 對NAS任務中強化學習的效率進行深入思考
對NAS任務中強化學習的效率進行深入思考
神經網絡結構搜索(Neural Architecture Search, NAS)是自動機器學習(AutoML)中的熱點問題之一。通過設計經濟高效的搜索方法,自動獲得泛化能力強、硬件友好的神經網絡結構,可以大量節省人工,解放研究員的創造力。經典的NAS方法[1]中,一個agent在trial and error中通過強化學習(Reinforcement Learning)的方式學習搭建網絡結構。本文作者對NAS任務中強化學習的效率進行了深入思考,從理論上給出了NAS中強化學習收斂慢的原因。作者進一步重新建模了NAS問題,提出了一個更高效的方法,隨機神經網絡結構搜索(Stochastic NAS, SNAS)。
1)與基于強化學習的方法(ENAS[2])相比,SNAS的搜索優化可微分,搜索效率更高,可以在更少的迭代次數下收斂到更高準確率。
2)與其他可微分的方法(DARTS[3])相比,SNAS直接優化NAS任務的目標函數,搜索結果偏差更小,可以直接通過一階優化搜索。
3)而且結果網絡不需要重新訓練參數。
4)此外,基于SNAS保持了概率建模的優勢,作者提出同時優化網絡損失函數的期望和網絡正向時延的期望,擴大了有效的搜索空間,可以自動生成硬件友好的稀疏網絡。
1. 背景
1.1 NAS中的MDP
圖1展示了基于人工的神經網絡結構設計和NAS的對比。完全基于人工的神經網絡結構設計一般包括以下關鍵流程:
1)由已知的神經變換(operations)如卷積(convolution)池化(pooling)等設計一些拓撲結構,
2)在所給定訓練集上訓練這些網絡至收斂,
3)在測試集上測試這些網絡收斂結果,
4)根據測試準確率選擇網絡結構,
5)人工優化拓撲結構設計并回到步驟1。
其中,步驟5需要消耗大量的人力和時間,而且人在探索網絡結構時更多的來自于經驗,缺乏明確理論指導。將該步驟自動化,轉交給agent在trial and error中不斷優化網絡結構,即是NAS的核心目的。
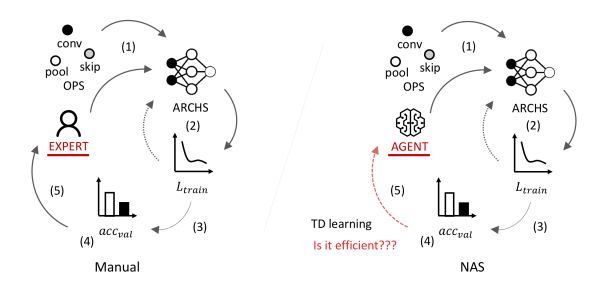
圖1: 人工神經網絡結構設計vs自動神經網絡結構搜索
在人的主觀認知中,搭建神經網絡結構是一個從淺層到深層逐層選擇神經變換(operations)的過程。 比如搭建一個CNN的時候需要逐層選擇卷積的kernel大小、channel個數等,這一過程需要連續決策,因而NAS任務自然的被建模為一個馬爾科夫決策過程(MDP)。
簡單來說,MDP建模的是一個人工智能agent和環境交互中的agent動作(action,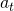 環境即是對網絡結構的抽象,狀態(state,
環境即是對網絡結構的抽象,狀態(state,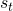 動作表示的是在下一層中要選怎樣的卷積。
動作表示的是在下一層中要選怎樣的卷積。
在一些情況下,我們會用策略函數(policy,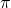 總得分,也就是搭建的網絡在測試集上的精度(accuracy),通過強化學習(Reinforcement Learning)這種通用黑盒算法來優化。然而,因為強化學習本身具有數據利用率低的特點,這個優化的過程往往需要大量的計算資源。
總得分,也就是搭建的網絡在測試集上的精度(accuracy),通過強化學習(Reinforcement Learning)這種通用黑盒算法來優化。然而,因為強化學習本身具有數據利用率低的特點,這個優化的過程往往需要大量的計算資源。
比如在NAS的第一篇工作[1]中,Google用了1800 GPU days完成CIFAR-10上的搜索。雖然通過大量的平行計算,這個過程的實際時間(wallclock time)會比人工設計短,但是如此大計算資源需求實際上限制了NAS的廣泛使用。[1]之后,有大量的論文從設計搜索空間[4]、搜索過程[2]以及model-based強化學習[5]的角度來優化NAS效率, 但“基于MDP與強化學習的建模”一直被當作黑盒而沒有被討論過。
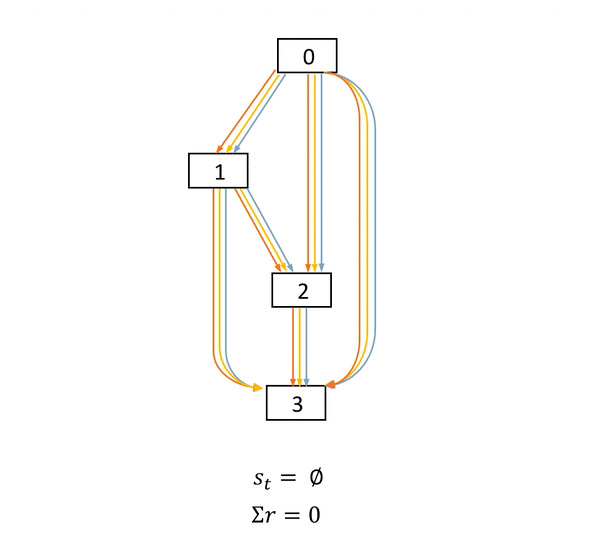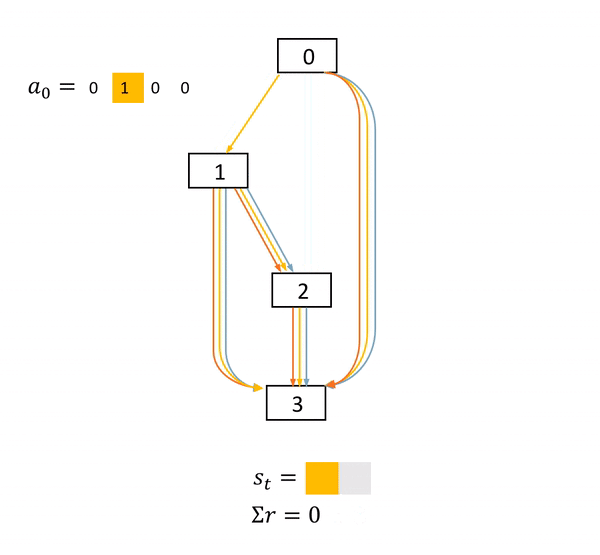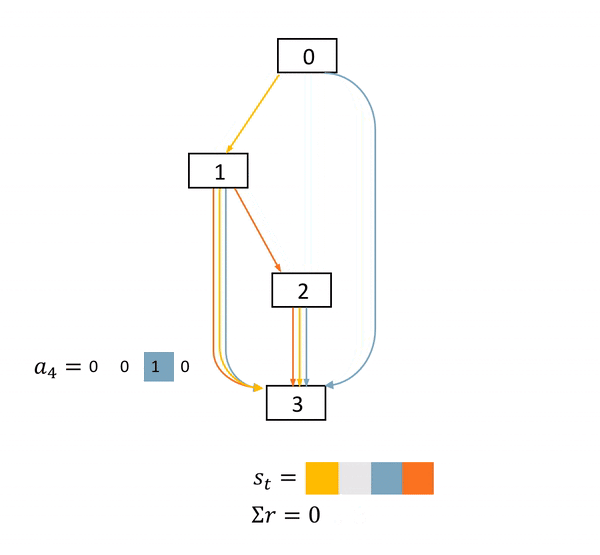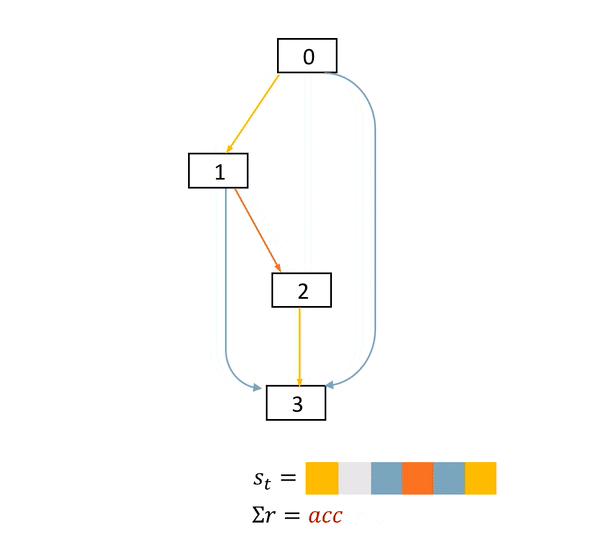
圖2: NAS是一個確定環境中的完全延遲獎勵任務。在這個DAG中,方框表示節點,具體的物理意義是feature map。不同顏色的箭頭表示不同的operations。s表示當前網絡結構狀態,a表示每一步的動作,r表示得分。只有在網絡結構最終確定后,agent才能獲得一個非零得分acc
