 探析自動駕駛規劃控制發展現狀及熱點研究
探析自動駕駛規劃控制發展現狀及熱點研究
對自動駕駛而言,傳感器、感知、地圖定位和規劃控制是目前研究的熱點,本文奇點汽車美研中心首席科學家兼總裁黃浴博士從多個方面綜述了目前自動駕駛的技術水平以及不同板塊的重要性。
傳感器技術
傳感器而言,大家比較關心新技術。
在攝像頭技術方面,HDR,夜視鏡頭,熱敏攝像頭等是比較熱的研究。前段時間有研究(MIT MediaLab教授)采用新技術穿透霧氣的鏡頭,叫做single photon avalanche diode (SPAD) camera;另外,能不能采用計算攝像技術(computational photography)改進一下如何避免雨雪干擾,采用超分辨率(SR)圖像技術也可以看的更遠。前不久,圖森的攝像頭可以看1000米遠嗎,要么采用高清攝像頭4K甚至8K,要么采用SR技術實現。
這是介紹SPAD的兩個截圖:
另外,單目系統比較流行,現在也有雙目系統存在,比如安霸從意大利帕爾馬大學買到的VisLab自動駕駛技術,還有Bertha Benz著名的Stixel障礙物檢測算法。因為基線原因,車上可以配備多個雙目系統,以方便測量不同距離的障礙物。懂計算機視覺的同學知道,立體匹配和基線寬度在涉及視覺系統的時候有一個權衡。深度學習已經用來估計深度/視差圖,就如分割一樣,pixel-to-pixel。甚至單目也可以推理深度,結果當然比雙目差。
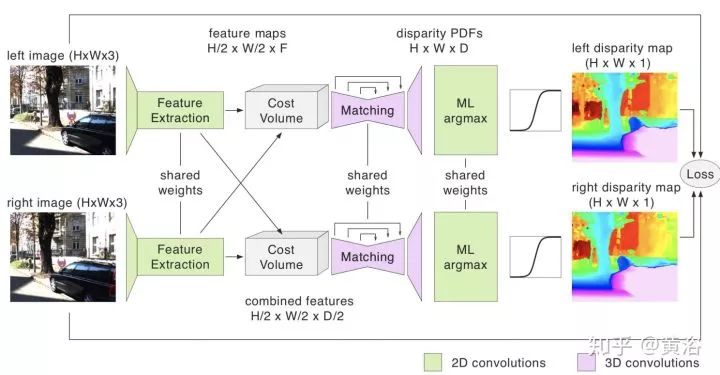
激光雷達最熱,一是降低成本和車規門檻的固態激光雷達,二是如何提高測量距離,三是提高分辨率和刷新頻率,還有避免互相干擾和入侵的激光編碼技術等。其實激光雷達的反射灰度圖也是一個指標,3-D點云加上反射圖會更好,比如用于車道線檢測。
另外,攝像頭和激光雷達在硬件層的融合也是熱點,畢竟一個點云的點是距離信息,加上攝像頭的RGB信息,就是完美了不是?一些做仿真模擬以及VR產品的公司就是這么做的,去除不需要的物體和背景就能生成一個虛擬的仿真環境。
這里是一家美國激光雷達創業公司AEye的技術iDAR截圖,iDAR 是IntelligentDetection and Ranging,最近該公司宣稱已經能夠實現測距1000米(一兩年前谷歌就說,它的激光雷達能看到3個足球場那么遠):
毫米波雷達方面,現在也在想辦法提高角分辨率。畢竟它是唯一的全天候傳感器了,如果能夠解決分辨率這一痛處,那么以后就不會僅僅在屏幕上展示一群目標點,而是有輪廓的目標,加上垂直方向的掃描,完全可以成為激光雷達的競爭對手。希望新的天線和信號處理技術可以解決雷達成像的難點,包括功耗。
這里是NXP提供的新型高分辨率雷達和激光雷達比較的截圖:
超聲波雷達,基本是用在泊車場景,便宜。
感知模塊
下面談感知模塊。
感知是基于傳感器數據的,以前反復提過了,傳感器融合是標配,信息越多越好嗎,關鍵在于怎么融合最優。比如某個傳感器失效怎么辦?某個傳感器數據質量變差(某個時候,比如隧道,比如天氣,比如夜晚,比如高溫低溫等等造成的)怎么辦?如果你要用數據訓練一個感知融合模型,那么訓練數據是否能夠包括這些情況呢?
