

過(guò)去的一年,深度神經(jīng)網(wǎng)絡(luò)的應(yīng)用開(kāi)啟了自然語(yǔ)言處理的新時(shí)代。預(yù)訓(xùn)練模型在研究領(lǐng)域的應(yīng)用已經(jīng)令許多NLP項(xiàng)目的最新成果產(chǎn)生了巨大的飛躍,例如文本分類,自然語(yǔ)言推理和問(wèn)答。
ELMo,ULMFiT 和OpenAI Transformer是其中幾個(gè)關(guān)鍵的里程碑。所有這些算法都允許我們?cè)诖笮蛿?shù)據(jù)庫(kù)(例如所有維基百科文章)上預(yù)先訓(xùn)練無(wú)監(jiān)督語(yǔ)言模型,然后在下游任務(wù)上對(duì)這些預(yù)先訓(xùn)練的模型進(jìn)行微調(diào)。
這一年里,在這一領(lǐng)域中最激動(dòng)人心的事件恐怕要數(shù)BERT的發(fā)布,這是一種基于多語(yǔ)言轉(zhuǎn)換器的模型,它已經(jīng)在各種NLP項(xiàng)目中取得了令人矚目的成果。BERT是一種基于transformer架構(gòu)的雙向模型,它以一種速度更快的基于Attention的方法取代了RNN(LSTM和GRU)的sequential屬性。
該模型還在兩個(gè)無(wú)監(jiān)督任務(wù)(“遮蔽語(yǔ)言模型”和“下一句預(yù)測(cè)”)上進(jìn)行了預(yù)訓(xùn)練。這讓我們可以通過(guò)對(duì)下游特定任務(wù)(例如情緒分類,意圖檢測(cè),問(wèn)答等)進(jìn)行微調(diào)來(lái)使用預(yù)先訓(xùn)練的BERT模型。
本文將手把手教你,用BERT完成一個(gè)Kaggle競(jìng)賽。
在本文中,我們將重點(diǎn)介紹BERT在多標(biāo)簽文本分類問(wèn)題中的應(yīng)用。傳統(tǒng)的分類問(wèn)題假定每個(gè)文檔都分配給一個(gè)且只分配給一個(gè)類別,即標(biāo)簽。這有時(shí)也被稱為多元分類,比如類別數(shù)量是2的話,就叫做二元分類。
而多標(biāo)簽分類假設(shè)文檔可以同時(shí)獨(dú)立地分配給多個(gè)標(biāo)簽或類別。多標(biāo)簽分類具有許多實(shí)際應(yīng)用,例如業(yè)務(wù)分類或?yàn)殡娪胺峙涠鄠€(gè)類型。在客戶服務(wù)領(lǐng)域,此技術(shù)可用于識(shí)別客戶電子郵件的多種意圖。
我們將使用Kaggle的“惡意評(píng)論分類挑戰(zhàn)”來(lái)衡量BERT在多標(biāo)簽文本分類中的表現(xiàn)。
在本次競(jìng)賽中,我們將嘗試構(gòu)建一個(gè)能夠?qū)⒔o文本片段分配給同惡評(píng)類別的模型。我們?cè)O(shè)定了惡意評(píng)論類別作為模型的目標(biāo)標(biāo)簽,它們包括普通惡評(píng)、嚴(yán)重惡評(píng)、污言穢語(yǔ)、威脅、侮辱和身份仇視。
比賽鏈接:
https://www.kaggle.com/c/jigsaw-toxic-comment-classification-challenge
從哪開(kāi)始?
