


1
概述
全球運營商相繼發布網絡演進和轉型戰略,希望能夠通過引入 SDN/NFV、云計算、區塊鏈、5G 等新技術,減少對專有硬件的依賴,實現新業務的快速部署,滿足用戶多樣化的需求,提升核心競爭力。但在轉型過程中通信運營商面臨著多種挑戰,一方面是聯網設備數量快速增長以及設備之間溝通產生的數據洪流,另一方面是隨著電信網絡設備日趨虛擬化、自動化和智能化,網絡復雜度指數型增長。這些挑戰無疑使網絡運維變得日益繁雜和困難,運維人員一方面必須面對各種高度集成設備產生的大量實時信息,另一方面需要處理海量的告警數據,并且為了不降低用戶感知,需要快速解決問題。現有的系統已經無法在異常狀況發生時為運維人員提供足夠的支持,導致許多問題不能被及時發現而不斷傳播升級,直至影響所有業務。如果發生異常告警時需要花費大量時間去尋找問題根源及解決辦法,那么即使是細微的問題也會迅速地升級擴大。
人工智能(AI)的發展可追溯到 1956 年達特茅斯會議(Dartmouth Conference)[1]。人工智能可以定義為機器能夠實現的智能,是與人類和其他動物表現出的人類智能和自然智能相對的概念。也可引用“人工智能之父”Marvin Minsky對人工智能的理解來定義它—“人工智能就是讓機器來完成那些如果由人來做則需要智能的事情的科學”。網絡人工智能(Network AI)[2]是將人工智能技術應用在網絡中,使用機器替代或優化目前依靠人工進行的工作,使運營商能夠更加便捷地提供更加優質的網絡服務。
本文以人工智能技術為基礎,結合現有網絡運維技術,提出故障溯源整體解決方案。希望通過對告警信息進行合適的過濾、篩選、匹配、分類等流程確認告警信息,并根據各個告警之間的關系來進行告警溯源,屏蔽不重要或衍生的告警,實現對網絡故障的快速診斷。同時配合相應的通信業務模型和網絡拓撲結構實現故障的精準定位。最后通過實踐中的具體案例分析,給出人工智能應用于網絡故障溯源的結論和展望。
2
國內外研究現狀
著名的 IT研究與顧問咨詢公司 Gartner在 2016年提出 AIOps(Artificial Intelligence for IT Operations)的概念[3],即通過人工智能的方式來支撐現在日益復雜的運維工作。AIOps 可以在深度集成 DevOps 工具鏈的基礎上獲取系統數據,然后通過機器學習算法進行數據分析,更深度地解析數據中所蘊藏的運維信息。Gartner的報告指出預計到2020年,50%的企業將會在他們的業務和 IT 運維方面采用 AIOps,遠超現在的10%。同時,國內外各大公司如AT&T、Microsoft、Facebook、百度、阿里巴巴等都在他們的運維系統中實驗或部署了機器學習算法,助力某些運維任務智能化。