本文作者的關鍵insight來自于發現了NAS任務的MDP的特殊性。圖2展示了一個NAS的MDP的完整過程。可以看到的是,在每一個狀態(state)中,一旦agent產生了動作,網絡結構狀態的改變是確定的。而在一個網絡被完全搭建好并訓練及測試之前,agent的每一個動作都不能獲得直接的得分獎勵。agent只會在整一條動作序列(trajectory)結束之后,獲得一個得分。
我們簡單總結一下,就是,NAS是一個確定環境中的完全延遲獎勵的任務。(A task with fully delayed reward in a deterministic environment.)如何利用網絡結構狀態改變的確定性,將在下一個章節被討論。
在本章節接下來的部分,我們先介紹一些強化學習領域的背景,解釋一條動作序列的得分是如何被分配到每一次動作上的,以及延遲獎勵為什么造成了這種得分分配的低效。
1.2 TD Learning與貢獻分配
強化學習的目標函數,是將來得分總和的期望。從每一個狀態中動作的角度來說,agent應該盡量選擇長期來說帶來最大收益的動作。然而,如果沒有輔助的預測機制,agent并不能在每一個狀態預測每一個動作將來總得分的期望。TD Learning就是用來解決這個問題,預測每一個動作對將來總得分的貢獻的。TD(0),一種最基本的計算每一個狀態上的總得分期望(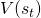 )的TD Learning,如以下公式所示:
)的TD Learning,如以下公式所示:
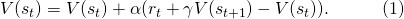
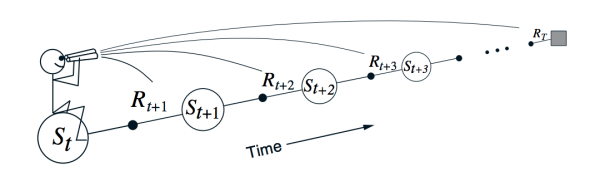
圖3: 在TD Learning中,agent對于某一狀態價值的評估基于它對將來狀態的評估,圖片來自 [6]
可以看出,以一種基于動態規劃的方式,agent對于每一個狀態的將來總得分的期望,從將來的狀態向過去傳播。Sutton在[6]中用一張圖來表現了這種得分從后向前的傳播,如圖3所示。
也就是說,agent對于某一狀態的價值的評估基于它對該狀態將來狀態的評估。值得注意的是,(1)中TD的回傳是一個局部的回傳,并不會在一個回傳就實現將最后一個狀態的信息傳遞到之前的每一個節點。這是一個很極端的例子,agent對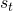 ?的價值評估,完全取決于
?的價值評估,完全取決于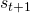 ,在一次更新中,信息只會向前傳遞一步。根據動態規劃,如果只有這一條trajectory是可能的,這個傳遞的總時間就是這條trajectory的長度。當可能出現trajectory超過一條時,就需要根據出現的概率來取期望。
,在一次更新中,信息只會向前傳遞一步。根據動態規劃,如果只有這一條trajectory是可能的,這個傳遞的總時間就是這條trajectory的長度。當可能出現trajectory超過一條時,就需要根據出現的概率來取期望。
像(1)這種動態規劃的局部信息傳遞帶來的風險就是,當將來某些狀態的價值評估出現偏差時,它過去的狀態的價值評估也會出現問題。而這個偏差只能通過更多次的動態規劃來修復。
當一個任務趨向于復雜,狀態空間的維度越來越高時,上面說到的將來狀態價值評估的偏差基本不可避免,TD learning的收斂時間大大增加。
經典的強化學習領域中有很多方法嘗試解決這個問題。比如放棄TD直接通過蒙特卡洛(Monte Carlo,MC )采樣來做價值評估。此外,也可以通過eligibility trace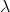
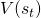 出現偏差的風險被將來更多的
出現偏差的風險被將來更多的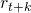 分攤。這里我們不繼續發散,感興趣的讀者可以查閱Sutton的textbook[6]。
分攤。這里我們不繼續發散,感興趣的讀者可以查閱Sutton的textbook[6]。
1.3 延遲獎勵中的貢獻分配
在1.1中,我們介紹到,NAS是一個完全延時獎勵的任務。運用我們在1.2中介紹的數學模型,我們可以把這個發現表達為:
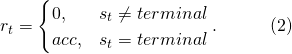
當我們把(2)代入(1)之中,我們會發現,基于TD Learning的價值評估,在TD learning的早期,當正確的貢獻分配還沒有從最終網絡結構狀態傳到決定淺層網絡的動作時,因為環境本身沒有反饋給這一步的得分,淺層網絡被分配到的貢獻接近于0,這是一個天然的偏差。當然,如1.2中介紹,這個偏差也可以通過設計各種方式結合Monte Carlo的預測來彌補,但是完全延遲獎勵對于MC方法來說又會帶來
 的收斂。
的收斂。
對于延遲獎勵,RUDDER[7]經過一系列嚴格的證明,得到了如下結論:
