 揭秘星際2人工智能AlphaStar:DeepMind科學家回應一切
揭秘星際2人工智能AlphaStar:DeepMind科學家回應一切
25 日凌晨,人工智能 AlphaStar 與職業玩家 MaNa 進行了一場史無前例的「人機大戰」:雖然之前在內部比賽中 AI 十戰十勝,但現場比賽中,MaNa 機智地戲耍了對手,為人類取得了一場勝利。賽后,DeepMind 科學家、AlphaStar 項目的領導者 Oriol Vinyals 和 David Silver 在 Reddit 上回答了人們關心的很多問題。與此同時,曾與人工智能交手的兩位職業玩家,Liquid 戰隊的 TLO 與 MaNa 也作為嘉賓回答了一些有趣的問題。
例如:對于 AI 研究者來說,打星際 2 的能力是不是應該寫進簡歷里?
網友 NexYY:我應該把會打星際爭霸 2 作為一項技能寫在簡歷里證明我是一個有抱負的 AI 開發者嗎?有時我沉迷于打星際,而不是提高寫代碼的能力,我常常因此感到迷茫……
Oriol Vinyals:在比賽那天我打了好多盤星際,我得說這是非常好的體驗——特別是考慮到它塑造了我在人工智能、學習計算機科學等方面的動力。所以如果你想完成一個好簡歷,請把星際爭霸 2 當做一個愛好寫進去,祝你好運!
1 月 25 日,AlphaStar 與 MaNa 的人機大戰,以及此前對戰的一些精彩鏡頭。現場比賽從 10:30 開始。
問:從 pysc2 的早期版本(和目前的 master 版本)來看,似乎 DeepMind 開發的方法是基于對人類游戲過程的完全模仿,如 bot 無法獲得屏幕視角外任何東西的信息。而這個版本似乎放開了這些限制,因為要素圖層現在是「全地圖大小」,而且添加了新的要素。是這樣嗎?如果是,那這與從 API 中獲取原始數據并將其簡單抽象成結構化數據來作為神經網絡的輸入有什么真正的不同呢?DeepMind 博客中甚至表明,直接將原始數據和屬性以列表形式的數據輸入神經網絡,這似乎表明你們不再真正使用要素圖層了?
Oriol Vinyals:事實上,有了基于鏡頭的(和不基于鏡頭的)輸入界面,智能體知道已經構建了什么,因為我們將其作為列表(由神經網絡 Transformer 進一步處理)輸入。一般來說,即使你沒有那種列表,智能體也會知道已經構建了什么,因為智能體的記憶會跟蹤所有之前發生的動作,以及過去訪問的所有視圖的位置。
問:當我使用 pysc2 時,我發現要了解已經構建、正在進行、已經完成的事物是一件非常困難的事,因為我必須一直平移相機視圖來獲取這些信息。camera_interface 方法是如何保存這些信息的?即使在 camera_interface 模式下,通過原始數據訪問(如 unitTypeID、建筑物等的計數),大量數據仍是完全可用的?
Oriol Vinyals:是的,我們的確放開了智能體的視角,主要是因為算力原因——沒有屏幕移動的游戲大約會有 1000 步,而有屏幕移動的游戲步數會是前者的 2-3 倍。我們的確為迷你地圖使用了要素圖層,但是對于屏幕,你可以認為要素列表「轉換」了那些信息。實際上,事實證明,即使是在處理圖像上,將每個像素單獨作為一個列表效果也很好!
問:達到當前水平需要玩多少把游戲?換句話說,在你們的案例中,200 年游戲時間一共打了多少把游戲?