Google Research最近公開(kāi)了BERT 的tensorflow部署代碼,并發(fā)布了以下預(yù)訓(xùn)練模型:
BERT-Base, Uncased: 12層,768個(gè)隱藏單元,自注意力的 head數(shù)為12,110M參數(shù)
BERT-Large, Uncased:24層,1024個(gè)隱藏單元,自注意力的 head數(shù)為16,340M參數(shù)
BERT-Base, Cased:12層,768個(gè)隱藏單元,自注意力的 head數(shù)為12,110M參數(shù)
BERT-Large, Cased:24層,1024個(gè)隱藏單元,自注意力的 head數(shù)為16,340M參數(shù)
BERT-Base, Multilingual Cased (最新推薦):104種語(yǔ)言,12層,768個(gè)隱藏單元,自注意力的 head數(shù)為12,110M參數(shù)
BERT-Base, Chinese:中文(簡(jiǎn)體和繁體),12層,768個(gè)隱藏單元,自注意力的 head數(shù)為12,110M參數(shù)
編者注:這里cased和uncased的意思是在進(jìn)行WordPiece分詞之前是否區(qū)分大小寫(xiě)。uncased表示全部會(huì)調(diào)整成小寫(xiě),且剔除所有的重音標(biāo)記;cased則表示文本的真實(shí)情況和重音標(biāo)記都會(huì)保留下來(lái)。
我們將使用較小的Bert-Base,uncased模型來(lái)完成此任務(wù)。Bert-Base模型有12個(gè)attention層,所有文本都將由標(biāo)記器轉(zhuǎn)換為小寫(xiě)。我們?cè)?a href="http://www.1cnz.cn/tags/亞馬遜/" target="_blank">亞馬遜云 p3.8xlarge EC2實(shí)例上運(yùn)行此模型,該實(shí)例包含4個(gè)Tesla V100 GPU,GPU內(nèi)存總共64 GB。
因?yàn)槲覀€(gè)人更喜歡在TensorFlow上使用PyTorch,所以我們將使用來(lái)自HuggingFace的BERT模型PyTorch端口,這可從https://github.com/huggingface/pytorch-pretrained-BERT下載。我們已經(jīng)用HuggingFace的repo腳本將預(yù)先訓(xùn)練的TensorFlow檢查點(diǎn)(checkpoints)轉(zhuǎn)換為PyTorch權(quán)重。
我們的實(shí)現(xiàn)很大程度上是以BERT原始實(shí)現(xiàn)中提供的run_classifier示例為基礎(chǔ)的。
數(shù)據(jù)展示
數(shù)據(jù)用類InputExample來(lái)表示。
text_a:文本評(píng)論
text_b:未使用
標(biāo)簽:來(lái)自訓(xùn)練數(shù)據(jù)集的評(píng)論標(biāo)簽列表(很明顯,測(cè)試數(shù)據(jù)集的標(biāo)簽將為空)
class InputExample(object): """A single training/test example for sequence classification.""" def __init__(self, guid, text_a, text_b=None, labels=None): """Constructs a InputExample. Args: guid: Unique id for the example. text_a: string. The untokenized text of the first sequence. For single sequence tasks, only this sequence must be specified. text_b: (Optional) string. The untokenized text of the second sequence. Only must be specified for sequence pair tasks. labels: (Optional) [string]. The label of the example. This should be specified for train and dev examples, but not for test examples. """ self.guid = guid self.text_a = text_a self.text_b = text_b self.labels = labels
class InputFeatures(object): """A single set of features of data.""" def __init__(self, input_ids, input_mask, segment_ids, label_ids): self.input_ids = input_ids self.input_mask = input_mask self.segment_ids = segment_ids self.label_ids = label_ids
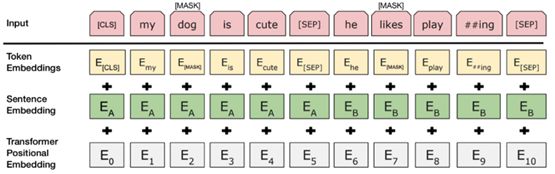
我們將InputExample轉(zhuǎn)換為BERT能理解的特征,該特征用類InputFeatures來(lái)表示。
input_ids:標(biāo)記化文本的數(shù)字id列表
input_mask:對(duì)于真實(shí)標(biāo)記將設(shè)置為1,對(duì)于填充標(biāo)記將設(shè)置為0
segment_ids:對(duì)于我們的情況,這將被設(shè)置為全1的列表
label_ids:文本的one-hot編碼標(biāo)簽
標(biāo)記化(Tokenisation)
BERT-Base,uncased模型使用包含30,522個(gè)單詞的詞匯表。標(biāo)記化過(guò)程涉及將輸入文本拆分為詞匯表中可用的標(biāo)記列表。為了處理不在詞匯表中的單詞,BERT使用一種稱為基于雙字節(jié)編碼(BPE,Byte-Pair Encoding)的WordPiece標(biāo)記化技術(shù)。
這種方法將不在詞匯表之中的詞一步步分解成子詞。因?yàn)樽釉~是詞匯表的一部分,模型已經(jīng)學(xué)習(xí)了這些子詞在上下文中的表示,并且該詞的上下文僅僅是子詞的上下文的組合,因此這個(gè)詞就可以由一組子詞表示。要了解關(guān)于此方法的更多詳細(xì)信息,請(qǐng)參閱文章《使用子詞單位的稀有單詞的神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯》。
文章鏈接:
https://arxiv.org/pdf/1508.07909
在我看來(lái),這與BERT本身一樣都是一種突破。
模型架構(gòu)
我們將改寫(xiě)B(tài)ertForSequenceClassification類以使其滿足多標(biāo)簽分類的要求。