1)延遲獎勵會指數級延長TD的收斂需要的更新次數;
2)延遲獎勵會給指數級多的狀態的MC價值評估帶來抖動。
他們提出的解決方式是用一個神經網絡來擬合每條trajectory的總得分,并通過這個神經網絡里的梯度回傳來將得分分配到輸入層的所有狀態中,繞過TD和MC。我們繼續回到搭建CNN的例子,如果要實現這個方法,就需要構建一個新的神經網絡,它的輸入是表達網絡結構的編碼(encoding),輸出是預測的該網絡結構的精度。
在[7]的實驗中,這種通過額外訓練一個可微分的總得分函數來分配貢獻的方法,表現出了非常明顯的收斂速度提升,如圖4。然而,這個額外的神經網絡需要額外的數據和額外的訓練,而且它能否收斂到真實的總得分并沒有保證。更重要的是,這個神經網絡回傳的梯度分配的貢獻是否合理,在普通延遲獎勵的任務中只能有一個現象級的評估,可解釋性有限。
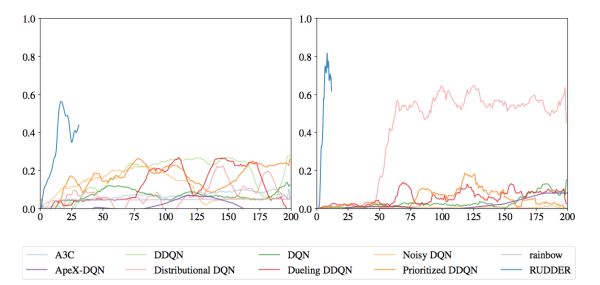
圖4: 在延時獎勵的游戲Bowling和Venture中,基于微分的貢獻分配方法RUDDER收斂速度明顯快于基于TD和MC的方法,圖片來自 [7]
2. 方法
2.1 重新建模NAS
本文作者的第一條關鍵insight是,當我們用損失函數(loss function)來替代準確率,不需要像RUDDER一樣額外擬合一個得分函數,NAS問題的總得分就已經不是一個來自環境的常數而是一個可微函數了。基于1.3的介紹,這很可能大幅提高NAS的搜索效率。又因為損失函數和準確率都可以表達一個網絡學習的結果,這一替換并沒有在本質上改變NAS問題原本的“優化網絡結構分布以使得它們的期望性能最好”的目標(objective)。于是我們有
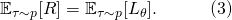
其中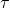 表示的是trajectory,?
表示的是trajectory,?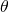 是網絡參數,或者更具體的說是所有可能神經變換的參數。
是網絡參數,或者更具體的說是所有可能神經變換的參數。
而第二條insight來自于我們在1.1中介紹的,NAS任務的狀態轉移是確定的。在確定性的環境中,一條狀態動作序列出現的概率可以表達為策略函數概率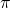 的連乘
的連乘
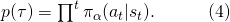
將(3)和(4)結合起來看,我們發現
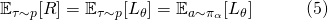
這是一個非常常見的生成式模型(generative model)的目標函數。因而我們可以使用生成式模型中的一些方法,重新表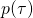 ?. 比如將?
?. 比如將?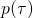 ?建模成一個fully factorizable的分布
?建模成一個fully factorizable的分布
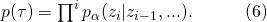
如果我們假設每一次動作是相互獨立的,這個分解可以寫成
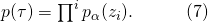
其中,為了與MDP的建模區分開,我們用決策 來替換動作
來替換動作 ?。將(6)或者(7)帶入(5)中,我們得到了一個新的目標函數
?。將(6)或者(7)帶入(5)中,我們得到了一個新的目標函數
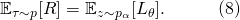
2.2 用隨機神經網絡表達NAS任務
在經典的基于強化學習的NAS方法中,agent的損失函數和網絡本身的損失函數并不連通:
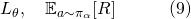
因而他們的計算圖也不需要連通。圖五展示了一個基于強化學習的NAS中agent和網絡交互前向(forward)及各自后向(backward)更新的過程。

圖5: 基于強化學習的NAS的前向和后向,網絡結構策略的后向需要利用TD來做貢獻分配,收斂速度不能保證,資源消耗大
與(9)不同的是,在本文作者重新建模的目標函數(8)中,表達網絡結構分布的參數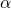 ?和網絡變換的參數?
?和網絡變換的參數?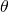 ?被統一在了一起,這就為一次后向同時更新?
?被統一在了一起,這就為一次后向同時更新?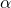 ?和?
?和?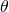 ?提供了可能,也就是說有可能實現在更新?
