅發布
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
博世與清華大學續簽人工智能研究合作協議
陳天橋雒芊芊腦科學研究院在人工智能領域取得重大突破
中國電信人工智能研究院完成首個全國產化萬卡萬參大模型訓練
深圳云芯晨半導體科技有限公司榮幸地宣布與深圳清華大學研究院攜手合作
直線電機生產廠家談高校建成投用人形機器人研究院

香港城市大學與富士康鴻海研究院成立聯合研究中心

三星電子與首爾大學共建人工智能聯合研究中心
易華錄無錫數據湖與清華大學蘇州汽車研究院(吳江)合作挖掘智能駕駛數據新價值
全國首家!迅龍軟件牽手首師大附中成立基礎教育階段人工智能課程開發研究中心






 工商網監
工商網監
評論