 面向圖譜的深度學習會迎來重大突破嗎
面向圖譜的深度學習會迎來重大突破嗎
神經網絡(Graph NN)是近來的一大研究熱點,尤其是DeepMind提出的“Graph Networks”,號稱有望讓深度學習實現因果推理。但這篇論文晦澀難懂,復星集團首席AI科學家、大數醫達創始人鄧侃博士,在清華俞士綸教授團隊對GNN綜述清晰分類的基礎上,解析DeepMind“圖網絡”的意義。
- 1 -
回顧2018年機器學習的進展,2018年6月DeepMind團隊發表的論文“Relational inductive biases, deep learning, and graph networks”,是一篇重要的論文,引起業界熱議。
隨后,很多學者沿著他們的思路,繼續研究,其中包括清華大學孫茂松團隊。他們于2018年12月,發表了一篇綜述,題目是“Graph neural networks: A review of methods and applications”。
2019年1月,俞士綸教授團隊,也寫了一篇綜述,這篇綜述的覆蓋面更全面,題目是“A Comprehensive Survey on Graph Neural Networks”。
俞士綸教授團隊綜述GNN,來源:arxiv
DeepMind團隊的這篇論文,引起業界這么熱烈的關注,或許有三個原因:
聲望:自從AlphaGo戰勝李世乭以后,DeepMind享譽業界,成為機器學習業界的領軍團隊,DeepMind團隊發表的論文,受到同行普遍關注;
開源:DeepMind團隊發表論文[1]以后不久,就在Github上開源了他們開發的軟件系統,項目名稱叫Graph Nets[4];
主題:聲望和開源,都很重要,但是并不是被業界熱議的最主要的原因。最主要的原因是主題,DeepMind團隊研究的主題是,如何用深度學習方法處理圖譜。
- 2 -
圖譜(Graph)由點(Node)和邊(Edge)組成。
圖譜是一個重要的數學模型,可以用來解決很多問題。
譬如我們把城市地鐵線路圖當成圖譜,每個地鐵站就是一個點,相鄰的地鐵站之間的連線就是邊,輸入起點到終點,我們可以通過圖譜的計算,計算出從起點到終點,時間最短、換乘次數最少的行程路線。
又譬如Google和百度的搜索引擎,搜索引擎把世界上每個網站的每個網頁,都當成圖譜中的一個點。每個網頁里,經常會有鏈接,引用其它網站的網頁,每個鏈接都是圖譜中的一條邊。哪個網頁被引用得越多,就說明這個網頁越靠譜,于是,在搜索結果的排名也就越靠前。
圖譜的操作,仍然有許多問題有待解決。
譬如輸入幾億條滴滴司機行進的路線,每條行進路線是按時間排列的一連串(時間、GPS經緯度)數組。如何把幾億條行進路線,疊加在一起,構建城市地圖?
不妨把地圖也當成一個圖譜,每個交叉路口,都是一個點,連接相鄰的兩個交叉路口,是一條邊。
貌似很簡單,但是細節很麻煩。
舉個例子,交叉路口有很多形式,不僅有十字路口,還有五角場、六道口,還有環形道立交橋——如何從多條路徑中,確定交叉路口的中心位置?
日本大阪天保山立交橋,你能確定這座立交橋的中心位置嗎?
- 3 -
把深度學習,用來處理圖譜,能夠擴大我們對圖譜的處理能力。
深度學習在圖像和文本的處理方面,已經取得了巨大的成功。如何擴大深度學習的成果,使之應用于圖譜處理?
