") GPT2.0究竟是做什么的?有哪些優(yōu)勢和不足?未來發(fā)展趨勢如何?
GPT2.0究竟是做什么的?有哪些優(yōu)勢和不足?未來發(fā)展趨勢如何?
最近NLP領域的大事不斷,前幾天GPT2.0的消息幾乎刷屏,作為有望對標谷歌BERT的技術,GPT2.0究竟是做什么的?有哪些優(yōu)勢和不足?未來發(fā)展趨勢如何?本文給出了深入淺出的分析與預測。
最近朋友圈被NLP的技術大新聞刷屏刷得有點多,前幾天(2月15日)中午開始又被GPT 2.0刷屏了,大致看了下新聞大致了解了下思路,覺得好像思路還好,但是看GPT 2.0那個生成的續(xù)寫故事的例子確實嚇了我一跳,這個效果好到出人意料。
我看網上有些有才的朋友評論說:“應該讓GPT去續(xù)寫紅樓夢后40回”,我估計高鶚聽后,正在地下或者天上凝視著說這句話的朋友瑟瑟發(fā)抖(這位有才的朋友,你想到這個場景會瑟瑟發(fā)抖嗎,哈哈),被人批評水平不夠100年,本來就郁悶,結果目前還冒出一個替代者,嘿嘿。
還有的朋友說,也可以讓GPT去把那些挖坑不填坑的垃圾網絡小說作品續(xù)完。我覺得把GPT當作垃圾文學回收站,也是個不錯的主意,但是我想問的是你問過GPT本人的意見嗎?寫小說這種工作,目前NLP技術很明顯還差得遠,不過如果再發(fā)展一步的話,還真有這種可能。
我的預感,未來兩年NLP可能會不斷爆出類似的刷屏新聞,真的進入一個技術快速發(fā)展期。按理說,這是NLP研發(fā)者的黃金期,這種時期最容易出好的成果,但是事實上,很可能你只能作為看熱鬧的看客,眼看他起高樓,眼看他宴賓客,但是別人的紅火與你無關。我想這種心情,昨天估計不敢刷朋友圈怕心靈創(chuàng)傷難以愈合的的單身狗朋友們,他們對這種類似的感受是理解最深的。那么為什么說NLP很可能進入快速發(fā)展期但是與你無關呢?原因我后面會說。
下午有位技術媒體的朋友問我說是不是寫點看法,我覺得貌似從技術上看算是正常進展,所以寫不寫都行,看了論文再決定。結果一直開會開到晚上,回家找來論文仔細看了一看,再結合前幾天媒體廣泛傳播的微軟的MT-DNN 技術,它們之間以及和Bert之間,是有內在聯(lián)系的,所以覺得可以放一起簡單談談看法,于是動手熬夜寫了這篇。本來我春節(jié)期間寫好了三篇推薦系統(tǒng)召回模型系列的文章,想最近先發(fā)一篇的,想了想既然GPT 2.0熱度高,不如蹭個熱度先發(fā)了,召回模型以后再慢慢陸續(xù)發(fā)出來吧。
下面進入正題。
GPT 2.0到底做了什么?