華為諾亞方舟實驗室開發了智能故障診斷系統,利用網絡故障的歷史記錄數據自動構建通信領域知識圖譜[4],并在知識圖譜上進行概率推理,以自動問答的形式幫助工程師找出故障的根本原因。微軟分別在會議NSDI’09和SIGCOMM’16發表了2篇基于機器學習的故障檢測系統的論文[5-6]。其中,2009 年發表的論文中提到針對家庭網絡配置問題診斷的NetPrints系統。該系統通過學習明確針對應用的正確配置,在用戶的某個應用發生錯誤時,可以通過檢測用戶的配置來為用戶選擇一個最小代價的調整策略恢復應用工作。同時,由于系統的特殊設計,一些系統原本無法解決的問題可以通過用戶的協作更新到診斷系統中,實現了用戶間的知識共享,提高系統的可用性。
2016年微軟發表的論文中提到針對微軟數據中心的錯誤定位問題的 NetPoirot 系統。該系統僅通過觀察主機側的 TCP數據就可以定位故障的發生位置,并且對于未訓練過的錯誤也具有很高的故障位置識別率。但是,該系統只能診斷發生在主機、網絡或服務器中的錯誤,無法精確地定位到設備也很難精確定位具體錯誤。針對移動設備的視頻傳輸問題,加泰羅尼亞理工大學的研究者在 2015 年的 CoNEXT 上提出了解決方案[7]。該方案通過收集和處理服務中部分位置的設備數據,可實現視頻流QoE的預測和故障定位。
3
故障溯源相關應用場景研究
結合電信網絡的實際業務場景,剖析運維過程中的實際問題,更有益于將最新的AI技術運用到電信網絡的運維和故障溯源中去,從而提升運維人員的運維效率和運維體驗。目前典型的業務場景有以下幾個。
3.1 場景1:瞬斷告警
瞬斷告警定義為告警的發生時間和清除時間很短,小于一定的閾值。這類告警因為生命周期比較短,對運維人員沒有太大的價值,而且會導致告警量激增,從而掩蓋真正需要關注的告警,增加運維人員識別難度。
3.2 場景2:頻發告警
如果一定時間內發生的相同告警/事件達到一定的數目,可以認為這些告警/事件之間存在一定的相關性。通過設置告警/事件頻次分析規則,當某一段時間內發生的設定告警/事件的數目超過了預先設置的閾值,則認為這些告警/事件之間存在相關性。如同一網元同一單板的單板溫度過高或過低告警X分鐘出現Y次,合并生成一條新告警,說明單板溫度異常。
