 深度強化學習大神Pieter Abbeel發表深度強化學習的加速方法
深度強化學習大神Pieter Abbeel發表深度強化學習的加速方法
深度強化學習一直以來都以智能體訓練時間長、計算力需求大、模型收斂慢等而限制很多人去學習,比如:AlphaZero訓練3天的時間等,因此縮短訓練周轉時間成為一個重要話題。
加州大學伯克利分校教授,Pieter Abbeel最近發表了深度強化學習的加速方法,他從整體上提出了一個加速深度強化學習周轉時間的方法,成功的解決了一些問題。
論文地址: https://arxiv.org/pdf/1803.02811.pdf
最近幾年,深度強化學習在各行各業已經有了很成功的應用,但實驗的周轉時間(turn-around time)仍然是研究和實踐中的一個關鍵瓶頸。
該論文研究如何在現有計算機上優化現有深度RL算法,特別是CPU和GPU的組合。
且作者確認可以調整策略梯度和Q值學習算法以學習使用許多并行模擬器實例。 通過他們進一步發現可以使用比標準尺寸大得多的批量進行訓練,而不會對樣品復雜性或最終性能產生負面影響。
同時他們利用這些事實來構建一個統一的并行化框架,從而大大加快了兩類算法的實驗。 所有神經網絡計算都使用GPU,加速數據收集和訓練。
在使用同步和異步算法的基礎上,結果標明在使用整個DGX-1在幾分鐘內學習Atari游戲中的成功策略。
注: 【1】 周轉時間(turnaround time):訓練模型的時間。【2】. Nvidia DGX-1是Nvidia生產的服務器和工作站系列,專門用于使用GPGPU加速深度學習應用程序。這些服務器具有8個GPU,基于帶有HBM 2內存的Pascal或Volta 子卡,通過NVLink 網狀網絡連接。該產品系列旨在彌合GPU和AI加速器之間的差距,因為該設備具有專門用于深度學習工作負載的特定功能。最初的基于Pascal的DGX-1提供了170 teraflops的半精度處理,而基于Volta的升級將其提高到960 teraflops。更多信息,點擊查看
背景和相關內容
目前的深度強化學習嚴重依賴于經驗評估,因此turnaround 時間成為一個關鍵的限制因素,盡管存在這一重要瓶頸,但許多參考實施方案不能滿足現代計算機的吞吐量潛力,在這項工作中,作者研究如何在不改變其基本公式的情況下調整深度RL算法,并在一臺機器中更好地利用多個CPU和GPU進行實驗。 結果標明,顯著提高了硬件利用率的效率和規模,從而提高了學習速度。
今天比較領先的深度RL算法大致分為兩類:
策略梯度方法 ,以Asynchronous Advantage Actor-Critic(A3C)(Mnih et al 2016)是一個代表性的例子
Q值學習方法 ,一個代表性的例子是Deep Q-Networks(DQN)(Mnih等,2015)
傳統上,這兩個系列出現在不同的實現中并使用不同的硬件資源,該篇paper作者將它們統一在相同的擴展框架下。
作者貢獻了并行化深度RL的框架,包括用于推理和訓練的GPU加速的新技術。演示了以下算法的多GPU版本:Advantage Actor-Critic(A3C),Proximal Policy Optimization(PPO),DQN,Categorical DQN和Rainbow。
