 機器學習在嵌入式系統中的應用
機器學習在嵌入式系統中的應用
機器學習已從一個有趣的研究課題迅速發展成為廣泛應用的有效解決方案。它顯而易見的有效性迅速吸引了人工智能理論學者群體之外的開發者社區的興趣。在某些方面,機器學習開發能力已經擴展到其它基于強大理論基礎的技術應用層面。
要開發有價值、高精度的機器學習應用絕非易事。盡管如此,不斷增長的機器學習生態系統已經大大減少了對底層算法深入理解的要求,并使機器學習開發越來越容易被嵌入式系統開發人員使用,而不僅僅是理論上的研究。本文著重介紹一些神經網絡模型開發中使用的主要概念和方法,機器學習本身是一個非常多樣化的領域,目前只有一種實用的機器學習方法可供嵌入式開發人員使用。
任何基于高深理論的方法都遵循從研究到工程的發展模式,機器學習也是一樣。就在不久前,希望實現三相交流感應電機精確控制的開發人員需要自己找出解決方案來處理相關的微分方程組。如今,開發人員可以使用庫來快速實現先進的運動控制系統,這些庫使用非常先進的技術(如磁場定向控制、空間矢量調制和梯形控制等)集成完整的電機控制解決方案。除非遇到特殊要求,開發人員通常無需深入了解底層算法或其特定的數學方法,即可部署復雜的電機控制解決方案。運動控制研究人員繼續用新的理論技術發展這門學科,但開發人員可以開發有用的應用,依靠庫來抽象底層方法。
在某些方面,機器學習已達到類似的階段。機器學習算法研究及專用硬件的發展在持續進步當中,如果工程師在理解其相關要求和當前局限的情況下進行處理,這些算法的應用便可成為一種實用的工程方法。在這種情況下,機器學習可以提供有用的結果,不需要高級線性代數專業知識,只要對目標應用數據有正確的理解,并且愿意接受比傳統軟件開發經驗更具實驗性的開發方法。對機器學習基礎感興趣的工程師會發現他們對細節的偏愛可以得到滿足。然而,那些沒有時間或興趣探索理論的人會發現有一個不斷擴大的機器學習生態系統,可以幫助他們簡化有用的機器學習應用開發。
機器學習方法
工程師可以找到能夠支持廣泛類型機器學習的優化庫,包括無監督學習、強化學習和監督學習。無監督學習可以揭示出大量數據中的模式,但是這種方法不能將這些模式明確地標記為屬于特定類別的數據。盡管本文未涉及無監督學習,但這些技術在物聯網應用中可能非常重要,可以揭示數據集中的異常值或表明存在偏離數據趨勢的情況。例如,在工業應用中,從一組機器的傳感器讀數中可以看出,統計上顯著偏離正常的現象可以作為該組機器出現潛在故障的指示。類似地,在一個大規模分布式IoT應用中,顯著偏離多個性能參數正常值的現象可能揭示出,在數百或數千個設備組成的網絡中可能有遭受黑客攻擊的設備。
強化學習是一種通過實驗進行有效學習的應用方法,利用正反饋(激勵)來學習對事件的成功響應。例如,當一個強化學習系統檢測到來自一組機器的異常傳感器讀數時,可能試圖通過采取不同的動作(例如增加冷卻劑流量、降低室溫、減少機器負載等)來校正,以便將這些讀數恢復到正常。在了解到哪個動作達到期望的結果后,強化學習系統在下次遇到相同的異常讀數時就可以更快地執行相同的操作。雖然本文不探討這種方法,但強化學習可能會在大規模復雜應用(如物聯網)中得到越來越廣泛的應用,因為在這些應用中所實現的運行狀態都不能有效地預測。
監督學習
監督學習方法消除了在識別哪組輸入數據對應于哪個特定狀態(或對象)時進行的猜測。 利用這種方法,開發人員明確識別出與特定對象、狀態或條件相對應的輸入值或特征組合。 在一個假設的機器示例中,工程師通過一組由n和x組成的函數來表征要解決的問題,其中x是函數表達式(如x2),而n代表不同的特征參數,比如傳感器輸入、機器運行時間、最后服務日期、機器年齡和其他可測量參數。然后工程師根據他們的專業知識創建一個訓練數據集,即這些特征向量的多個實例(x1 x2 ... xn),每個特征向量都有n個觀察值與已知輸出狀態相關聯,標記為y:
(x11, x12, … x1n) ? y1
(x21, x22, … x2n) ? y2
(x31, x32, … x3n) ? y3
…
