 DeepMind在倫敦向世界展示了他們的最新成果——星際爭霸2人工智能AlphaStar
DeepMind在倫敦向世界展示了他們的最新成果——星際爭霸2人工智能AlphaStar
北京時間2019年1月25日2時,DeepMind在倫敦向世界展示了他們的最新成果——星際爭霸2人工智能AlphaStar[1] 。
圖1. DeepMind AlphaStar挑戰星際人類職業玩家直播畫面
比賽共11局,直播展示的是去年12月期間AlphaStar挑戰Liquid team職業玩家TLO和MANA的部分比賽錄像,分別有5局。最后一局為AlphaStar對戰MaNa的現場直播。比賽采用固定天梯比賽地圖、神族對抗神族的形式。
圖2. 比賽地圖、游戲版本、對戰種族信息
結果自然是AlphaStar大比分碾壓式勝利,在2018年12月10日以5:0擊敗TLO,12月19日以5:0擊敗MaNa。但是當天現場表演賽上AlphaStar卻不敵MaNa。最終,AlphaStar取得了10-1的絕佳成績,堪稱世界上第一個擊敗星際爭霸頂級職業玩家的人工智能。
星際爭霸
星際爭霸是由暴雪娛樂公司開發的一款經典即時戰略游戲。與國際象棋、Atari游戲、圍棋不同,星際爭霸具有以下幾個難點:
1、博弈——星際爭霸具有豐富的策略博弈過程,沒有單一的最佳策略。因此,智能體需要不斷的探索,并根據實際情況謹慎選擇對局策略。
2、非完全信息——戰爭迷霧和鏡頭限制使玩家不能實時掌握全場局面信息和迷霧中的對手策略。
3、長期規劃——與國際象棋和圍棋等不同,星際爭霸的因果關系并不是實時的,早期不起眼的失誤可能會在關鍵時刻暴露。
4、實時決策——星際爭霸的玩家隨著時間的推移不斷的根據實時情況進行決策動作。
5、巨大動作空間——必須實時控制不同區域下的數十個單元和建筑物,并且可以組成數百個不同的操作集合。因此由小決策形成的可能組合動作空間巨大。
6、三種不同種族——不同的種族的宏機制對智能體的泛化能力提出挑戰。
圖3. 直播中組織者分析Atari,圍棋,星際三者在信息獲取程度、玩家數量、動作空間、動作次數的不同,難度呈現逐漸提升
正因為這些困難與未知因素,星際爭霸不僅成為風靡世界的電子競技,也同時是對人工智能巨大的挑戰。
評估AlphaStar戰力
星際爭霸中包含神族、人族、蟲族三種選擇,不同種族有不同的作戰單位、生產機制和科技機制,因而各個種族間存在戰術制衡。為了降低任務訓練所需時間,并避免不同種族間客觀存在的不平衡性,AlphaStar以神族對陣神族為特定訓練場景,固定使用天梯地圖-CatalystLE為訓練和對決地圖。
面對蟲族職業玩家TLO和排名更加靠前的神族職業玩家MaNa的輪番挑戰,AlphaStar憑借近乎無解的追獵微觀操作和鳳凰技能單位的配合,能在絕大多數人類玩家都認為嚴重受到克制的兵種不朽下,在正面戰場上反敗為勝扭轉戰局,并最終兵不血刃的橫掃人類職業玩家,取得了星際爭霸AI當前最佳的表現水平,在實時戰略游戲上取得了里程碑式的意義。
圖4. 追獵者相互克制兵種關系
AlphaStar是如何訓練的?