在之前我寫的《從Word Embedding到Bert模型—自然語言處理中的預訓練技術發(fā)展史》(https://zhuanlan.zhihu.com/p/49271699)中:我說GPT有個缺點,就是作者不太會炒作,因為它是個非常扎實的重大NLP進展,出生證日期顯示年齡比Bert大,但是Bert哇哇墜地就引來各界慈愛的目光,和交口稱贊,GPT只能躲在無人角落里暗地淚垂,演繹了算法模型界的真正的同人不同命,冰火兩重天。沒想到時過不到4個月,GPT 2.0就爆紅,被推上打著聚光燈的華美舞臺,驚艷亮相。
炒作能力見長進,其實挺好,好工作其實是應該PR的,這樣能讓更多人跟進真正有價值的工作,而這會更進一步促進領域的進步和發(fā)展,形成正循環(huán)。而不是特別好的工作過度PR,會錯誤地引導大量人力/時間/機器等資源投入到錯誤的方向,這個其實是種資源浪費。
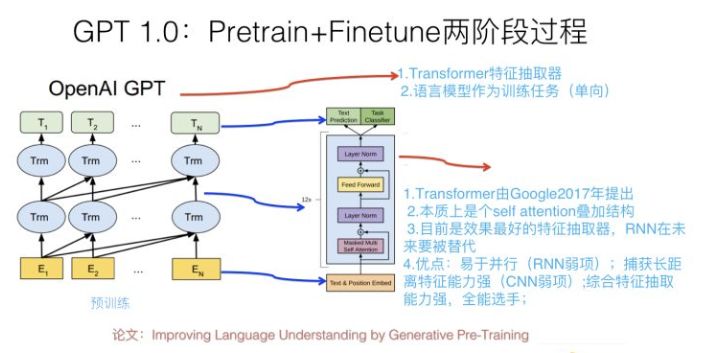
在談GPT 2.0之前,先回顧下它哥GPT 1.0,這個之前我在介紹Bert模型的時候介紹過,過程參考上圖,簡述如下:GPT 1.0采取預訓練+FineTuning兩個階段,它采取Transformer作為特征抽取器。預訓練階段采用“單向語言模型”作為訓練任務,把語言知識編碼到Transformer里。第二階段,在第一階段訓練好的模型基礎上,通過Finetuning來做具體的NLP任務。GPT 1.0本身效果就很好,不過之前說過,因為不會PR,所以默默無聞,直到Bert爆紅后,才被人偶爾提起。從大框架上來說,Bert基本就是GPT 1.0的結構,除了預訓練階段采取的是“雙向語言模型”之外,它們并沒什么本質差異,其它的技術差異都是細枝末節(jié),不影響大局,基本可忽略。
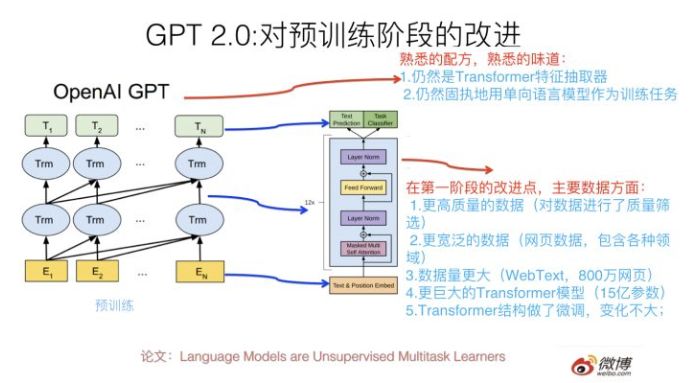
那么GPT 2.0本質上是怎么做的呢?最大的改進是什么?其實幾句話就能說明白,就是上圖寫的內容。
它的大框架其實還是GPT 1.0的框架,但是把第二階段的Finetuning做有監(jiān)督地下游NLP任務,換成了無監(jiān)督地做下游任務,為啥這么做?后面會講。我相信如果你理解GPT 1.0或者Bert,那么是非常容易理解GPT 2.0的創(chuàng)新點在哪里的。
那么它最大的改進在哪里?本質上,GPT2.0選擇了這么一條路來強化Bert或者是強化GPT 1.0的第一個預訓練階段:就是說首先把Transformer模型參數(shù)擴容,常規(guī)的Transformer Big包含24個疊加的Block,就是說這個樓層有24層高,GPT 2.0大干快上,加班加點,把樓層連夜蓋到了48層,高了一倍,參數(shù)規(guī)模15億,這個還是很壯觀的,目前貌似還沒有看到過Transformer樓層有這么高的模型。那么,為什么要擴容呢?這個只是手段,不是目的。真正的目的是:GPT 2.0準備用更多的訓練數(shù)據(jù)來做預訓練,更大的模型,更多的參數(shù),意味著更高的模型容量,所以先擴容,免得Transformer樓層不夠多的房間(模型容量)容納不下過多的住戶(就是NLP知識)。
水庫擴容之后,我們就可以開閘放水了。本質上GPT 2.0主要做的是:找更大數(shù)量的無監(jiān)督訓練數(shù)據(jù),這個其實好辦,反正是無監(jiān)督的,網上有的是,估計未來有一天我寫的這篇文章也能住進GPT 2.0的Transformer客房里。所以,GPT2.0找了800萬互聯(lián)網網頁作為語言模型的訓練數(shù)據(jù),它們被稱為WebText。