Oriol Vinyals:如果平均每場比賽持續 10 分鐘,這相當于大約 1000 萬場比賽。不過請注意,并不是所有智能體的訓練時間都相當于 200 年的游戲時間,這只是接受訓練最多的智能體的訓練量。
問:所學知識遷移到其它地圖效果如何?Oriol 在 discord 上提到它在其它地圖上「有效」。我們都很好奇在哪個地圖上最有效,所以現在可以揭露答案嗎?根據我的個人觀察,AlphaStar 似乎很大程度依賴于記憶中的地圖信息。它有可能在沒見過的地圖上執行很好的 wall-off 或 proxy cheese 嗎?在全新地圖上玩時,MMR 的估計差異是什么?
Oriol Vinyals:參考以上答案。
David Silver(圖中黑衣者)與 Oriol Vinyals 在線回答人們有關 AlphaStar 的問題。
問:智能體對「save money for X」這個概念了解得怎么樣?這不是一個小問題,因為如果你們從回放中學習,并考慮玩家的無作為行動(NOOP),強化學習算法通常會認為 NOOP 是在游戲中非理想點時的最佳決策。所以你們怎么處理「save money for X」,以及在學習階段是否排除了 NOOP?
David Silver:實際上,作為其行動的一部分,AlphaStar 會提前選擇執行多少 NOOP。最開始這是從監督數據中學到的,以便反映人類游戲玩法,也就是說 AlphaStar 通常以人類玩家相似的速度「點擊」。然后通過強化學習來完善,選擇減少或增加 NOOP 次數。所以,「save money for X」可以通過提前決定實施幾個 NOOP 來輕松實現。
問:你們最終使用的步長是多少?在博客中你們寫道,星際的每幀視頻被用作輸入的一步。然而,你們也提到過平均處理時長是 50 毫秒,而這會超過實際時間(給定 22.4fps,需要<46 毫秒)。所以你們是否要求每 1 步,或每 2 步、3 步是動態的?
Oriol Vinyals:我們要求每一步是動態的,但由于延遲,該操作將僅在某一步結束后處理(即我們是異步操作)。另一個選擇是鎖定該步,但這樣會造成玩家的游戲體驗不佳。
問:APM 是怎么回事?我印象中 SC2 LE 被強行限制在 180 WPM,但是我看你們的比賽中,AS 的平均 APM 似乎在很長一段時間內都遠遠超過這個水平。DeepMind 的博客上展示了相關圖表和數字,但沒有解釋為什么 APM 如此之高。
Oriol Vinyals:這個問題問得好,這也是我們打算解釋的。我們咨詢了 TLO 和暴雪關于 APM 的意見,并對其增加了一個硬性限制。具體來說,我們在 5 秒內設置 APM 最大為 600,15 秒內為 400,30 秒內為 320,60 秒內為 300。如果智能體在此期間發出了更多動作,我們會刪除/忽略那些動作。這些值取自人類玩家的統計數據。暴雪在其 APM 計算中對某些動作進行了多次計算(前面提到的數字是指 pysc2 中「智能體的動作」)。同時,我們的智能體還使用模仿學習,這意味著我們經常看到一些非常「垃圾」的動作。也就是說,并非所有動作都是有效動作。有些人已經在 Reddit 上指出了這一點——AlphaStar 的有效 APM(或 EPM)相當低。我們很高興能夠聽到社區的反饋,因為我們只咨詢了少數人。我們將考慮所有的反饋。
問:PBT 中需要多少不同的智能體來保持足夠的多樣性以防止災難性遺忘?這是如何隨著智能體數量的增加而擴展的?還是只需要幾個智能體就能保持穩健性?這與歷史 checkpoint 的有效通常策略有什么可比性嗎?
David Silver:我們保留了每個智能體的舊版本作為 AlphaStar 聯賽的競爭對手。當前的智能體通常根據對手的勝率與這些競爭者比賽。這樣能夠很好地防止災難性遺忘,因為智能體必須一直打敗所有以前的版本。我們也嘗試了一些其他的多智能體學習策略,發現這個方法非常穩健。此外,增加 AlphaStar 聯賽的多樣性非常重要。關于擴展我們很難給出精確的數字,但根據我們的經驗,豐富聯賽的策略空間有助于使終版的智能體更加強大。
問:從 TPU 和 CPU 的角度來看,總計算時間是怎樣的?
