 我們如何實現通用語言智能
我們如何實現通用語言智能
DeepMind新年力作《學習和評估通用語言智能》,從全新的角度對跨任務NLP模型進行了評估,探討了要實現“通用語言智能”現如今的研究還缺失什么,以及如何實現通用語言智能。
2014年11月,那時候還沒有被廣泛認知為“深度學習教父”的Geoffrey Hinton,在國外網站Reddit回答網友提問的活動“AMA” (Ask Me Anything) 中表示,他認為未來5年最令人激動的領域,將是機器真正理解文字和視頻。
Hinton說:“5年內,如果計算機沒能做到在觀看YouTube視頻后能夠講述發生了什么,我會感到很失望。”
幸好,現在計算機已經能夠在觀看一段視頻后簡述其內容,但距離Hinton所說的“真正理解文字和視頻”,還有很遠的距離。
無獨有偶,統計機器學習大神Michael I. Jordan在2014年9月Reddit AMA中也提到,如果他有10億美金能夠組建研究項目,他會選擇構建一個NASA規模的自然語言處理 (NLP) 計劃,包括語義學、語用學等分支。
Jordan說:“從學術上講,我認為NLP是個引人入勝的問題,既讓人專注于高度結構化的推理,也觸及了‘什么是思維 (mind)’ 這一核心,還非常實用,能讓世界變得更加美好。”
一直以來,NLP/NLU (自然語言理解) 都被視為人工智能桂冠上的明珠,不僅因其意義重大,也表示著目標距我們遙不可及。
總之,NLP是個大難題。
前段時間在業內廣泛流傳的一篇“人工智障”的文章,本質上講的就是目前NLP領域的困境。縱使有谷歌BERT模型所帶來的各項指標飛躍,但要讓計算機真正“理解”人類的語言,需要的恐怕不止是時間。
在最近一篇發布在Arxiv上的論文中,DeepMind的研究人員對“通用語言智能” (General Linguistic Intelligence) 做了定義,并探討了機器如何學習并實現通用語言智能。

DeepMind新年力作《學習和評估通用語言智能》
實現通用語言智能,首先需要統一的評估標準
DeepMind的研究人員從語言的角度出發,根據近來不斷發展的“通用人工智能”(AGI)的配套能力,也即能夠讓智能體與虛擬環境實現交互而發展出通用的探索、規劃和推理能力,將“通用語言智能”定義為:
能夠徹底應對各種自然語言任務的復雜性;
有效存儲和重用各種表示 (representations)、組合模塊 (combinatorial modules, 如將單詞組成短語、句子和文檔的表示),以及先前獲得的語言知識,從而避免災難性遺忘;
在從未經歷過的新環境中適應新的語言任務,即對領域轉換的魯棒性。
作者還指出,如今在NLP領域存在一種非常明顯且不好的趨勢,那就是越來越多的數據集通過眾包完成,量的確是大了,特別是在體現人類語言的“概括” (generalization) 和“抽象” (abstraction) 能力方面大打折扣,并不貼近現實中的自然分布。