?提供了可能,也就是說有可能實現在更新?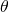 的同時將可微的總得分分配到每一條邊的決策上。然而,要達到這個目的,我們首先需要將網絡結構分布
的同時將可微的總得分分配到每一條邊的決策上。然而,要達到這個目的,我們首先需要將網絡結構分布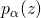 構建進神經網絡的計算圖里,以在一次前向中實現對子網絡結構的采樣。
構建進神經網絡的計算圖里,以在一次前向中實現對子網絡結構的采樣。
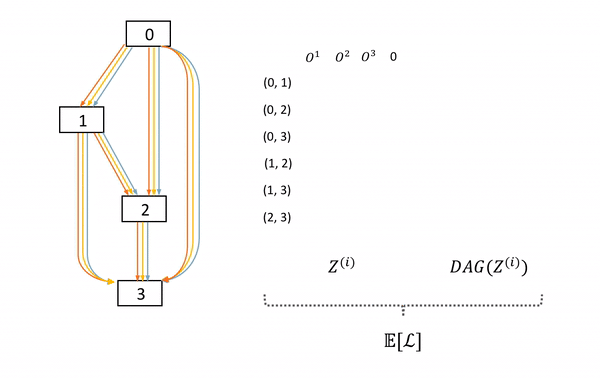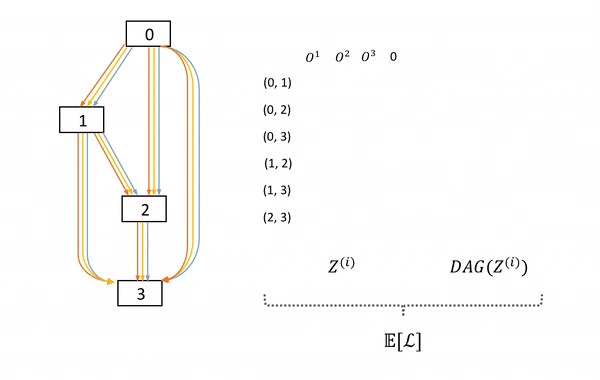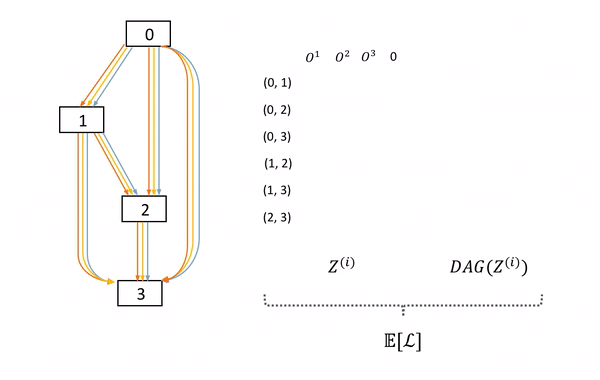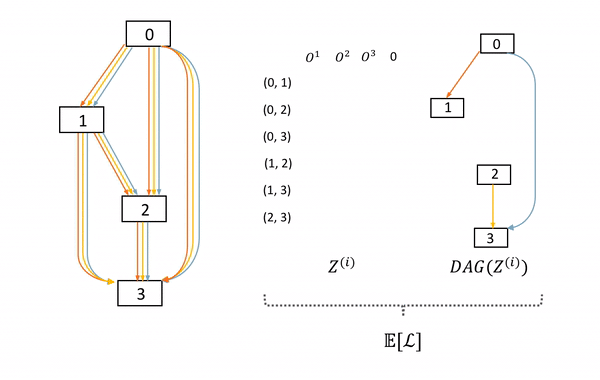
圖6: SNAS中子網絡的采樣及前向過程。左邊DAG為母網絡,中間的矩陣表示每次在母網絡每條邊上采樣的決策z,右邊為這次采樣的子網絡。
本文作者提出,這一采樣過程可以通過將網絡結構分布融合到母網絡以形成隨機神經網絡(Stochastic Neural Network, SNN)來實現。具體來說,從母網絡中產生子網絡,可以通過在母網絡的每一條邊的所有可能神經變換的結果后乘上一個one-hot向量來實現。而對于子網絡的采樣,就因此自然轉化為了對一系列one-hot隨機變量的采樣
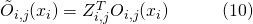
其中表示節點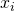
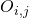
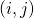 ?上選擇的神經變換(operations),?
?上選擇的神經變換(operations),?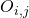 表示在邊?
表示在邊?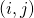 ?上所有的神經變換,
?上所有的神經變換,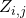 表示在邊?
表示在邊?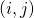 ?上的one-hot隨機變量。圖6展示了這種SNN中一個cell的采樣方法。
?上的one-hot隨機變量。圖6展示了這種SNN中一個cell的采樣方法。
因為SNAS被定位為通用神經網絡結構搜索方法,在構建母圖時,作者采用了與ENAS及DARTS相同的方法。這體現在:
1)在模塊(cell)基本母圖中,設計了超過一個輸入節點(input node),表示該cell的輸入來自于之前哪些模塊的輸出,因而包含了產生cell之間的skipping和branching的可能;
2)在設計每個cell中的中間節點(intermediate node)的輸入時考慮了所有來自cell內所有之前中間節點的輸入邊(input edge),并在每條輸入邊上提供的神經變換(operation)中包括了Identity的變換和0的變換,用以表達skip和直接刪除這條輸入邊。因此考慮了所有之間skipping和branching的可能。
將(10)與這種母網絡結合,我們可以獲得每一個節點的實際數學表達
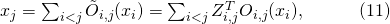
這是一個在之前確定神經層上的一個隨機的線性變換。將它考慮進來,我們可以進一步完善SNAS的目標函數
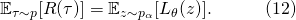
2.3 可微化近似
經過2.1和2.2,我們獲得了一個表達NAS任務的隨機神經網絡,定義了它的損失函數。接下來我們要解決的問題就是,如何計算這個損失函數對網絡結構參數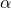
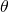 的梯度。
的梯度。
對一個如(12)的目標函數的求導,特別是對期望項的求導,最經典的方法是likelihood ratio trick,它在強化學習中策略梯度(policy gradient)的推導中被使用。然而,這一方法的主要問題是由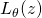 抖動帶來的較大的梯度方差(variance),并不利于整個優化過程的收斂。特別是考慮到?
抖動帶來的較大的梯度方差(variance),并不利于整個優化過程的收斂。特別是考慮到?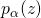 本身的維度比較高(其維度等于所有輸入邊的總數),如何降低likelihood ratio trick帶來的梯度方差本身就仍然是一個未解決的問題(open question)。?