給定所測量特征值與相應標簽之間的已知關系,開發人員就可以為訓練集中的每個特征向量(x1k x2k ... xnk)生成預期標簽yk的模型(方程組)。在這一訓練過程期間,訓練算法使用迭代方法,通過調整構成該模型的方程組的參數來最小化預測標簽與其實際標簽之間的差異。將訓練集中的所有樣本都訓練一次,稱為“一次迭代(epoch)”,而每一次epoch都會產生一組新的參數、一組與這些參數相關的新預測標簽,以及相關的差異或損失。
針對損失進行繪圖,在每次迭代時產生的參數值集合是具有一些最小值的多維表面。該最小值對應于訓練集中提供的實際標簽與模型推斷的預測標簽之間的最接近的一致性。因此,訓練的目標是調整模型的內部參數以達到最小損失值,使用方法來尋求最小的“下坡”路徑。在多維表面上,通過計算每個參數相對于其他參數的斜率 - 即每個參數的偏導數,可以確定導致最佳下坡路徑的方向。訓練算法通常使用矩陣方法,稱為梯度下降,以便在每個epoch通過模型運行訓練數據的全部或子集之后來調整模型參數值。為了最小化這種調整的幅度,訓練算法將每個步長調整一些值,稱為學習速率,這有助于訓練過程收斂。在沒有受控學習速率的情況下,由于模型參數的過大調整,梯度下降可能超過最小值。在模型達到(或可接受地收斂)最小損失之后,工程師就可以測試模型的標簽預測能力。
一旦經過訓練和評估,就可以在生產環境中部署合適的模型,作為推理模型來預測實際應用數據的標簽。請注意,推理會為訓練中使用的每個標簽生成一組概率值。因此,用標記為“y1”,“y2”或“y3”的特征向量訓練的模型可能在呈現與y1相關的特征向量時產生這樣的推斷結果,比如“y1:0.8; y2:0.19; y3:0.01”。額外的軟件邏輯將監視輸出層以選擇具有最佳似然值的標簽,并將所選標簽傳遞給應用。通過這種方式,一個應用就可以使用機器學習模型來識別一個或其他數據模式,并采取適當的行動。
神經網絡的發展
創建精確的推理模型當然是對監督學習過程的回報,該過程能夠利用各種基礎模型的類型和體系結構。在這些模型類型中,神經網絡因其在圖像識別、自然語言處理和其他應用領域的成功而迅速普及。實際上,當先進的神經網絡在圖像識別中顯著優于早期算法之后,神經網絡架構已經成為這類問題事實上的解決方案。隨著GPU等能夠快速執行基礎計算的硬件的出現,算法開發者和用戶可以快速獲得這些技術。反過來,有效的硬件平臺和神經網絡的廣泛接受又推動了各種方便開發人員使用的框架,包括Facebook的Caffe2、H2O、英特爾的neon、MATLAB、微軟認知工具包、Apache MXNet、三星Veles、TensorFlow、Theano和PyTorch等。結果,開發人員可以輕松地找到合適的環境來評估機器學習,特別是神經網絡。
神經網絡的開發始于使用任意數量的可用安裝選項來部署框架。盡管依賴性通常很小,但所有流行的框架都能夠利用GPU加速庫。因此,開發人員可以通過安裝NVIDA CUDA工具包和NVIDIA深度學習SDK中的一個或多個庫[比如用于多節點/多GPU平臺的NCCL(NVIDIA集體通信庫)或NVIDIA cuDNN(CUDA深度神經網絡)庫]來大幅提高計算速度。機器學習框架在GPU加速模式下運行,可充分利用cuDNN針對標準神經網絡例程的優化實現,包括卷積、池化、規范化和激活層。
無論是否使用GPU,框架的安裝都很簡單,通常需要為這些基于Python的軟件包安裝pip。例如,要安裝TensorFlow,可以使用與任何Python模塊相同的Python安裝方法:
pip3 install --upgrade tensorflow
(或僅適用于Python 2.7環境)
此外,開發人員可能希望添加其他Python模塊以加速不同方面的開發。例如,Python pandas模塊提供了一個功能強大的工具,用于創建所需的數據格式,執行不同的數據轉換,或者只處理機器學習模型開發中經常需要的各種數據整理操作。
經驗豐富的Python開發人員通常會為Python開發創建一個虛擬環境,例如,流行的框架都可以通過Anaconda獲得。開發人員可以使用容器技術來簡化devops,也可以找到其所用框架內置的合適容器。例如,TensorFlow在Dockerhub上的Docker容器中就支持兩個版本,一個是僅支持CPU的,一個是支持GPU的。Python wheel檔案中也提供了一些框架。例如,Microsoft在CPU和GPU兩個版本中都提供Linux CNTK wheel 文件,開發人員也可以在Raspberry Pi 3上找到用于安裝TensorFlow的wheel 文件。
