 用來創建神經網絡的兩種樣式之間的利弊權衡
用來創建神經網絡的兩種樣式之間的利弊權衡
關于 TensorFlow 2.0, 我最喜歡的一點是它提供了多個抽象級別,因此您可以為您的項目選擇合適的抽象級別。在本文中,我將為您解釋用來創建神經網絡的兩種樣式之間的利弊權衡。第一種是符號樣式,通過操作層形成的圖 (graph of layers) 來構建模型。第二種是命令式樣式,通過擴展類來構建模型。我將介紹這些樣式并討論重要的設計和可用性權衡。我將詳細介紹技術細節,并提供快速建議以幫助您為目標選擇合適的方法。
符號式(或聲明的)API
通常我們會用 “層形成的圖” 來想象神經網絡,如下圖所示。
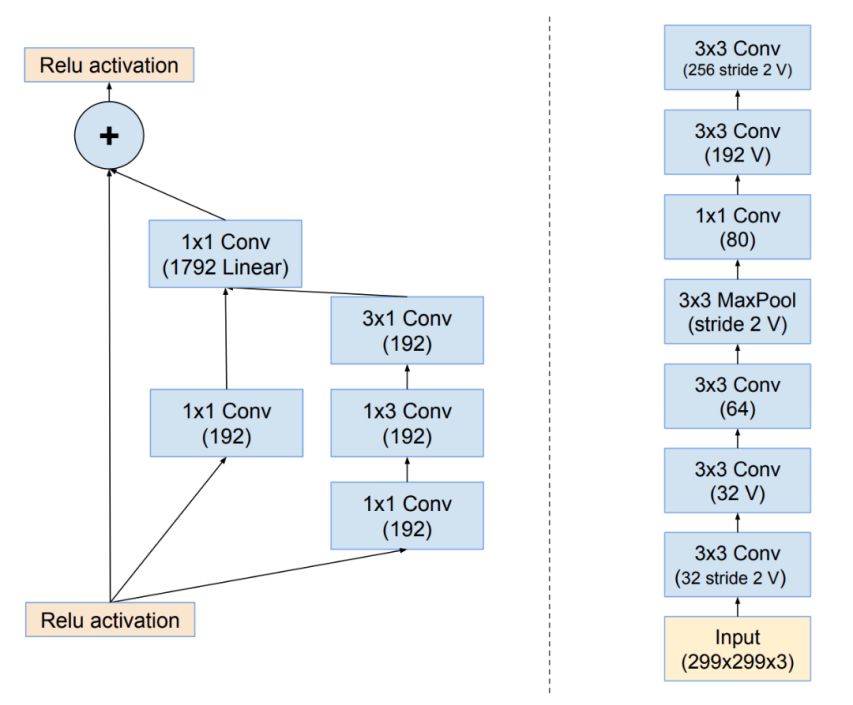
通常我們會用 “層形成的圖” 來想象神經網絡( 這些圖片是用于初始化 Inception-ResNet 的模式 )
這種圖可以是左側顯示的 DAG ( 有向無環圖 ),也可以是右側顯示的堆棧。當我們符號化地構建模型時,我們通過描述該圖的結構來實現。
這聽起來很技術性,那么如果你使用了 Keras,你可能會驚訝地發現你已經有過這樣的經驗了。以下是使用 Keras Sequential API 以符號樣式構建模型的快速示例。
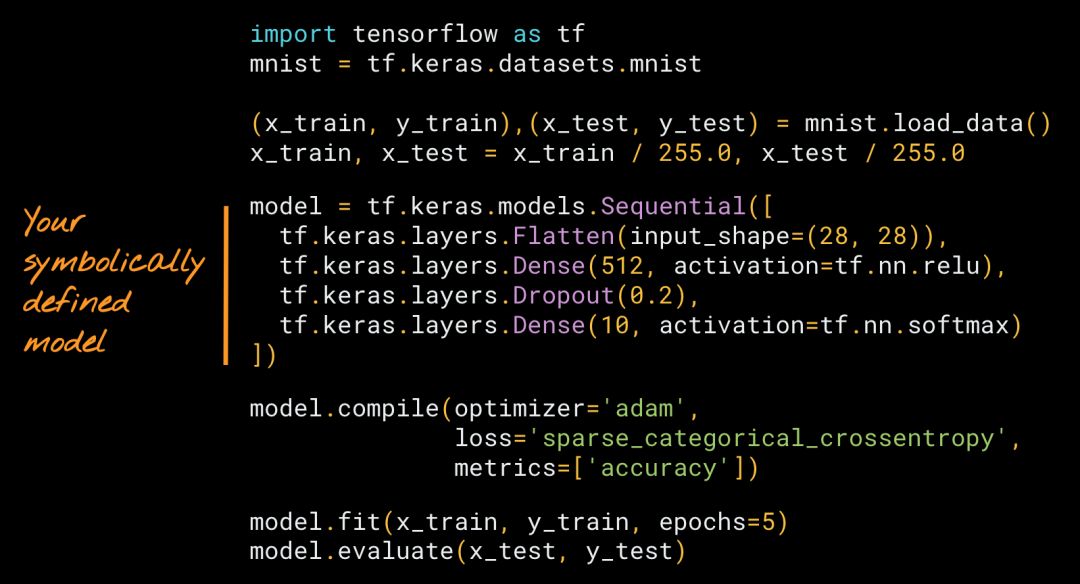
使用 Keras Sequential API 符號化構建的神經網絡。你可以在https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/_index.ipynb運行這個例子
在上面的示例中,我們已經定義了一堆圖層,然后使用內置的訓練循環 model.fit 來訓練它。
使用 Keras 構建模型就像 “把樂高積木拼在一起” 一樣簡單。為什么這樣說呢?我們后面將介紹其中的技術原因,以這種方式定義網絡,除了符合我們的想象之外,更易于調試,它可以通過盡早捕獲詳細的錯誤信息從而進行調試,以便及早的發現錯誤。