AlphaStar的行為是由一個深度神經網絡產生。網絡的輸入來自游戲原始的接口數據,包括單位以及它們的屬性,輸出則是一組指令,這些指令構成了游戲的可行動作。網絡的具體結構包括處理單位信息的變換器(transformer),深度LSTM核(deep LSTM core),基于指針網絡(pointer network)的自動回歸策略頭(auto-regressive policy head),和一個集中式價值評估基準(centralised value baseline)。這些組成元件是目前最先進的人工智能方法之一。DeepMind將這些技術組合在一起,有信心為機器學習領域中普遍存在的一些問題,包括長期序列建模、大規模輸出空間如翻譯、語言建模、視覺表示等,提供一種通用的結構。
AlphaStar權重的訓練同樣是使用新型的多智能體學習算法。研究者首先是使用暴雪發布的人類匿名對戰數據,對網絡權重進行監督訓練,通過模仿來學習星際天梯上人類玩家的微觀、宏觀策略。這種模擬人類玩家的方式讓初始的智能體能夠以95%的勝率打敗星際內置電腦AI精英模式(相當于人類玩家黃金級別水平)。
在這初始化之后,DeepMind使用了一種全新的思路進一步提升智能體的水平。星際本身是一種不完全信息的博弈問題,策略空間非常巨大,幾乎不可能像圍棋那樣通過樹搜索的方式確定一種或幾種勝率最大的下棋方式。一種星際策略總是會被別一種策略克制,關鍵是如何找到最接近納什均衡的智能體。為此,DeepMind設計了一種智能體聯盟(league)的概念,將初始化后每一代訓練的智能體都放到這個聯盟中。新一代的智能體需要要和整個聯盟中的其它智能體相互對抗,通過強化學習訓練新智能體的網絡權重。這樣智能體在訓練過程中會持續不斷地探索策略空間中各種可能的作戰策略,同時也不會將過去已經學到的策略遺忘掉。
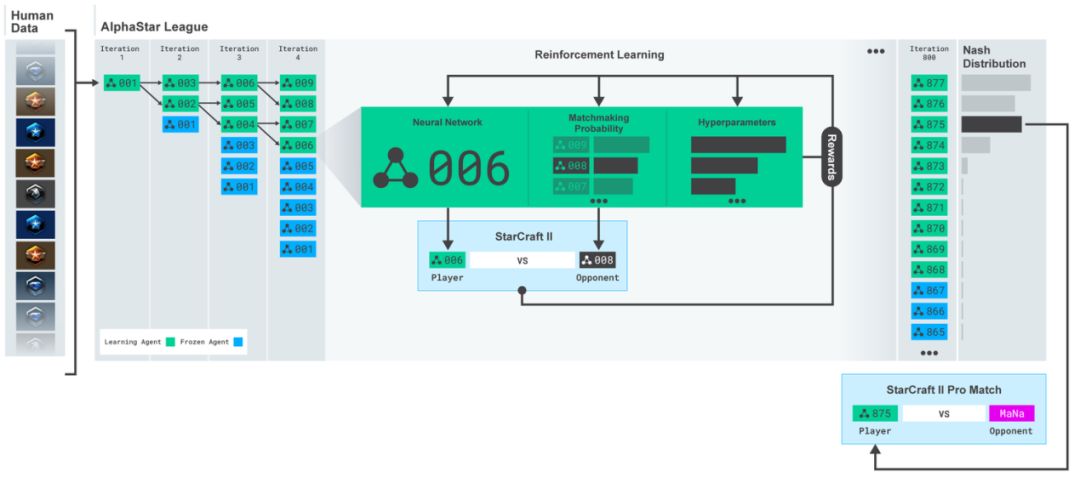
圖5.在使用人類數據初始化智能體后,DeepMind構建了一個智能體聯盟,在每一代都將強化學習得到的智能體放入這個聯盟中,每個智能體要和聯盟中其它的智能體做對抗學習。最終從聯盟中水平靠前的幾個智能體中選取一個和MaNa對抗。