本身的維度比較高(其維度等于所有輸入邊的總數),如何降低likelihood ratio trick帶來的梯度方差本身就仍然是一個未解決的問題(open question)。?
在這里,作者選擇了另一種可微化近似方法,重參數法(reparameterization)。這是一種在當前深度生成式模型(Deep Generative Model)中被驗證有效的方法。具體來說,在實現一個離散分布時,有一種方法是先采樣與該one-hot vector維度相同數量的連續均勻分布(uniform distribution)的隨機變量,將他們經過Gumbel變換轉為Gumbel隨機變量,并從中選擇最大的那一維度(argmax)取為1,其他維度為0。這個變換被稱為Gumbel-max。這樣采樣的隨機變量的分布與該離散分布相同,而離散分布的參數也就轉化為了Gumbel max中的參數,實現了對該離散分布的重參數化。
但是因為argmax這個操作本身不可微,[8,9]提出將max近似為softmax,
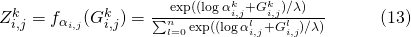
他們同時證明了當softmax的溫度(temperature)趨近于0時,該方法產生的隨機變量趨近于該離散分布。 作者在論文中給出了近似后的損失函數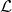
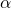

圖7: SNAS中的前向和后向,通過構建隨機神經網絡和可微化近似,保證了前向的采樣能夠估計NAS的優化目標,后向可以將梯度回傳到網絡結構分布的參數上,因此無偏而高效。
2.4 網絡正向時延懲罰與網絡稀疏化
除了從開始就一直提的搜索效率問題之外,經典的NAS方法還有一個更加實際的問題,就是設計出的網絡往往為了追求精度而過于復雜。具體體現在agent最終學會搭建一個有復雜拓撲結構的網絡,這導致在訓練中需要消耗比較多的時間,就算是在實際的使用中,網絡前向的時延也非常長。
本文作者的第三條insight是,agent對于這些復雜網絡的偏好,一方面來自于在優化目標中并沒有一個對于前向時延的限制,另一方面來自于在最終網絡的選取中依然有不在優化目標中的人工操作(如在DARTS中,每個中間節點強制要求選擇top-2權重的輸入邊上的top-1權重的非0神經變換),因此在整個網絡結構搜索的過程中并不能自動實現網絡的稀疏化,也就是說有一些搜索空間在最后被放棄了。
鑒于在2.2中介紹到的母網絡的設計中實際已經包含了直接刪除某條輸入邊的可能,本文作者嘗試從補充優化目標入手,以期達到不需要在子網絡的選取中加入人工就能自動獲得稀疏網絡的目的。這個目的被建模為“在給定的網絡正向時延預算下優化網絡準確率”的問題
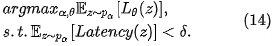
通過拉格朗日變換(Lagrangian transformation),我們可以將(14)轉化為對網絡正向時延的懲罰
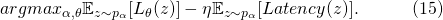
其中,如果每個網絡的正向時延可以在具體部署的硬件上測得,對于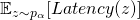
這些量值包括參數量、浮點計算數(FLOPs)以及需要的內存。使用這些量的一大優勢在于,采樣出的子網絡的這些值的總量計算是與(11)一樣是一個對于各個備選神經變換的一些常量(如長、寬、通道數)的隨機線性變換。與(11)相似,我們有
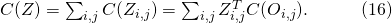
因而相較于在每一條輸入邊上優化一個全局的網絡正向時延,我們只需要優化每條邊上自己對時延的貢獻量。如果回到之前貢獻分配的語境,全局的時延懲罰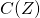 被線性分配到了每一條邊的決策
被線性分配到了每一條邊的決策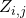 上,這有利于提高收斂效率。又因為(16)是一個線性的變換,我們既可以用重參數化計算?
上,這有利于提高收斂效率。又因為(16)是一個線性的變換,我們既可以用重參數化計算?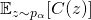 的期望,也可以用策略梯度的方法。
的期望,也可以用策略梯度的方法。
3. 深度探究
3.1 SNAS中的貢獻分配
在之前的介紹中,雖然在2.1中提到了SNAS中使用了得分的可微性可以解決1.3中提到的在NAS這個完全延時獎勵任務中TD Learning可能會遇到的問題,這種得分分配仍然是一個黑盒。為了提高方法的可解釋性,作者通過數學推導,證明了SNAS中用來更新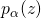 ?的梯度
?的梯度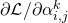 的期望在策略梯度中的等價形式,每一條輸入邊
的期望在策略梯度中的等價形式,每一條輸入邊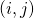 上的決策
上的決策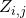 ?被分配到的得分為
?被分配到的得分為
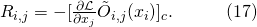
比較明顯的是,這個得分可以被解釋為一個對于得分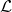 ?的一階泰勒展開(Taylor Decomposition)。對于cell中的某一個節點
?的一階泰勒展開(Taylor Decomposition)。對于cell中的某一個節點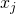 ,它會聚集所有從輸出邊回傳的貢獻?
,它會聚集所有從輸出邊回傳的貢獻?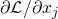 ,并把它按照的權重分配到它的所有輸入邊?
,并把它按照的權重分配到它的所有輸入邊?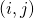 。又由(10)我們知道,分配在?
。又由(10)我們知道,分配在?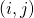 上的貢獻會根據隨機變量
上的貢獻會根據隨機變量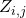 ?來進行分配,當
?來進行分配,當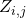 無限趨近于one-hot時,貢獻會完全被分配到被選擇的那個神經變換。
無限趨近于one-hot時,貢獻會完全被分配到被選擇的那個神經變換。
這種基于一階泰勒展開的貢獻分配,在[12]中被用來解釋神經網絡中每個神經元的重要性,是目前比較被接受的解釋神經網絡中不同模塊重要性的方法。
在1.2中,我們介紹了MDP建模中,在搜索早期TD Learning因為價值評估還沒來得及回傳到淺層的動作,它們被分配的貢獻并不合理。在1.3中,我們介紹到雖然這個不合理最終可以被修正,整個修正的過程卻需要比較長的時間。而SNAS中的貢獻分配從最開始就是合理的,而且每一步都是合理的,因而幸運的避開了這項時間成本。
這可以從一定程度上解釋為什么SNAS的搜索比基于強化學習的搜索收斂快。與1.3中提到的RUDDER相比,SNAS利用了NAS任務的特殊性,搭建了一張連通網絡結構分布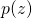 ?和任務環境也就是網絡結構的計算圖,使得總得分函數天然可微,而且貢獻分配合理可解釋。
?和任務環境也就是網絡結構的計算圖,使得總得分函數天然可微,而且貢獻分配合理可解釋。
當與2.4中提到的網絡正向時延向結合時,(17)中提到的得分會有一個懲罰項的補充,而這個懲罰項因為2.4中介紹的(16)的線性可分性同樣可以解釋為一種一階泰勒展開。
3.2 SNAS與DARTS的關系
在SNAS之前,Liu et al. 提出了一種可微分的神經網絡結構搜索,DARTS。不同于SNAS中通過完整的概率建模來提出新方法,DARTS將網絡結構直接近似為確定性的連續權重,類似于注意力機制(attention)。在搜索過程中,表達這個softmax連續權重的參數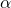 與網絡神經變換的參數?