數據準備
雖然設置機器學習框架已經比較簡單,但真正的工作始于選擇和準備數據。如前所述,數據在模型訓練中起著核心作用,因此決定著一個推理模型的有效性。之前未提及的事實是,訓練集通常包括數十萬甚至數百萬個特征向量和標簽以達到足夠的準確度水平。這些數據集的龐大規模使得對輸入數據的隨意檢查變得不可能或基本上無效。然而,糟糕的訓練數據直接影響模型質量。錯誤標記的特征向量、缺失數據,以及“太”干凈的數據集可能導致推理模型無法提供準確的預測或很好地歸納。對于整體應用而言可能更糟糕的是,選擇統計上不具代表性的訓練集預示著模型會因那些缺失的特征向量及其所代表的實體而偏離實際。由于訓練數據的重要性以及創建數據的難度很大,業界已經發展了大量的標記數據集,這些數據集可從諸如UCI機器學習庫等來源獲取。對于僅僅探索不同機器學習算法的開發人員,Kaggle數據集通常可以提供一個很有用的起點。
當然,對于從事獨特的機器學習應用開發的組織來說,模型開發需要自己獨特的數據集。即使有足夠大的可用數據池,標記數據也是一項龐大的工程。實際上,標記數據的過程主要還是人工來完成的。因此,創建一個準確標記數據的系統本身就是一個過程,需要結合心理學理解人類如何解釋指令(如標簽方式和內容),以及技術支持來加速數據的呈現、標記和驗證。Edgecase、Figure Eight和Gengo等公司結合了數據標簽多種要求方面的專業知識,提供旨在將數據轉化為有用的監督學習培訓集的服務。有了一組合格的標記數據,開發人員就需要將數據分成訓練集和測試集,通常使用90:10左右的比例進行分割。注意測試集是一個有代表性但又與訓練集截然不同的數據集。
模型開發
在許多方面,創建合適的訓練和測試數據可能比創建實際模型本身更困難。例如,使用TensorFlow,開發人員可以在TensorFlow的Estimator類中使用內置模型類型來構建模型。例如,單個調用如:
classifier = tf.estimator.DNNClassifier(
feature_columns=this_feature_column,
hidden_units=[4,],
n_classes=2)
使用內置的DNNClassifier類自動創建一個基本的完全連接的神經網絡模型(見圖1),它包括一個有三個神經元的輸入層(支持的特征數量),一個有四個神經元的隱藏層,以及一個有兩個神經元的輸出層(支持的標簽數量)。在每個神經元內,相對簡單的激活函數對其輸入組合執行一些轉換以生成其輸出。
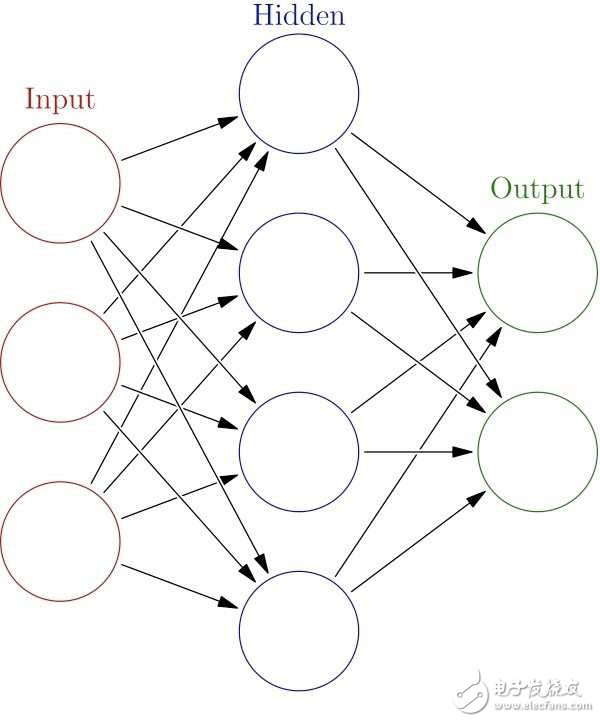
圖1:最簡單的神經網絡包括輸入層、隱藏層和輸出層,而有用的推理依賴于包含大量隱藏層的深度神經網絡模型,每個隱藏層包含大量神經元。 (來源:維基百科)
圖片翻譯:輸入層;隱藏層;輸出層
為了訓練模型,開發人員只需在實例化的估算器對象中調用訓練方法 - 在此示例中為classifier.train(input_fn = this_input_function),并使用TensorFlow數據集API通過輸入函數提供正確形成的數據(本示例中為this_input_function)。需要這樣的預處理或“整形”來將輸入數據流轉換為具有輸入層所期望的維度(形狀)的矩陣,但是這一預處理步驟還可能包括數據縮放、歸一化以及特定模型所需的任何數量的變換。
神經網絡是許多高級識別系統的核心,但實際應用所采用的神經網絡,其結構比本示例要復雜得多。這些“深度神經網絡”架構具有許多隱藏層,每層都有大量神經元。雖然開發人員可以簡單地使用內置的Estimator類來添加更多層及更多神經元,但成功的模型架構往往會混合不同類型的層和功能。