這種思路最早出現在DeepMind另一項工作——種群強化學習(population-based reinforcement learning)。這與AlphaGo明顯的不同在于:AlphaGo讓當前智能體與歷史智能體對抗,然后只對當前智能體的權重做強化學習訓練;而種群強化學習則是讓整個種群內的智能體相互對抗,根據結果每個智能體都要進行學習,從而不只是最強的智能體得到了提升,它的所有可能的對手都有所提升,整個種群都變得更加智能。
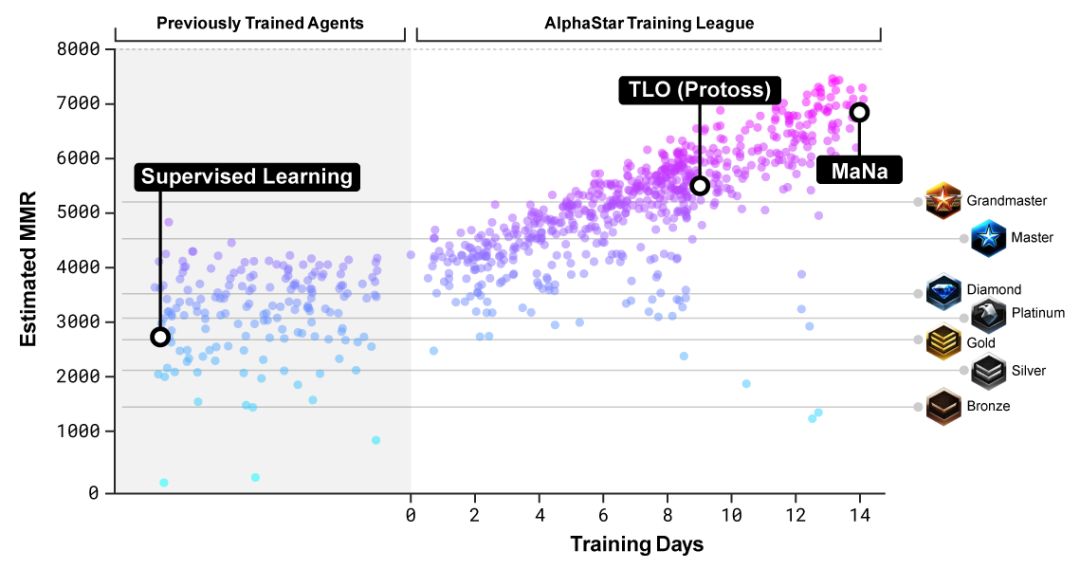
圖6.隨著聯盟中對智能體的訓練,整個聯盟的最強水平和整體水平都得到了提升,最終超過了人類玩家MaNa和TLO(神族)在MMR下的評分。圖中縱坐標給出的是Match Making Rate (MMR),是一種對玩家水平的有效評估,圖中橫線對應暴雪對線上玩家水平的分級。
此外DeepMind還宣稱,每個智能體不只是簡單地和聯盟其它智能體相互對抗學習,而是有針對性、有目的性的學習。例如通過內在激勵的調整,有些智能體只考慮打敗某種類型的競爭對手,而另一些智能體則是要盡可能地擊敗種群的大部分智能體。這就需要在整體訓練過程中不斷地調整每個智能體的目標。
權重的訓練使用了新型的強化學習——離策略執行-評價(off-policy actor-critic)算法,結合了經驗回放(experience replay)、自我模仿學習(self-imitation learning)、和策略蒸餾(policy distillation)。這些技術保證了訓練的穩定性和有效性。

圖7.黑點代表了和MaNa對戰所選擇的智能體。大圖給出了該智能體在訓練過程中策略的變化情況。其它彩色點代表了不同策略對應的智能體,并顯示出了不同時期不同策略被選中和MaNa智能體對抗的概率。尺寸越大,被選中概率越大。左下圖給出了不同訓練時期MaNa智能體出兵組成變化。
硬件部分
為了訓練AlphaStar,DeepMind調動了Google的v3云TPU。構建了高度可拓展的分布式訓練方式,支持數千個智能體群并行訓練。整個AlphaStar智能體聯盟訓練了14天,每個智能體調用了16個TPU。在訓練期間,每個智能體經歷了相當于正常人類要玩200年的游戲時長。最終的AlphaStar智能體集成了聯盟當中最有效策略的組合,并且可以在單塊桌面級GPU上運行。
AlphaStar是如何玩游戲的?