這里當然談到深度學習了,而且深度學習也不僅僅用在圖像數據,激光雷達點云數據也用,效果也非常好,明顯勝過傳統方法。不過,深度學習有弱點,畢竟還是靠大量數據“喂”出來的模型,有時候很敏感,比如像素上改變一點兒對人眼沒什么而機器識別就造成錯誤,還有當識別類別增多性能會下降,同時出現一些奇怪的誤判,比如谷歌曾經把黑人識別成猩猩。機器學習一個問題是泛化問題(generalization),如何避免overfitting是一個模型訓練的普遍問題,當然大家都提出了不少解決方法,比如data augmentation,drop out等。
深度學習發展還是很快的,好的模型不斷涌現,如ResNet, DenseNet;好的訓練方法也是,比如BN成了標配,采用NAS基礎上的AutoML基本上可以不用調參了(GPU設備很貴呀);具體應用上也是進步很大,比如faster RCNN,YOLO3等等。
在激光雷達數據上,最近深度學習應用發展很快,畢竟新嗎,而且這種傳感器會逐漸普及,成本也會降下來,畢竟是3-D的,比2-D圖像還是好。這里要提到sync和calibration問題,要做好激光雷達和攝像頭數據的同步也不容易,二者的坐標系校準也是,去年有個CNN模型叫RegNet,就是深度學習做二者calibration的。
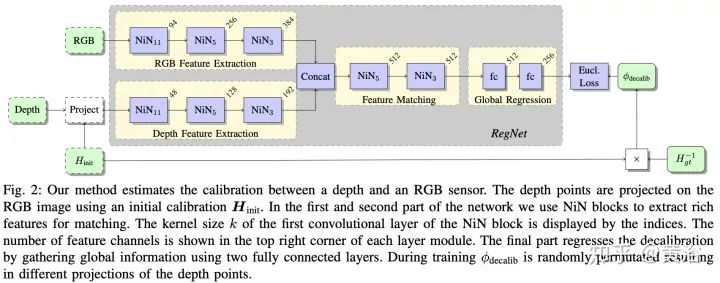
談到融合,這里包括幾個意思,一是數據層的直接融合,前面提到硬件層可以直接完成,軟件也可以,而且還可以解決硬件做不了的問題:激光雷達畢竟稀疏,越遠越稀疏,有時候還會有“黑洞”,就是不反射的物質,比如車窗玻璃;而圖像可以致密,分辨率也可以很高,畢竟造價便宜,二者在深度圖(depth map)空間結合是一個互補,深度學習可以幫上忙,有興趣的可以看看MIT的論文。
除了數據層,還有中間模型層融合,以及最后任務層(一般指多個模型結果輸出)的融合,目前深度學習用在激光雷達數據以及結合圖像數據融合的目標檢測識別分割跟蹤等方面有不少論文,基本可以在這三個層次劃分。
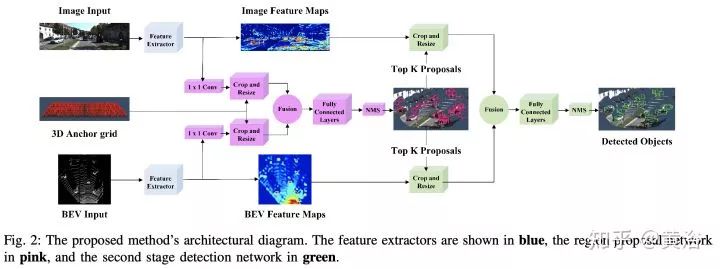