David Silver:為了訓練 AlphaStar,我們用谷歌的 TPU v3 構建了一個高度可擴展的分布式訓練系統,該系統支持很多智能體從星際 II 的數千個并行示例中學習。AlphaStar 聯賽運行了 14 天,每個智能體使用 16 個 TPU。最終的 AlphaStar 智能體由發現的最有效策略組成,然后在單個桌面 GPU 上運行。
問:看起來 AI 的反應速度不太穩定。神經網絡是在 GPU 上以 50 毫秒或者 350 毫秒運行嗎?還是說這些是指不同的東西(前向傳遞 VS 行動限制)?
David Silver:神經網絡本身大概要花 50 毫秒來計算一個動作,但這只是游戲事件發生和 AlphaStar 對該事件做出反應期間的部分處理過程。首先,AlphaStar 平均每 250 毫秒才觀察一次游戲,這是因為神經網絡除了本身的動作(有時被稱為時間抽象動作)之外,還會等待一些其他的游戲動作。觀察結果必須從星際爭霸 2 傳到 AlphaStar,然后再將 AlphaStar 的動作傳回到星際爭霸 2,這樣除了神經網絡選擇動作的時間之外,又增加了另外 50 毫秒的延遲時間,導致平均反應時間為 350 毫秒。
問:有做過泛化測試嗎?可能這些智能體無法玩其他種族(因為可用的單位/動作完全不同,甚至架構也不盡相同),但它們至少可以泛化至其它地圖吧?
Oriol Vinyals:我們的確做了這種測試。我們有 AlphaStar 的內部排行榜,我們沒有將該榜單的地圖設置為 Catalyst,而是留白了。這意味它會在所有目前的天梯地圖上運行。令人驚訝的是,智能體仍然表現很好,雖然沒到昨天看到的那種水平。
問:看起來人工智能不擅長打逆風?如果落后的話它就會不知所措,這和 OpenAI 在 Dota2 上的 AI 很相似。這是否是人工智能自我博弈所導致的問題?
David Silver:實際上有很多種不同的學習方法。我們發現單純的自我博弈經常會陷入特定的策略中,有時也會讓人工智能忘記如何擊敗此前了解的戰術。AlphaStar 聯賽也是基于讓人工智能進行自我博弈的思路,但多個智能體進行動態學習鼓勵了與多種戰術之間的對抗,并在實踐中展現了對抗不尋常戰術的更強大實力。
問:在去年 11 月 Blizzcon 訪談中,Vinyals 曾經說過會把星際爭霸 2 bot 開放到天梯上,現在還有這樣的計劃嗎?
Oriol Vinyals:非常感謝社區的支持,它會納入我們的工作中,我們已經把這十場比賽的 Replay 公開,讓大家觀看。未來如有新計劃隨時會公開。
問:它如何處理不可見的單位?人類玩家在非常靠近隱身單位時會發現它(注:在星際爭霸 2 中,隱身單位在對手的屏幕上顯示為類似水波紋的模糊輪廓)。但如果 AI 可以看到的話,那隱身幾乎沒有什么用。但如果它看不見的話,又會給大規模隱形單位策略帶來很大優勢,因為觀察者必須在場才能看到東西。
Oriol Vinyals:非常有趣的問題。一開始我們忽略了不可見單位的「水波紋」。智能體仍然可以玩,因為你可以制造檢測器,這樣單位會像往常一樣顯示出來。但我們后來又增加了一個「shimmer」功能,如果某個位置有隱形裝置,這個功能就會激活。
問:從這次經歷中,你們是否獲得了一些可以用到其他人機交互強化學習任務中的經驗?