3.3 場景3:同網元內故障影響分析
指同一網元內某物理對象(單板、拓撲)上產生告警會導致該網元上其他物理對象和邏輯對象產生關聯告警。
對于LTE設備,基站內單板之間以及單板和小區(邏輯對象)存在關聯特性,因此單板故障往往會導致小區也存在異常。如圖1所示,4槽BPN出現“光模塊不可用告警”時,會導致51號RRU產生“RRU 斷鏈告警”,而承載在該RRU上的小區也會上報“LTE小區退服告警”,即“光模塊不可用告警”為根告警。
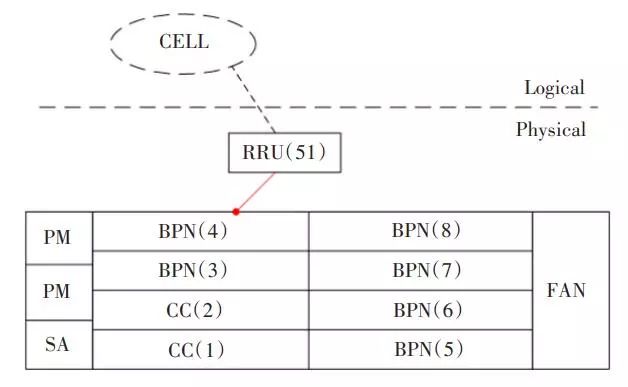
▲圖1 某同網元內故障示意圖
3.4 場景4:同專業網上下層業務故障影響分析
該場景體現為因為某一個故障導致大面積告警的現象,需要快速地獲取故障原因。如圖2所示,服務層告警會導致客戶層告警的發生,如光纖出現斷點,光纖所在端口會報LOS告警,導致上層的 TMS、隧道、偽線、業務都上報告警,此時光纖所在端口的LOS告警就是根告警。
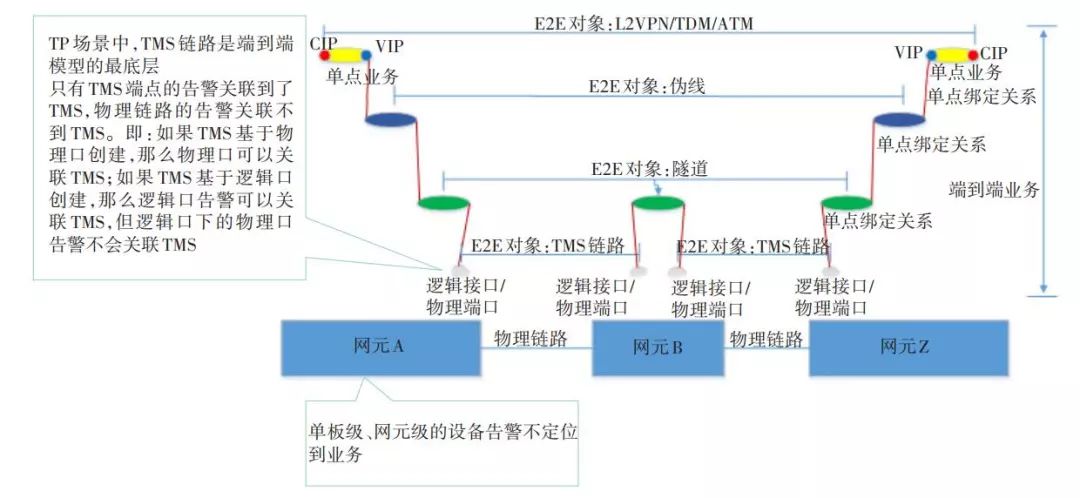
▲圖2 某同專業網上下層業務故障示意圖
3.5 場景5:跨專業網告警分析
傳輸包括光傳輸和微波傳輸,光傳輸節點會下掛很多微波節點,當一個鏈路中斷會影響這條鏈路上的1個或多個站點,光傳輸節點斷開導致所有下游的微波 BTS站點都會退服,中間微波某一跳斷也會導致下游所有BTS退服(見圖3)。
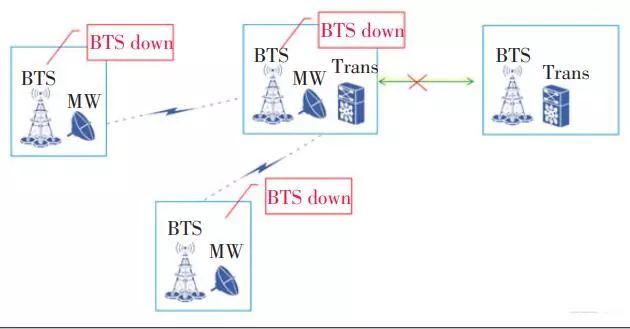
▲圖3 某跨專業網故障示意圖
3.6 場景6:綜合故障診斷
故障的表現具有多樣性,可能表現為告警、KPI異常或單純業務不通,很多情況下告警并不能反映所有的故障點,所以也無法僅通過告警分析來定位故障。
比如網絡升級后,某LTE業務不通,如圖4所示的流程,根據經驗,查看監控數據,進行各種診斷動作和配置檢查,從而定位故障點,告警只是分析的一部分。
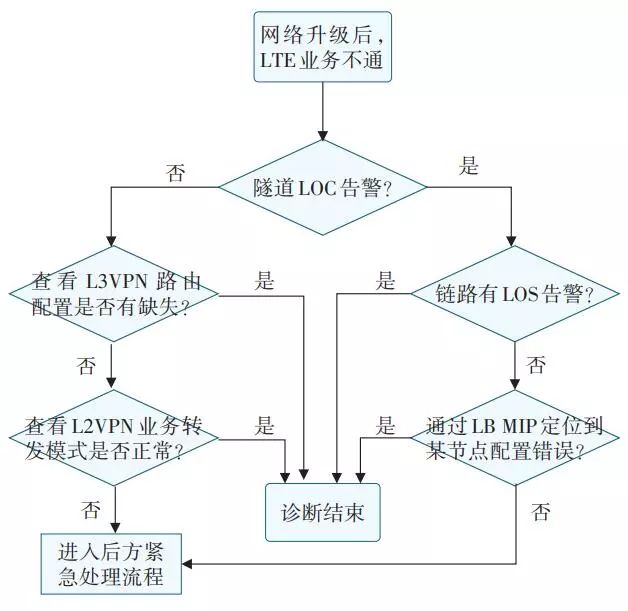
▲圖4 某綜合故障分析過程流程圖
4
通信網絡故障溯源整體解決方案研究
第3章所述業務場景要解決的問題就是如何智能地識別故障并做有效分析,故障分析模型是基于關聯規則,而關聯規則通常使用關聯分析算法得到。