圖像由橫平豎直的像素矩陣組成。如果換一個角度,把每個像素視為圖譜中的一個點,每個像素點與它周邊的8個相鄰像素之間都有邊,而且每條邊都等長。通過這個視角,重新審視圖像,圖像是廣義圖譜的一個特例。
處理圖像的諸多深度學習手段,都可以改頭換面,應用于廣義的圖譜,譬如convolution、residual、dropout、pooling、attention、encoder-decoder等等。這就是深度學習圖譜處理的最初想法,很樸實很簡單。
雖然最初想法很簡單,但是深入到細節,各種挑戰層出不窮。每種挑戰,都意味著更強大的技術能力,都孕育著更有潛力的應用場景。
深度學習圖譜處理這個研究方向,業界沒有統一的稱謂。
強調圖譜的數學屬性的團隊,把這個研究方向命名為Geometric Deep Learning。孫茂松團隊和俞士綸團隊,強調神經網絡在圖譜處理中的重要性,強調思想來源,他們把這個方向命名為Graph Neural Networks。DeepMind團隊卻反對綁定特定技術手段,他們使用更抽象的名稱,Graph Networks。
命名不那么重要,但是用哪種方法去梳理這個領域的諸多進展,卻很重要。把各個學派的目標定位和技術方法,梳理清楚,有利于加強同行之間的相互理解,有利于促進同行之間的未來合作。
- 4-
俞士綸團隊把深度學習圖譜處理的諸多進展,梳理成5個子方向,非常清晰好懂。
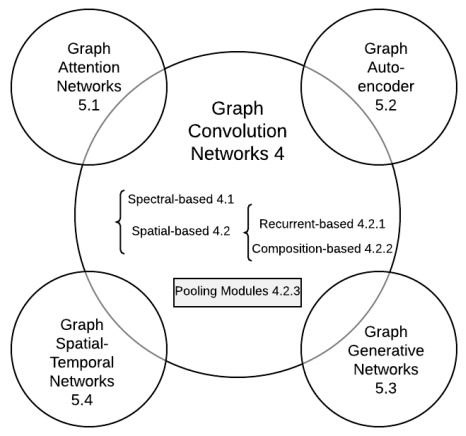
俞士綸團隊把深度學習圖譜處理梳理成5個子方向,來源:論文 A Comprehensive Survey on Graph Neural Networks
Graph Convolution Networks
Graph Attention Networks
Graph Embedding
Graph Generative Networks
Graph Spatial-temporal Networks
先說Graph Convolution Networks (GCNs)。
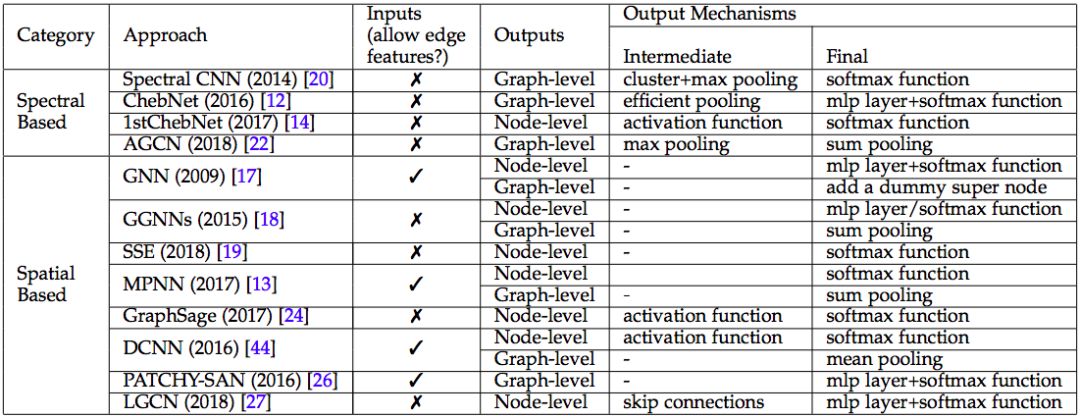
GCN 類別匯總,來源:論文 A Comprehensive Survey on Graph Neural Networks
GCN把CNN諸般武器,應用于廣義圖譜。CNN主要分為四個任務,
點與點之間的融合。在圖像領域,點與點之間的融合主要通過卷積技術(convolution)來實現。在廣義圖譜里,點與點之間的關系,用邊來表達。所以,在廣義圖譜里,點點融合,有比卷積更強大的辦法。Messsage passing [5]就是一種更強大的辦法。