與網絡神經變換的參數?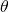 ?同時被更新,完全收斂之后選擇
?同時被更新,完全收斂之后選擇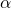 的argmax搭建子網絡,再重新訓練?
的argmax搭建子網絡,再重新訓練?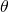 ?。
?。

圖8: DARTS中的前向和后向,因為并沒有子網絡采樣的過程,優化的損失函數并不是NAS的目標函數
因為SNAS直接優化NAS的目標,作者從SNAS的建模出發,對DARTS的這一近似作出了概率建模下的解釋:這種連續化的近似可以被理解為是將(12)中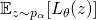 的全局期望
的全局期望
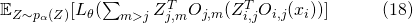 直接分解到每一條輸入邊上,計算了一個解析的期望
直接分解到每一條輸入邊上,計算了一個解析的期望
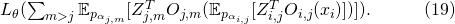
如果說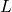 ?對于每一個
?對于每一個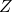 都是線性的,(19)與(18)就是等價的。但是因為設計了 ReLU-Conv-BN 的堆疊,帶來了非線性,這兩個目標并不等價。
都是線性的,(19)與(18)就是等價的。但是因為設計了 ReLU-Conv-BN 的堆疊,帶來了非線性,這兩個目標并不等價。
也就是說,在DARTS的連續化近似中帶來了很大的偏差(bias)。這一方面帶來了最終優化的結果并沒有理論保證的問題,使得一階優化(single-level optimization)的結果不盡人意;另一方面因為連續化近似并沒有趨向離散的限制,最終通過刪除較低權重的邊和神經變換產生的子網絡將無法保持訓練時整個母網絡的精度。
Liu et al. 提出用二階優化(bi-level optimization)通過基于梯度的元學習(gradient-based meta learning)來解決第一個問題,但是對于第二個問題,并沒有給出一個自動化的解法,而是人工定義了一些規則來挑選邊和神經變換,構建子網絡,再重新訓練。
4. 實驗
4.1 CIFAR-10上的搜索效率
從ENAS開始,在極致壓縮搜索資源成本的方向上,比較常見的方法是先搜索少量的cell,再把它們堆疊起來,重新訓練。為了和現有的通用NAS方法進行公平的對比,本文作者也采用了相同的方法,在一張GPU上針對CIFAR-10任務搜索cell結構。
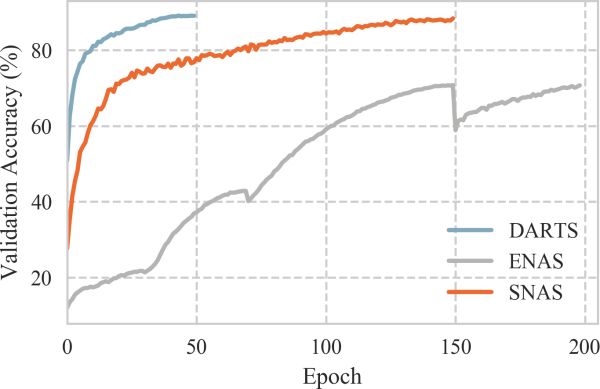
圖9: SNAS, ENAS和DARTS在搜索中的validation accuracy隨著訓練epoch數的變化
圖9展示了整個搜索過程中SNAS、ENAS和DARTS的測試準確率隨著epoch數的變化。可以看到的是SNAS如作者理論預言的一樣,收斂速度明顯快于ENAS,而且最后收斂的準確率也遠遠高于ENAS。雖然從這張圖里看起來DARTS的收斂速度快于SNAS,而且二者的收斂精度相似,但是這個準確率是整張母圖的準確率,基于3.2中的分析,它并不能反應最終子網絡的性能。
4.2 搜索結束直接產生子網絡