很有趣的現象是,激光雷達點云投射到平面上變成圖像數據是一個很討巧的方法,而且鳥瞰平面比前視平面(攝像機方向)效果好,當然也有直接在3-D數據上做的,比如VoxelNet,PointNet。很多工作都是將圖像領域成功的模型用在激光雷達數據上,做些調整和推廣,比如faster RCNN,其中RPN和RCNN部分可以通過不同傳感器數據訓練。
這里是一個激光雷達+攝像頭融合做目標檢測的論文截圖:
談到深度學習在圖像/視頻/深度圖/3-D點云上的應用,不局限在檢測識別分割上,這個以后再談吧,又要寫一篇才行。
感知的任務是理解自動駕駛車的周圍環境,除了定位跟地圖有關,像障礙物檢測,運動目標跟蹤,紅綠燈識別,道路標志識別,車道線檢測(根據需要而定,比如有些地圖直接用路標或者特征匹配實現定位,車道線就是由地圖給出)都是感知的任務。更高級的任務會涉及對周圍其他物體的行為預測,比如行人,尤其是路口行人過馬路的預測,比如行駛車輛,到底是打算cut-in還是僅僅偏離了車道,在高速入口的車輛,到底是想加速先過還是減速等你,這些都是“老司機”很擅長的,而提供線索的恰恰是感知模塊。
這里是一個做紅綠燈檢測識別的NN模型例子:
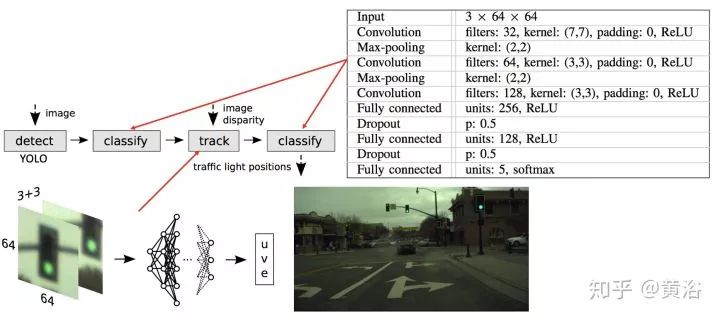
而一個檢測路牌的NN模型:
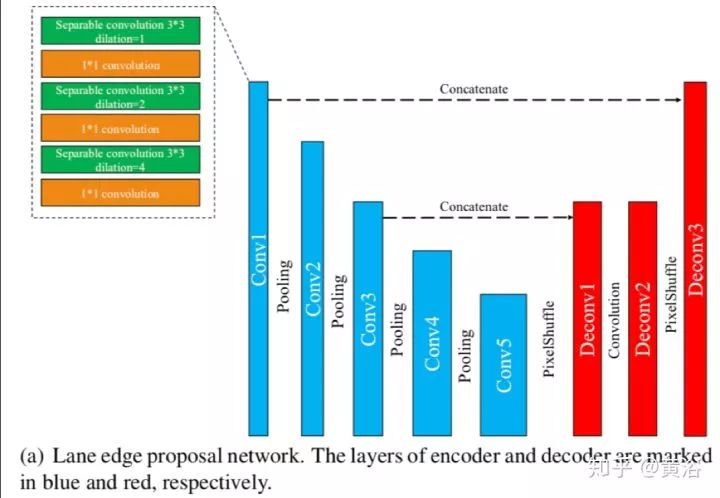
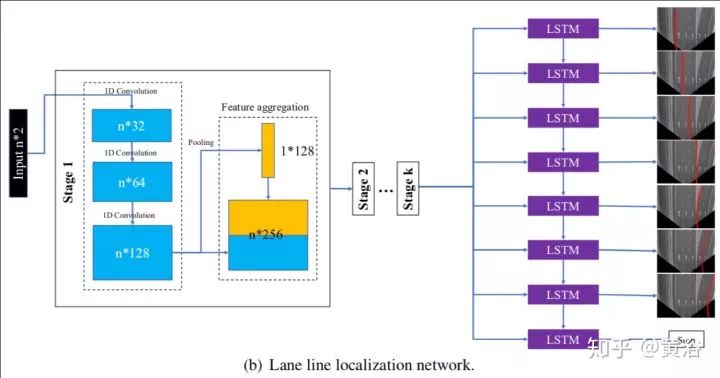
這是一個車道線檢測的NN模型LaneNet示意圖:車道線proposal network和車道線localization network。
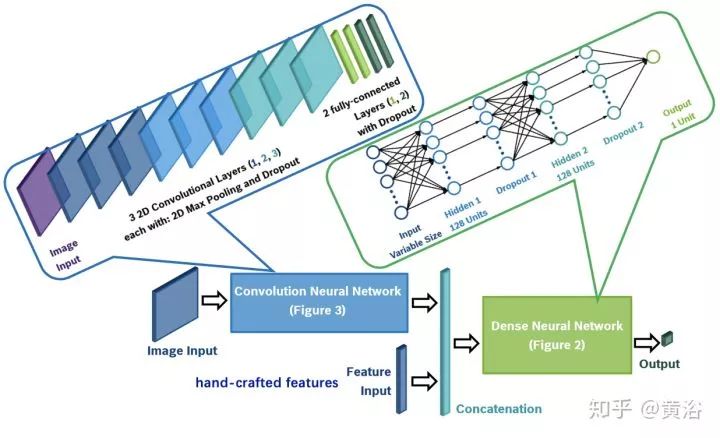
這個NN模型就是對行人預測的:
應用場景可以看下面的示意圖:激光雷達點云作為輸入
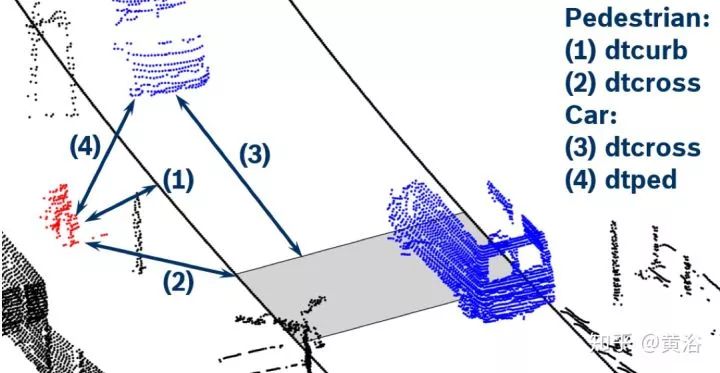