在比賽時AlphaStar通過其界面直接與星際爭霸游戲引擎交互,獲得地圖上可以觀察的所有信息,也可稱為全局信息。它并沒有輸入移動視角的視野圖像。不過對比賽錄像的分析表明AlphaStar隱式地學到了注意力集中機制。平均而言,AlphaStar的動作指令每分鐘會在前線和運營之間切換30次,這與MANA和TLO等人類玩家的切屏行為非常相近。
圖8. 與MaNa第二場比賽中AlphaStar的神經網絡可視化。從智能體的角度顯示了它對游戲的理解,左下角起為游戲的輸入,神經網絡的激活可視化,智能體的主要操作位置,局勢評估,生產建造。
在12月份的比賽之后,DeepMind開發了第二版的AlphaStar。加入了移動視角機制,使其只能感知當前屏幕上的視野信息,并且動作位置僅限于當前區域。結果表明AlphaStar同樣能在移動視角輸入下迅速提升性能,緊緊追趕全局輸入的性能,最終結果幾乎一致。
DeepMind一共訓練了兩種智能體,一個使用原始全局輸入,一個使用移動視角輸入。它們都首先使用人類數據監督學習初始化,然后使用上述強化學習過程和第一版學好的智能體聯盟對抗。使用使用視角輸入的智能體幾乎與全局輸入的一樣強大。在DeepMind的內部排行榜上超過7000MMR(遠高于MaNa的MMR)。然而在直播比賽當中,MaNa戰勝了移動視角的智能體。DeepMind分析認為該智能體只訓練了七天的時間,還沒有達到它的最高水平,希望在不久的將來會對收斂結果做進一步評測。

圖9. 以整個地圖信息為輸入和以移動視角為輸入兩種智能體訓練的提升效果比較。兩者都是不完全信息,存在戰爭迷霧遮擋敵方單位的情況。只不過前者是將所有可視單位的信息放在全局地圖上作為輸入,后者是只將玩家局部視野內的單位信息作為輸入。因此后者需要智能體在游戲過程中不斷調整局部視野的范圍,確保有用信息的輸入。
眾多觀戰者另一個關心的問題是AlphaStar的平均每分鐘操作數(Actions Per Minute, APM)。計算機可以利用強大的計算能力,在短時間集中大量的操作,遠超過人類的極限能力。就算是頂級職業玩家,APM也僅有數百,遠遠低于現有的對戰機器人。如自動悍馬2000,可以獨立控制每個單元,APM維持在數萬以上。
在TLO和MANA的比賽當中,AlphaStar的平均APM為280,盡管其操作更為精確,但APM明顯低于大部分職業玩家。同時,AlphaStar從觀察到行動之間存在350毫秒的延遲。
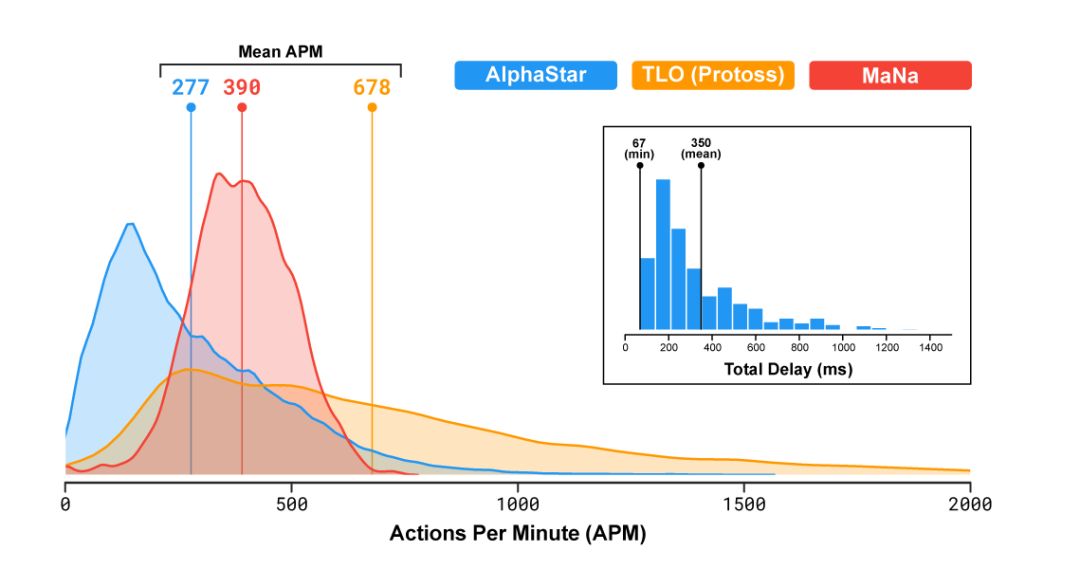
圖10. 對戰時AlphaStar,TLO(神族),MaNa三者的APM比較
綜上,DeepMind認為AlphaStar對MaNa和TLO的勝利依靠的是卓越的宏觀機制和微觀戰略決策,而不是單純的靠閃爍追獵Blink。
AlphaStar優缺點分析
AlphaStar優勢
1)戰勝職業玩家
AlphaStar的成功在星際爭霸游戲乃至整個實時戰略游戲具有里程碑式的意義,不僅在于第一次正式擊敗人類職業玩家,更在于這套深度強化學習框架在不完全依賴于規則腳本的基礎上,通過監督學習、模仿訓練、種群提升、和后期強化學習來提升智能體的作戰能力。這套研究思路和方法一樣適用于其他的實時戰略游戲。
2)微觀操作卓越