為了直觀表現3.2中提到的第二個問題,即DARTS最終獲得的子網絡并不能直接使用而一定需要參數的重新訓練,并檢測作者對于SNAS可以避免這個問題的理論預言,作者提供了上圖搜索結束之后DARTS和SNAS按照各自的方式產生子網絡的準確率。

圖10: SNAS與DARTS在搜索收斂時的準確率和直接產生子網絡的準確率對比
從圖10可以看到,SNAS中產生的子網絡可以保持搜索時的測試集準確率,而DARTS的結果并不能。Liu et al. 提出的解決方案是,重新訓練子網絡100個epoch。當把這部分時間同樣算進去,再外加上DARTS沒有最優的保證可能需要訓練多個網絡再進行選擇,(如原文中Liu et al. 搜索了十次選擇其中最好的,)SNAS的實際搜索效率遠高于DARTS。
同時,在構建子網絡的過程中,作者發現,同樣訓練150個epoch,SNAS的網絡結構分布,相對于DARTS中的softmax,對每條邊上的決策更加確定。圖11展示了這兩個分布的信息熵(entropy)的對比,SNAS的熵小于DARTS。
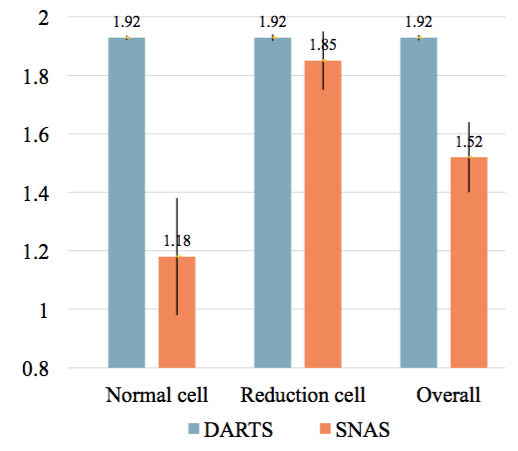
圖11: SNAS與DARTS搜索收斂后網絡結構分布的信息熵
4.3 搜索過程中的網絡演化
在2.4中介紹到,除了重新建模NAS問題,SNAS的另一項創新點在于通過優化網絡正向時延懲罰來自動實現網絡稀疏化,避免搜索出正向時延過長的網絡。在ENAS和DARTS中,最終的網絡都是通過人工規則來挑選每個節點上的兩條輸入邊的,在這個規則下的演化過程主要就是對每條邊上神經變換的替換。而SNAS有可能在搜索過程中就出現網絡本身拓撲結構的演化。
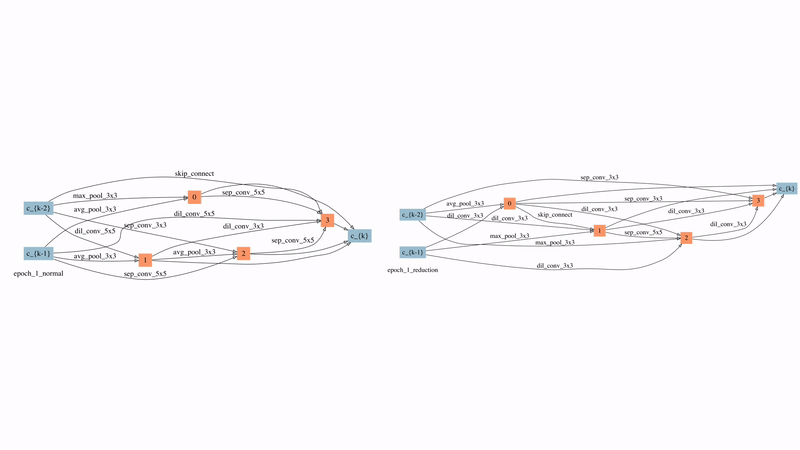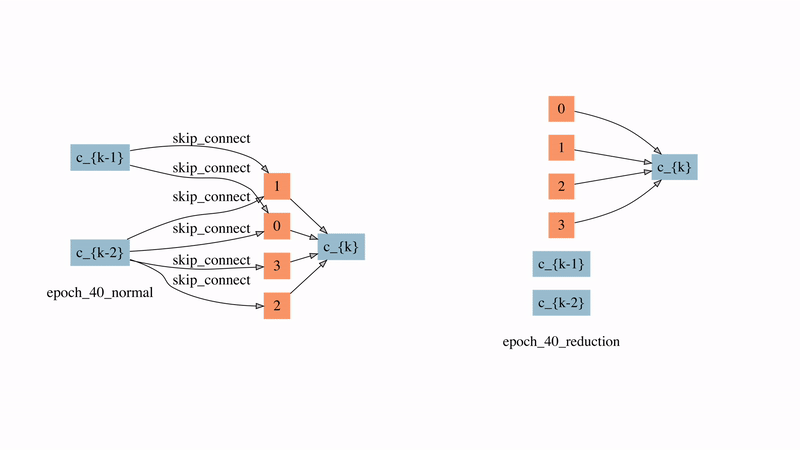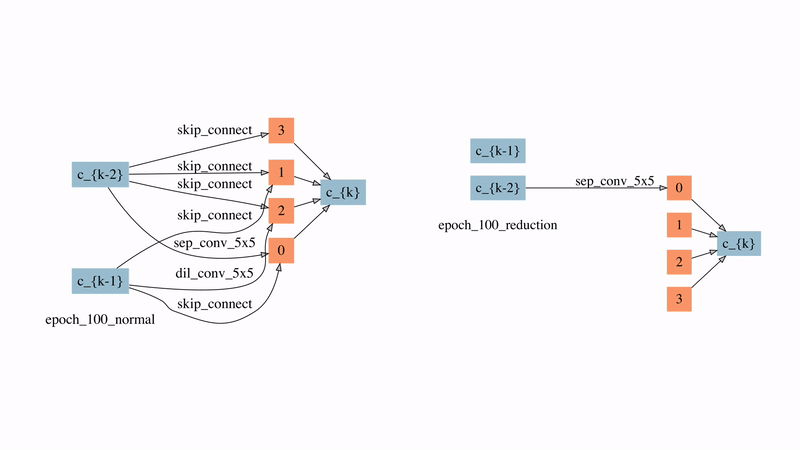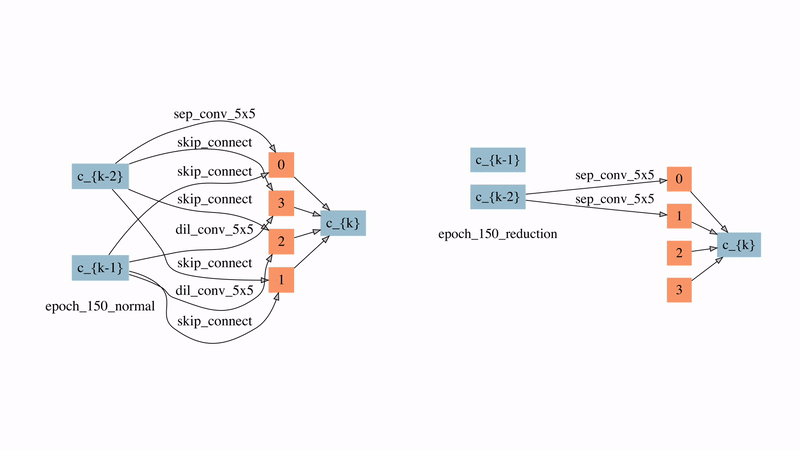
圖12: 在較強時延懲罰下的normal cell和reduction cell的演化過程
圖12展示了SNAS在較強延時懲罰下的normal cell和reduction cell的演化過程。可以看到的是,在搜索的非常早期,大部分的邊就因此被自動刪除了。有兩點比較有意思的觀察:
1)來自于藍色節點即輸入節點的邊在reduction cell中直到80個epoch之后才出現,這意味著在前80個epoch中reduction cell都是被跳過的,直到需要時它才被引入。
2)在normal cell中最后學習的結果是自動產生了每個節點有且僅有兩條輸入邊的拓撲結構,這說明ENAS和DARTS中做top-2的選擇有一定的合理性。但在reduction cell中最后的結果是有一半的節點沒有被使用,這對之前人工設計的子網絡生成規則提出了挑戰。
4.4 不同程度延時懲罰的影響
作者在實驗中嘗試了三種不同程度的時延懲罰:
1)較弱時延懲罰是一個時延懲罰的邊界值,由它搜出的網絡會出現邊的自動刪除,搜索結果如圖13。當時延懲罰小于這個值時,時延懲罰更多的體現在對每條邊上的簡單神經操作的偏好上。
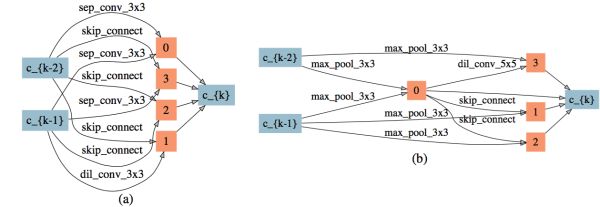
圖13: 較弱時延懲罰下搜索出的網絡結構,(a): normal cell,(b): reduction cell
2)中等時延懲罰與較弱時延懲罰相比降低了網絡的深度和網絡參數量,并且帶來了更高的準確率(見4.5章),表現出了一定的正則效果。搜索結果如圖14。