當然,光量大還不夠,互聯(lián)網網頁還有個好處,覆蓋的主題范圍非常廣,800萬網頁,主題估計五花八門,你能想到的內容,除了國家禁止傳播的黃賭毒,估計在里面都能找到。這帶來另外一個好處:這樣訓練出來的語言模型,通用性好,覆蓋幾乎任何領域的內容,這意味著它可以用于任意領域的下游任務,有點像圖像領域的Imagenet的意思。GPT 2.0論文其實更強調訓練數(shù)據(jù)的通用性強這點。當然,除了量大通用性強外,數(shù)據(jù)質量也很重要,高質量的數(shù)據(jù)必然包含更好的語言及人類知識,所以GPT 2.0還做了數(shù)據(jù)質量篩選,過濾出高質量的網頁內容來。
之后,GPT 2.0用這些網頁做“單向語言模型”,我這里強調下,仍然是類似GPT 1.0的單向語言模型,而不是Bert的雙向語言模型任務,后面我會單獨講下對這個事情的看法。這樣GPT就可以訓練出一個更好的預訓練模型了,盡管GPT 2.0沒有像Bert或者1.0版本一樣,拿這個第一階段的預訓練模型有監(jiān)督地去做第二階段的Finetuning任務,而是選擇了無監(jiān)督地去做下游任務,盡管這看著和Bert差異很大,其實這點并不重要,甚至你都可以忽略掉這個過程(當然,最吸引眼球的是第二個過程),要記住對于GPT 2.0來說最重要的其實是第一個階段。
其實,如果你不是非常專業(yè)的前沿NLP研究者的話,了解GPT 2.0,這就足夠了,這即使不是GPT 2.0的百分之百,也有它的百分之80了。至于它提到的對Transformer結構的微調,以及BPE輸入方式,我相信都是不太關鍵的改動,應該不影響大局。
如果你細致思考的話,上面講述的GPT流程,其實隱含了三個問題。
第一個問題是:為什么GPT 2.0第二階段不通過Fine tuning去有監(jiān)督地做下游任務呢?
其實GPT的作者是想通過這種方式說明:你看,通過這種改造,GPT 2.0的Transformer學到了多少知識呀,通用性多強啊,做下游任務的時候,包括語言模型,QA,摘要,機器翻譯這么多任務,即使不用有監(jiān)督的方式,直接拿第一階段用語言模型訓練好的模型,都能比較好地做這些任務(從無監(jiān)督的角度比,效果確實挺好,但是跟目前有監(jiān)督的方法比很多效果差的還遠,這也正常)。
GPT作者心里想對你說的是:兄dei(說起這個流行詞,我就有點哭笑不得,因為它讓我想起一件往事:我那7歲的娃今年春節(jié)期間竟然對她媽媽說:兄dei,給我買個玩具小狗可好?),我就問你神奇不神奇?驚喜不驚喜?嗯,其它任務其實不驚奇,但是能做機器翻譯這個確實有點意思,不展開講了,建議機器翻譯的實驗部分可以好好看看想想為什么,論文里說了,這其實是個事故和意外,哈哈。
所以,第一個問題的答案是:無監(jiān)督地去做很多第二階段的任務,只是GPT作者想說明在第一階段Transformer學到了很多通用的包含各個領域的知識,第二部分各種實驗是對這點的例證,如此而已。這是為何說第二階段其實不重要,因為它不是論文的中心思想,而是說明中心思想的例子。
下面談隱含的第二個問題,第二個問題其實比較相對有那么點意思,什么問題呢,就是:“在預訓練階段,為什么GPT 2.0仍然固執(zhí)地用單向語言模型,而不是雙向語言模型呢?”你可以想想這背后可能是什么原因。
關于這點,我講講我的看法,當然你別太嚴肅地看我下面的說法,就當是個我編撰的科技版八卦,今天不是“情人節(jié)后第二天紀念日”嗎?我開個玩笑調節(jié)下氣氛,哈哈。技術科普沒必要老板著臉推公式,是吧,反正這是我的理念。