分層抽象。CNN使用convolution的辦法,從原始像素矩陣中,逐層提煉出更精煉更抽象的特征。更高層的點,不再是孤立的點,而是融合了相鄰區域中其它點的屬性。融合鄰點的辦法,也可以應用于廣義圖譜中。
特征提煉。CNN使用pooling等手段,從相鄰原始像素中,提煉邊緣。從相鄰邊緣中,提煉實體輪廓。從相鄰實體中,提煉更高層更抽象的實體。CNN通常把convolution和pooling交替使用,構建結構更復雜,功能更強大的神經網絡。對于廣義圖譜,也可以融匯Messsage passing和Pooling,構建多層圖譜。
輸出層。CNN通常使用softmax等手段,對整張圖像進行分類,識別圖譜的語義內涵。對于廣義圖譜來說,輸出的結果更多樣,不僅可以對于整個圖譜,輸出分類等等結果。而且也可以預測圖譜中某個特定的點的值,也可以預測某條邊的值。
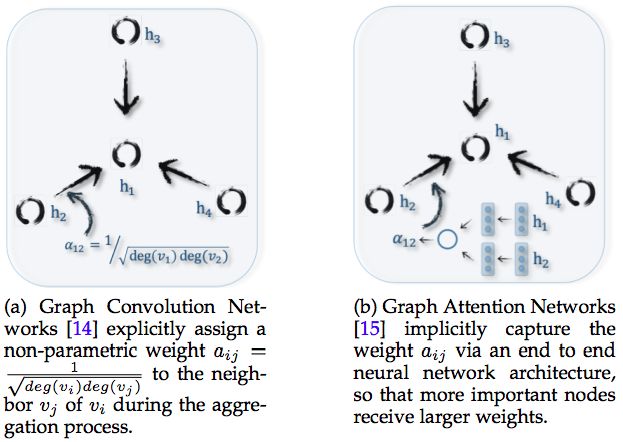
GCN 和Graph Attention Networks 的區別來源:論文 A Comprehensive Survey on Graph Neural Networks
Graph Attention Networks要解決的問題,與 GCN類似,區別在于點點融合、多層抽象的方法。
Graph Convolution Networks使用卷積方式,實現點點融合和分層抽象。Convolution卷積方式僅僅適用于融合相鄰的點,而attention聚焦方式卻不限于相鄰的點,每個點可以融合整個圖譜中所有其它點,不管是否相鄰,是否融合如何融合,取決于點與點之間的關聯強弱。
Attention能力更強大,但是對于算力的要求更高,因為需要計算整個圖譜中任意兩個點之間的關聯強弱。所以Graph Attention Networks研究的重點,是如何降低計算成本,或者通過并行計算,提高計算效率。
- 5-
Graph Embedding要解決的問題,是給圖譜中每個點每條邊,賦予一個數值張量。圖像不存在這個問題,因為像素天生是數值張量。但是,文本由文字詞匯語句段落構成,需要把文字詞匯,轉化成數值張量,才能使用深度學習的諸多算法。
如果把文本中的每個文字或詞匯,當成圖譜中的一個點,同時把詞與詞之間的語法語義關系,當成圖譜中的一條邊,那么語句和段落,就等同于行走在文本圖譜中的一條行進路徑。
如果能夠給每個文字和詞匯,都賦予一個貼切的數值張量,那么語句和段落對應的行進路徑,多半是最短路徑。
有多種實現Graph Embedding的辦法,其中效果比較好的辦法是Autoencoder。用GCN的辦法,把圖譜的點和邊轉換成數值張量,這個過程稱為編碼(encoding),然后通過計算點與點之間的距離,把數值張量集合,反轉為圖譜,這個過程稱為解碼(decoding)。通過不斷地調參,讓解碼得到的圖譜,越來越趨近于原始圖譜,這個過程稱為訓練。
