 探討深度文本分類之DPCNN原理與代碼
探討深度文本分類之DPCNN原理與代碼
01
導讀
ACL2017 年中,騰訊 AI-lab 提出了Deep Pyramid Convolutional Neural Networks for Text Categorization(DPCNN)。
論文中提出了一種基于 word-level 級別的網絡-DPCNN,由于 TextCNN不能通過卷積獲得文本的長距離依賴關系,而論文中 DPCNN 通過不斷加深網絡,可以抽取長距離的文本依賴關系。
實驗證明在不增加太多計算成本的情況下,增加網絡深度就可以獲得最佳的準確率。?
02
DPCNN 結構
究竟是多么牛逼的網絡呢?我們下面來窺探一下模型的芳容。
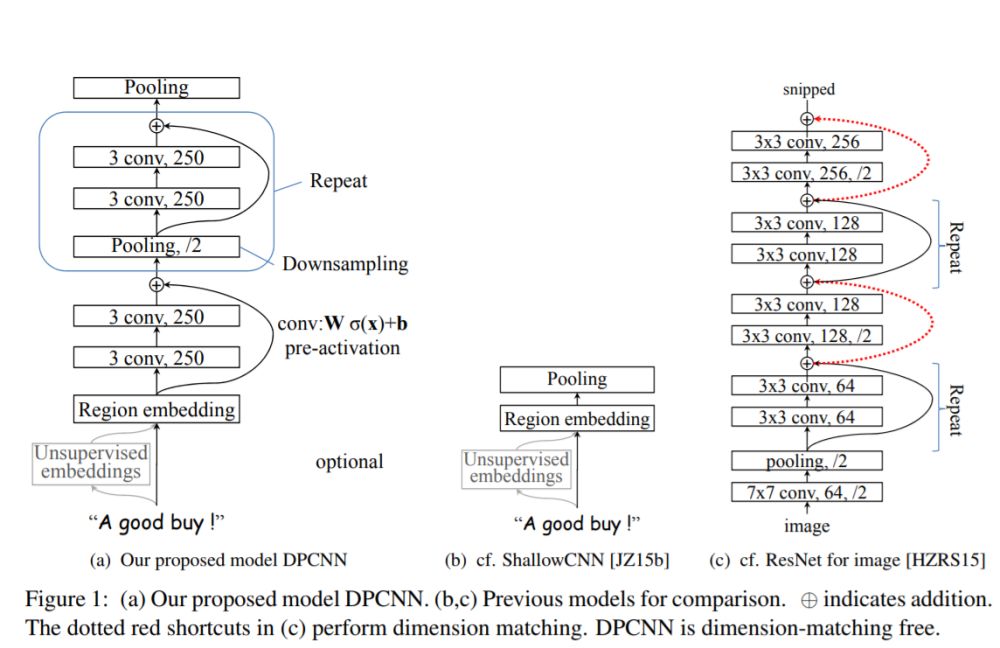
03
DPCNN 結構細節
模型是如何通過加深網絡來捕捉文本的長距離依賴關系的呢?下面我們來一一道來。為了更加簡單的解釋 DPCNN,這里我先不解釋是什么是 Region embedding,我們先把它當作 wordembedding。
等長卷積
首先交代一下卷積的的一個基本概念。一般常用的卷積有以下三類:
假設輸入的序列長度為n,卷積核大小為m,步長(stride)為s,輸入序列兩端各填補p個零(zero padding),那么該卷積層的輸出序列為(n-m+2p)/s+1。
(1)窄卷積(narrow convolution):步長s=1,兩端不補零,即p=0,卷積后輸出長度為n-m+1。
(2)寬卷積(wide onvolution):步長s=1,兩端補零p=m-1,卷積后輸出長度n+m-1。
(3)等長卷積(equal-width convolution):步長s=1,兩端補零p=(m-1)/2,卷積后輸出長度為n。如下圖所示,左右兩端同時補零p=1,s=3。
池化
那么DPCNN是如何捕捉長距離依賴的呢?這里我直接引用文章的小標題——Downsampling with the number of featuremaps fixed。
作者選擇了適當的兩層等長卷積來提高詞位 embedding 的表示的豐富性。然后接下來就開始Downsampling(池化)。
再每一個卷積塊(兩層的等長卷積)后,使用一個 size=3 和 stride=2 進行 maxpooling 進行池化。序列的長度就被壓縮成了原來的一半。其能夠感知到的文本片段就比之前長了一倍。
例如之前是只能感知3個詞位長度的信息,經過1/2池化層后就能感知6個詞位長度的信息啦,這時把 1/2 池化層和 size=3 的卷積層組合起來如圖所示。
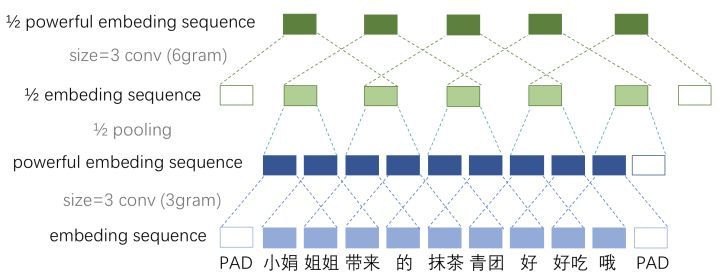
固定 feature maps(filters) 的數量
為什么要固定feature maps的數量呢?許多模型每當執行池化操作時,增加feature maps的數量,導致總計算復雜度是深度的函數。與此相反,作者對 feature map 的數量進行了修正,他們實驗發現增加 feature map 的數量只會大大增加計算時間,而沒有提高精度。
另外,夕小瑤小姐姐在知乎也詳細的解釋了為什么要固定featuremaps的數量。有興趣的可以去知乎搜一搜,講的非常透徹。
固定了 feature map 的數量,每當使用一個size=3和stride=2進行maxpooling進行池化時,每個卷積層的計算時間減半(數據大小減半),從而形成一個金字塔。
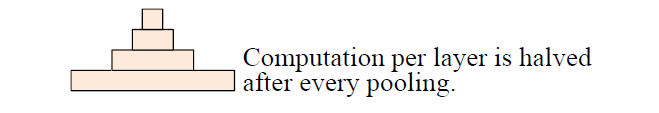
這就是論文題目所謂的Pyramid。
好啦,看似問題都解決了,目標成功達成。剩下的我們就只需要重復的進行等長卷積+等長卷積+使用一個 size=3 和 stride=2 進行 maxpooling 進行池化就可以啦,DPCNN就可以捕捉文本的長距離依賴啦!