Oriol Vinyals:當我們看到高 APM 值或點錯鍵這種問題時,我們覺得這些可能是來自模仿。其實,我們經常看到智能體的某些動作出現冗余行為(濫發移動命令、在游戲剛開始時閃爍鏡頭)。
David Silver:就像星際爭霸一樣,多數人類與 AI 交互的現實應用都有信息不完全的問題。這就意味著沒有真正意義上的最佳行為,智能體必須能夠穩健地應對人類可能采取的一系列不可預測的行為。也許從星際爭霸中學到的最有用的一點是,我們必須非常謹慎,確保學習算法能夠覆蓋所有可能出現的狀況。另外,我認為我們學到了很多關于如何將 RL 擴展到真正復雜問題中的經驗,這些問題都有很大的動作空間和長遠的視野。
問:很多人認為 AlphaStar 在最后一局中的失敗是因為該算法在最后一場比賽中受到了視力限制。我個人認為這種說法沒有說服力,因為折躍棱鏡在戰爭迷霧中進進出出,AI 相應地指揮其部隊前進撤退。這看起來絕對像是理解上的差距,而不是操作的局限。AlphaStar 以這種方式落敗,對此您有什么看法?
David Silver:很難說清我們為什么輸掉(或贏了)某場比賽,因為 AlphaStar 的決策非常復雜,是一個動態多智能體訓練進程導致的結果。MaNa 游戲打得很棒,似乎發現并利用了 AlphaStar 的弱點——但很難確定這一弱點究竟是什么造成的:視角?訓練時間不夠?還是對手和其它智能體不一樣?
問:Alphastar 的「記憶」有多大?它在玩游戲時需要接收多少數據?
Oriol Vinyals:每個智能體使用一個深度 LSTM,每個 LSTM 有 3 個層和 384 個單元。AlphaStar 在游戲中每做出一個動作,該記憶就會更新一次。平均每個游戲會有 1000 個動作。我們的網絡大約有 7000 萬個參數。
問:像 AlphaGo 和 AlphaZero 這樣的智能體是使用完美信息游戲進行訓練的。對于不完美信息游戲如星際爭霸來說,智能體的設計會有什么不同?AlphaStar 是否有之前與人類對決的「記憶」?
David Silver:有趣的是,像 AlphaGo 和 AlphaZero 這樣的基于搜索的方法更難適應不完美信息博弈。例如,基于搜索的***算法(比如 DeepStack 和 Libratus)通過信念狀態推測對手的手牌。
與之不同的是,AlphaStar 是一種無模型的強化學習算法,可以間接地推理對手狀態,即通過學習行為這一最有效擊敗對手的方法,而不是試圖給對手看到什么建模。可以認為,這是應對不完整信息的一個有效方法。
另一方面,不完美信息游戲沒有絕對最佳的游戲方式,而是取決于對手的行為。這就是星際爭霸如此讓人著迷的原因,就像「石頭剪刀布」一樣,所有決策都有優勢劣勢。這就是我們使用 AlphaStar 聯賽,以及為什么策略空間的所有角落都如此重要的原因——在圍棋這樣的游戲里這是不重要的,掌握了最優策略就可以擊敗所有對手。
問:星際爭霸 2 之后的下一個里程碑會是什么?
Oriol Vinyals:人工智能還面臨著一些重要而令人興奮的挑戰。我最感興趣的是「元學習(Meta Learning)」,它與更少的數據點和更快速的學習有關。這種思想自然可以應用在星際爭霸 2 上——它可以減少訓練智能體所需的數據量,也可以讓 AI 更好地學習和適應新的對手,而不是「凍結」AlphaStar 的權重。
問:AlphaStar 的技術可以應用到哪些其他科學領域?