我的不太準的第六感隱隱約約地告訴我:貌似GPT 的作者們,對于GPT作為本來該火的前輩模型,結果默默無聞,而后來居上的Bert爆紅,可能對這點有點意見?因為它們兩者僅有的大的不同就是GPT用的單向語言模型,Bert用的雙向語言模型做預訓練。所以感覺他們在做GPT 2.0的時候憋著一口氣。
為啥這么講呢?因為Bert在論文的實驗部分已經證明了:Bert的效果比GPT好主要歸因于這個雙向語言模型(參考上圖Bert的實驗結果,去掉雙向語言模型的對比模型其實就等價于GPT 1.0)。按理說,正常的思考模式,后面的改進模型應該采納雙向語言模型,原因很簡單,因為它比單向的效果好。
但是,GPT 2.0仍然固執(zhí)地選擇單向語言模型(也許GPT 作者只想強調他們想做語言模型這個事情,畢竟生成內容后續(xù)單詞這種模式,單向語言模型更方便,這估計是真正原因。不過既然我已經開始編八卦了,就索性編完,畢竟我不是個輕言放棄的人,哈哈),貌似作者們選擇了另外一種打算趕超Bert的方式,就是提升模型參數(shù)容量和增加訓練數(shù)據(jù)的數(shù)量,選了這么條路。我估計意思是說,Bert你別得意得太早,盡管我用單向語言模型,一樣能干翻你。
GPT 2.0的論文在末尾留了個引子,說打算試試看GPT 2.0的單向語言模型是不是就比Bert的雙向語言模型差。估計他們還會推出GPT 3.0,但是肯定還是單向語言模型,就是說人家不服氣,要靠其它方法用單向語言模型超過Bert。嘿嘿,當然,在強調一下,這是我編的八卦,或者是臆斷,未必是事實,但是我死活想不明白為啥他們做下游任務的時候不用雙向語言模型,想來想去貌似只有這個解釋最合理,哈哈,這是我的小人之心和玩笑話,別當真。
下面嚴肅起來,不過我的感覺是,如果GPT 2.0采取雙向語言模型,然后再把目前增加訓練數(shù)據(jù)質量和數(shù)量的路子搭配起來,估計八九成做下游任務是能超過Bert的效果的,那為啥不這么做呢?覺得簡單擴充數(shù)據(jù),這么做創(chuàng)新性不夠酷,所以走了無監(jiān)督做下游任務的不尋常的路子?我估計后面GPT 3.0出來我們會知道真正的答案。當然,話講回來,假設Bert也在第一階段采取類似的擴充數(shù)據(jù)的改進方式,我相信GPT 3.0如果仍然采取單向語言模型的話,很大概率估計還是Bert贏。
最后是隱含的第三個問題,第三個問題也很有意思,這個問題其實跟第一個問題有點關系,問題是:“GPT 2.0 既然第二階段是無監(jiān)督的任務,而它不做Finetuning,那么你訓練好一個語言模型,它當然會根據(jù)輸入的一句話,給你蹦出后面可能緊跟那個單詞,這是標準的語言模型過程,這個正常。但是如果這時候讓它去做一個文本摘要任務,它怎么知道它現(xiàn)在在做什么事情呢,根據(jù)輸入,應該輸出什么東西呢?”就是這么個問題,你不細想可能容易忽略,但是細想其實挺有意思。
其實GPT 2.0在做下游無監(jiān)督任務的時候,給定輸入(對于不同類型的輸入,加入一些引導字符,引導GPT正確地預測目標,比如如果做摘要,在輸入時候加入“TL:DR”引導字符串),它的輸出跟語言模型的輸出是一樣的,就是蹦出一個單詞。那么問題來了:對于比如摘要任務,我們期待的輸出結果是一句話或者幾句話,你給我一個單詞,有點太小氣,那該怎么辦?很簡單,繼續(xù)一個字一個字往出蹦,按照這些字從系統(tǒng)里蹦出來的時間順序連起來,就是你想要的摘要結果,這種所有任務采取相同的往出蹦字的輸出模式也是有點意思的。就是說,GPT2.0給出了一種新穎的生成式任務的做法,就是一個字一個字往出蹦,然后拼接出輸出內容作為翻譯結果或者摘要結果。傳統(tǒng)的NLP網絡的輸出模式一般需要有個序列的產生結構的,而GPT 2.0完全是語言模型的產生結果方式:一個字一個字往出蹦,沒有輸出的序列結構。