Graph Embedding給圖譜中的每個點每條邊,賦予貼切的數值張量,但是它不解決圖譜的結構問題。
如果輸入大量的圖譜行進路徑,如何從這些行進路徑中,識別哪些點與哪些點之間有連邊?難度更大的問題是,如果沒有行進路徑,輸入的訓練數據是圖譜的局部,以及與之對應的圖譜的特性,如何把局部拼接成圖譜全貌?這些問題是Graph Generative Networks要解決的問題。
Graph Generative Networks比較有潛力的實現方法,是使用Generative Adversarial Networks (GAN)。
GAN由生成器(generator)和辨別器(discriminator)兩部分構成:1.從訓練數據中,譬如海量行進路徑,生成器猜測數據背后的圖譜應該長什么樣;2.用生成出來的圖譜,偽造一批行進路徑;3.從大量偽造的路徑和真實的路徑中,挑選幾條路徑,讓辨別器識別哪幾條路徑是偽造的。
如果辨別器傻傻分不清誰是偽造路徑,誰是真實路徑,說明生成器生成出的圖譜,很接近于真實圖譜。
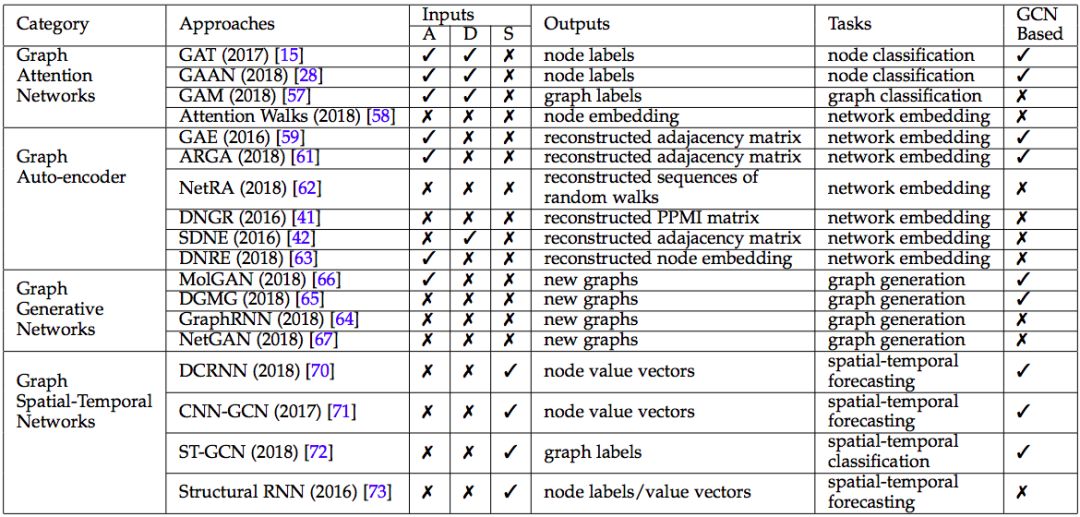
GCN 以外的其他 4 種圖譜神經網絡,來源:論文 A Comprehensive Survey on Graph Neural Networks
- 6-
以上我們討論了針對靜態圖譜的若干問題,但是圖譜有時候是動態的,譬如地圖中表現的道路是靜態的,但是路況是動態的。
如何預測春節期間,北京天安門附近的交通擁堵情況?解決這個問題,不僅要考慮空間spatial的因素,譬如天安門周邊的道路結構,也要考慮時間temporal的因素,譬如往年春節期間該地區交通擁堵情況。這就是Graph Spatial-temporal Networks要解決的問題之一。
Graph Spatial-temporal Networks還能解決其它問題,譬如輸入一段踢球的視頻,如何在每一幀圖像中,識別足球的位置?這個問題的難點在于,在視頻的某些幀中,足球有可能是看不見的,譬如被球員的腿遮擋了。
解決時間序列問題的通常思路,是RNN,包括LSTM和GRU等等。
DeepMind團隊在RNN基礎上,又添加了編碼和解碼(encoder-decoder)機制。
- 7 -
在DeepMind團隊的這篇論文里[1],他們聲稱自己的工作,“part position paper, part review, and part unification”,既是提案,又是綜述,又是融合。這話怎么理解?