例如,AlexNet是一種卷積神經網絡(CNN)或ConvNet,它在ImageNet競賽(以及之后的許多圖像識別應用)中引發了CNN的廣泛使用,共有八層(見圖2)。每層包含非常多的神經元,在第一層中有253440個,第二層及以后依次為186624、64896、64896、43264、4096、4096和1000個神經元。不是使用觀察數據的特征向量,ConvNets掃描圖像通過一個窗口(n×n像素濾鏡),移動窗口幾個像素(步幅)并重復該過程,直到圖像被完全掃描。每個過濾結果都通過ConvNet的各個層來完成圖像識別模型。
圖2:AlexNet演示了使用深度卷積神經網絡架構來降低圖像識別中的錯誤率。 (來源:ImageNet大規模視覺識別競賽)
圖片翻譯:步幅4;最大池化;密集矩陣
即使采用這種“簡單”配置,與前一年的領先解決方案相比,使用CNN可以顯著降低ImageNet大規模視覺識別競賽(ILSVRC)中的前5個錯誤。 (前5個錯誤是一個常見指標,表示在該模型的輸入數據對可能標簽的前五個預測中,不包括正確標簽的推斷百分比。)在隨后的幾年中,領先的參賽作品顯示了層數的急劇增加,以及前5個錯誤顯著減少(圖3)。
圖3:由于AlexNet在2012年大幅降低了ImageNet前5個錯誤率,因此ILSVRC中表現最佳的模型架構具有更深層次的模型架構。 (來源:計算機視覺基金會)
圖片翻譯:ImageNet分類前5個錯誤率(%);層;
模型開發
開發人員可以使用任何流行的框架來創建ConvNets和其他復雜的自定義模型。使用TensorFlow,開發人員使用方法調用逐層構建ConvNet模型,以構建卷積層,使用池化層聚合結果,并對結果進行標準化,通常重復該組合以根據需要創建盡可能多的卷積層。實際上,在設計用于完成CIFAR-10分類集的ConvNet的TensorFlow演示中,前三層是使用三種關鍵方法構建的:tf.nn.conv2d、tf.nn.max_pool和tf.nn.lrn:
# conv1
with tf.variable_scope('conv1') as scope:
kernel = _variable_with_weight_decay('weights',
shape=[5, 5, 3, 64],
stddev=5e-2,
wd=None)
conv = tf.nn.conv2d(images, kernel, [1, 1, 1, 1], padding='SAME')
biases = _variable_on_cpu('biases', [64], tf.constant_initializer(0.0))
pre_activation = tf.nn.bias_add(conv, biases)
conv1 = tf.nn.relu(pre_activation, name=scope.name)
_activation_summary(conv1)
# pool1
pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1],
padding='SAME', name='pool1')
# norm1
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75,
name='norm1')
模型訓練
開發人員使用清單1中所示的訓練方法來訓練完整的TensorFlow模型。
其中,train_op引用cifar10類對象的訓練方法來執行訓練,直到滿足開發人員在其他地方定義的停止條件。 cifar10訓練方法處理實際的訓練周期,包括損失計算、梯度下降、參數更新,以及將指數衰減函數應用于學習率本身(清單2)。
def train():
"""Train CIFAR-10 for a number of steps."""
with tf.Graph().as_default():
global_step = tf.train.get_or_create_global_step()
# Get images and labels for CIFAR-10.
# Force input pipeline to CPU:0 to avoid operations sometimes ending up on
# GPU and resulting in a slow down.
with tf.device('/cpu:0'):