順便說一下,我對一些大講“感知已經OK,現在最重要的是規劃決策”的言論難以茍同,畢竟感知在這些行為細節上缺乏充分的數據提供給預測和規劃部分,所以也很難有更細膩的規劃決策模型來用。當然采用大數據訓練的規劃決策模型可以包括這些,但僅僅憑軌跡/速度/加速度這些輸入信息夠嗎?大家也可以注意到一些startup公司已經在展示人體運動跟蹤,頭部姿態,路上人工駕駛車輛的駕駛員視線方向 (gaze detection) 和面部表情/手勢識別的結果,說明大家已經意識到這些信息的重要性。
這里展示最近一些基于深度學習的人體姿態研究論文截圖:
另外,感知模型基本上是概率決策,是軟的推理(soft inference),最后是最小化誤差的硬決定(hard decision),所以誤差是難免的。現在一些安全標準,比如ASIL,ISO26262, NHTSA,要求做到功能安全,還有最近的SOTIF,要求考慮unknown safe/unsafe,這些對感知在自動駕駛的作用是提出了更嚴格的標準。說白了就是,以前給出判斷就行,現在必須給出判斷的可靠性以及不自信的警告(confidence score)。有時候融合就要考慮這個問題,最好給出多個模型輸出,當一個模型可靠性不高的時候,就要采用其他可靠性高的模型輸出,當所有模型都不可靠,自然就是準備進入安全模式了。對突發性事故的適應性有多強,就考驗安全模型了。
以前提到過L2-L3-L4演進式開發自動駕駛模式和L4這種終極自動駕駛開發模式的不同,提醒大家可以注意一個地方:特斯拉的演進模式在用戶自己人工駕駛的時候仍然運行自動駕駛程序,稱之為“影子”模式,當用戶的駕駛動作和自動駕駛系統的判斷出現矛盾的時候,相關上傳的數據會引起重視,以幫助提升自動駕駛系統性能,比如一個立交橋出現,自動駕駛系統誤認為是障礙物,而駕駛員毫無猶豫的沖過去,顯然這種傳感器數據會重新被標注用來訓練更新模型,甚至引導工程師采集更多相關數據進行訓練;另外,當駕駛員突然剎車或者避讓,而自動駕駛系統認為道路無障的情況,收集數據的服務器一端也會將這種數據重新標注。
這種影子模式就是演進式開發模式系統升級的法寶,同時大量駕駛數據的收集也可以幫助規劃決策的提升,這個下面再講。相比之下,谷歌模式在安全員操控車輛時候,自然也在收集數據,當運行自動駕駛出現報警或者安全員覺得危險需要接管的時候,這種數據也會像影子模式一樣需要注意。兩種開發模式都會及時獲取特別數據方法,唯一不同的是前者是付錢的(買車),而后者是要錢的(工資)。
