 關于AlphaStar你最應該知道的15件事
關于AlphaStar你最應該知道的15件事
昨天DeepMind的AlphaStar橫掃星際2職業玩家,項目負責人Oriol Vinyals和David Silver兩位技術大牛親自答網友提問。新智元摘選點贊最高的15個問題,關于APM、算法和工程的精華。
“AI早晚會超越人類”的念頭,其實從AlphaGo開始,就已經在每個人心底,悄悄蔓延開。
只不過我們每個人心里還是很不甘心!面對智力甚至無法達到人類嬰兒水平的AI,玩起游戲來,已經沒人能打得過了。
AlphaStar取勝靠的APM、計算機多線操作,還是AI已經有了戰術判斷、宏觀大局分析能力?
賽后,DeepMind官方在Reddit上,回復了網友關于AlphaStar的種種疑問。
此次派出的是Oriol Vinyals和David Silver。
Oriol Vinyals是 Google 旗下人工智能公司 DeepMind 的研究科學家,年少時,他曾是西班牙《星際爭霸》游戲排名第一的電競高手,同時參與 Gmail、Google 圖像識別服務開發。
David Silver是DeepMind首席研究員,帶領DeepMind強化學習研究小組,也是AlphaGo項目的負責人。可以說,Silver從AlphaGo誕生前起,到最強版本AlphaGo Zero,一直在用深度強化學習攻克圍棋。David Silver也是AlphaStar項目的聯合負責人。
AlphaStar獲勝靠的是APM嗎?
問:APM是怎么回事?我印象中是被SC2限制為180 WPM,但看視頻,AS的平均APM似乎很長一段時間都遠遠超過了180 WPM,而且DeepMind的博客文章里提到了上面的圖表和數字,但沒有解釋為什么APM這么高。
Oriol Vinyals:我認為這是一個很好的問題,也是我們想要澄清的。
我們向TLO和暴雪咨詢了關于APM的問題,也對APM增加了一個硬性限制。特別是,我們設置了5秒內最多600 APM, 15秒內最多400 APM, 30秒內最多320 APM, 60秒內最多300 APM。
如果智能體在此期間發出更多操作,我們會刪除/忽略這些操作。這些是來自人類統計的數據。
同樣重要的是,暴雪在APM計算中多次計算某些動作(上面的數字是指來自pysc2中的“代理動作”)。
同時,我們的智能體使用模仿學習,這意味著我們經常會看到非常“垃圾”的行為。也就是說,并不是所有的操作都是有效的操作,因為代理傾向于發送糟糕的“移動”命令,例如在周圍繞來繞去。
有人已經在reddit的帖子中指出了這一點——AlphaStar的有效APM (或EPM) 要低得多。
AlphaStar一共有幾個版本?
問:在PBT中需要多少種不同的agent才能保持足夠的多樣性,以防止災難性遺忘?這與agent的數量有多大關系,或者只需要幾個agent就可以保持魯棒性?有沒有與比較常用的歷史檢查點策略的效率進行比較?
David Silver:我們保留每個agent的舊版本作為AlphaStar聯賽的競爭對手。
當前的agent通常根據對手的勝率來打。這在防止災難性遺忘方面是非常成功的,因為agent必須要能夠繼續打敗它之前的所有版本。
我們嘗試了許多其他的多智能體學習策略,發現這種方法非常有效。此外,增加AlphaStar聯賽的多樣性也很重要,盡管這實際上是災難性遺忘的另一個方面。
很難給出準確的數字,但我們的經驗是,豐富聯盟中的戰略空間有助于使最終的智能體更強大。
AlphaStar的關鍵算法是什么?
問:像AlphaGo和AlphaZero這樣的agent接受的是完美信息的博弈訓練。像星際爭霸這樣的不完美信息的博弈如何影響agent的設計?AlphaStar對之前的觀察是否有類似于人類的“記憶”?
David Silver:有趣的是,基于搜索的方法,例如AlphaGo和AlphaZero,實際上可能更難適應不完美的信息。例如,基于搜索的撲克算法 (例如DeepStack或Libratus) 通過belief states顯式地推理對手的牌。
但AlphaStar是一個model-free的強化學習算法,可以隱式地對對手進行推理,即通過學習對其對手最有效的行為,而不是試圖建立一個對手實際看到的模型——可以說,這是一種更容易處理不完全信息的方法。
此外,不完美的信息博弈并沒有一種絕對最優的博弈方式——這取決于對手的行為。這就是《星際爭霸》中有趣的“石頭剪刀布”動態的來源。
這是我們在AlphaStar聯賽中使用的方法背后的動機,以及為什么這種方法對于覆蓋所有戰略空間很重要——這在圍棋之類的游戲是不需要的,其中有一個minimax的最優策略可以擊敗所有對手,不管對手做出何種舉動。
AlphaStar有使用人類信息,還是全靠自我對弈?
問:你們還嘗試了什么其他方法嗎?大家非常好奇是否涉及任何樹搜索、深度環境模型或分層RL技術,但似乎沒有一個涉及;這些方法中有那個在嘗試后取得了可觀的進步嗎?
子問題:鑒于SC2的極端稀疏性,你對于單純self-play是否對SC2有效這一點有什么看法?OA5在沒有任何模仿學習或領域知識的情況下就成功地打敗了DoTA2,所以僅僅是擁有巨大動作空間的長游戲并不能說明self-play就不能成功。
David Silver:我們在self-play方面確實取得了一些初步的積極成果,事實上,我們的agent的早期版本完全通過self-play,使用基本策略就擊敗了內置的bot。
但是,有監督的人類數據對引導探索過程非常有幫助,并有助于更廣泛地覆蓋高級策略。
特別是,我們包含了一個policy distillation cost,以確保在整個訓練過程中,agent以某種概率繼續嘗試類似人的行為,這跟從self-play開始相比,發現不太可能的策略要更容易。
迄今為止最有效的方法沒有使用樹搜索、環境模型或顯式HRL。當然,這些都是很大的開放研究領域,不可能系統地嘗試所有可能的研究方向,而且這些領域很可能為未來的研究帶來豐碩的成果。
需要提一下的是,我們的研究中有一些可能被認為是“hierarchical”的元素。
AlphaStar消耗的計算量如何?
問:你們使用的TPU和CPU總計算時間是多少?
David Silver:為了訓練AlphaStar,我們使用Google的v3 TPU構建了一個高度可伸縮的分布式訓練設置,該設置支持從數千個《星際爭霸2》的并行實例中學習的agents。
AlphaStar聯賽運行了14天,每個agent使用16個TPU。最終的AlphaStar agent由已發現的最有效的策略組合而成,在單個桌面GPU上運行。
AlphaStar 和 OpenAI Five 誰更強?
問:談到OpenAI Five,似乎它在DoTA2游戲中崩潰,你們是否有進行檢查看看AlphaStar在self-play中是否會出現類似的問題?