為了提供校準結果,作者通過Arcade學習環境(ALE)測試我們在重度基準測試的Atari-2600域中的實現。
同時使用批量推斷的高度并行采樣可以加速所有實驗的(turnaround)周轉時間,同時發現神經網絡可以使用比標準大得多的批量大小來學習,而不會損害樣本復雜性或最終游戲分數。
除了探索這些新的學習方式之外,作者還利用它們來大大加快學習速度。例如, 策略梯度算法在8-GPU服務器上運行,在10分鐘內學會成功的游戲策略,而不是數小時。
他們同樣將一些標準Q值學習的持續時間從10天減少到2小時以下。或者,獨立的RL實驗可以與每臺計算機的高聚合吞吐量并行運行。相信這些結果有望加速深度研究,并為進一步研究和發展提出建議。
另外,作者對演員評論方法的貢獻在很多方面超越了目前的很多人做法,他們主要做了:“”改進抽樣組織,使用多個GPU大大提高規模和速度,以及包含異步優化。
并行,加速的RL框架
作者考慮使用深度神經網絡來實驗基于CPU的模擬器環境和策略,在這里描述了一套完整的深度RL并行化技術,可以在采樣和優化過程中實現高吞吐量。
同時并對GPU進行均勻處理,每個都執行相同的抽樣學習過程,該策略可以直接擴展到各種數量的GPU。
同步采樣(Synchronized Sampling)
首先將多個 CPU核心 與 單個GPU 相關聯。多個模擬器在CPU內核上以并行進程運行,并且這些進程以同步方式執行環境步驟。在每個步驟中,將所有單獨的觀察結果收集到批處理中以進行推理,在提交最后一個觀察結果后在GPU上調用該批處理。 一旦動作返回,模擬器再次步驟,依此類推,系統共享內存陣列提供了動作服務器和模擬器進程之間的快速通信。
由于落后效應等同于每一步的最慢過程,同步采樣可能會減速。步進時間的變化源于不同模擬器狀態的不同計算負載和其他隨機波動。隨著并行進程數量的增加,落后者效應會惡化,但通過在每個進程中堆疊多個獨立的模擬器實例來緩解它。每個進程為每個推理批處理步驟(順序)執行所有模擬器。這種安排還允許用于推斷的批量大小增加超過進程數(即CPU核心),其原理如圖1(a)所示。
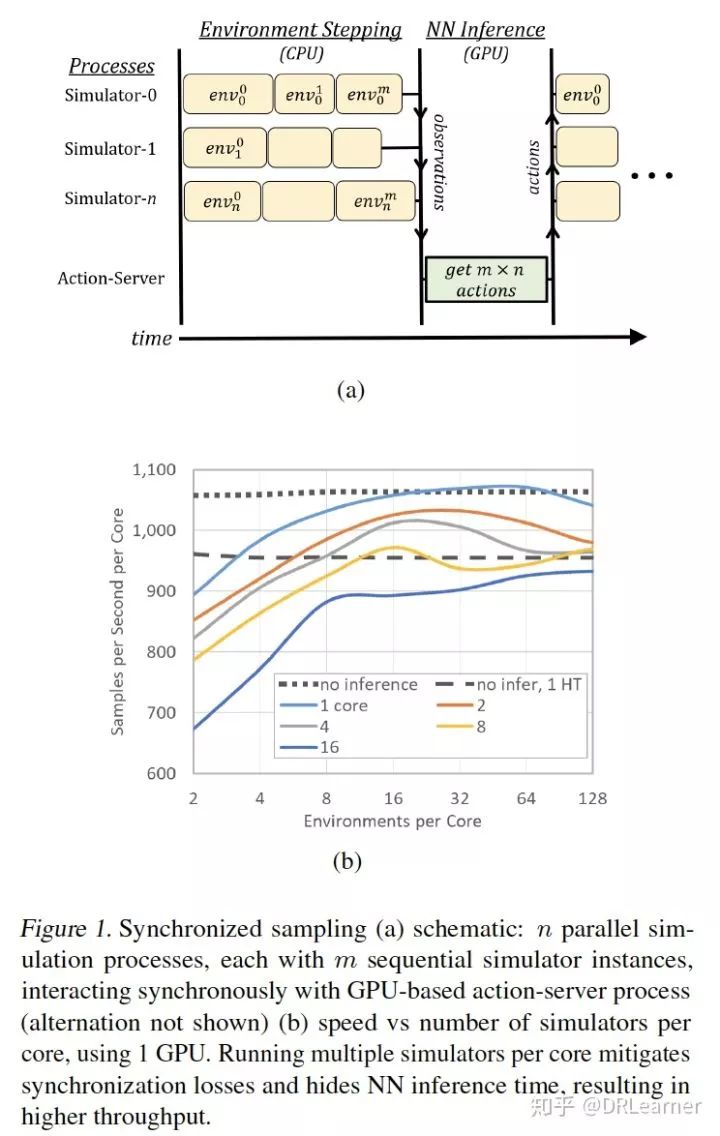
通過僅在優化暫停期間重置可以避免由長環境重置引起的減速,如果模擬和推理負載平衡,則每個組件將在一半的時間內處于空閑狀態,因此我們形成兩組交替的模擬器過程。當一個組等待其下一個動作時,其他步驟和GPU在為每個組服務之間交替。交替保持高利用率,并且進一步隱藏兩者中較快的計算的執行時間。我們通過重復模板組織多個GPU,均勻分配可用的CPU核心。我們發現修復每個模擬器進程的CPU分配是有益的,其中一個核心保留用于運行每個GPU。實驗部分包含采樣速度的測量值,該測量值隨環境實例的數量而增加。
同步多GPU優化(Synchronous Multi-GPU Optimization)
在同步算法中,所有GPU都保持相同的參數值,利用隨機梯度估計的數據并行性并在每個GPU上使用眾所周知的更新程序:
使用本地采集的樣本計算梯度
全部減少GPU之間的梯度
使用組合梯度更新本地參數。我們使用NVIDIA集體通信庫在GPU之間進行快速通信。
異步多GPU優化(Asynchronous Multi-GPU Optimization)
在異步優化中,每個GPU充當其自己的采樣器-學習器單元,并將更新應用于CPU內存中保存的中央參數存儲。