地圖與定位
再談地圖和定位。
我們知道自動駕駛在L2是不需要地圖的,特別高清地圖(HD Map),帶有車道線信息,L2級別用不上,現在有一種“降維打擊”模式,采用L4技術去開發L3甚至L2,主要是地圖定位可以提供很多輔助信息,簡化一些感知負擔,比如車道線,路牌和紅綠燈位置。
一般我們看到的地圖,俗稱導航地圖,基于GPS進行車定位和道路規劃。現在又出現了一種ADAS地圖(四維圖新就提供這種服務),其實就是在導航地圖上附加一些信息,比如道路曲率和坡度,可以有助于車輛控制的時候調整參數,如ACC,LKS。
我們一般談到定位,可以是GPS/IMU,也可以是高清地圖。前者有誤差,要么采用差分GPS,如RTK(國內的千尋網絡就是提供這樣的服務),要么和其他方式融合,比如激光雷達的點云匹配,攝像頭的特征匹配,也包括基于車道線和路牌的識別定位。
談到高清地圖,以前提到過兩種模式,一是谷歌的高成本方式,采用高價的數據采集車,獲取環境的激光雷達點云以及反射灰度圖,濾除不需要的物體(行人/車輛/臨時障礙物),提取車道線/紅綠燈/路牌(停止/讓路符號,街道距離信息)/車道標志(箭頭/限速/斑馬線)等等,另外也標注了道路的其他信息如曲率,坡度,高程,側傾等等。
這是一個谷歌HD Map的截圖:
由于激光雷達點云數據大,大家就考慮壓縮的方法,比如TomTom的RoadDNA,國內高德地圖的道路指紋匹配,美國startup地圖公司CivilMaps也有類似地圖指紋技術,不過前者是在視覺層,而后者是在點云層。有些公司是不提供點云層,因為數據太大,相反視覺層和語義層可以給,基本矢量圖就能描述,數據量小多了,但匹配難度大。地圖的繪制,存儲和訪問是相當復雜的工程,所以投入很大,尤其是底圖(base map)的繪制。
這是TomTom的RoadDNA定位的介紹截圖:
高清地圖的第二種方式就是Mobileye和Tesla采用的,一般低成本,期望通過眾包實現。不用激光雷達,采用攝像頭獲取道路標識,Mobileye稱之是REM(Road Experience Management),也是“路書”(Roadbook)。REM提取的信息有道路邊緣線、車道中心線、車道邊緣線以及靜態物體的標示。