Shortcut connections with pre-activation
但是!如果問題真的這么簡單的話,深度學習就一下子少了超級多的難點了。
(1) 初始化CNN的時,往往各層權重都初始化為很小的值,這導致了最開始的網絡中,后續幾乎每層的輸入都是接近0,這時的網絡輸出沒有意義;
(2) 小權重阻礙了梯度的傳播,使得網絡的初始訓練階段往往要迭代好久才能啟動;
(3)就算網絡啟動完成,由于深度網絡中仿射矩陣(每兩層間的連接邊)近似連乘,訓練過程中網絡也非常容易發生梯度爆炸或彌散問題。
當然,上述這幾點問題本質就是梯度彌散問題。那么如何解決深度 CNN 網絡的梯度彌散問題呢?當然是膜一下何愷明大神,然后把 ResNet 的精華拿來用啦!ResNet 中提出的shortcut-connection/ skip-connection/ residual-connection(殘差連接)就是一種非常簡單、合理、有效的解決方案。
類似地,為了使深度網絡的訓練成為可能,作者為了恒等映射,所以使用加法進行shortcut connections,即z+f(z),其中f用的是兩層的等長卷積。這樣就可以極大的緩解了梯度消失問題。
另外,作者也使用了pre-activation,這個最初在何凱明的 “Identity Mappings in Deep Residual Networks 上提及,有興趣的大家可以看看這個的原理。
直觀上,這種“線性”簡化了深度網絡的訓練,類似于 LSTM 中 constant errorcarousels 的作用。而且實驗證明pre-activation 優于 post-activation。
整體來說,巧妙的結構設計,使得這個模型不需要為了維度匹配問題而擔憂。
Region embedding
同時 DPCNN 的底層貌似保持了跟 TextCNN 一樣的結構,這里作者將 TextCNN 的包含多尺寸卷積濾波器的卷積層的卷積結果稱之為 Region embedding,意思就是對一個文本區域/片段(比如3gram)進行一組卷積操作后生成的embedding。
另外,作者為了進一步提高性能,還使用了tv-embedding (two-views embedding)進一步提高 DPCNN 的 accuracy。
上述介紹了 DPCNN 的整體架構,可見 DPCNN 的架構之精美。本文是在原始論文以及知乎上的一篇文章的基礎上進行整理。
本文可能也會有很多錯誤,如果有錯誤,歡迎大家指出來!建議大家為了更好的理解 DPCNN,看一下原始論文和參考里面的知乎。
04
用 Keras 實現 DPCNN 網絡
這里參考了一下 kaggle 的代碼,模型一共用了七層,模型的參數與論文不太相同。這里濾波器通道個數為64(論文中為256),具體的參數可以參考下面的代碼,部分我寫了注釋。
05
DPCNN 實戰
上面我們用 keras 實現了我們的 DPCNN 網絡,這里我們借助 kaggle 的有毒評論文本分類競賽來實戰下我們的 DPCNN 網絡。
-
網絡
+關注
關注
14文章
7580瀏覽量
88933 -
cnn
+關注
關注
3文章
353瀏覽量
22246
原文標題:一文看懂深度文本分類之 DPCNN 原理與代碼
文章出處:【微信號:AI_Thinker,微信公眾號:人工智能頭條】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
pyhanlp文本分類與情感分析
NLPIR平臺在文本分類方面的技術解析
基于文章標題信息的漢語自動文本分類
基于apiori算法改進的knn文本分類方法
textCNN論文與原理——短文本分類
文本分類的一個大型“真香現場”來了
基于深度神經網絡的文本分類分析

基于不同神經網絡的文本分類方法研究對比
基于LSTM的表示學習-文本分類模型
帶你從頭構建文本分類器
PyTorch文本分類任務的基本流程
人工智能中文本分類的基本原理和關鍵技術





 工商網監
工商網監
評論