關聯規則算法是從一個數據集中發現項與項之間的隱藏關系。只有從多個不同的維度分析告警數據,才能識別出它們之間的關聯關系,如告警發生的模式或規律。
基于人工智能的故障診斷和溯源就是在結合大數據關聯規則分析及人工智能技術的基礎上,根據系統中的網絡、業務上下游關系,綜合所有監控數據(包括告警、性能)、操作日志以及故障解決歷史記錄,輸出故障特征與故障原因之間的一系列規則。本方案旨在采用人工智能和大數據挖掘技術,研究開發智能故障診斷系統(見圖 5)。在實際網絡運維中,根據故障特征自動匹配診斷規則進行診斷,自動得出故障點及相關處理建議。
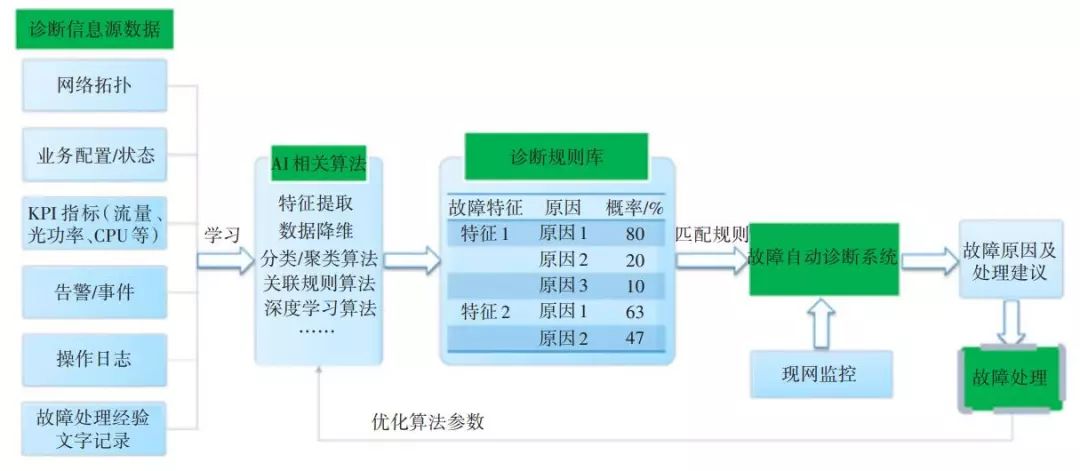
▲圖5 智能故障診斷系統示意圖
本文所提出的智能故障診斷系統要先基于AI學習生成診斷規則庫,然后根據規則進行故障分析。
4.1 基于AI學習生成診斷規則庫
4.1.1 診斷信息獲取
診斷信息越豐富,診斷效果越好,所以系統應具有自動獲取整個周期(當前、歷史)的網絡狀態信息的功能。即在現網運行中,除了記錄操作日志、告警、KPI、故障處理建議這種日常監控數據外,對于網絡拓撲、業務配置、業務狀態這些只記錄當前狀態的數據,也要定時采樣,作為學習的素材。
4.1.2 建立自學習能力
提取故障特征,比如PWE3-CES的包丟失表示2G業務不通,分析其附近的KPI、操作日志、丟包情況、業務配置,業務狀態等信息,獲取故障特征。此處可使用數據降維,分類算法。
根據故障產生與消失這段時間的操作日志、故障文字記錄、其他告警的產生消失情況等相關數據,分析原因。此處可使用關聯算法、深度學習算法。
分析足夠多的案例,得到所有可能的原因,并計算原因概率。此處可使用概率論的相關算法。
4.2 診斷規則的運行
現網監控:實時監控告警,并且對流量、丟包情況定時采樣,并記錄操作日志。
匹配故障特征,進行故障診斷:對現網監控數據實時進行匹配,一旦匹配成功,立即開始診斷。將故障的原因按概率從大到小排序,逐個診斷,當確認某個原因存在時,就可以定位故障并給出處理建議。
故障修復確認,反向修正診斷規則庫:故障在自動恢復或派單修復后,反饋派單中原因是否有效,修正診斷規則庫的原因概率。
相比傳統的故障溯源方案,本方案結合運維中的多種數據源,包括并不限于告警、性能、拓撲資源、日志以及偵測命令,這使本方案溯源結果更加精確,并且更具有可參考性。
5
中國聯通IPRAN告警智能化分析識別
5.1 案例背景和目的
