

ICLR-17最佳論文《理解深度學習需要重新思考泛化》曾引發學界熱議。現作者張馳原和Samy Bengio等再出新作,指出神經網絡每個層并非“生而平等”,進一步拓展對神經網絡泛化的理解。
今天新智元要介紹的論文是ICLR 2017最佳論文獎得主、《理解深度學習需要重新思考泛化》的作者張弛原和Samy Bengio等人的新作:
神經網絡的各個層生而平等嗎?(Are All Layers Created Equal?)

張弛原、Samy Bengio等人新作:神經網絡各個層生而平等嗎?
在ICLR 2017那篇“重新思考泛化”的文章中,張馳原等人得出結論認為,只要參數的數量超過實踐中通常的數據點的數量,即便是簡單的層數為2的神經網絡,就已經具有完美的有限樣本表現力(finite sample expressivity)。
而在這篇新的論文中,張弛原等人繼續探討深度神經網絡的泛化能力,深入到“層”的級別,并指出在研究深度模型時,僅關注參數或范數(norm)的數量是遠遠不夠的。
研究深度模型時,只考慮參數和范數的數量是不夠的
理解深層架構的學習和泛化能力是近年來一個重要的研究目標,《理解深度學習需要重新思考泛化》發表后在學界卷起了一股風暴,有人甚至稱其為“勢必顛覆我們對深度學習理解”。