images, labels = cifar10.distorted_inputs()
# Build a Graph that computes the logits predictions from the
# inference model.
logits = cifar10.inference(images)
# Calculate loss.
loss = cifar10.loss(logits, labels)
# Build a Graph that trains the model with one batch of examples and
# updates the model parameters.
train_op = cifar10.train(loss, global_step)
class _LoggerHook(tf.train.SessionRunHook):
"""Logs loss and runtime."""
def begin(self):
self._step = -1
self._start_time = time.time()
def before_run(self, run_context):
self._step += 1
return tf.train.SessionRunArgs(loss) # Asks for loss value.
def after_run(self, run_context, run_values):
if self._step % FLAGS.log_frequency == 0:
current_time = time.time()
duration = current_time - self._start_time
self._start_time = current_time
loss_value = run_values.results
examples_per_sec = FLAGS.log_frequency * FLAGS.batch_size / duration
sec_per_batch = float(duration / FLAGS.log_frequency)
format_str = ('%s: step %d, loss = %.2f (%.1f examples/sec; %.3f '
'sec/batch)')
print (format_str % (datetime.now(), self._step, loss_value,
examples_per_sec, sec_per_batch))
with tf.train.MonitoredTrainingSession(
checkpoint_dir=FLAGS.train_dir,
hooks=[tf.train.StopAtStepHook(last_step=FLAGS.max_steps),
tf.train.NanTensorHook(loss),
_LoggerHook()],
config=tf.ConfigProto(
log_device_placement=FLAGS.log_device_placement)) as mon_sess:
while not mon_sess.should_stop():
mon_sess.run(train_op)
清單1:在這一來自TensorFlow CIFAR-10 ConvNet的演示示例中,TensorFlow會話mon_sess運行方法執行訓練周期,引用cifar10實例本身包含的損失函數和其他訓練參數。 (來源:TensorFlow)
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(INITIAL_LEARNING_RATE,
global_step,
decay_steps,
LEARNING_RATE_DECAY_FACTOR,
staircase=True)
tf.summary.scalar('learning_rate', lr)