DeepMind聯合谷歌大腦、MIT等機構27位作者發表重磅論文,提出“圖網絡”(Graph network),將端到端學習與歸納推理相結合,有望解決深度學習無法進行關系推理的問題。
前文說到,俞士綸團隊把深度學習圖譜處理的諸多進展,梳理成5個子方向:1) Graph Convolution Networks、2) Graph Attention Networks、3) Graph Embedding、4) Graph Generative Networks、5) Graph Spatial-temporal Networks。
DeepMind團隊在5個子方向中著力解決后4個方向,分別是Graph Attention Networks、Graph Embedding、Graph Generative Networks和Graph Spatial-temporal Networks。他們把這四個方向的成果,“融合”成統一的框架,命名為Graph Networks。
在他們的論文中,對這個四個子方向沿途的諸多成果,做了“綜述”,但是并沒有綜述Graph Convolution Networks方向的成果。然后他們從這四個子方向的諸多成果中,挑選出了他們認為最有潛力的方法,形成自己的“提案”,這就是他們開源的代碼[4]。
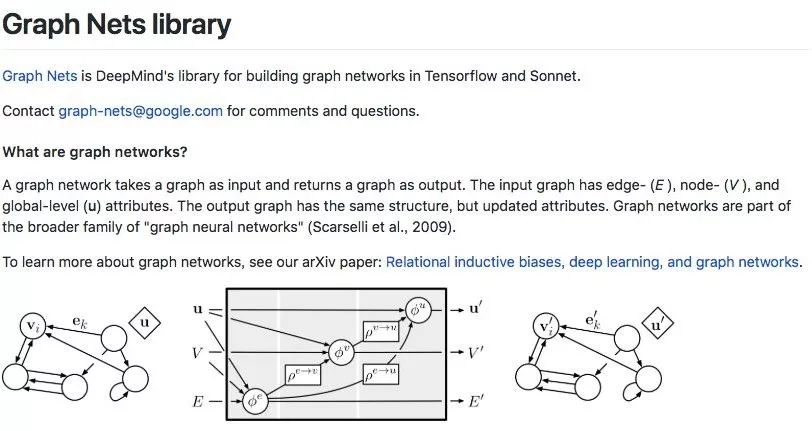
DeepMind在2018年10月開源的Graph Nets library,用于在TensorFlow中構建簡單而強大的關系推理網絡。來源:github.com/deepmind/graph_nets
雖然論文中,他們聲稱他們的提案解決了四個子方向的問題,但是查看他們開源的代碼,發現其實他們著力解決的是后兩個子方向,Graph Attention Networks和Graph Spatial-temporal Networks。
DeepMind的思路是這樣的:首先,把[5]的message passing點點融合的機制,與[6]圖譜全局的聚焦機制相結合,構建通用的graph block模塊;其次,把LSTM要素融進encoder-decoder框架,構建時間序列機制;最后,把graph block模塊融進encoder-decoder框架,形成Graph Spatial-temporal Networks通用系統。
- 8-
為什么DeepMind的成果很重要?事關四件大事。
一、深度學習過程的解釋
從原理上講,深度學習譬如CNN的成果,來自于對圖像的不斷抽象。也就是,從原始的像素矩陣中,抽象出線段。從首尾相連的相鄰線段中,抽象出實體的輪廓。從輪廓抽象出實體,從實體抽象出語義。
但是,如果窺探CNN每一層的中間結果,實際上很難明確,究竟是哪一層的哪些節點,抽象出了輪廓,也不知道哪一層的哪些節點,抽象出了實體。總而言之,CNN的網絡結構是個迷,無法明確地解釋網絡結構隱藏的工作過程的細節。
無法解釋工作過程的細節,也就談不上人為干預。如果CNN出了問題,只好重新訓練。但重新訓練后的結果,是否能達到期待的效果,無法事先語料。往往按下葫蘆浮起瓢,解決了這個缺陷,卻引發了其它缺陷。