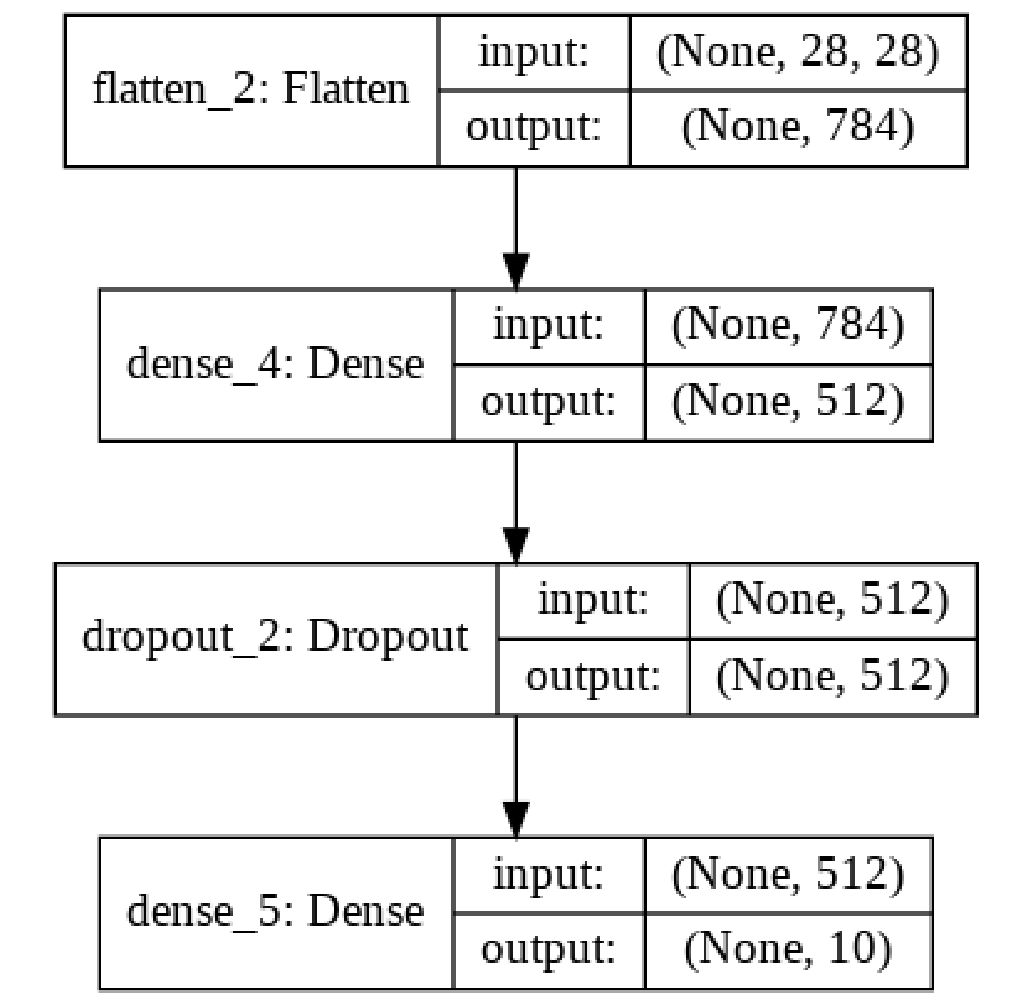
圖中顯示了上面代碼創建的模型(使用 plot_model 構建,您可以在本文的下一個示例中重用代碼片段)
TensorFlow 2.0 提供了另一種符號模型構建 API:Keras Functional。Sequential 用于堆棧,而 Functional 用于 DAG ( 有向無環圖 )。
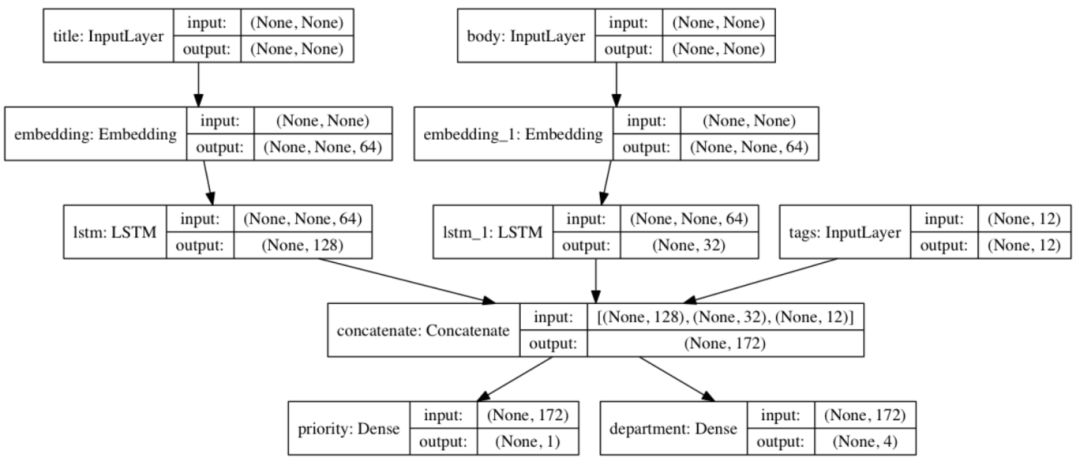
使用 Functional API 創建多輸入 / 多輸出模型的快速示例
Functional API 是一種創建更靈活模型的方法。它可以處理非線性拓撲 (non-linear topology),具有共享層的模型以及具有多個輸入或輸出的模型。基本上,Functional API 是一組用于構建這些層形成的圖的工具。現在我們為您準備了幾種新的教程。
您可能會遇到其他符號式 API。例如,TensorFlow v1(和 Theano)提供了更低級別的 API。您可以通過創建一個由 ops(操作)組成的圖來構建模型,然后對其進行編譯和執行。有時,使用此 API 會讓你感覺就像直接與編譯器進行交互一樣。對于許多人(包括作者)而言,這是很不簡單的。
相比之下,在 Keras 中,抽象的水平是與我們想象的方式相匹配的:由層構成的圖,像樂高積木一樣疊在一起。這感覺很自然,這是我們在 TensorFlow 2.0 中標準化的模型構建方法之一。還有一個方法我將要為你描述(你很有可能也用過這個,也許很快你就有機會試一試)。
命令式(或模型子類)API
在命令式風格中,您可以像編寫 NumPy 一樣編寫模型。以這種方式構建模型就像面向對象的 Python 開發一樣。下面是一個子類化模型的簡單示例:
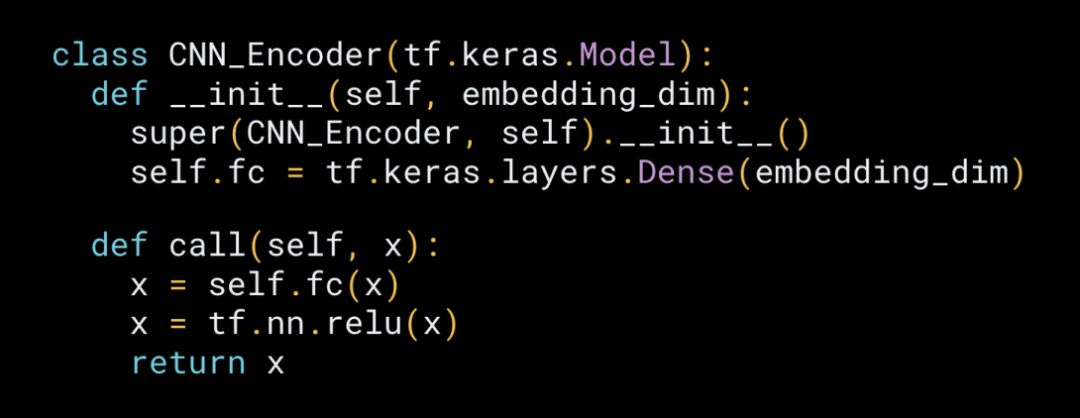
使用命令式樣式來構建一個帶有注意圖像字幕的模型(注意:此示例目前正在更新)(https://github.com/tensorflow/docs/blob/master/site/en/r2/tutorials/generative/image_captioning.ipynb)