使用加速器會強制選擇執行參數更新的位置。根據經驗,在GPU上將更快的常見規則應用于網絡更快。一般更新程序包括三個步驟:
在本地計算梯度并將其存儲在GPU上
將當前中心參數拉到GPU上并使用預先計算的梯度將更新規則應用于它們
寫入更新的參數回到中央CPU商店
在此序列之后,本地GPU參數與中心值同步,并且再次進行采樣,集中更新規則參數。其不會將更新增量添加到需要CPU計算的中心參數,而是覆蓋這些值。
因此,采用上述步驟(2)和(3)的鎖定,防止其他進程同時讀取或寫入參數值。同時將參數分成少量不相交的塊,這些塊分別更新,每個塊都有自己的鎖(步驟2-3成為塊上的循環)。這可以平衡更新調用效率與鎖爭用,并可以提供良好的性能。
實驗
使用Atari-2600域來研究高度并行化RL的縮放特性,研究如下:
同步采樣的效率如何,它可以達到什么速度?
策略梯度和Qlearning算法是否可以適應學習使用許多并行模擬器實例而不會降低學習成績
大批量培訓和/或異步方法能否加快優化速度而不會降低樣品的復雜性?
在所有學習實驗中,作者保持原始訓練強度,意味著每個采樣數據點的平均訓練使用次數。
對于A3C,PPO和DQN+變體,參考訓練強度分別為1,4和8。此處顯示的所有學習曲線均為至少兩個隨機種子的平均值。
對于策略梯度方法,我們跟蹤在線分數,對最近100個完成的軌跡進行平均。對于DQN和變體,我們每100萬步暫停以評估,直到達到125,000步,最大路徑長度為27,000步。
Sampling(采樣)
一系列僅采樣測量表明,盡管存在潛在的落后者,同步采樣方案可以實現良好的硬件利用率。
首先,我們研究了 單個GPU 在為多個環境提供推理時的容量。圖1(b)顯示了在播放BREAKOUT時在P100 GPU上運行訓練有素的A3C-Net策略的測量結果。
通過CPU核心計數歸一化的聚合采樣速度被繪制為在每個核心上運行的(順序)Atari模擬器的數量的函數,交替方案的最小值是每個核心2個模擬器。
不同的曲線表示運行模擬的不同數量的CPU核心。作為參考,我們包括在沒有推斷的情況下運行的單個核心的采樣速度--單個過程的虛線,以及兩個超線程中的每一個的虛線一個過程。
使用推理和單核運行,采樣速度隨著模擬器計數而增加,直到推斷時間完全隱藏。出現更高核心數的同步丟失。但是,每個核心只有8個環境,GPU甚至支持16個CPU內核,運行速度大約為無推理速度的80%。
接下來,測量了在整個8-GPU,40核服務器上并行播放BREAKOUT的同一A3C-Net的僅采樣速度。
在模擬器計數為256(每個核心8個)及以上時,服務器每秒實現大于35,000個樣本,或每小時5億個仿真器幀,其結果如圖:
許多模擬器實例(Learning with Many Simulator Instances)
為了利用并行采樣的高吞吐量,同時研究了如何使用現有的深度RL算法來學習許多模擬器實例。
以下研究結果表明,只有微小的變化才能適應所有算法并保持性能。我們為每種算法嘗試了不同的技術。有趣的是,縮放對同步和異步學習的影響有所不同。
開始狀態解相關(Starting State Decorrelation) 在許多模擬器的一些策略梯度實驗中,學習很早就失敗了。
我們發現在起始游戲狀態中的相關性導致大的但知情度不足的學習信號,從而破壞了早期學習的穩定性。
