") 關于NLP基準數(shù)據(jù)集的快速概覽,以及最新技術的進展
關于NLP基準數(shù)據(jù)集的快速概覽,以及最新技術的進展
本文是一個自然語言處理資源索引,涵蓋了目前NLP領域常用任務的最佳實驗 結果和數(shù)據(jù)集資源,可以作為進一步從事NLP研究的基礎。讀者也可以自行在Github頁面上添加新的結果,本文中大部分為英文NLP資源,還有少數(shù)漢語、印地語和越南語資源。
本文實際上是一個索引,旨在記錄自然語言處理(NLP)領域的新進展,并概述最常見的NLP任務及其相應數(shù)據(jù)集的新技術。
這篇索引旨在涵蓋主要的傳統(tǒng)和核心NLP任務,如語義依賴性解析和詞性標注等,以及最近不斷取得新突破的任務,比如閱讀理解和自然語言推理。本文主要目標是為感興趣的讀者提供關于NLP基準數(shù)據(jù)集的快速概覽,以及最新技術的進展,這些數(shù)據(jù)集和新進展可以作為進一步NLP研究的基礎。
因此,本文有意將這些NLP領域的新研究進展做一個簡單匯總,便于研究人員集中查閱參考。
讀者也可以通過瀏覽器訪問nlpprogress.com或nlpsota.com來閱讀本文。
簡易使用指南
實驗結果
本文首選在已發(fā)表的論文中的實驗結果,但對少數(shù)影響力很大的預印本論文也可能入選。
數(shù)據(jù)集
本文中收錄的數(shù)據(jù)集,除了利用該數(shù)據(jù)集的論文之外,還應經(jīng)過至少一篇已發(fā)表的其他論文的評估。
代碼
我們建議添加指向實現(xiàn)的鏈接(如果可用)。如果代碼不存在,您可以向表中添加代碼列(見下文)。在Code列,建議使用官方實現(xiàn)。如果有非官方實現(xiàn),請使用鏈接(見下文)。如果沒有可用的實現(xiàn),可以將單元格留空。
向本索引中添加新結果
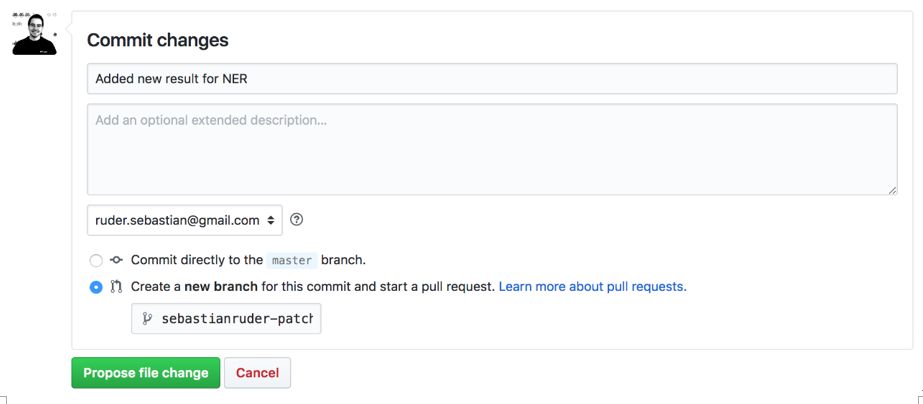
如果要添加新結果,只需單擊文件右上角的小編輯按鈕以執(zhí)行相應任務(如下圖所示)。

讀者可以在Markdown中編輯文件。只需以相同的格式將一行添加到相應的表中即可。確保表格中數(shù)據(jù)排序正確(將最佳結果位于頂部)。完成更改后,單擊頁面頂部的“預覽更改”選項卡,確保表格看起來還不錯。如果一切看起來都OK,請轉到頁面底部確認更改。
此處需要為建議更改添加名稱,可以選擇添加說明文字,可以選擇“創(chuàng)建新分支并啟動拉取請求”,然后單擊“提交更改”。
具體索引內容和研究領域如下,絕大部分為英語,有少量資源為漢語、印地語和越南語。
英語
自動語音識別
CCG超級標準
常識
選區(qū)解析
共同決議
依賴解析
對話
域適應
實體鏈接
語法糾錯
信息提取
語言建模
詞匯規(guī)范化
機器翻譯
多任務學習
多模態(tài)
命名實體識別
自然語言推理
詞性標注
關系預測
關系提取
語義文本相似度
語義解析
語義角色標記
情緒分析
淺語法
簡單化
狀態(tài)檢測
概要
分類學習
時間處理
文字分類
詞義消歧
中文
實體鏈接
中文詞匯分割
印地語
分塊
詞性標注
機器翻譯
越南語
依賴解析
機器翻譯
命名實體識別
詞性標注
分詞
最后以”中文-詞匯分割”子類目為例,簡單說明這個索引資源的呈現(xiàn)方式。
點擊相應鏈接進入,首先是中文詞匯分割這個任務的簡要介紹。

下面列出了不同作者建立的基于不同搜索方式的單詞分割模型,以及相應模型的發(fā)表時間。

接下來是評估指標,此類中為F1分數(shù)。下面以表格形式給出每種模型在不同數(shù)據(jù)集上獲得的最佳F1分數(shù)。每個分數(shù)對應的研究論文鏈接和部分Github資源地址。

可以看到,表中中文詞匯分割模型的最優(yōu)F1分數(shù)均超過了96分,感興趣的讀者可以點擊查看論文或Github資源。
-
數(shù)據(jù)集
+關注
關注
4文章
1208瀏覽量
24727 -
自然語言處理
+關注
關注
1文章
619瀏覽量
13579 -
nlp
+關注
關注
1文章
489瀏覽量
22052
原文標題:盤點NLP最新進展:多語種40+任務最優(yōu)結果任你查
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
如何設計ADC和DAC的基準源,以及基準源如何影響ADC與DAC那些性能?
當今數(shù)據(jù)中心新技術趨勢
康謀分享 | AD/ADAS的性能概覽:在AD/ADAS的開發(fā)與驗證中“大海撈針”!

關于數(shù)據(jù)轉換器的基準電壓選擇和設計提示

【「時間序列與機器學習」閱讀體驗】全書概覽與時間序列概述
nlp神經(jīng)語言和NLP自然語言的區(qū)別和聯(lián)系
nlp自然語言處理的主要任務及技術方法
nlp自然語言處理模型怎么做
NLP技術在機器人中的應用
NLP技術在人工智能領域的重要性
NLP模型中RNN與CNN的選擇
光伏儲能最新技術進展 最新光伏儲能發(fā)電項目有哪些?
宏集Web HMI快速實現(xiàn)PLC數(shù)據(jù)的遠程監(jiān)控






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論