從開發人員的角度來看,它的工作方式是擴展框架定義的 Model 類,實例化圖層,然后命令性地編寫模型的正向傳遞(反向傳遞會自動生成)。
TensorFlow 2.0 支持 Keras Subclassing API 開箱即用。與 Sequential 和 Functional API 一起,它也是在 TensorFlow 2.0 中開發模型的推薦方法之一。
雖然這種風格對于 TensorFlow 來說是全新的,但是您可能會驚訝地發現它是由 Chainer 在 2015 年推出的(時間過得真快!)。從那時起,許多框架采用了類似的方法,包括 Gluon,PyTorch 和 TensorFlow(使用 Keras Subclassing)。令人驚訝的是,在不同框架中以這種風格編寫的代碼可能會看起來如此相似,甚至很難區分!
這種風格為您提供了極大的靈活性,但它的可用性和維護成本并不明顯。關于這一點,我們稍后會詳細介紹。
訓練循環
以 Sequential,Functional 或 Subclassing 樣式定義的模型可以通過兩種方式進行訓練。您可以使用內置的訓練例程和損失函數(請參閱第一個示例,我們使用 model.fit 和 model.compile),或者如果您需要增加自定義訓練循環的復雜性(例如,如果您喜歡編寫自己的梯度裁剪代碼)或損失函數,您可以輕松完成如下操作:
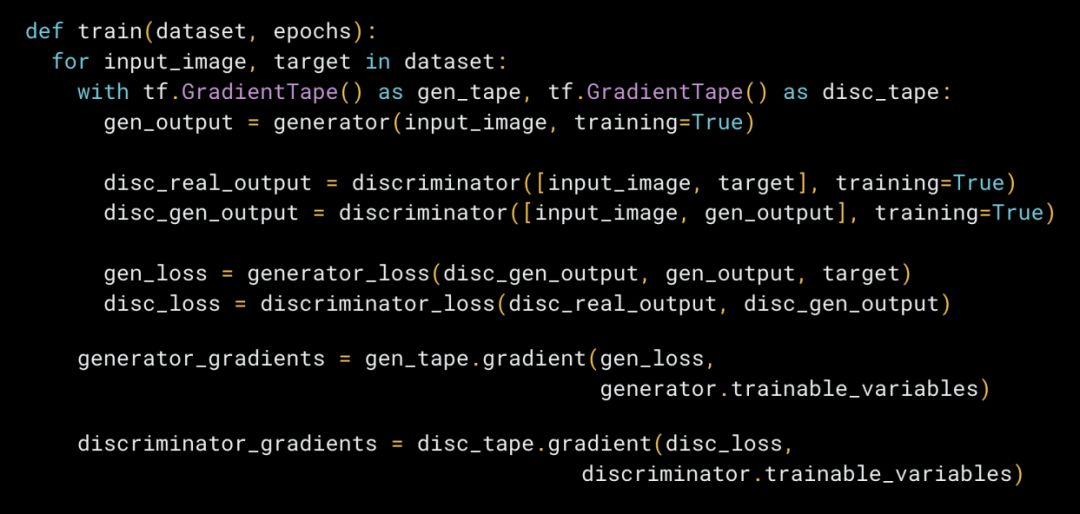
Pix2Pix 的自定義訓練循環和損失功能的示例
這兩種方法都很重要,并且可以方便地降低代碼復雜性和維護成本。基本上,您可以在有需要的時候使用額外的復雜性,當不必要的時候,使用內置的方法把時間花在您的研究或項目上。
既然我們已經對符號樣式和命令樣式有了一定的了解,那就讓我們來看看折中方案。
符號式 API 的優點和局限性
優點
使用符號化 API,您的模型是一個類似圖的數據結構。這意味著可以對您的模型進行檢查或匯總。