截圖來自Mobileye的REM介紹:
Bosch基于此,還提出一種基于毫米波雷達的方法提取道路其他信息,比如隔離欄、電線桿和橋梁等等,稱為Bosch Road Signature(BRS)。追隨這種眾包方法的公司也不少,如特斯拉出來的人成立的公司Lvl5,國內有幾家,如寬凳科技,MOMENTA,深動科技,最近地平線也給出一個NavNet平臺,支持這種眾包的低成本制圖方式。
這是Lvl5作圖的一個示意圖:像VO的例子吧。
其實“實時更新”是高清地圖提供服務的關鍵,而對這個服務的成本考慮當然是第二種方式容易推廣。眾包的缺點是容易數據碎片化,同時攝像頭的制圖難度也遠大于激光雷達方法,視覺SLAM是比較有挑戰性的,當然如果限制一下做車道線和路牌為主的目標取地圖特征,難度可以降低。
美國地圖公司HERE采用的更新方法也是通過眾包,只是它先建了底圖。所以,一些提出眾包建圖的公司都想先擁有底圖。Mobileye就和HERE合作,最近它在日本已經完成了REM的高速公路建圖。
這張圖是在今年CES介紹REM的一頁PPT:
定位是基于地圖的,融合方式是包括GPS/IMU/HD Map,比如隧道就沒有GPS信號,甚至高樓大廈密集的地方也不會有穩定的GPS信號,如果網絡不好造成地圖下載不利,基本就是靠IMU和L2的車道線/路牌識別了(激光雷達的反射灰度圖可以做車道線識別,但是傳感器性能有時候限制它的工作距離,不如攝像頭靈活),這時候“降維打擊”的方法都失效了,回歸原始,就靠現場感知了,真正的“老司機”做派:)。
值得一提的是,MIT教授就有在研究如何不用地圖做自動駕駛。
規劃控制
下面該是規劃控制(包含預測和決策)。
規劃分三個層面,路徑規劃(任務規劃),行為規劃和運動規劃。最后一個運動規劃,和后面的控制模塊捆在一起,基本上L2-L4都通用了,除非軟硬件聯合開發,L2和L4用的運動規劃(經典的有RRT,Lattice planner)及控制(PID,MPC之類)沒啥變化。路徑規劃,就是基于道路網絡確定地圖上A點到B點的路徑,這個以前導航地圖也是要做這個任務。那么,剩下一個最新的問題就是行為規劃了。