class BertForMultiLabelSequenceClassification(PreTrainedBertModel): """BERT model for classification. This module is composed of the BERT model with a linear layer on top of the pooled output. """ def __init__(self, config, num_labels=2): super(BertForMultiLabelSequenceClassification, self).__init__(config) self.num_labels = num_labels self.bert = BertModel(config) self.dropout = torch.nn.Dropout(config.hidden_dropout_prob) self.classifier = torch.nn.Linear(config.hidden_size, num_labels) self.apply(self.init_bert_weights) def forward(self, input_ids, token_type_ids=None, attention_mask=None, labels=None): _, pooled_output = self.bert(input_ids, token_type_ids, attention_mask, output_all_encoded_layers=False) pooled_output = self.dropout(pooled_output) logits = self.classifier(pooled_output) if labels is not None: loss_fct = BCEWithLogitsLoss() loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1, self.num_labels)) return loss else: return logits def freeze_bert_encoder(self): for param in self.bert.parameters(): param.requires_grad = False def unfreeze_bert_encoder(self): for param in self.bert.parameters(): param.requires_grad = True
這里主要的改動(dòng)是用logits作為二進(jìn)制交叉熵的損失函數(shù)(BCEWithLogitsLoss),取代用于多元分類的vanilla交叉熵?fù)p失函數(shù)(CrossEntropyLoss)。二進(jìn)制交叉熵?fù)p失可以讓我們的模型為標(biāo)簽分配獨(dú)立的概率。
下面的模型摘要說(shuō)明了模型的各個(gè)層及其維度。
BertForMultiLabelSequenceClassification( (bert): BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(28996, 768) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): FusedLayerNorm(torch.Size([768]), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1) ) (encoder): BertEncoder( (layer): ModuleList(# 12 BertLayers (11): BertLayer( (attention): BertAttention( (self): BertSelfAttention( (query): Linear(in_features=768, out_features=768, bias=True) (key): Linear(in_features=768, out_features=768, bias=True) (value): Linear(in_features=768, out_features=768, bias=True) (dropout): Dropout(p=0.1) ) (output): BertSelfOutput( (dense): Linear(in_features=768, out_features=768, bias=True) (LayerNorm): FusedLayerNorm(torch.Size([768]), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1) ) ) (intermediate): BertIntermediate( (dense): Linear(in_features=768, out_features=3072, bias=True) ) (output): BertOutput( (dense): Linear(in_features=3072, out_features=768, bias=True) (LayerNorm): FusedLayerNorm(torch.Size([768]), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1) ) ) ) ) (pooler): BertPooler( (dense): Linear(in_features=768, out_features=768, bias=True) (activation): Tanh() ) ) (dropout): Dropout(p=0.1) (classifier): Linear(in_features=768, out_features=6, bias=True))
BertEmbeddings:輸入嵌入層
BertEncoder: 12個(gè)BERT模型attention層
分類器:我們的多標(biāo)簽分類器,out_features = 6,每個(gè)分類符對(duì)應(yīng)6個(gè)標(biāo)簽
模型訓(xùn)練
訓(xùn)練循環(huán)與原始BERT實(shí)現(xiàn)中提供的run_classifier.py里的循環(huán)相同。我們的模型訓(xùn)練了4個(gè)epoch(一個(gè)完整的數(shù)據(jù)集通過(guò)了神經(jīng)網(wǎng)絡(luò)一次并且返回了一次,這個(gè)過(guò)程稱為一個(gè) epoch),每批數(shù)據(jù)大小為32,序列長(zhǎng)度為512,即預(yù)訓(xùn)練模型的最大可能性。根據(jù)原始論文的建議,學(xué)習(xí)率保持在3e-5。
因?yàn)橛袡C(jī)會(huì)使用多個(gè)GPU,所以我們將Pytorch模型封裝在DataParallel模塊中,這使我們能夠在所有可用的GPU上進(jìn)行訓(xùn)練。