您可以將其繪制為圖像以顯示圖(使用 keras.utils.plot_model),或者直接使用 model.summary(),或者參見圖層,權重和形狀的描述來顯示圖形
同樣,在將圖層連接在一起時,庫設計人員可以運行廣泛的圖層兼容性檢查(在構建模型時和執行之前)。
這類似于編譯器中的類型檢查,可以大大減少開發人員錯誤
大多數調試將在模型定義階段進行,而不是在執行期間進行。這樣您可以保證任何編譯的模型都會運行。可以加快迭代速度,并使調試更容易
符號模型提供了一致的 API。 這使得它們易于重用和共享。例如,在遷移學習中,您可以訪問中間層激活來從現有的模型中構建新模型,如下所示:
```
from tensorflow.keras.applications.vgg19 import VGG19
base = VGG19(weights='imagenet')
model = Model(inputs=base.input, outputs=base_model.get_layer('block4_pool').output)
image = load('elephant.png')
block4_pool_features = model.predict(image)
```
符號模型由一種數據結構定義的,這種數據結構使得它們可以自然地復制或克隆。
例如,Sequential 和 Functional API 為您提供 model.get_config(),model.to_json(),model.save(),clone_model(model),能夠在數據結構中重新創建相同的模型 ( 無需使用原始代碼來定義和訓練模型 )
雖然一個設計良好的 API 應該與我們想象中的神經網絡相匹配,但同樣重要的是符合我們作為程序員的想象方式。對于我們許多人來說,這是一種命令式的編程風格。在符號化 API 中,您正在操作 “符號張量”(這些是尚未保留任何值的張量)來構建圖。Keras Sequential 和 Functional API “感覺” 勢在必行。它們的設計使許多開發人員沒有意識到他們已經象征性地定義了模型。