上面內容應該就是我覺得關于GPT 2.0,最值得了解的部分以及它的核心思路和思想了。
我的感覺,GPT 2.0作為語言模型,用來生成自然語言句子或者段落的能力特別強,要理解有多強,看下面的例子就知道了:
參考上圖,系統(tǒng)提示出一個故事開始的幾句話,然后后面的內容就靠GPT2.0的語言模型一個字一個字往出蹦,蹦出很多字后,形成后它補充的故事,如果你英文還可以的話,建議還是看看里面的內容。文章開始說我看了GPT的例子嚇了一跳,就是說的這個例子。無論是語法,可讀性,語義一致性,都是很強的,這個超出我對目前技術的期待。也許未來我們會擁有GPT版莎士比亞,也未可知,我對此很期待。
歸納一下,我覺得,我們可以從兩個不同的角度來理解GPT 2.0。
一個角度是把它看作采取類似Elmo/GPT/Bert的兩階段模型解決NLP任務的一種后續(xù)改進策略,這種策略可以用來持續(xù)優(yōu)化第一階段的預訓練過程。畢竟目前GPT 2.0還只采用了800萬的網頁。你說用一億網頁去訓練可以嗎?理論上看是可以的,方法都是現(xiàn)成的,就是Bert那種方法,可能連改都不用改。但是實際上要看你自己或者公司的賬戶余額,你數(shù)數(shù)后面有幾個零,你沒數(shù)我都遙遠地隔著屏幕聽到了你的嘆息聲了,是吧?
當然,從GPT 2.0的做法和結果來看,可能意味著這一點是可行的:后面我們也許可以通過現(xiàn)在的Transformer架構,持續(xù)增加高質量網頁數(shù)量,就能夠不斷讓Transformer學到更多的知識,繼而進一步持續(xù)對下游任務有更高的提升。這是一條簡單有效的技術發(fā)展路徑。這也是為何我在開頭說,隱隱地預感到未來兩年我們會持續(xù)看到不同的NLP任務記錄被刷新,以及不斷爆出的新紀錄。
為什么?很簡單,加大預訓練數(shù)據(jù)量很可能就能做到這點。是否真的會是這樣,我們拭目以待,我對此也很有期待。當然,你會問:這么做的收益有邊界嗎,如果無限增加數(shù)據(jù),就能持續(xù)提升任務效果,沒有終點嗎?事實肯定不是這樣,如果真是這樣那真是個天大的好消息,而這不可能,不過話說回來,但是目前GPT 只用了800萬網頁,這肯定還只是一個開始,距離這種優(yōu)化模式的天花板還遠。
那么另外一個問題是:GPT 2.0和Bert兩階段模型是什么關系?其實答案上面都說了,GPT 2.0其實進一步驗證了Bert這種兩階段是個非常有效的無監(jiān)督NLP語言知識編碼方法。進一步在哪里?它說明了第一個階段的預訓練過程,如果采用更高質量的數(shù)據(jù),采用更寬泛的數(shù)據(jù)(Web數(shù)據(jù)量大了估計包含任何你能想到的領域),采用更大量的數(shù)據(jù)(WebText,800萬網頁),Transformer采用更復雜的模型(最大的GPT2.0模型是Transformer的兩倍層深),那么在Transformer里能學會更多更好的NLP的通用知識。
為什么是通用的?因為第二階段不做任何fine-tuning就能達到更好的效果,而且是各種任務,說明通用性好,通用性好說明了學到了各種類型的語言知識;而這無疑,如果我們第二階段仍然采取Finetuning,對下游任務的提升效果是可以很樂觀地期待的。