我們沒(méi)有使用半精度FP16技術(shù),因?yàn)槭褂胠ogits 損失函數(shù)的二進(jìn)制交叉熵不支持FP16處理。但這并不會(huì)影響最終結(jié)果,只是需要更長(zhǎng)的時(shí)間訓(xùn)練。
評(píng)估指標(biāo)
def accuracy_thresh(y_pred:Tensor, y_true:Tensor, thresh:float=0.5, sigmoid:bool=True): "Compute accuracy when `y_pred` and `y_true` are the same size." if sigmoid: y_pred = y_pred.sigmoid() return np.mean(((y_pred>thresh)==y_true.byte()).float().cpu().numpy(), axis=1).sum()
from sklearn.metrics import roc_curve, auc# Compute ROC curve and ROC area for each classfpr = dict()tpr = dict()roc_auc = dict()for i in range(num_labels): fpr[i], tpr[i], _ = roc_curve(all_labels[:, i], all_logits[:, i]) roc_auc[i] = auc(fpr[i], tpr[i])# Compute micro-average ROC curve and ROC areafpr["micro"], tpr["micro"], _ = roc_curve(all_labels.ravel(), all_logits.ravel())roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
我們?yōu)榫榷攘亢瘮?shù)增加了一個(gè)閾值,默認(rèn)設(shè)置為0.5。
對(duì)于多標(biāo)簽分類,更重要的指標(biāo)是ROC-AUC曲線。這也是Kaggle比賽的評(píng)分指標(biāo)。我們分別計(jì)算每個(gè)標(biāo)簽的ROC-AUC,并對(duì)單個(gè)標(biāo)簽的roc-auc分?jǐn)?shù)進(jìn)行微平均。
如果想深入了解roc-auc曲線,這里有一篇很不錯(cuò)的博客。
博客鏈接:
https://towardsdatascience.com/understanding-auc-roc-curve-68b2303cc9c5。
評(píng)估分?jǐn)?shù)
我們重復(fù)進(jìn)行了幾次實(shí)驗(yàn),每次都有一些輸入上的變化,但都得到了類似的結(jié)果,如下所示:
訓(xùn)練損失:0.022,驗(yàn)證損失:0.018,驗(yàn)證準(zhǔn)確度:99.31%。
各個(gè)標(biāo)簽的ROC-AUC分?jǐn)?shù):
普通惡評(píng):0.9988
嚴(yán)重惡評(píng):0.9935
污言穢語(yǔ):0.9988
威脅:0.9989
侮辱:0.9975
身份仇視:0.9988
微觀平均ROC-AUC得分:0.9987
這樣的結(jié)果似乎非常令人鼓舞,因?yàn)槲覀兛瓷先ヒ呀?jīng)創(chuàng)建了一個(gè)近乎完美的模型來(lái)檢測(cè)文本評(píng)論的惡毒程度。現(xiàn)在看看我們?cè)贙aggle排行榜上的得分。
Kaggle競(jìng)賽結(jié)果
我們?cè)贙aggle提供的測(cè)試數(shù)據(jù)集上運(yùn)行推理邏輯,并將結(jié)果提交給競(jìng)賽。以下是結(jié)果:

我們的roc-auc評(píng)分達(dá)到了0.9863,在所有競(jìng)爭(zhēng)者中排名前10%。為了使比賽結(jié)果更具說(shuō)服力,這次Kaggle比賽的獎(jiǎng)金為35000美元,而一等獎(jiǎng)得分為0.9885。
最高分的團(tuán)隊(duì)由專業(yè)的高技能數(shù)據(jù)科學(xué)家和從業(yè)者組成。除了我們所做的工作之外,他們還使用各種技術(shù)來(lái)進(jìn)行數(shù)據(jù)集成,數(shù)據(jù)增強(qiáng)(data augmentation)和測(cè)試時(shí)增強(qiáng)(test-time augmentation)。
結(jié)論和后續(xù)
我們使用強(qiáng)大的BERT預(yù)訓(xùn)練模型實(shí)現(xiàn)了多標(biāo)簽分類模型。正如我們所展示的那樣,模型在已熟知的公開(kāi)數(shù)據(jù)集上得到了相當(dāng)不錯(cuò)的結(jié)果。我們能夠建立一個(gè)世界級(jí)的模型生產(chǎn)應(yīng)用于各行業(yè),尤其是客戶服務(wù)領(lǐng)域。
對(duì)于我們來(lái)說(shuō),下一步將是使用“遮蔽語(yǔ)言模型”和“下一句預(yù)測(cè)”對(duì)下游任務(wù)的文本語(yǔ)料庫(kù)來(lái)微調(diào)預(yù)訓(xùn)練的語(yǔ)言模型。這將是一項(xiàng)無(wú)監(jiān)督的任務(wù),希望該模型能夠?qū)W習(xí)一些我們自定義的上下文和術(shù)語(yǔ),這和ULMFiT使用的技術(shù)類似。
資料鏈接:
https://nbviewer.jupyter.org/github/kaushaltrivedi/bert-toxic-comments-multilabel/blob/master/toxic-bert-multilabel-classification.ipynb
https://github.com/kaushaltrivedi/bert-toxic-comments-multilabel/blob/master/toxic-bert-multilabel-classification.ipynb
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4814瀏覽量
103814 -
數(shù)據(jù)庫(kù)
+關(guān)注
關(guān)注
7文章
3937瀏覽量
66374 -
Transformer
+關(guān)注
關(guān)注
0文章
151瀏覽量
6531
原文標(biāo)題:搞定NLP領(lǐng)域的“變形金剛”!手把手教你用BERT進(jìn)行多標(biāo)簽文本分類
文章出處:【微信號(hào):BigDataDigest,微信公眾號(hào):大數(shù)據(jù)文摘】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

美女手把手教你如何裝機(jī)(中)
手把手教你學(xué)習(xí)FPGA—LED篇
手把手教你安裝Quartus II
手把手教你學(xué)LabVIEW視覺(jué)設(shè)計(jì)
手把手教你開(kāi)關(guān)電源PCB排板






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)

評(píng)論