行為規劃需要定義一個行為類型集,類似多媒體領域采用的ontology,領域知識的描述。而行為規劃的過程,變成了一個有限狀態機的決策過程,需要各種約束求解最優解。這里對周圍運動障礙物(車輛/行人)的行為也有一個動機理解和軌跡預測的任務。上面談到的,感知模塊對周圍車輛行人的行為理解,就會在這里扮演一個重要的角色。
深度學習在這里有價值了。行為模型的學習過程需要大量的駕駛數據,包括感知和定位的輸出,路徑規劃和車輛的運動狀態作為輸入,最終的車輛行駛的控制信號(方向盤,油門,剎車)作為輸出,那么這就是一個E2E的行為規劃+運動規劃+控制的模型;如果把車輛軌跡作為輸出,那么這個E2E就不包括控制。
如果把傳感器/GPS/IMU/HD Map和路徑規劃作為輸入,那么這個E2E就是前端加上感知的模型,這就變成特斯拉想做的software 2.0,不過感知太復雜了,不好辦。還是覺得把感知和定位的輸出作為輸入吧,這樣放心:)。
這里不得不提到自動駕駛的仿真模擬系統,按我看,這種規劃控制的行為模型學習,最適合在模擬仿真環境做測試。Waymo在Carcraft仿真系統中測試左拐彎行為時候,會加上各種變化來測試性能,稱子為“fuzzing"。
這里給大家推薦兩篇重要論文做參考:
1 “A Scenario-Adaptive Driving Behavior Prediction Approach to Urban Autonomous Driving”
2 “ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst”
第一篇是中科大的論文,個人認為非常適合大家了解百度剛剛發布的Apollo 3.5的行為規劃模型。這篇文章我一年前就讀了,不是深度學習的方法。這里貼幾個截圖:
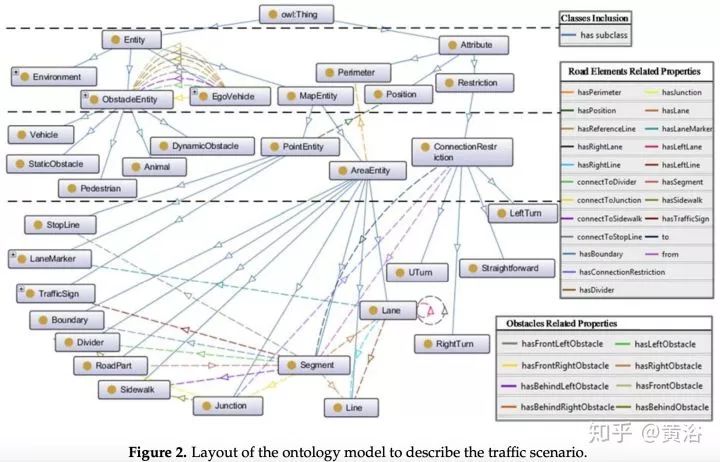
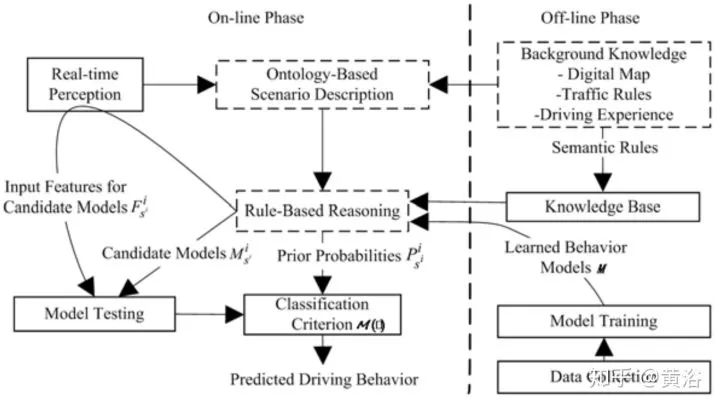
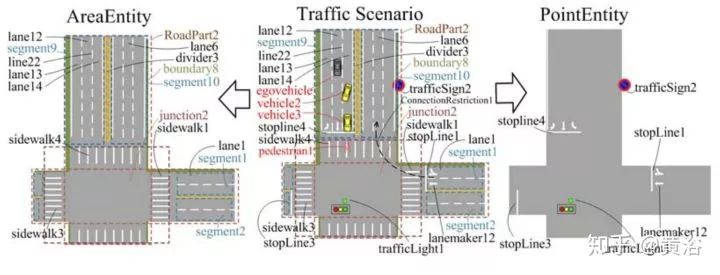
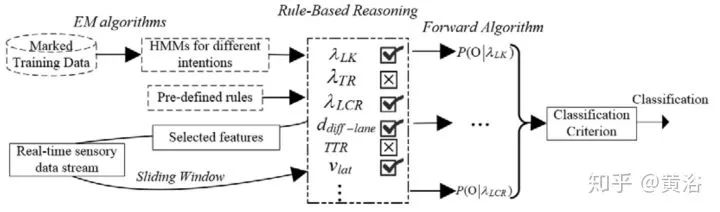