ICLR 2017最佳論文《理解深度學習需要重新思考泛化》
ICLR 2017那篇文章指出,傳統方法無法解釋大規模神經網絡在實踐中泛化性能好的原因,并提出了兩個新的定義——“顯示正則化”和“隱示正則化”來討論深度學習。
作者通過在CIFAR10和ImageNet的幾個不同實驗發現:
神經網絡的有效容量對于整個數據集的暴力記憶是足夠大的;
對隨機標簽進行優化的過程很容易。與對真實標簽的訓練相比,隨機標簽的訓練時間只增加了一個小的恒定因子;
對標簽進行隨機化只是一種數據變換,神經網絡要學習的問題的所有其他屬性不變。
更準確地說,當對真實數據的完全隨機標記進行訓練時,神經網絡實現了零訓練誤差——當然,測試誤差并不比隨機概率好,因為訓練標簽和測試標簽之間沒有相關性。
換句話說,通過單獨使標簽隨機化,我們可以迫使模型的泛化能力顯著提升,而不改變模型、大小、超參數或優化器。
這一次,論文又提出了兩個新的概念——(訓練后)“重新初始化”和“重新隨機化魯棒性”,并認為神經網絡的層可以分為“關鍵層”和“魯棒層”;與關鍵層相比,將魯棒層重置為其初始值沒有負面影響,而且在許多情況下,魯棒層在整個訓練過程中幾乎沒有變化。
作者根據經驗研究了過度參數化深度模型的分層功能結構,為神經網絡層的異構特征提供了證據。
再次思考神經網絡泛化:各個層并非“生而平等”
深度神經網絡在現實世界的機器學習實例中已經得到了非常成功的應用。在將這一系統應用于許多關鍵領域時,對系統的深層理解至少與其最先進的性能同樣重要。最近,關于理解為什么深度網絡在實踐中表現優異的研究主要集中在網絡在漂移下的表現,甚至是數據分布等問題上。
與此類研究相關的另一個有趣的研究是,我們如何解釋并理解受過訓練的網絡的決策函數。雖然本文的研究問題與此相關,但采取了不同的角度,我們主要關注網絡層在受過訓練的網絡中的作用,然后將經驗結果與泛化、魯棒性等屬性聯系起來。
本文對神經網絡表達力的理論進行了深入研究。眾所周知,具有足夠寬的單個隱藏層的神經網絡是緊湊域上的連續函數的通用逼近器。
最近的研究進一步探討了深度網絡的表達能力,是否真的優于具有相同數量的單元或邊緣的淺層網絡。同時,也廣泛討論了用有限數量的樣本表示任意函數的能力。
然而,在上述用于構建近似于特定功能的網絡的研究中,使用的網絡結構通常是“人工的”,且不太可能通過基于梯度的學習算法獲得。我們重點關注的是實證深層網絡架構中不同網絡層發揮的作用,網絡采用基于梯度的訓練。