David Silver:其實有很多不同的方法可以通過self-play學習。我們發現,單純的self-play實現往往會陷入特定的策略中,或者忘記如何打敗以前的策略。
AlphaStar聯賽也是基于agent的自己與自己打,但它的多智能體學習機制鼓勵agent在面對各種不同的對手策略時進行更強的博弈,并且在實踐中,面對不同尋常的對抗模式時,似乎會產生更強的行為。
神經網絡執行一個動作需要多少時間?
問:神經網絡在GPU上運行的時間是50ms還是350ms,還是指的是不同的東西(前向傳遞 vs 動作限制)?
David Silver:神經網絡本身需要大約50ms來計算一個動作,但這只是發生在游戲事件和AlphaStar對該事件作出反應之間的處理的一部分。
首先,AlphaStar平均每250ms觀察一次游戲,這是因為神經網絡除了動作(有時稱為時間抽象動作)之外,還會選擇一些時間等待。
然后,觀察結果必須從Starcraft傳遞到Starcraft,除了神經網絡選擇動作的時間之外,這又增加了50ms的延遲。總的來說,平均反應時間是350ms。
AlphaStar對戰MaNa輸掉的那一場原因是什么?
問:許多人將AlphaStar的單次失利歸咎于算法在最后一場比賽中被限制了視覺。我個人并不認為這是一個令人信服的解釋,因為相位棱鏡在戰爭的迷霧中進進出出,而AI則在整個軍隊中來回移動作為回應。這看起來絕對像是理解上的差距,而不是機械操作上的局限。你對AlphaStar以這種方式失敗的原因有什么看法?
David Silver:很難解釋我們為什么會輸掉(或贏得)任何一場游戲,因為AlphaStar的決策很復雜,是動態多智能體訓練過程的結果。
MaNa打了一場非常精彩的游戲,似乎發現并利用了AlphaStar的一個弱點——但是很難說這個弱點是由于攝像頭、較少的訓練時間、不同的對手等等,而不是其他agent。
AlphaStar是從攝像頭還是從API獲取信息?
問:本次比賽中AI是可以看到全地圖的。這與從API中獲取原始數據并簡單地將它們抽象為結構化數據作為NN的輸入有何不同?似乎新版本不再使用要素圖層了?PySC2(DeepMind的星際爭霸II學習環境的Python組件。它將暴雪娛樂的星際爭霸II機器學習API暴露為Python RL環境)中建筑的狀態,是在造中、已建成等等。這些信息在camera_interface方法中是如何保留的?
Oriol Vinyals:實際上,通過攝像頭(和非攝像頭)接口,當我們將其作為列表輸入(由神經網絡變換器進一步處理)時,智能體就能獲得是什么建筑被被建造出來的信息。
通常,即使沒有保留這樣的列表,智能體也會知道什么建筑被建造出來。智能體的內存(LSTM)跟蹤所有先前發布的操作,以及過去訪問過的所有攝像頭位置。
我們確實為小地圖使用了要素圖層,但是對于屏幕,您可以將要素列表視為“轉置”該信息。事實證明,即使是處理圖像,將每個像素作為列表獨立處理,也能很好地工作!更多信息請參閱:https://arxiv.org/abs/1711.07971
AlphaStar的兩百年相當于人類多久時間?
問:有多少類似星際爭霸這種需要200年訓練時間的游戲?
Oriol Vinyals:平均每場比賽持續10分鐘,這相當于大約1000萬場比賽。但請注意,并非所有智能體都經過長達200年的培訓,這是各種版本的AlphaStar中智商最高的。
AlphaStar如何攢錢生成高級兵種?
問:它怎么學習到“為某種目的存錢”,比如攢錢生成高級兵種?這種“不作為”的操作被稱作NOOP,在RL算法中,會越來越多的認為NOOP是非理想點的最佳決策。
David Silver:事實上AlphaStar選擇執行多少次NOOP,就是作為其行動的一部分。
這首先是從監督數據中學習的,鏡像人類操作,這意味著AlphaStar通常以與人類玩家類似的速度進行“點擊”操作。
然后通過強化學習來改進,可以選擇減少或增加NOOP的數量。 因此,通過事先規劃好有幾個NOOP,可以很容易地實現“為X省錢”。
AlphaStar的輸入數據是實時的嗎?
問:最終使用的步長是多少?在博客中你寫道,星際爭霸的每一幀都被用作輸入的一步。但是,你還提到平均處理時間為50ms,這將超過即時游戲給定22.4fps時需要<46ms的要求。所以你們是逐幀作為輸入,還是隔幀呢?隔的幀數是固定還動態?
Oriol Vinyals:我們是逐幀的,但是由于延遲和您注意到的幾個延遲,操作將僅在該步驟結束后處理(即,我們異步播放)。 另一種選擇是鎖定步驟,這使得玩家的游戲體驗不是很好:)
AlphaStar還能玩星際2的其他地圖嗎?
問:你們是否做過泛化 (generalizations) 測試?假設沒有一個agent可以選擇不同的族來打(因為可用的單元/操作是完全不同的,甚至在架構上也不能工作),但是至少應該能推廣到其他地圖,是嗎?
David Silver:我們實際上(無意中)測試了這個。我們有一個AlphaStar的內部排行榜,我們沒有將排行榜的地圖設置為Catalyst,而是將字段留空——這意味著它能在所有的Ladder 地圖上運行。
令人驚訝的是,agent仍然很強大,表現也很不錯,盡管還不能達到我們昨天公開的那個水平。
只用臺式機如何在機器學習和強化學習領域取得好成績?
問:你有什么建議ML/RL愛好者關注的領域嗎?哪些領域不需要超過臺式機級別的計算資源就可以做出有用的貢獻?
Oriol Vinyals:有很多事情不需要大量計算資源就可以做,可以推進ML的進步。
我最喜歡的例子是我們做機器翻譯的時候,我們開發了一個叫做seq2seq的東西,它有一個大型的LSTM,在機器翻譯中達到了state of the art的性能,并且只使用了8個GPU訓練。
與此同時,蒙特利爾大學開發了叫做“attention”的機制,這是ML技術的一個根本性進步,使得模型變得更小,從而不需在大型硬件上運行。
普通玩家何時能對戰AlphaStar?
問:在11月 Blizzcon的演講中,IIRC Vinyals說他很樂意將SC2 bot開放給普通玩家。這件事有什么計劃嗎?
Oriol Vinyals:這讓人興奮!我們非常感謝社區的支持,我們希望將社區的反饋納入到我們的工作中,這也是為什么我們要發布這10個游戲回放供社區去評論和欣賞。我們將隨時告訴大家我們的計劃進展!
-
AI
+關注
關注
87文章
31148瀏覽量
269478 -
強化學習
+關注
關注
4文章
268瀏覽量
11270 -
DeepMind
+關注
關注
0文章
130瀏覽量
10882
原文標題:DeepMind回應一切:AlphaStar兩百年相當于人類多長時間?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
關于陶瓷電路板你不知道的事