通過在實驗初始化期間通過隨機數量的均勻隨機動作步進每個模擬器來糾正此問題。采取這一措施時,發現學習率升溫沒有進一步的效果。在訓練時,游戲重置照常進行。
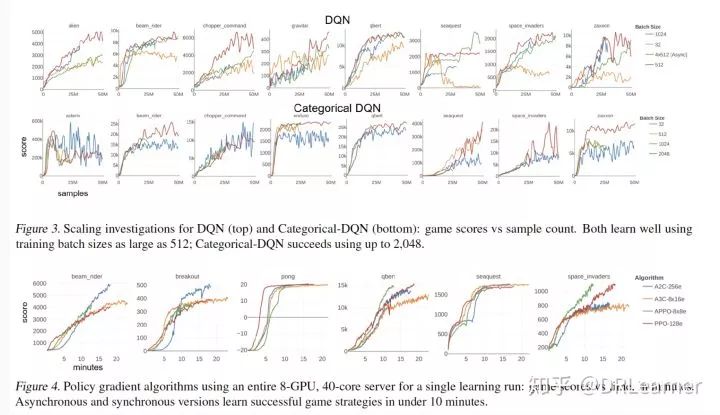
A2C:優化批量大小隨著模擬器的數量而增加(保持采樣范圍固定)。相應地,每個采集的樣本進行的參數更新步驟更少,我們發現,在一組測試游戲中,以批量大小的平方根增加學習率是最佳的。圖2的上圖顯示了學習曲線與總樣本數,模擬器計數范圍為16到512(批量大小為80到2,560)。雖然大型模擬器計數的樣本效率逐漸下降,但游戲分數基本沒有變化。
A3C:我們測試的異步適應使用16環境A2C代理作為基礎采樣器 - 學習器單元。圖2顯示學習曲線與學習者數量的總樣本計數,范圍從1到32,4,對應于16到512個模擬器。在大多數情況下,由此產生的學習曲線幾乎無法區分,盡管有些學習曲線在最大范圍內降級。
PPO:已經用于基準PPO的大批量(8模擬器x 256-horizon = 2,048)提供了與許多模擬器學習的不同途徑:我們減少了采樣范圍,使得總批量大小保持固定。圖2顯示了模擬器計數從8到512的學習曲線與樣本計數,相應的采樣范圍從256到4步。成功的學習繼續保持最大規模。
APPO:嘗試了PPO的異步版本,使用8模擬器PPO代理作為基礎學習器單元。圖2中的底部面板顯示了對8個GPU運行的8個學習者的研究的學習曲線,其中通信頻率不同。標準PPO每個時期使用4個梯度更新,每個優化使用4個時期;我們在同步之間進行了1-4次漸變更新(補充材料中提供了更新規則)。我們發現在采樣期間定期從中心參數中提取新值是有幫助的,并且在所有情況下都采用64步的范圍(因此減少了異步技術中固有的策略滯后,PPO的頻率降低,但更頻繁,但更實質性的更新) 。在幾個游戲中,學習保持一致,表明可以減少某些異步設置中的通信。
DQN + Variants:我們通過模擬器組織了體驗重放緩沖區。總緩沖區大小保持在1百萬次轉換,因此每個模擬器保持相應較短的歷史記錄。我們觀察到學習性能在很大程度上獨立于模擬器計數高達200以上,前提是每個優化周期的更新步驟數不是太多(大批量大小可以改善這一點)。
Q-Value Learning with Large Training Batches
DQN:我們試驗了從標準32到2,048的批量大小。我們發現一致的學習成績高達512,超過這一點,很難找到在所有測試游戲中表現良好的單一(縮放)學習率。在幾個游戲中,更大的批量大小改進了學習,如圖3所示。

發現異步DQN可以使用多達4個GPU學習者很好地學習,每個學習者使用批量大小512。
分類DQN:我們發現分類DQN比DQN進一步擴展。圖3的下顯示批量大小高達2,048的學習曲線,最大分數沒有減少。
這可能是由于梯度信號的內容更豐富。值得注意的是,SEAQUEST游戲中最大批量的學習被延遲,但最終達到了更高的最高分。由于使用了Adam優化器,因此沒有必要縮放學習率。
e-Rainbow:盡管使用了分布式學習,但在某些游戲中,e-Rainbow的性能卻超過批量512。該批次大小的分數大致與批量大小為32的文獻中報道的分數相符(Hessel等,2017)(曲線顯示在附錄中)。
學習速度(Learning Speed)