Oriol Vinyals:AlphaStar 背后的技術可以應用在很多問題上。它的神經網絡架構可以用于超長序列的建模——基于不完美信息,游戲時間可以長達一個小時,而步驟有數萬個。星際爭霸的每一幀都被算作一步輸入,神經網絡會在每幀之后預測游戲剩余時間內的預期行動順序。這樣的方式在天氣預報、氣候建模、語言理解等需要對長序列數據進行復雜預測的領域非常有前景。
我們的一些訓練方法也可以用于提高人工智能系統的安全性與魯棒性,特別是在能源等安全關鍵領域,這對于解決復雜的前沿問題至關重要。
職業玩家的看法
兩位與 AlphaStar 交手的星際爭霸 2 職業玩家,TLO 與 MaNa (圖中居右)。
問:對于職業玩家來說,你們就像在指導 AlphaStar,在你們看來它在比賽中展現出了哪些優缺點?它獲得勝利的方式來自決策還是操作?
MaNa:它最強的地方顯然是單位控制。在雙方兵力數量相當的情況下,人工智能贏得了所有比賽。在僅有的幾場比賽中我們能夠看到的缺點是它對于技術的頑固態度。AlphaStar 有信心贏得戰術上的勝利,卻幾乎沒有做任何其他事情,最終在現場比賽中也沒有獲得勝利。我沒有看到太多決策的跡象,所以我說人工智能是在靠操作獲得勝利。
問:和 AlphaStar 比賽是什么樣的體驗?如果你不知道對手是誰的話,你能猜出它是機器嗎?人工智能的引入會為星際爭霸 2 帶來哪些變化?
MaNa:與 AlphaStar 比賽過程中我非常緊張,特別因為它是一臺機器。在此之前,我對它所知甚少。由于缺乏信息,我不得不以一種不熟悉的方式進行比賽。如果沒有被告知對手是誰,我會質疑它是否是人類。它的戰術和人類很像,但微操不是任何人類都能實現的。我肯定會發現它不是人類,但可能需要不止一場游戲的信息。我對 AlphaStar 的未來非常期待,我迫不及待地想要和它進行更多游戲。
星際爭霸 2 人機大戰賽事回顧
昨天是 DeepMind 星際爭霸 2 智能體 AlphaStar 首秀。DeepMind 放出了 AlphaStar 去年 12 月與星際爭霸 2 職業玩家 LiquidTLO、MaNa 的比賽視頻,AlphaStar 均以 5:0 的戰績戰勝星際爭霸 2 職業玩家。目前,AlphaStar 只能玩神族,不過它依然戰勝了神族最強十人之一的 MaNa!
昨天,DeepMind 還組織了一次 MaNa 和 AlphaStar 的現場對決。MaNa 在賽前稱,自己要來一場「復仇之戰」。事實證明,他成功了。
所有 11 場比賽的 Replay:https://deepmind.com/research/alphastar-resources/
在這場比賽中,我們可以看到 AI 的一個缺陷:除了特定的分兵戰術,并沒有靈活的兵力分配概念。這讓我們想起打星際 1 電腦的遠古時代,開局派出一個農民去攻擊電腦的基地,電腦就會派出所有農民去一直追殺你這個農民。這場 MaNa 也是利用的相似的辦法,棱鏡帶著兩不朽在 AI 的基地不停騷擾,AlphaStar 一旦回防立刻飛走,等 AI 兵力出門又立刻繼續騷擾。
開局不久后,AlphaStar 便逐漸占據優勢,正面利用追獵者襲擾 MaNa 的二礦,背面則用兩個先知不斷進犯礦區。人工智能展現的壓迫力讓場面變得非常緊張。