# Generate moving averages of all losses and associated summaries.
loss_averages_op = _add_loss_summaries(total_loss)
# Compute gradients.
with tf.control_dependencies([loss_averages_op]):
opt = tf.train.GradientDescentOptimizer(lr)
grads = opt.compute_gradients(total_loss)
# Apply gradients.
apply_gradient_op = opt.apply_gradients(grads, global_step=global_step)
清單2:在TensorFlow CIFAR-10 ConvNet實現中,cifar10對象執行梯度下降,使用指數衰減計算損耗,并更新模型參數。 (來源:TensorFlow)
TensorFlow方法提供了強大的功能和靈活性,但代碼可以說是比較笨拙的。 好消息是,Keras作為一個更直觀的神經網絡API,可以運行在TensorFlow之上。使用Keras,開發人員只需幾行代碼即可構建CIFAR-10 ConvNet,比如添加所需的層、激活函數、聚合(池)等(見清單3)。
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes))
model.add(Activation('softmax'))
清單3:Keras提供了一種逐層構建ConvNet模型的直觀方法。 (來源:Keras)
在Keras中定義模型之后,開發人員調用模型的編譯方法來指定所期望的損耗計算算法和優化算法(比如梯度下降)。為了訓練模型,開發人員稱之為模型的擬合方法。 或者,模型的fit_generator方法提供了一種更簡單的訓練方法,即使用Python的生成器功能對從Keras預處理類生成的批量數據進行處理,以此來訓練模型。
要將模型部署到目標設備(如邊緣設備),開發人員通常可以從其開發環境中導出模型。 例如,使用TensorFlow,開發人員可以使用TensorFlow freeze_graph.py實用程序,以pb格式導出模型,這是一種基于Google協議緩沖器的序列化格式。在目標設備中,開發人員可以使用TensorFlow C ++ API創建TensorFlow運行會話、加載pb文件,并使用應用輸入數據運行它。對于能夠使用容器的目標平臺,開發人員通常可以在Docker Hub上找到他們喜歡的框架的Docker容器,添加他們的模型執行應用程序,并將應用程序容器導出到他們的目標平臺。在實踐中,重新部署模型的過程需要額外注意,特別在將從開發環境中提取訓練數據而構建的功能更換為專門為生產環境的數據處理而優化的功能時。
開發方法
TensorFlow、Keras和其他神經網絡框架顯著簡化了構建復雜模型的任務,但創建一個有效地滿足設計目標的模型完全是另一回事。與傳統的軟件開發不同,開發有效的模型可能需要更多的推測來嘗試不同的解決方案,以便“看出哪種方案可行”。研究人員正在積極研究能夠創建優化模型的算法,但神經網絡優化的一般定理仍然難以捉摸。就此而言,創建模型沒有通用的最佳實踐或啟發式方法:每個應用在前端都有其獨特的數據特征,而在后端都有性能、準確性和功耗的獨特要求。