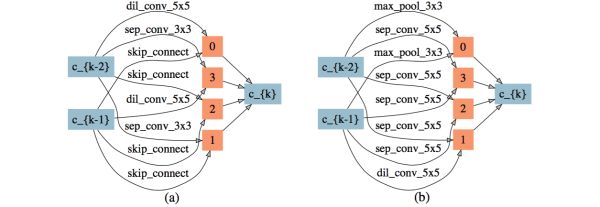
圖14: 中等延時懲罰下搜索出的網絡結構,(a): normal cell,(b): reduction cell
3)較強時延懲罰下可以直接刪除中間節點,搜索結果如圖15。可以看到節點2、3的輸入邊被完全刪除。同時,因為輸入節點 k-1 無輸出邊,整個cell的拓撲結構被大大簡化。
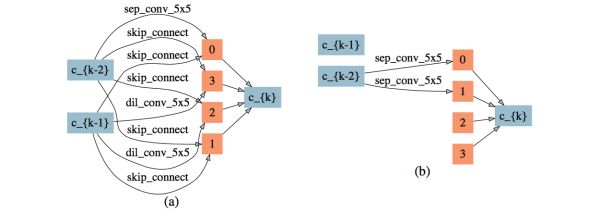
圖15: 較強延時懲罰下搜索出的網絡結構,(a): normal cell,(b): reduction cell
4.5 CIFAR-10搜得結果網絡的評估
與DARTS相同,作者將SNAS搜得的cell堆疊起來,在CIFAR-10上重新訓練參數,獲得了state-of-the-art的精度,如圖16所示。
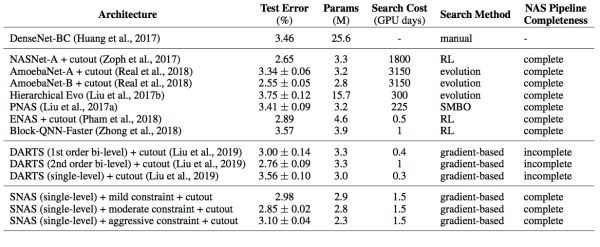
圖16: SNAS搜得的cell與其他NAS方法及人工設計結構在CIFAR上的對比
值得注意的是,一階優化的DARTS的結果并不如不優化網絡結構分布產生完全均勻分布產生的結果,而一階優化的SNAS達到了DARTS二階優化獲得的準確率。而且因為前向時延懲罰的加入,SNAS搜得的網絡在參數量上小于其他網絡,卻獲得了相近的準確率。特別是在中等時延懲罰下,SNAS的子網絡在使用更少參數的情況下準確率超過了較弱時延懲罰獲得的網絡,表現出了時延懲罰的正則效果。
4.6 CIFAR-10搜得結果網絡對ImageNet的拓展
與DARTS相同,作者提供了將SNAS搜得的cel拓展到tiny ImageNet上獲得的結果,如圖17所示。盡管使用更少的參數量和FLOPs,子網絡可以達到state-of-the-art的準確率。
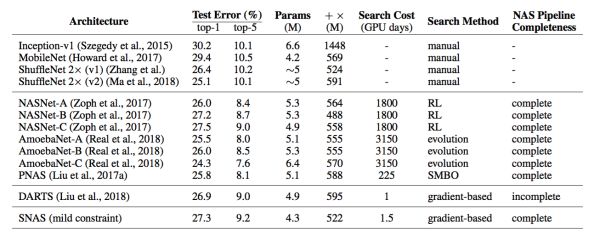
圖17: SNAS搜得的cell與其他NAS方法及人工設計結構在ImageNet上的對比
5. 結語
隨機神經網絡結構搜索(SNAS)是一種高效率、低偏差、自動化程度高的神經網絡結構搜索(NAS)框架。作者通過對NAS進行重新建模,從理論上繞過了基于強化學習的方法在完全延遲獎勵中收斂速度慢的問題,直接通過梯度優化NAS的目標函數,保證了結果網絡的網絡參數可以直接使用。
相較于其他NAS方法中根據一定規則產生子網絡的方式,作者提出了一套更加自動的網絡拓撲結構演化方法,在優化網絡準確率的同時,限制了網絡結構的復雜度和前向時延。相信隨著這一研究的不斷深入,我們會看到更多SNAS在大數據集、大網絡以及其他任務中的發展。
-
神經網絡
+關注
關注
42文章
4771瀏覽量
100713 -
機器學習
+關注
關注
66文章
8406瀏覽量
132561 -
強化學習
+關注
關注
4文章
266瀏覽量
11246
原文標題:一文詳解隨機神經網絡結構搜索 (SNAS)
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

什么是深度強化學習?深度強化學習算法應用分析

將深度學習和強化學習相結合的深度強化學習DRL
什么是強化學習?純強化學習有意義嗎?強化學習有什么的致命缺陷?

用PopArt進行多任務深度強化學習
強化學習在智能對話上的應用介紹
機器學習中的無模型強化學習算法及研究綜述

NeurIPS 2023 | 擴散模型解決多任務強化學習問題

通過強化學習策略進行特征選擇






 工商網監
工商網監
評論