此外,對于某一特定任務(比如問答),存在多個不同的數據集。因此,單獨看在某個數據集上取得的結果,很容易讓我們高估所取得的進步。
所以,要實現通用語言智能,或者說朝著這個方向發展,首先需要確定一個統一的評估標準。在本文中,為了量化現有模型適應新任務的速度,DeepMind的研究人員提出了一個基于在線前序編碼 (online prequential coding) 的新評估指標。
接下來,就讓我們看看現有的各個state-of-the-art模型性能如何。
對現有最先進模型的“五大靈魂拷問”
作者選用了兩個預訓練模型,一個基于BERT,一個基于ELMo。其中,BERT(base)擁有12個Transformer層,12個自注意力指針和768個隱藏層,這個預訓練模型中有1.1億個參數。另一個則基于ELMo(base),這個預訓練模型有將近1億個參數,300個雙向LSTM層,100個輸出層。
另有BERT/ELMo(scratch),表示沒有經過預訓練,從頭開始的模型。
首先,作者考察了需要多少與領域知識相關的訓練樣本,兩個模型才能在SQuAD閱讀理解和MNLI自然語言推理這兩個任務上取得好的表現。
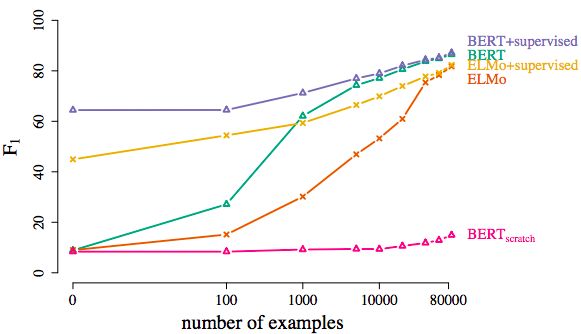
縱軸F1代表在SQuAD閱讀理解數據集上的得分函數,橫軸代表訓練樣本量的對數值
答案是4萬。而且,與領域知識相關的訓練樣本量超過4萬以后,兩個模型的提升都不明顯,非要說的話,BERT模型在兩項任務中比ELMo稍好一點。
那么,改用在其他數據集上預訓練過的模型,同樣的任務性能又能提高多少呢?答案是一點點。但在代碼長度上,預訓練過的模型要顯著優于沒有經過預訓練的模型。
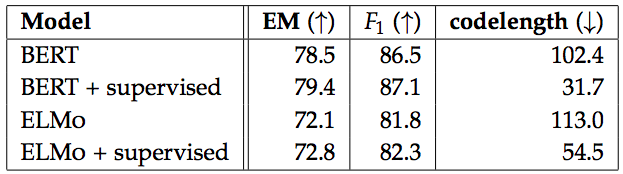
預訓練模型(+supervised)與非預訓練模型性能比較
作者考察的第三點是這些模型的泛化能力。實驗結果表明,在SQuAD數據集上表現最好的模型,移到其他數據集,比如Trivia、QuAC、QA-SRL、QA-ZRE后,仍然需要額外的相關訓練樣本。這個結果在意料之中,但再次凸顯了“學會一個數據集”和“學會完成一項任務”之間存在的巨大鴻溝。

在SQuAD數據集上性能最優的模型(得分超過80),在其他數據集上分數大幅降低
最后是有關學習課程 (curriculum) 和災難性遺忘的問題。模型忘記此前學會的語言知識有多快?學習課程的設計與模型的性能之間有什么影響?
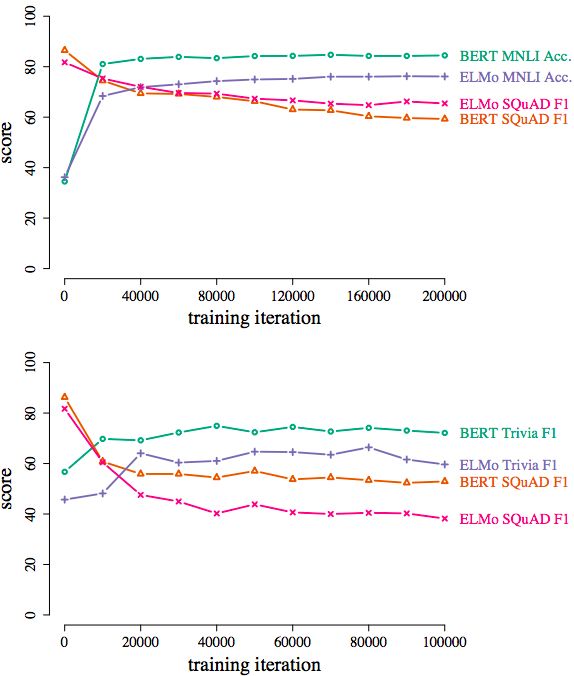
(上)將在SQuAD數據集上訓練好的模型改到MNLI上;(下)將在SQuAD數據集上訓練好的模型改到TriviaQA。兩種情況模型的性能都大幅下降。
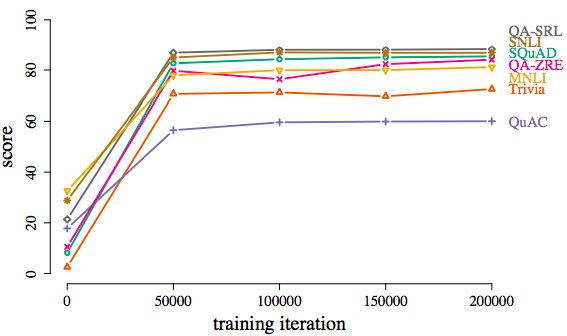
BERT模型用隨機訓練課程在各種數據集上取得的結果。實際上經過5萬次迭代后,模型就能基本完成各項任務(超過60分)。