一種有效的方法是自動化模型構建工具,例如Google的Cloud AutoML,它使用遷移學習和強化學習在特定領域找到良好的模型架構。到目前為止,Google已經發布了一款還處于早期測試階段的產品AutoML Vision。雖然沒有立即出現,但自動化模型構建工具的出現將是不可避免的。因為AI工具供應商在爭奪機器學習的主導地位,想借此改變游戲規則,因此,AutoML類工具仍然是一個活躍的研究課題。
與此同時,云服務提供商和框架開發人員也在不斷改進更直接的功能,以簡化機器學習解決方案的開發。開發人員可以使用TensorFlow調試器等工具深入了解模型和TensorBoard的內部狀態,以便更輕松地可視化和探索復雜的模型拓撲和節點交互。例如,TensorBoard提供了損失與epoch的交互式視圖,可以對模型有效性和學習速率適用性做出早期衡量(見圖4)。

圖4:TensorBoard幫助開發人員可視化模型內部結構和訓練過程,顯示損失函數(此處使用損失函數的交叉條目)與epoch的關系。 (來源:TensorFlow)
最終,找到最合適的架構和配置是經驗和反復試錯的結果。即使是最有經驗的神經網絡研究人員也建議找到最佳機器學習架構和特定拓撲結構的方法是嘗試,看看哪種方法效果最好。從這個意義上說,神經網絡發展與傳統應用開發有很大不同。不要期望對模型編碼后,就萬事大吉了,經驗豐富的機器學習開發人員,特別是神經網絡開發人員,會將每個模型構建視為一個試驗,使用不同的模型架構和配置運行多個實驗,以找到最適合自己應用需要的模型。
然而,開發人員可以利用框架提供商和開源社區提供的大量預建模型來加速模型開發過程。預構建模型帶有通用數據集,甚至特定應用的數據集,但很少有開發人員所期望模型的最佳選擇。然而,采用遷移學習方法,這些模型不僅可以加速開發,而且得到的結果通常比使用自己的數據集來訓練初級模型更好。實際上,開發人員可以從很多渠道找到開源的預訓練模型,比如Caffe2 Model Zoo、Microsoft CNTK Model Gallery、Keras和TensorFlow等。
平臺要求
然而,即使可用的模型創建技術數量不斷增加,模型選擇的關鍵約束仍然是目標平臺的性能。為多GPU系統而設計的模型,將無法在基于通用處理器的系統上有效運行。如果沒有適當的硬件支持,通用處理器無法快速完成主導機器學習算法的矩陣乘法計算(圖5)。
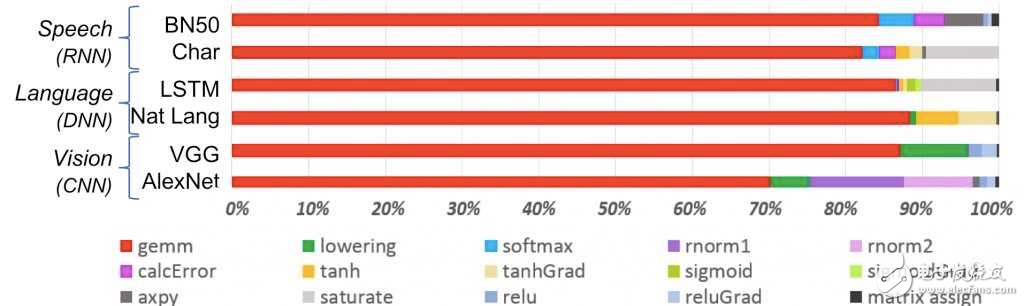
圖5:通用矩陣乘法(gemm)計算是一般機器學習的主要方式,特別是神經網絡架構。 (來源:IBM)
盡管如此,開發人員仍然可以使用前面提到的TensorFlow for Raspberry Pi的版本來開發神經網絡模型,能夠在Raspberry Pi這樣的系統上運行。更普遍地,Arm的計算庫提供了針對Arm Cortex-A系列CPU優化的機器學習功能,比如Raspberry Pi 3使用的CPU就是Arm處理器。開發人員甚至可以使用Arm的CMSIS-NN為Arm Cortex-M7 MCU創建普通但有效的神經網絡庫。實際上,Arm介紹過一個示例,NUCLEO Mbed板上的標準216 MHz Cortex-M7處理器,就可以支持為CIFAR-10預先構建的Caffe ConvNet,運行后,它可以在合理的時間內完成推理(圖6)。