另外一個角度也可以把GPT 2.0看成一個效果特別好的語言模型,可以用它來做語言生成類任務,比如摘要,QA這種,再比如給個故事的開頭,讓它給你寫完后面的情節(jié),目前看它的效果出奇的好。當然,僅僅靠拼數(shù)據(jù)量做純語言模型能讓機器產生情節(jié)合理的文章嗎?我覺得可能性不太大,GPT 2.0的生成內容質量好,很可能只是它的記憶能力強導致的,我估計可能是它在把它從大量網頁中記憶的語言片段往外直接拋出來的,不代表它真有編寫合理故事的能力。為什么GPT 2.0通過語言模型能夠在QA任務中能夠不做訓練,回答正確一定比例的問題?我覺得很可能是因為預訓練數(shù)據(jù)集合太大,又比較寬泛,這些問題及答案在網頁里面很接近的地方出現(xiàn)過。而看它的實驗部分,起碼QA任務確實也是這樣的。
但是不論如何,GPT 2.0的結果起碼告訴我們,走這條路子對于產生高質量的生成文章是很有幫助的,我覺得起碼對于生成句子的流暢性,可讀性這些語言表層的方面有直接幫助,但是涉及到情節(jié),這個估計就純粹靠蒙了。但是寫到這句話的時候,我突然想到了一個改進它的思路,讓它能夠受到你想要的情節(jié)context的約束去生成內容,有點跑題,就不展開講了。我覺得對于GPT 2.0的改進方向來說,如何加入情節(jié)約束,產生特別好的生成文章,這個是個很有前途的方向。而在這點上,GPT 2.0的貢獻是給我們指出了一條路,就是Transformer+刷數(shù)據(jù)量,省心省力費機器的一條路。另外,Transformer之前在語言模型上通常做不過RNN,雖然有后續(xù)研究表明它可以達到RNN類似的效果,但是GPT 2.0無疑進一步突破了這個障礙,為Transformer的進一步攻城略地打下了堅實的基礎。
Bert的另外一種改進模式:進一步的多任務預訓練
上面介紹的是GPT 2.0的改進模式,如上歸納,它采取的大的策略是:優(yōu)化Bert的第一個預訓練階段,方向是擴充數(shù)據(jù)數(shù)量,提升數(shù)據(jù)質量,增強通用性,追求的是通過做大來做強。那么如果讓你來優(yōu)化Bert模型,除了這種無監(jiān)督模式地把訓練數(shù)據(jù)做大,還有其它模式嗎?
當然有,你這么想這個問題:既然Bert的第一個階段能夠無監(jiān)督模式地把訓練數(shù)據(jù)做大,我們知道,機器學習里面還有有監(jiān)督學習,NLP任務里也有不少有監(jiān)督任務是有訓練數(shù)據(jù)的,這些數(shù)據(jù)能不能用進來改善Bert第一階段的那個學習各種知識的Transformer呢?肯定是可以的呀,所以很自然的一個想法是:把Bert第一階段改成多任務學習的訓練過程,這樣就可以把很多NLP任務的有監(jiān)督訓練數(shù)據(jù)里包含的知識引入到Transformer中了。
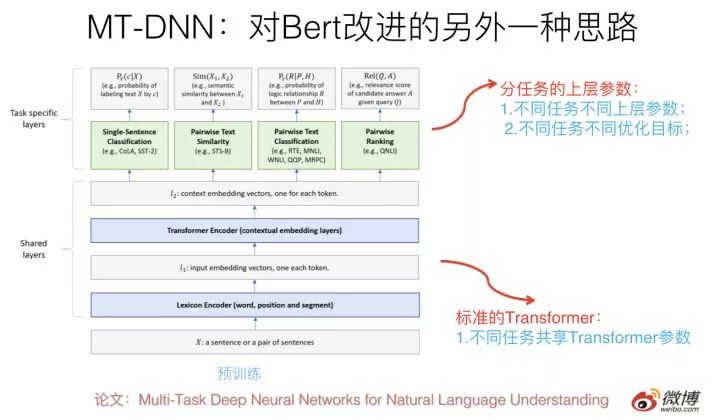
這種做法一個典型的模型是最近微軟推出的MT-DNN,改進思路就如上所述,可以參考上圖示意。核心思想如上,結構上底層就是標準的Bert Transformer,在上層針對不同任務構造不同優(yōu)化目標,所有不同上層任務共享底層Transformer參數(shù),這樣就強迫Transformer通過預訓練做很多NLP任務,來學會新的知識,并編碼到Transformer的參數(shù)中。