反過來說,如果能明確地搞清楚CNN工作過程的細節,就可以有針對性地調整個別層次的個別節點的參數,事先人為精準干預。
二、小樣本學習
深度學習依賴訓練數據,訓練數據的規模通常很大,少則幾萬,多大幾百萬。從哪里收集這么多訓練數據,需要組織多少人力去對訓練數據進行標注,都是巨大挑戰。
如果對深度學習的過程細節,有更清晰的了解,我們就可以改善卷積這種蠻力的做法,用更少的訓練數據,訓練更輕巧的深度學習模型。
卷積的過程,是蠻力的過程,它對相鄰的點,無一遺漏地不分青紅皂白地進行卷積處理。
如果我們對點與點之間的關聯關系,有更明確的了解,就不需要對相鄰的點,無一遺漏地不分青紅皂白地進行卷積處理。只需要對有關聯的點,進行卷積或者其它處理。
根據點與點之間的關聯關系,構建出來的網絡,就是廣義圖譜。廣義圖譜的結構,通常比CNN網絡更加簡單,所以,需要的訓練數據量也更少。
三、遷移學習和推理
用當今的CNN,可以從大量圖片中,識別某種實體,譬如貓。
但是,如果想給識別貓的CNN擴大能力,讓它不僅能識別貓,還能識別狗,就需要額外的識別狗的訓練數據。這是遷移學習的過程。
能不能不提供額外的識別狗的訓練數據,而只是用規則這樣的方式,告訴電腦貓與狗的區別,然后讓電腦識別狗?這是推理的目標。
如果對深度學習過程有更精準的了解,就能把知識和規則,融進深度學習。
從廣義范圍說,深度學習和知識圖譜,是機器學習陣營中諸多學派的兩大主流學派。迄今為止,這兩大學派隔岸叫陣,各有勝負。如何融合兩大學派,取長補短,是困擾學界很久的難題。把深度學習延伸到圖譜處理,給兩大學派的融合,帶來了希望。
四、空間和時間的融合,像素與語義的融合
視頻處理,可以說是深度學習的最高境界。
視頻處理融合了圖像的空間分割,圖像中實體的識別,實體對應的語義理解。
多幀靜態圖像串連在一起形成視頻,實際上是時間序列。同一個實體,在不同幀中所處的位置,蘊含著實體的運動。運動的背后,是物理定律和語義關聯。
如何從一段視頻,總結出文本標題。或者反過來,如何根據一句文本標題,找到最貼切的視頻。這是視頻處理的經典任務,也是難度超大的任務。
-
AI
+關注
關注
87文章
30728瀏覽量
268891 -
深度學習
+關注
關注
73文章
5500瀏覽量
121113
原文標題:為什么說圖網絡是 AI 的未來?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
國外科研團隊在X射線科學領域取得了重大突破
谷歌量子芯片實現計算領域重大突破
谷歌量子芯片Willow實現重大突破
Anthropic在人工智能領域取得重大突破
FPGA做深度學習能走多遠?
中國芯片制造關鍵技術取得重大突破,預計一年內實現應用落地
NVIDIA攜手聯發科,G-Sync技術獲重大突破
努比亞發布自主研發的星云大模型,在AI技術領域又一重大突破
我國科學家實現激光雷達系統研制重大突破

百度WAVE SUMMIT深度學習開發者大會,文心大模型4.0 Turbo震撼發布
據新華社等多家媒體報道!暢能達科技實現散熱技術重大突破!
深度解析深度學習下的語義SLAM

重大突破│捷杰傳感APEF自適應算法將設備健康監測誤報率和漏報率降低92.8%!






 工商網監
工商網監
評論