圖6:Arm展示Caffe CIFAR-10 ConvNet模型能夠在標準Arm Cortex-M7處理器上運行。 (來源:Arm)
FPGA可以提供重要的性能升級和快速開發平臺。例如, Lattice 半導體公司的SensAI平臺使用神經網絡編譯器,能夠將TensorFlow pb文件和其他文件編譯到Lattice 神經網絡IP核上,以便在其FPGA上實現人工智能。
專用的AI設備則更進一步,它們采用專門的硬件來加速面向大眾市場的機器學習應用。比如Intel Movidius Neural Compute Stick、NVIDIA Jetson TX2模塊和高通Snapdragon模塊等硬件設備可讓開發人員在各種系統中嵌入高性能機器學習算法。
專門針對AI應用的架構旨在減少CPU-內存瓶頸。例如,IBM在2018年VLSI電路研討會上描述的AI加速器芯片將用于加速矩陣乘法的處理單元與用于減少片外存儲器訪問的“暫存存儲器”層次結合在一起(圖7)。同樣地,新興的高級AI芯片利用各種方法將微架構中的邏輯和存儲器合并,以加速AI應用的各種操作。

圖7:使用了諸如IBM AI芯片中描述的暫存器內存層次結構等技術的新興AI芯片架構旨在減少CPU-內存瓶頸的影響。 (來源:IBM)
專用框架和架構
專用硬件旨在充分發揮機器學習的潛力,IC行業繼續提供更加強大的AI處理器。與此同時,框架開發人員和機器學習算法專家也在不斷尋找優化框架和神經網絡架構的方法,以便更有效地支持資源受限的平臺,包括智能手機、物聯網邊緣設備和其他性能一般的系統。雖然Apple Core ML和Android神經網絡API都為各自的環境提供了解決方案,但TensorFlow Mobile等框架(及其演化版本TensorFlow Lite)提供了更通用的解決方案。
模型結構本身在不斷發展,以解決嵌入式設備的資源限制。SqueezeNet就是通過擠壓模型架構的元素,從而顯著減少了模型大小和參數。MobileNet采用不同的架構方法,可達到與其他方法相當的top-1 精度,但所需要的乘法-加法操作卻少得多(圖8)。機器學習公司Neurala使用自己的獨創方法開發出很小的模型,但仍然能夠達到很高的精度。
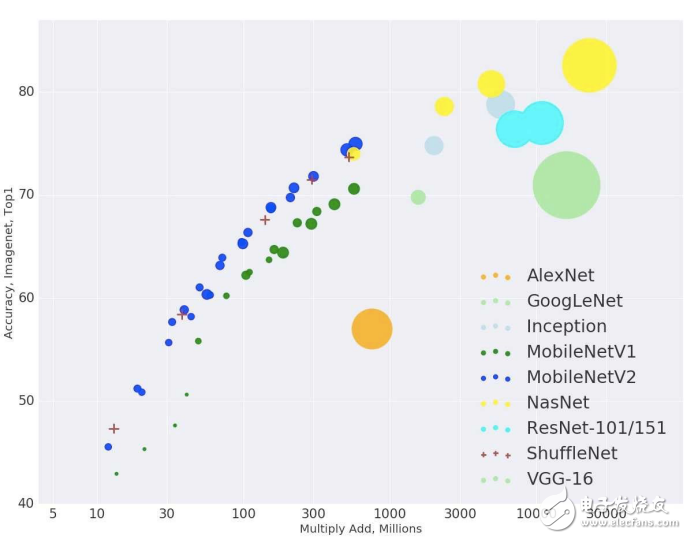
圖8:Google的MobileNet等專用模型架構通過減少資源受限的嵌入式應用所需的矩陣乘法-加法運算,仍可提供具有競爭力的精度。
算法和工具的融合減少了從頭構建機器學習模型的需要。開發人員利用越來越強大的框架和工具,更多地在預先構建的模型上開發,來滿足他們自己的獨特需求。因此,開發人員可以在流行的平臺上部署推理模型,以執行圖像識別等簡單任務。利用同樣的技術來創建有用的高性能生產模型絕非易事,但任何開發人員都非常容易獲得和使用。隨著專用AI硬件在低功耗系統中的發展,機器學習很可能成為嵌入式開發人員常用的開發工具。
-
機器學習
+關注
關注
66文章
8411瀏覽量
132594
發布評論請先 登錄
相關推薦






 工商網監
工商網監
評論