研究運行8-GPU,40核服務器(P100 DGX-1),以學習單個游戲時可獲得的學習速度,作為大規模實施的示例。

圖4顯示了策略梯度方法A2C,A3C,PPO和APPO的良好性能配置的結果。幾場比賽表現出陡峭的初始學習階段;所有算法都在10分鐘內完成了該階段。值得注意的是,PPO在4分鐘內掌握了Pong。
具有256個環境的A2C每秒處理超過25,000個樣本,相當于每小時超過9000萬步(3.6億幀)。表2列出了縮放測量,顯示使用8個GPU相對于1的加速比大于6倍。
我們運行了DQN及其變體的同步版本,訓練時間如表2所示。使用1個GPU和5個CPU核心,DQN和e-Rainbow分別在8小時和14小時內完成了5000萬步(2億幀),一個重要的獲得超過10天的參考時間。
后者使用1個GPU和376個CPU核心(參見例如圖2中的10小時學習曲線)。使用多個GPU和更多內核加速了我們的實施。
憑借更大的批量大小,Categorical-DQN使用整個服務器在2小時內完成最佳擴展和完成培訓,相對于1 GPU,速度超過6倍。
然而,DQN和e-Rainbow的回報減少超過2個GPU。我們無法找到進一步提高學習速度而不會在某些游戲中降低性能的異步配置(我們只測試了完全通信的算法)。可能存在改善我們擴展的機會。

批量大小對優化的影響(Effects of Batch Size on Optimization)
限制培訓批量大小的可能因素包括:
(1) 減少探索,因為在環境中運行的網絡較少
(2) 網絡權重的數值優化存在困難
我們進行了實驗以開始識別這些因素。
二級學習者實驗(Secondary-Learner Experiment)
我們配置了一個輔助DQN學習器,僅使用普通DQN代理的重放緩沖區進行訓練。
初級學習者使用與主要參數值相同的參數值進行初始化, “采樣器 - 學習器”,兩個網絡同時訓練,數據消耗速率相同。每個人都抽樣自己的培訓批次。
在BREAKOUT的游戲中,64和2048采樣器學習者獲得了相同的分數,但是2048學習者需要更多的樣本,盡管使用最快的穩定學習率(數字指的是訓練批量大小)。
當使用2048樣本學習者訓練64中學習者時,中學習者的分數跟蹤了初級學習者的分數。然而,在相反的情況下,2048中學生無法學習。
我們認為這是由于參數更新數量減少的優化速度較慢 - 它無法跟蹤初始化附近的Q值估計的快速變化,并且變得過于偏離策略學習。
在使用兩個256學習者的相同測試中,他們的分數相匹配。如果2048年的二級學習者超過了2048年的樣本學習者,那么就會認為探索是一個比優化更重要的因素。有關數據,請參閱補充材料。
更新規則(Update Rule)
我們進行了一項實驗,以確定更新規則對分類DQN中的優化的影響。我們發現Adam公式優于RMSProp,為大批量學習者提供了在學習過程中遍歷參數空間的能力。
當比較實現相同學習曲線的代理時,那些使用較小批量(并因此執行更多更新步驟)的代理傾向于在訓練中的所有點具有更大的參數矢量規范。
與RMSProp不同,Adam規則導致批量大小之間參數規范的相當緊密的傳播,而不會改變學習率。
這解釋了在分類DQN和e-Rainbow中不需要縮放學習率,并且表明更新規則在縮放中起著重要作用。更多細節,包括卷積和完全連通層的趨勢.