十件關于PCB的趣事:帶你走進電子世界的奧秘

【電磁兼容標準解析分享】汽車電子零部件EMC標準解析---你應該了解和知道的細節(二)

還不會嗎?三分鐘讓你速通Printf~

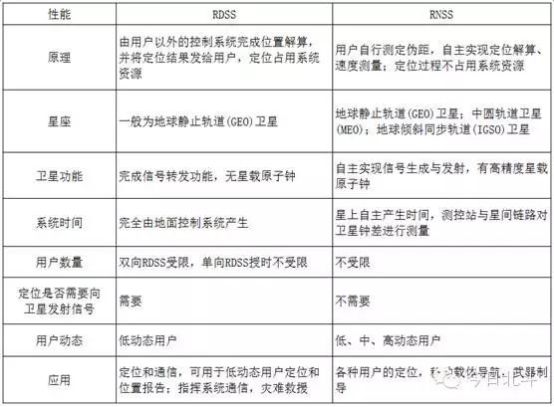
關于定位系統技術你知道多少?
解密元器件批次:你應該知道的那些事
關于MOS管,你需要知道的那些事

關于主干布線,你應該知道什么
如何實現數據線連接到SOM單元以進行USB高速連接,將CC線路連接到CYPD3177來設置電壓?
關于生成式人工智能你應該知道的7件事






 工商網監
工商網監
評論