IPRAN網絡主要用于承載3G/4G移動業務以及大客戶專線業務,主要采用IP/MPLS動態協議技術。IP RAN網絡協議以及網絡的邏輯連接的復雜性,使IPRAN網管系統每天接收到大量的設備告警消息,其中很多告警信息都是由根源告警信息引起。
目前處理告警數據的相關規則多依賴于專家經驗,通過規則過濾掉不關鍵的告警信息。這種方法的缺點是過濾能力有限且有些規則無法被發現。
因此需要將人工智能技術應用于IPRAN網絡告警根因溯源中,形成更高效的告警處理方法。
5.2 方案和效果分析
故障是產生告警的根本原因,當網絡發生故障時,將產生大量告警,挖掘告警之間的關聯規則對故障定位有著重要意義。總體方案思路如圖6所示。
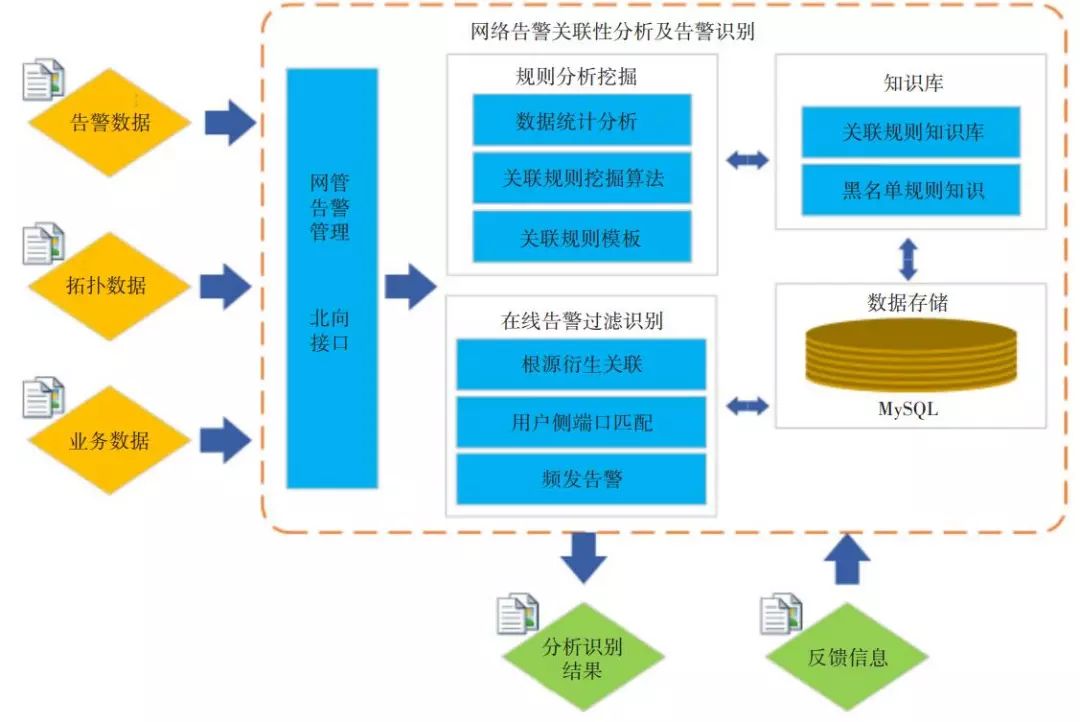
▲ 圖6 告警根因溯源技術方案流程圖
該方案流程總體可分為以下4個步驟。
a)數據預處理階段,包括數據導入和清洗、用戶端側告警匹配、頻發告警識別。輸入數據為現網提取的歷史告警數據、網絡拓撲數據和業務數據3種,經過清洗和整合轉變為可處理的數據格式。用戶端側告警匹配是根據以往運維經驗去除不關心/無價值的告警。頻發告警的具體描述見第3章中的場景2定義,該類告警的處理方式為對同一端口上連續10s內的相同告警進行壓縮,僅留下頻發告警的第1條告警,其他均標識為可過濾告警。
b)關聯規則挖掘階段,該部分核心算法為 Prefix-Span時間序列模式挖掘算法[8]。與Apriori、序列模式、時空模式等挖掘算法相比,該算法更適合本案例。但傳統的 PrefixSpan 算法挖掘出來的規則不帶有約束條件,導致專家也無法判斷關聯規則的正確性,如規則A[光模塊不可用告警→ RRU 斷鏈告警]。為解決該問題,改進了 PrefixSpan算法,這使其挖掘過程存在約束條件。此時規則A改進為[光模塊不可用告警→ RRU斷鏈告警,同網元],提升了算法規則挖掘的精確度。
c)關聯規則確認與入庫,其中包括已確認關聯規則庫和黑名單。通過多位專家確認上一步中挖掘出來的告警關聯規則,將正確的規則存入已確認關聯規則庫中,以支撐下一步的告警識別工作。錯誤和不合理的規則自動導入黑名單,防止下次挖掘出同類規則。
d)根告警識別階段,即給每個告警分別打上根告警、衍生告警、普通告警3種標簽。根據8類不同約束條件對當前告警進行識別處理,約束條件分別為同一端口、同一網元、對應業務網元、同一業務ID關聯、直連對端網元、直連對端端口、同環網元、對應業務ID關聯。