關于更新規則和批量大小規模的觀察的細節
我們在兩個不同的參數更新規則下提出了縮放訓練批量大小對神經網絡優化的影響的觀察結果:Adam和RMSProp(沒有動量的RMSProp,只有平方梯度的直接累積,參見例如:
https://github.com/Lasagne/Lasagne/blob/master/lasagne/updates.py
我們在游戲Q * BERT上培訓代理,調整學習率以產生非常相似的所有設置的性能曲線,并且我們在學習期間跟蹤了幾個量的L-2矢量規范。
這些包括漸變,參數更新步驟和參數值本身。與本文中的所有DQN實驗一樣,訓練強度固定為8,因此學習期間參數更新步驟的數量與批量大小成反比。每個設置運行兩個隨機種子。
盡管整個訓練過程中游戲分數大致相同,但在任何一點上找到的確切解決方案都沒有,正如不同的參數規范所證明的那樣。沒有使用正規化。
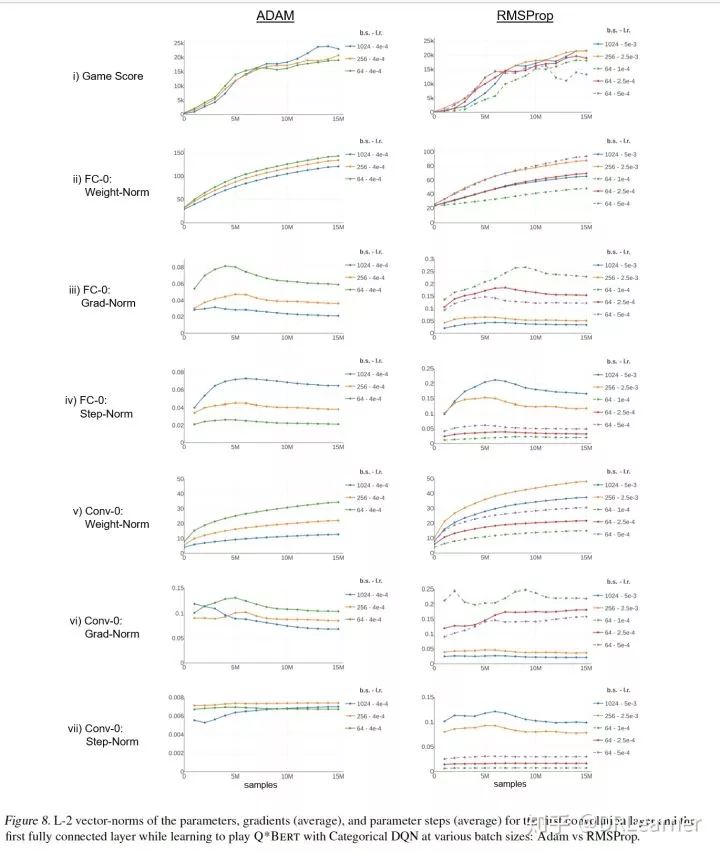
根據圖-8,其中曲線由批量大小和學習率標記。當整體觀察網絡(即所有權重和偏差的規范作為單個向量)時,趨勢反映了在大多數權重為的FC-0中看到的趨勢。
(i)學習曲線:我們控制游戲得分,根據需要調整學習率。對于批量大小為64的RMSProp,我們考慮的學習率略低(1×10^(-4)),學習速度慢,最終得分較低,學習率略高(5*10^-4) ),由于不穩定性而產生較低的最終得分 - 這些是所有面板中的虛線。
(ii)完全連接-0 Weights-Norm:盡管對所有設置使用相同的學習速率,但Adam優化器產生了相當緊密的分組。另一方面,RMSProp學習者需要在批量大小為64到1,024之間將學習率提高20倍,然后產生非常相似的規范。在批量大小64處,慢/不穩定學習分別以小/大規范為特征。批量大小256次運行的大規范表明這種學習率可能接近穩定性的上限。
(iii)完全連接-0梯度 - 范數:在兩個更新規則下,大批量大小總是產生較小的梯度向量 - 減小的方差導致減小的量值。在查看總梯度范數時,我們還在策略梯度方法中觀察到了這種模式。這里,梯度的大小與參數范數成反比;請參閱RMSProp 64批量大小的曲線。這種效果與批量大小的影響相反并且被抵消了。
( iv)完全連接-0步驟規范:盡管梯度較小,但Adam優化器為較大批量學習者產生了明顯更大的步長。 RMSProp需要調整學習率才能產生相同的效果。在兩個更新規則下,步長增加量并未完全補償步數的減少,這表明較大的批量學習者通過參數空間遵循更直的軌跡。 RMSProp總體上導致了更大的步驟,但盡管以較小的權重結束了學習 - 其學習軌跡顯然不那么直接,更蜿蜒。
(v)卷積-0權重 - 范數:亞當優化器在這里的規范中比在FC-0層中擴展得更多;隨著批量增加,學習重點從Conv-0轉移。但是在RMSProp中,學習率的提高導致第一個卷積層對于更大的批量大小變大,更加強調這一層。
(vi)卷積-0梯度 - 范數:亞當更新規則在梯度范數中產生了一個有趣的交叉;大批量學習者實際上開始走高,抵消了其他情況下看到的趨勢。 RMSProp下的模式與FC-0的模式相匹配。