局限性
當前的符號 API 最適合開發層的有向無環圖模型。這在實踐中占了大多數用例,盡管有一些特殊的用例不適合這種簡潔的抽象,例如,動態網絡(如樹狀神經網絡)和遞歸網絡。
這就是為什么 TensorFlow 還提供了一種命令式的模型構建 API 風格(Keras Subclassing,如上所示)。 您可以使用 Sequential 和 Functional API 中所有熟悉的層,初始化器和優化器。這兩種樣式也是完全可互操作的,因此您可以混合搭配(例如,您可以將一種模型類型嵌套在另一種模型類型中)。您可以將符號模型用作子類模型中的一個層,或者相反。
命令式 API 的優點和局限性
優點
您的正向傳遞是命令式編寫的,你可以很容易地將庫實現的部分(例如,圖層,激活或損失函數)與您自己的實現交換掉。這對于編程來說是很自然的,并且是深入了解深度學習的一個好方法。
這使得快速嘗試新想法變得容易(DL 開發工作流程變得與面向對象的 Python 相同),對研究人員尤其有用
使用 Python 在模型的正向傳遞中指定任意控制流也很容易
命令式 API 為您提供了最大的靈活性,但是這是有代價的。我也喜歡用這種風格編寫代碼,但是我想花點時間強調一下這種風格的局限性(了解其中的利弊是很好的)。
局限性
重要的是,在使用命令式 API 時,您的模型由類方法的主體定義的。您的模型不再是透明的數據結構,它是一段不透明的字節碼。在使用這種風格時,您需要犧牲可用性和可重用性來獲得靈活性。
在執行期間進行調試,而不是在定義模型時進行調試。
輸入或層間兼容性幾乎沒有被檢查到,因此在使用此樣式時,很多調試負擔從框架轉移到開發人員
命令式模型可能更難以重用。例如,您無法使用一致的 API 訪問中間圖層或激活。
相反,提取激活的方法是使用新的調用(或 forward)方法編寫新類。一開始寫起來可能很有趣,做起來也很簡單,但這可能會導致沒有標準的 tech debt
命令模型也更難以檢查,復制或克隆。