深度神經網絡的泛化研究引起了很多人的興趣。由于大神經網絡無法在訓練集上實現隨機標記,這使得在假設空間上基于均勻收斂來應用經典學習的理論結果變得困難。
本文提供了進一步的經驗證據,并進行了可能更細致的分析。尤其是,我們憑經驗表明,深層網絡中的層在表示預測函數時所起的作用并不均等。某些層對于產生良好的預測結果至關重要,而其他層對于在訓練中分配其參數則具備相當高的魯棒性。
此外,取決于網絡的容量和目標函數的不同復雜度,基于梯度的訓練網絡可以不使用過剩容量來保持網絡的復雜度。本文討論了對“泛化“這一概念的確切定義和涵蓋范圍。
全連接層(FCN)
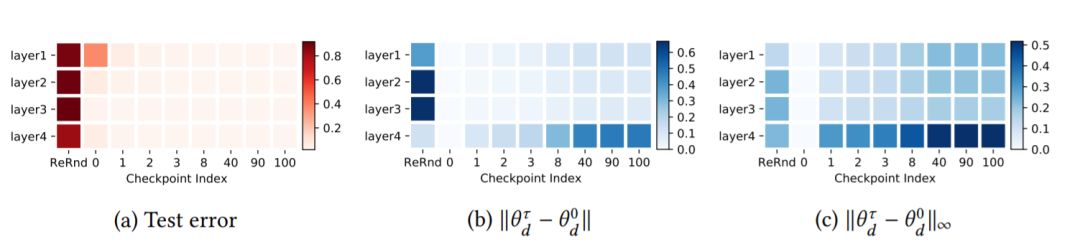
圖1:MNIST數據集上FCN 3×256的魯棒性結果。(a)測試錯誤率:圖中每行對應于網絡中的每一層。第一列指定每個層的魯棒性w.r.t重新隨機化,其余列指定不同檢查點的重新初始化魯棒性。最后一列為最終性能(在訓練期間設置的最后一個檢查點)作為參考。(b-c)權重距離:熱圖中的每個單元表示訓練參數與其初始權重的標準化2范數(b)或∞范數(c)距離
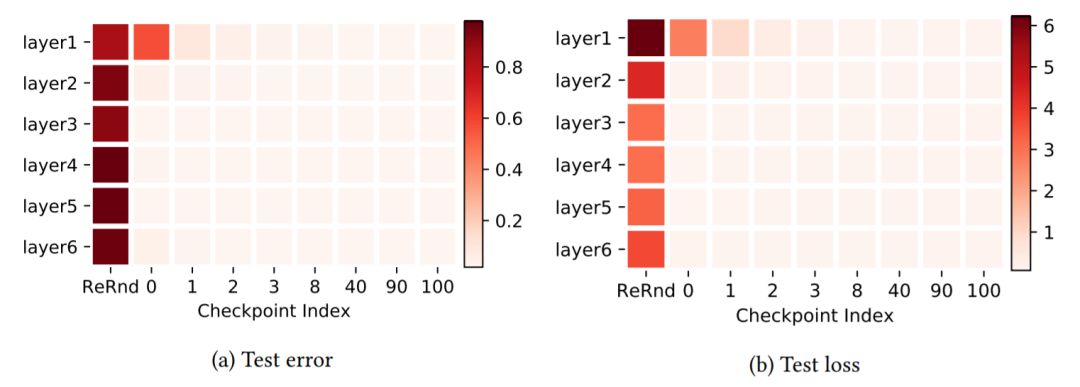
圖2:MNIST數據集上FCN 5×256的層魯棒性研究。兩個子圖使用與圖1(a)相同的布局。兩個子圖分別表示在測試錯誤(默認值)和測試損失中評估的魯棒性
大規模卷積網絡(CNN)
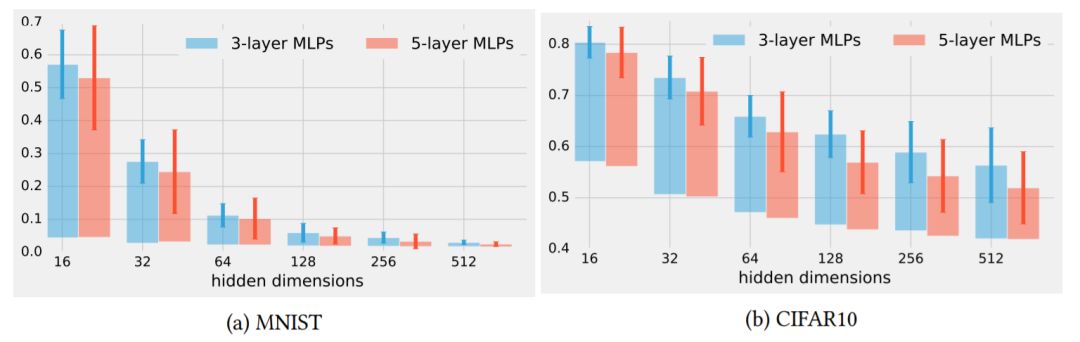
圖3:重新初始化所有層的魯棒性,但第一次使用檢查點0用于不同維度的隱藏層的FCN。每個條形表示完全訓練后的模型有具有一層重新初始化的模型之間的分類誤差的差異。誤差條表示通過使用不同的隨機初始化運行實驗得到的一個標準偏差。
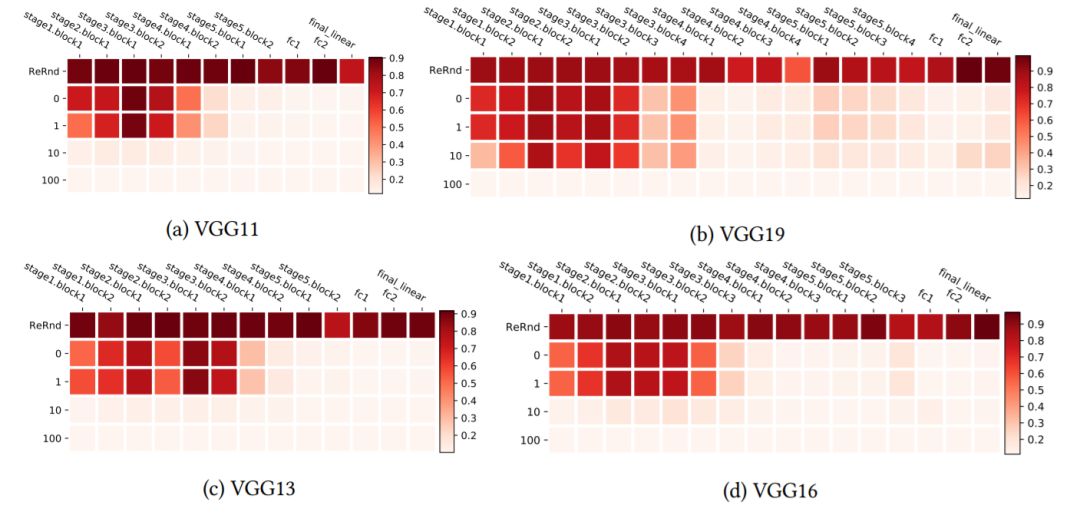
圖4:使用CIFAR10上的VGG網絡進行分層魯棒性分析。熱圖使用與圖1中相同的布局,但加以轉置,以便更有效地對更深層的架構進行可視化。
殘差網絡(ResNets)
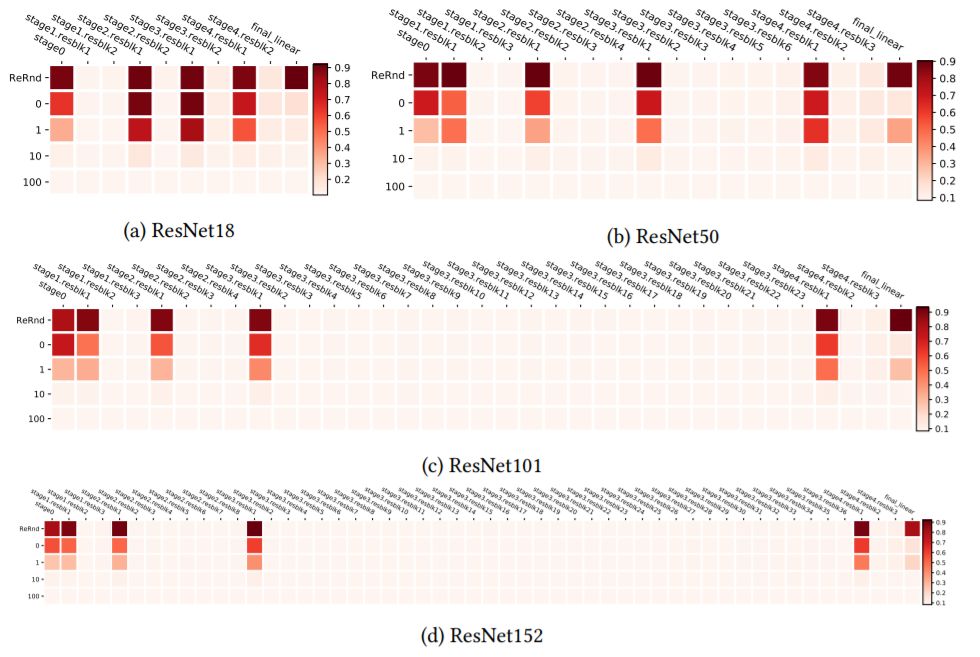
圖5:在CIFAR10上訓練的ResNets殘差塊的分層魯棒性分析。