(vii)卷積-0步驟范數:與FC-0不同,步驟范數在Adam下的批量大小沒有顯著變化。 RMSProp產生了與FC-0類似的模式。總體而言,Adam優化器似乎可以補償FC-0層中的批量大小,但在Conv-0層中則較少,導致Conv-0中大批量學習時不再強調。 RMSProp中學習率的提高補償了FC-0層中的批量大小,并增加了對Conv-0學習的重視程度。這種模式可能會對學習表示與游戲策略產生影響。對這些明顯趨勢的進一步研究可以深入了解學習退化的原因以及大批量RL的可能解決方案。

梯度估計飽和度(Gradient Estimate Saturation)
使用A2C,我們在每次迭代時測量正常,全批次梯度和僅使用批次的一半計算的梯度之間的關系。對于小批量試劑,測量的全批次和半批次梯度之間的平均余弦相似度接近1 =P2。
這意味著兩個半批漸變是正交的,高維空間中的零中心隨機向量也是正交的。 然而,對于大批量學習者(例如256個環境),余弦相似性在1 = p2之上顯著增加。 梯度估計的飽和度明顯與較差的樣本效率相關,如圖2頂部的學習曲線所示。

總結
:
我們引入了一個統一的框架來并行化深度RL,它使用硬件加速器來實現快速學習。該框架適用于一系列算法,包括策略梯度和Q值學習方法。
我們的實驗表明,幾種領先的算法可以高度并行的方式學習各種Atari游戲,而不會損失樣本復雜性和前所未有的掛鐘時間。
該結果表明了顯著提高實驗規模的有希望的方向。我們將發布代碼庫。我們注意到擴展該框架的幾個方向。
首先是將其應用于Atari以外的領域,尤其是涉及感知的領域。其次,由于GPU加速推理和訓練,我們的框架很可能有利地擴展到更復雜的神經網絡代理。
此外,隨著網絡復雜性的增加,擴展可能變得更容易,因為GPU可以以較小的批量大小有效地運行,盡管通信開銷可能會惡化。
降低精度算術可以加速學習 - 由于使用基于CPU的推理,在深度RL中尚待探索的主題。當前的單節點實現可以是用于分布式算法的構建塊。
關于深度RL中可能的并行化程度的問題仍然存在。我們還沒有最終確定縮放的限制因素,也沒有確定每個游戲和算法是否相同。
雖然我們已經看到大批量學習中的優化效果,但其他因素仍然存在。異步擴展的限制仍未得到探索;我們沒有明確確定這些算法的最佳配置,但只提供了一些成功的版本。
更好的理解可以進一步提高縮放率,這是推動深度RL的一個有希望的方向。
-
gpu
+關注
關注
28文章
4729瀏覽量
128890 -
模擬器
+關注
關注
2文章
874瀏覽量
43208 -
強化學習
+關注
關注
4文章
266瀏覽量
11246
原文標題:Pieter Abbeel:深度強化學習加速方法
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度強化學習實戰
將深度學習和強化學習相結合的深度強化學習DRL
薩頓科普了強化學習、深度強化學習,并談到了這項技術的潛力和發展方向
如何深度強化學習 人工智能和深度學習的進階
深度強化學習是否已經到達盡頭?
DeepMind發布強化學習庫RLax
模型化深度強化學習應用研究綜述

基于深度強化學習仿真集成的壓邊力控制模型
《自動化學報》—多Agent深度強化學習綜述







 工商網監
工商網監
評論