對Bert的多任務改造其實是個非常自然的Bert的拓展思路,因為本來原始版本的Bert在預訓練的時候就是多任務過程,包括語言模型以及next-sentence預測兩個任務。新的多任務的目標是進一步拓展任務數(shù)量,以此來進行模型優(yōu)化。
這種改進在效果上也有直接的效果提升,在11項NLP任務中9項超過了原始版本的Bert。
我覺得如果你是做應用,這條路也可以走得更遠一些,引入更多的有監(jiān)督NLP任務,集成更多的知識,無疑這么做是有好處的。
NLP領域的一些發(fā)展趨勢
最后,我結合最近兩個月一些熱門技術新聞的做法,順便再談談我的一些關于NLP技術趨勢的看法,有些觀點之前提過,再強調一下,有些觀點比較細,算是一個歸納吧。
目前可以看出,從NLP主流模型進化的角度,有以下幾個趨勢:
第一個趨勢:采取Bert的兩階段模式,Bert雖然還沒多大歲數(shù),還不到一歲,但是最近兩個月,目前各種NLP評測刷榜的基本都是它。據(jù)我所知很多具備一定規(guī)模的互聯(lián)網公司已經都開始在評估部署B(yǎng)ert模型了,微博也用Bert大幅度改進了標簽分類的精度,目前正在其它各種NLP應用任務進一步推廣。沒辦法,Bert效果確實好,你不得不服。所以這個趨勢已經開始彰顯了;
第二個趨勢:特征抽取器采用Transformer,這個之前在做NLP特征抽取器的文章里,我說明過原因,根本原因是效果比CNN和RNN好,至于它們之間的比較,可以參考之前的文章:
《放棄幻想,全面擁抱Transformer:自然語言處理三大特征抽取器(CNN/RNN/TF)比較》(https://zhuanlan.zhihu.com/p/54743941)
當然,Transformer也有幾個重點改進方向,這個后面找機會詳細說一下。
第三個趨勢,從最近的幾個工作,我們可以看出Bert兩階段模式中,第一個預訓練階段的兩種改進方向:當然基礎是越來越深(意味著模型參數(shù)容量大,各種知識和數(shù)據(jù)?就是死記硬背我也要記住你,大致就是這個意思)的Transformer作為特征抽取器;第一階段的改進工作花開兩只:
一種是強調通用性好以及規(guī)模大。加入越來越多高質量的各種類型的無監(jiān)督數(shù)據(jù),GPT 2.0指出了個明路,就是凈化的高質量網頁,這個跟無限也差不多了,就看你舍得花多少錢去訓練模型。通俗點說,就是靠數(shù)據(jù)規(guī)模和金錢堆出來的。它的最明顯好處是通用性好,訓練好后什么場合都適用。但是因為單純做純語言模型任務的話,學習效率低一些,只能靠量大取勝,這是種“瘦死的駱駝比馬大”的策略;
第二種是通過多任務訓練,加入各種新型的NLP任務數(shù)據(jù),它的好處是有監(jiān)督,能夠有針對性的把任務相關的知識編碼到網絡參數(shù)里,所以明顯的好處是學習目標明確,學習效率高;而對應的缺點是NLP的具體有監(jiān)督任務,往往訓練數(shù)據(jù)量少,于是包含的知識點少;而且有點偏科,學到的知識通用性不強。
當然,我相信,我們很快會看到兩者的合流,就是同時用超大規(guī)模的無監(jiān)督語言模型+各種花樣的有監(jiān)督NLP多任務訓練。這很正常,因為其實語言模型也是多任務的一種,本來Bert原始的預訓練過程就是多任務的:一個是語言模型,一個是next sentence預測。多任務無非是把Bert的兩個任務拓展到更多任務中去。所以兩者本來就是從Bert很自然能夠引出來的自然而然,又一體化的事情。
那么好奇的你問了:這種模式的發(fā)展盡頭在哪里?