圖6:在ImageNet上訓練的ResNets殘差塊的分層魯棒性分析

圖7:采用/不采用下采樣跳過分支的殘余塊(來自ResNets V2)。C,N和R分別代表卷積、(批量)歸一化和ReLU激活
網絡層的聯合魯棒性

圖8:MNIST上FCN 5×256的聯合魯棒性分析。布局與圖1中的相同,但是圖層分為兩組(每個圖層中圖層名稱上的*標記表示),對每組中的所有圖層全部應用重新隨機化和重新初始化。

圖9:CIFAR10上ResNets的聯合魯棒性分析,基于對所有剩余階段中除第一個殘余塊之外的所有剩余塊進行分組的方案。分組由圖層名稱上的*表示。
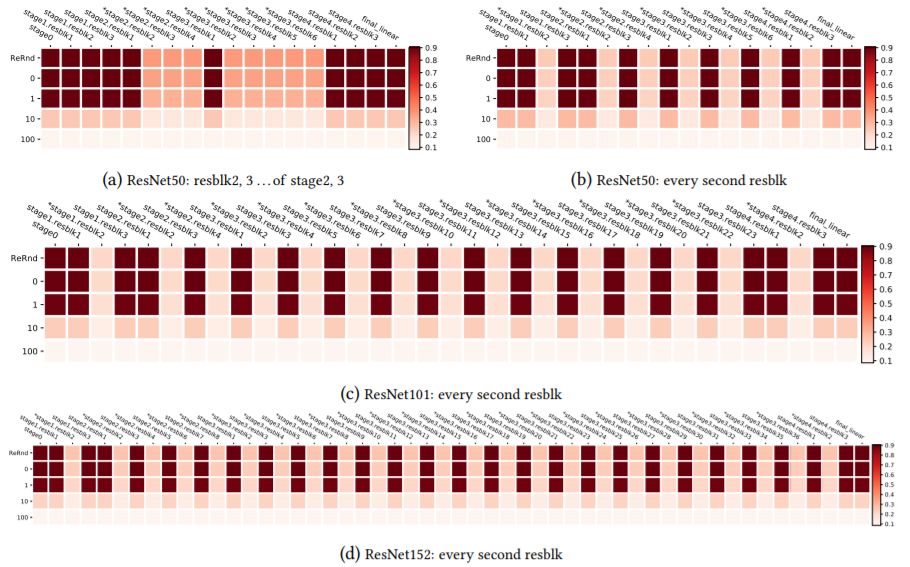
圖10:CIFAR10上ResNets的聯合魯棒性分析,以及其他分組方案。分組由圖層名稱上的*表示
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102909 -
網絡架構
+關注
關注
1文章
96瀏覽量
12850 -
深度學習
+關注
關注
73文章
5555瀏覽量
122529
原文標題:ICLR-17最佳論文一作張弛原新作:神經網絡層并非“生而平等”
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
ICLR 2019論文解讀:深度學習應用于復雜系統控制

谷歌工程師機器學習干貨:從表現力、可訓練性和泛化三方面詳解
探索機器“視覺”演進的無限可能性 Qualcomm AI研究人員獲得ICLR殊榮
ICLR 2019在官網公布了最佳論文獎!

ICLR 2019最佳論文日前揭曉 微軟與麻省等獲最佳論文獎項
谷歌發表論文EfficientNet 重新思考CNN模型縮放

自監督學習與Transformer相關論文
如何理解泛化是深度學習領域尚未解決的基礎問題







 工商網監
工商網監

評論