即使在兵種對抗處于劣勢的情況下,AlphaStar依靠精準的微操決策控制能力,仍然可以在形勢不利的局面下反敗為勝,化逆境為順境。表現了實時戰略游戲的一種雖然簡單粗暴但較為直接的解決方式,證明了深度強化學習探索到較優可行解的能力。
3)利用地形優勢的感知能力
在戰爭局勢不利的情況下,準確作出戰略撤退,并分散撤退到具有較高地勢的關口四周。利用峽口因素精確作出包夾的動作行為,形成對敵方的封鎖及包抄,從而為局勢逆轉提供條件,具備較強的地形感知能力和利用性。
AlphaStar不足
1)硬件資源需求高
單個智能體訓練需要16個V3版本(最新版,運算次數為V2版本的8倍)的云TPU,以AlphaLeague訓練完成的10類智能體作為保守估計,至少需要上百塊TPU作為硬件計算支持,帶來的硬件基礎成本使普通開發者難以承受。
2)魯棒性仍不足
在最后一場直播中可見,由于AlphaStar無法根據敵人騷擾意圖分散安排兵力部署防守本方基地,致使被人類玩家戲耍來回拉扯全軍大部隊,從而始終無法對人類玩家發起進攻,使人類玩家有足夠時間生產大量的反追獵兵種(不朽),最終導致比賽的失利。
3)地圖場景較為簡單
本次使用CatalstLE為兩人小地圖,沒有多余的隨機起始點,因而AlphaStar不需要派偵察部隊偵察敵人確定位置,減小了環境的不確定性,簡化了整體的不完全信息性。并且小地圖使智能體偏向于使用RUSH類戰術,使探索策略的復雜性顯著降低。
4)微操APM峰值過高
不同于普通人類玩家,AlphaStar的APM不具有冗余重復性,每次都為有效操作(EPM)。普通人類玩家的EPM平均大約只有80左右,只有在交戰過程中短暫的20秒到30秒左右的時間達到EPM 200以上。但AlphaStar在使用近乎無解的閃爍追獵戰術EPM估計能達到1000左右,顯然對于人類玩家并不公平。
5)后期表現未知
根據此次比賽公開的錄像表現,AlphaStar大部分時刻采取追獵者攻擊、騷擾或防御等動作,尚未觀察到其他更為高級的兵種操作,并且沒有出現滿人口滿科技樹的情況,因而AlphaStar的后期表現能力存在較大疑問。
總評:從開放的11組視頻對戰資源分析,AlphaStar可以在局勢不利的情況下,憑借卓越的微操控制能力、地形利用能力和多兵種整體協同配合能力,有效逆轉戰局,實現扭虧為盈。但是在最后一場現場直播中,AlphaStar出現了明顯的作戰缺陷,始終無法合理分配兵力保護基地,被人類玩家來回拉扯戰場,錯過了進攻的最佳時機,導致最終失利。縱觀本次人機對抗,雖然在限制Bot的APM部分做的不太到位,只限制其APM的均值而沒對峰值限制,但與2017年在韓國世宗大學舉辦的星際人機對抗(同樣沒對電腦APM作限制)以Bot的慘敗相比較,本次的AlphaStar是真正意義上在全尺度地圖上擊敗了星際爭霸人類職業玩家,可謂進步顯著。
星際爭霸AI的研究進展簡介
星際爭霸是由暴雪娛樂公司于1998年公開發售,為實時戰略游戲的典型代表,深受廣大游戲玩家的歡迎并創造一列歷史先河。與此同時,隨著BWAPI,TorchCraft,SC2LE等開源API(Application Interface)的發布,眾多研究者和工程師們紛紛對星際爭霸展開了深入研究。
圖11. 2017年星際人機對抗(腳本Bot)與2019年星際人機對抗(AIBot)