我指指銀行的方向:那就是你這個問題的答案。當然,我不是在唆使你去搶銀行啊,別會錯意,否則迎接你的不是美酒,而會是手銬和獵槍。
第四個趨勢:GPT2.0其實真正能夠吸引人眼球的是它生成的高質量內容,讓人印象深刻。從GPT 2.0的結果看,這種采取超深層Transformer+更大量的網頁數(shù)據(jù)去做更好的語言模型,并進而做各種生成式任務,看樣子是有前途的。當然,我前面提到,估計要引入情節(jié)規(guī)劃的約束,這個事情才能真正做好。
玩法的轉向
上面簡單談談我個人認為的幾個技術趨勢,其實最近的一些技術進展,隱隱地透漏出NLP研發(fā)模式的一個轉向,那么是怎樣的一個轉向呢?
我們從Bert/GPT 2.0也可以看出NLP研發(fā)模式在將來的一個發(fā)展趨勢:充分利用更大容量的模型,利用無限的無監(jiān)督的人寫好的文章,去編碼其中蘊含的語言學知識,以及,人類的知識。很明顯NLP已經在往這個方向轉向,而這背后隱藏著什么?超級昂貴的GPU計算時間,超大規(guī)模GPU機器學習集群,超長的模型訓練過程。歸根結底一句話:靠燒錢。
靠燒錢背后又有兩層意思,一個意思是你沒錢就玩不起,就會被清除出NLP的競賽場;另外一個意思是:即使你們公司有錢,但是錢讓不讓你花在這上面?當然這是另外一個問題。
總而言之,這說明NLP值得一提的技術進展的玩法已經變了,以后游戲規(guī)則變成了:土豪大科技公司靠暴力上數(shù)據(jù)規(guī)模,上GPU或者TPU集群,訓練好預訓練模型發(fā)布出來,不斷刷出大新聞。通過暴力美學橫掃一切,這是土豪端的玩法。而對于大多數(shù)人來說,你能做的是在別人放出來的預訓練模型上做小修正或者刷應用或者刷各種榜單,逐步走向了應用人員的方向,這是大多數(shù)NLP從業(yè)者未來幾年要面對的dilemma。原因很簡單,如果上數(shù)據(jù)能夠推進NLP效果,這其實是非常好的事情,這意味著我們會進入技術發(fā)展快車道,因為目標和手段非常簡單明確。
但是這背后的潛臺詞是:目前值得一提的技術創(chuàng)新,變成了已經進入燒錢比進展的時代了,而很明顯,在未來的1到2年里,類似Google/Facebook這種財大氣粗而且創(chuàng)始人具備極端的科學熱情的的土豪科技公司,會積累越來越明顯的軍備競賽優(yōu)勢。我們會看到未來這些公司不斷爆出在各個NLP應用領域的各種刷新記錄,及更巨無霸的新模型的出現(xiàn)。
這對于身處公司里搞算法的同志們,其實是個好事情,因為我們本身就是做應用的,追求短平快,簡單有效最好不過,我估計各個公司都在忙著改造基于Bert的大規(guī)模分布式計算框架呢。但是這對學術圈來說,意味著什么呢?這個問題值得您深入思考。
好了,今天啰嗦到這里,就此別過。
對了,忘了提了,本文作者欄那個名字其實是個筆名,隱藏在幕后的真實作者是:GPT 2.0。
-
語言模型
+關注
關注
0文章
521瀏覽量
10268 -
GPT
+關注
關注
0文章
354瀏覽量
15347 -
nlp
+關注
關注
1文章
488瀏覽量
22033
原文標題:最近爆出的強大NLP模型證明馬太效應:小團隊將難出大成果
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦






 工商網監(jiān)
工商網監(jiān)
評論