從實驗結果看,在SQuAD數據集上訓練好的模型改到MNLI或TriviaQA這些不同數據集后,模型性能很快出現大幅下降,說明災難性遺忘發生。
雖然采用連續學習的方法,隨機初始化,5萬次迭代后,兩個模型尤其是BERT,基本上能在各個數據集上都達到差強人意的表現。

通過隨機訓練,20萬次迭代以后,BERT和ELMo在多項任務上的得分
但缺點是,這樣的隨機訓練模型在開始不需要樣本,轉換新任務以后也不需要保留此前學會的東西。因此,在連續學習的過程中,知識遷移究竟是如何發生的,目前還不得而知。
綜上,對一系列在各個不同NLP任務上取得當前最佳性能的模型進行實證評估后,DeepMind的研究人員得出結論:雖然NLP領域如今在模型設計方面取得了令人矚目的進展,而且這些模型在很多時候都能同時完成不止一項任務,但它們仍然需要大量與領域知識相關的訓練樣本 (in-domain training example),并且很容易發生災難性遺忘。
實現通用語言智能,我們還需要什么?
通過上述實驗可以發現,現有的state-of-the-art NLP模型幾乎全部都是:
擁有超大規模參數的深度學習模型;
事先以監督或非監督的的方式在訓練樣本上經過訓練;
通常包含了多個針對某項特定任務的構件以完成多項任務;
默認或者說假設某項任務的數據分布是平均的。
這種方法雖然合理,但仍舊需要大量與領域知識相關的訓練樣本,并且非常容易發生災難性遺忘。
因此,要實現通用語言智能,DeepMind研究人員在論文最后的討論中指出,我們還需要:更加復雜的遷移學習和連續學習方法 (transfer and continual learning method),能讓模型快速跨領域執行任務的記憶模塊 (memory module),訓練課程 (training curriculum) 的選擇對模型性能的影響也很重要,在生成語言模型 (generative language models) 方面的進展,也將有助于實現通用語言智能。
-
DeepMind
+關注
關注
0文章
130瀏覽量
10848 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:DeepMind:實現通用語言智能我們還缺什么?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
在ads1261的通用c語言例程中的390行的if是用來區分什么的呢?
編程語言在人工智能中的使用
鴻蒙原生應用元服務開發-初識倉頡開發語言
鴻蒙原生應用元服務開發-初識倉頡開發語言
【《大語言模型應用指南》閱讀體驗】+ 俯瞰全書
大語言模型的預訓練
nlp神經語言和NLP自然語言的區別和聯系
大模型應用之路:從提示詞到通用人工智能(AGI)
谷歌DeepMind推出SIMI通用AI智能體
fpga通用語言是什么
“單純靠大模型無法實現 AGI”!萬字長文看人工智能演進






 工商網監
工商網監
評論