早期的搜索型算法(如α-β搜索,MCTS樹搜索)已經被廣泛用于完成星際中動作攻擊選擇任務和建筑生產序列規劃任務。并隨著計算資源及性能的不斷提升,演化計算、深度神經網絡、深度強化學習(AlphaStar的主要采用方法)等方法正發揮著越來越顯著的作用。圖11表示了近些年人工智能算法在星際爭霸的子任務中的具體應用。其中以強化學習為代表的計算智能算法在星際爭霸領域取得了一系列顯著的突破性進展。在特定場景的星際微操任務下,多智能體強化學習方法如阿里的Peng等提出的基于雙向RNN的BicNet[3] ,牛津大學Foerster等提出的基于反事實機制的COMA[4] , 自動化所Shao等提出的基于SARSA(λ)和權重共享的PS-MAGDS[5] 等方法表現突出,能有效處理多智能體間信譽分配的問題。而在宏觀序列生產預測任務,自動化所Tang等基于卷積神經網絡的前向Q學習方法[6] 能幫助智能體找到最佳的生產序列,提升智能體的環境適應性,從而擊敗內置AI。分層強化學習方法可以在需要長期規劃的任務問題上解決獎賞反饋稀疏的問題,以騰訊的TStarBot[7] 為代表的層級強化學習證明了該方法能在標準天梯地圖中完整地完成AI的整套系統性學習任務。
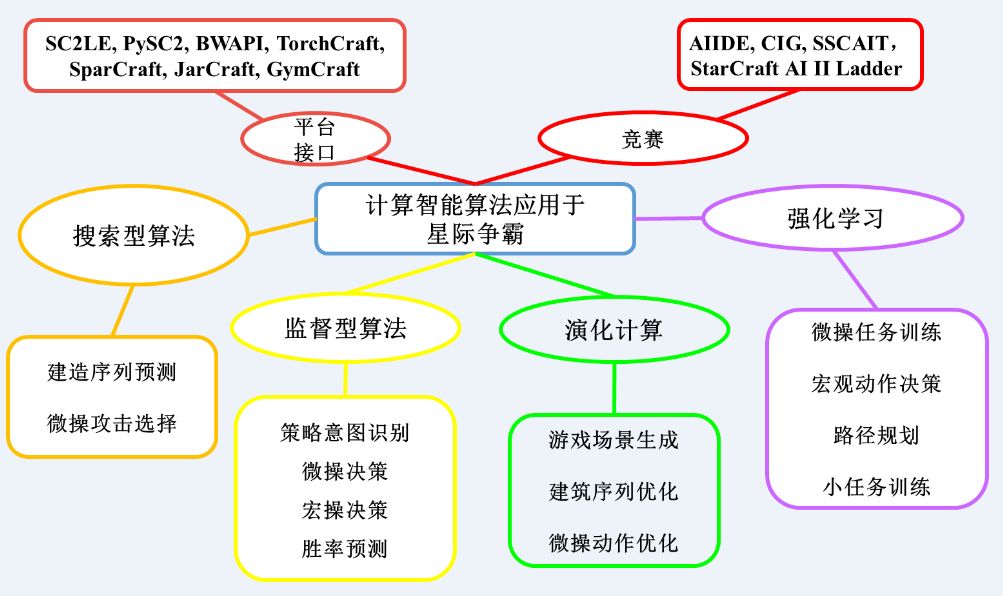
圖12. 計算智能算法在星際爭霸中的應用環境[2]
AlphaStar同樣采用深度強化學習作為其核心訓練方法,并與他的“哥哥”AlphaGo具有相似之處,都采用人類對戰數據作預訓練模仿學習。但為了滿足實時性要求,AlphaStar舍棄了搜索模塊,只讓神經網絡輸出發揮作用,是一種更為純粹的“深度強化學習”方法。
結束語
從AlphaStar的表現來看,人工智能半只腳已經踏上了實時對戰游戲的頂峰。然而另外半只腳能否踏上去還要看能否解決現存的后期乏力、魯棒性差的問題。近年來隨著國際象棋、Atari游戲、圍棋、德州撲克等一一被征服,人工智能在不斷挑戰人類智力領域的統治力。反之人類研究者也在不斷推動和挖掘人工智能的極限。人工智能是否有極限?下一個將會被征服的領域會是什么?讓我們拭目以待。
-
人工智能
+關注
關注
1792文章
47354瀏覽量
238811 -
智能體
+關注
關注
1文章
152瀏覽量
10590 -
DeepMind
+關注
關注
0文章
130瀏覽量
10878
原文標題:Deepmind AlphaStar 如何戰勝人類職業玩家【中科院自動化所深度解析】
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
嵌入式和人工智能究竟是什么關系?
《AI for Science:人工智能驅動科學創新》第6章人AI與能源科學讀后感
AI for Science:人工智能驅動科學創新》第4章-AI與生命科學讀后感
《AI for Science:人工智能驅動科學創新》第一章人工智能驅動的科學創新學習心得
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅動科學創新

報名開啟!深圳(國際)通用人工智能大會將啟幕,國內外大咖齊聚話AI
FPGA在人工智能中的應用有哪些?
劉潤:逛了2個小時世界人工智能大會






 工商網監
工商網監
評論