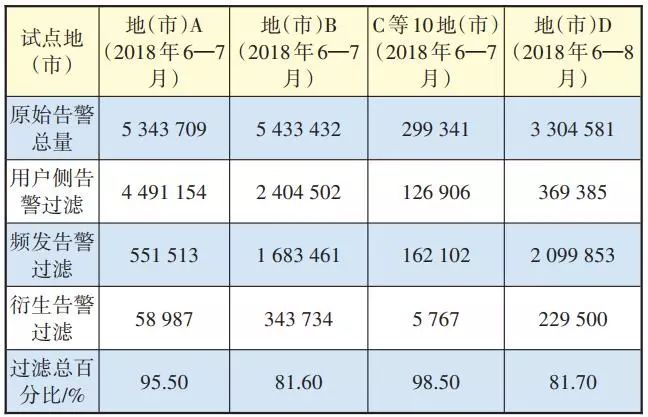
由于廠商和地域的差異性,目前還無法建立統一適用的關聯規則數據庫。現已建立了A設備商IPRAN的告警關聯規則知識庫,共計198條規則。通過已建立的知識庫,在多個城市進行了試點,表1為相關告警分析的結果。
從表1中可以看到B市和D市處理效果較差,冗余告警(用戶側、頻發、衍生)過濾百分比為81%左右,C市和A市結果較好,最高可達98%。產生該結果的原因有2方面:一是由于告警總數不同,其中無關聯的普通告警數量也不同;二是地域的差異性,B市和D市的傳輸網絡設備更多,無法根據人工規則去除無關告警。
表1 多個試點城市的歷史網絡告警分析處理結果
為了更直觀查看告警之間存在的拓撲及業務關聯關系,系統可根據分析結果自動呈現告警關聯分析拓撲圖,通過不同顏色標記網元以區分根告警和衍生告警,并可通過查看歷史告警、網元、端口等信息,輔助支撐運維人員更準確地定位故障、精準派單。
6
總結和展望
通過案例分析可以看出將人工智能技術引用到網絡運維的故障溯源場景中是可行且有效的,基于運維數據智能化地識別告警之間的關聯規則,解決了人工經驗積累不足的問題,提升了運維效率。但現階段仍存在一些問題,由于目前采用的是單一的數據挖掘算法,需要人工判斷關聯規則和結果是否正確,準確率和實時性仍無法保障,并未做到真正的智能。
為解決單一人工智能方法的不足,未來可采用多種診斷技術協同的新模式,即多智能體技術。基于多種具備不同功能的軟件系統,將復雜的網絡告警分解成單一、獨立的成分和因素,各個系統協同合作,能整合包括網絡狀態信息、硬件信息、工單信息等更多的數據,實現自主學習、自主訓練,不斷提升系統性能,全面關聯網絡告警,準確定位網絡故障。
-
人工智能
+關注
關注
1806文章
48987瀏覽量
249003 -
通信網絡
+關注
關注
22文章
2076瀏覽量
52964
原文標題:人工智能在通信網絡故障溯源的應用研究
文章出處:【微信號:C114-weixin,微信公眾號:C114通信網】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
光通信網絡故障排除技巧
人工智能在未來戰爭中占主導地位?
網絡故障排除基本指南
DolphinDB 登陸倫敦!攜手中英人工智能協會共話 AI 未來






 工商網監
工商網監

評論