雖然人工智能在兵力對等的情況下每次都能占到便宜,但人類的偷襲戰術逐漸吸引了 AlphaStar 的主要兵力,幫助 MaNa 成功扛過 AI 的正面進攻。隨后,MaNa 的大軍在對手二礦位置獲得了決定性勝利。到了第 12 分鐘,人類打爆了 AI 的所有建筑,獲得了勝利。
AlphaStar 官方解讀
AlphaStar 的行為是由一種深度神經網絡生成的,該網絡從原數據界面(單位列表與它們的特性)接收輸入數據,輸出構成游戲內行為的指令序列。具體來說,該神經網絡在單元中使用了一個 transformer 作為軀干,結合了一個深度 LSTM 核、一個帶有 pointer 網絡的自動回歸策略 head 以及一個中心價值基線。
AlphaStar 也使用到了全新的多智能體學習算法。神經網絡最初通過暴雪公開的匿名人類游戲視頻以監督學習進行訓練。這讓 AlphaStar 能夠通過模仿進行學習天梯玩家的基礎微操與宏觀操作策略。
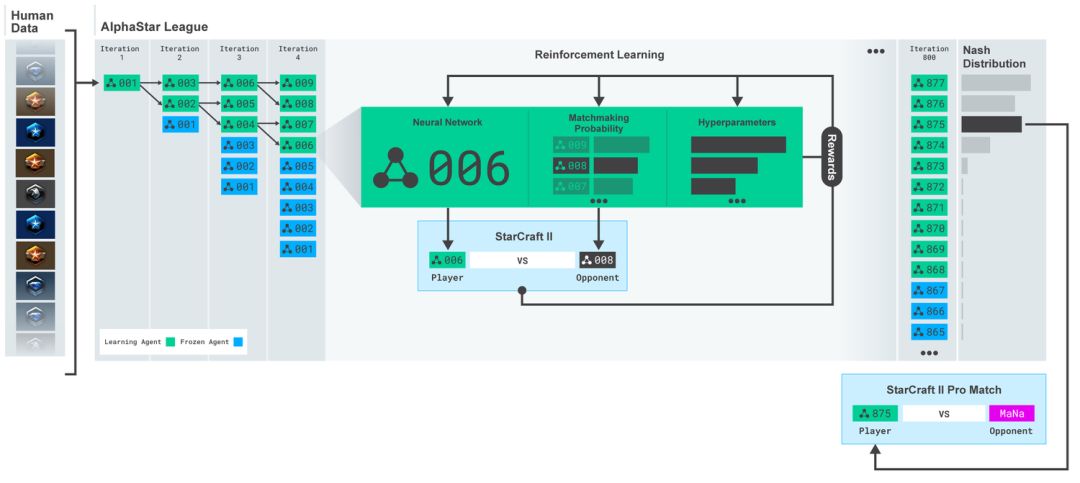
AlphaStar 聯盟。最初是通過人類玩家的游戲回放視頻進行訓練,然后與其他對手對抗訓練。每次迭代就匹配新的對手,凍結原來的對手,匹配對手的概率和超參數決定了每個智能體采用的的學習目標函數,保留多樣性的同時增加難度。智能體的參數通過強化學習進行更新。最終的智能體采樣自聯盟的納什分布(沒有更換)。

隨著自我博弈的進行,AlphaStar 逐漸開發出了越來越成熟的戰術。DeepMind 表示,這一過程和人類玩家發現戰術的過程類似:新的戰術不斷擊敗舊的戰術。
為了訓練 AlphaStar,DeepMind 使用了谷歌最先進的深度學習芯片 TPU v3 構建了一個高度可擴展的分布式訓練配置,支持數千個對戰訓練并行運算。AlphaStar 聯賽運行了 14 天,每個人工智能體使用 16 塊 TPU。在訓練時間上,每個智能體相當于訓練了人類的 200 年游戲時間。最后成型的 AlphaStar 采用了各個智能體中獲勝概率最高戰術的組合,并可以在單個 GPU 的計算機上運行。
-
神經網絡
+關注
關注
42文章
4772瀏覽量
100857 -
人工智能
+關注
關注
1792文章
47354瀏覽量
238831 -
DeepMind
+關注
關注
0文章
130瀏覽量
10878
原文標題:揭秘星際2人工智能AlphaStar:DeepMind科學家回應一切
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第二章AI for Science的技術支撐學習心得
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新

報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
FPGA在人工智能中的應用有哪些?
前OpenAI首席科學家創辦新的AI公司
本源量子參與的國家重點研發計劃青年科學家項目啟動會順利召開







 工商網監
工商網監
評論