例如,model.save(),model.get_config()和 clone_model 不適合用于子類模型。同樣,model.summary()只提供一個圖層列表(并不提供有關它們如何連接的信息,因為它不可訪問)
ML 系統中的 Technical Debt
重要的是要記住,模型構建只是在實踐中使用機器學習的一小部分。這是我最喜歡的一部分。模型本身(代碼中指定層、訓練循環等部分)是中間的小盒子。
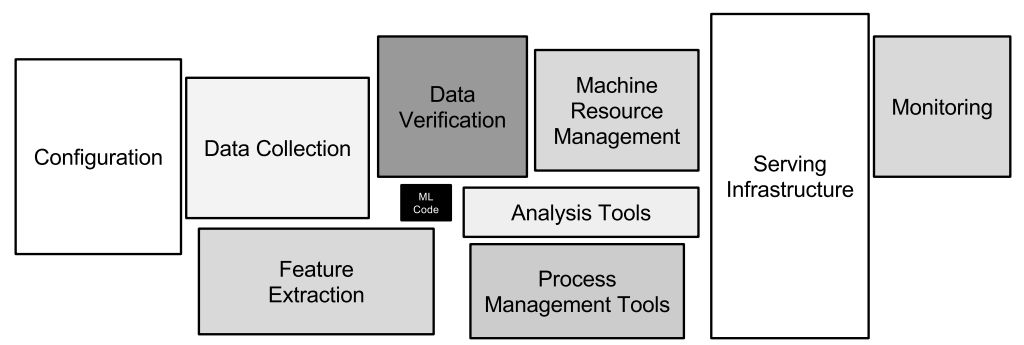
如圖所示,只有一小部分真實 ML 系統由 ML 代碼組成
由中間的小黑匣子進行。避免機器學習系統中隱藏的 Technical Debt
符號定義的模型在可重用性,調試和測試方面具有優勢。例如,在教學時 — 如果他們使用的是 Sequential API,我可以立即調試學生的代碼。當他們使用子類模型(不管框架是什么)時,它需要更長的時間(bug 可能更微妙,并且有許多類型)。
結論
TensorFlow 2.0 支持這兩種開箱即用的樣式,因此您可以為您的項目選擇合適的抽象級別(和復雜性)。
如果您的目標是易用性,低概念開銷 (low conceptual overhead),并且您希望將模型視為層構成的圖:使用 Keras Sequential 或 Functional API(如將樂高積木拼在一起)和內置的訓練循環。這是解決大多數問題的正確方法
如果您希望將模型視為面向對象的 Python / Numpy 開發人員,并且優先考慮靈活性和可編程性而不是易用性(以及易于重用),Keras Subclassing 是適合您的 API
-
神經網絡
+關注
關注
42文章
4777瀏覽量
100997 -
代碼
+關注
關注
30文章
4815瀏覽量
68858 -
tensorflow
+關注
關注
13文章
329瀏覽量
60578
原文標題:劃重點! TensorFlow 2.0 中的符號和命令式 API
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論