第二篇論文是Waymo最近發的research工作,是深度學習方法,完全依賴其強大的感知模塊輸入,還有1000萬英里的駕駛數據,強烈推薦。附上幾個截圖:
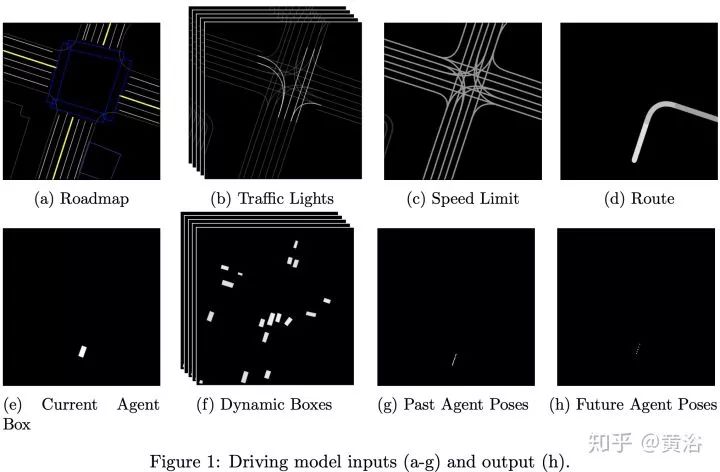
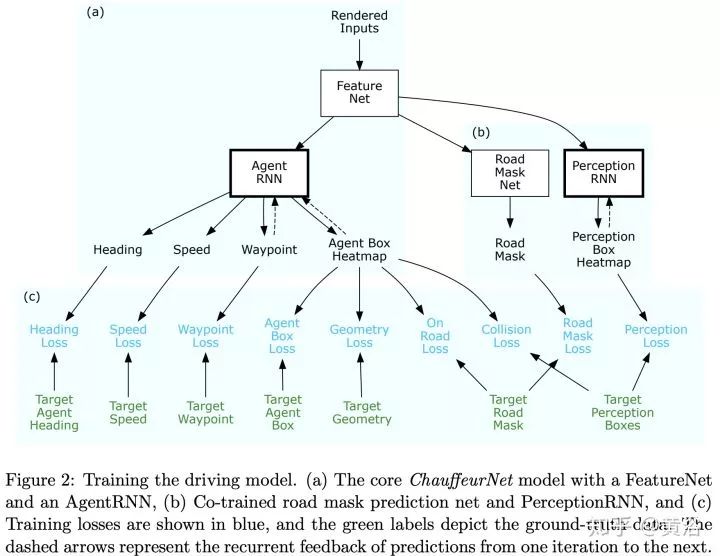
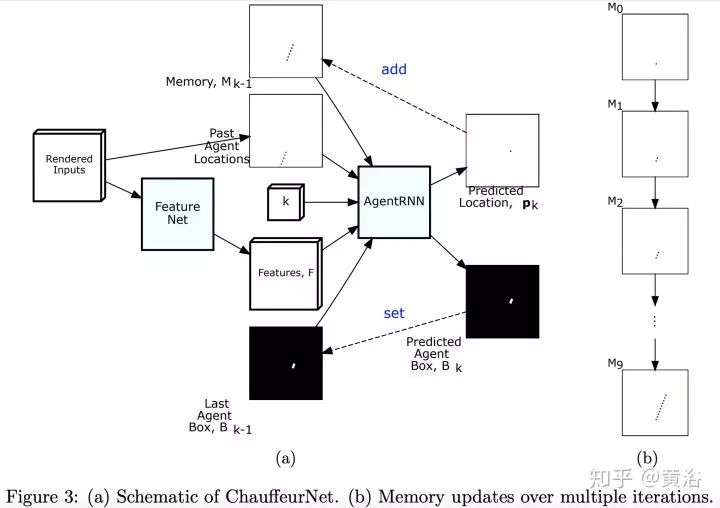

仿真模擬平臺
順便介紹一下,仿真模擬平臺的發展。
DARPA當年比賽的時候前幾名都做了模擬系統,谷歌收購斯坦福團隊以后就先把模擬仿真平臺升級了。畢竟它是一個軟件系統,谷歌天生就強。這里不包括那些車體動力和電子性能的模擬仿真工作,這個已經存在好多年,是車企的強項,比如它們常用的CarMaker,PreScan,CarSim等商用軟件系統。
這是谷歌CarCraft和Xview的樣子:
其中提到的"fuzzing"圖就是這樣的:
仿真模擬平臺已經是自動駕駛開發的標配,看看Daimler汽車公司這部分工作的介紹:
還有自動駕駛高校研究的例子:北卡的AutonoVi-Sim
-
傳感器
+關注
關注
2550文章
51038瀏覽量
753086 -
自動駕駛
+關注
關注
784文章
13785瀏覽量
166399
原文標題:自動駕駛傳感器,感知,地圖定位和規劃控制發展現狀及熱點研究
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
端到端自動駕駛技術研究與分析
一文聊聊自動駕駛測試技術的挑戰與創新

連接視覺語言大模型與端到端自動駕駛

線控底盤,自動駕駛時代的基石?
淺談自動駕駛技術的現狀及發展趨勢
工控機廠家發展現狀及未來趨勢

FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
嵌入式熱門領域有哪些?
深度學習在自動駕駛中的關鍵技術
2.晶體和振蕩器 行業研究及十五五規劃分析報告(行業發展現狀及“十五五”前景預測)
自動駕駛發展問題及解決方案淺析
萬兆電口模塊的產業發展現狀與前景展望
乘用車一體化電池的發展現狀和未來趨勢






 工商網監
工商網監
評論