


MIT 深度學習課程系列(6.S091、6.S093、6.S094)。講座視頻與教程對所有人開放
作為麻省理工學院(MIT)深度學習講座系列與GitHub 教程的一部分,我們將介紹使用神經網絡解決計算機視覺、自然語言處理、游戲、自動駕駛、機器人等領域內問題的基礎知識。
本文以7 種架構范例簡要介紹深度學習,每種范例均提供 TensorFlow 教程鏈接。以下講座是 MIT 課程 6.S094 的一部分,其中介紹了深度學習基礎知識,而本文對其進行了說明。
深度學習是表征學習,即通過數據自動生成有用的表征。我們表述世界的方式可以使復雜事物簡單化,讓人類及我們構建的機器學習模型能夠容易理解。
我最喜歡的歷史示例是哥白尼于 1543 年發表的日心說模型。與先前以地球為中心的地心說模型不同,該模型將太陽置于 “宇宙” 的中心。在最佳情況下,深度學習讓我們可以自動處理此步驟,無需哥白尼(即人類專家)即可完成 “特征工程” 過程:

日心說(1543 年)與地心說(公元前 6 世紀)
從高層次來看,神經網絡可以是編碼器、解碼器或二者的結合:
-
編碼器會在原始數據中找到模式,以生成簡潔有用的表征
-
解碼器會利用這些表征生成高分辨率數據。所生成的數據是新示例或描述性知識
其余是一些巧妙方法,可幫助我們有效處理視覺信息、語言和音頻(范例 1 - 6),甚至可以幫助我們根據這些信息和偶爾的獎勵在現實世界中采取行動(范例 7)。以下是總體圖示:
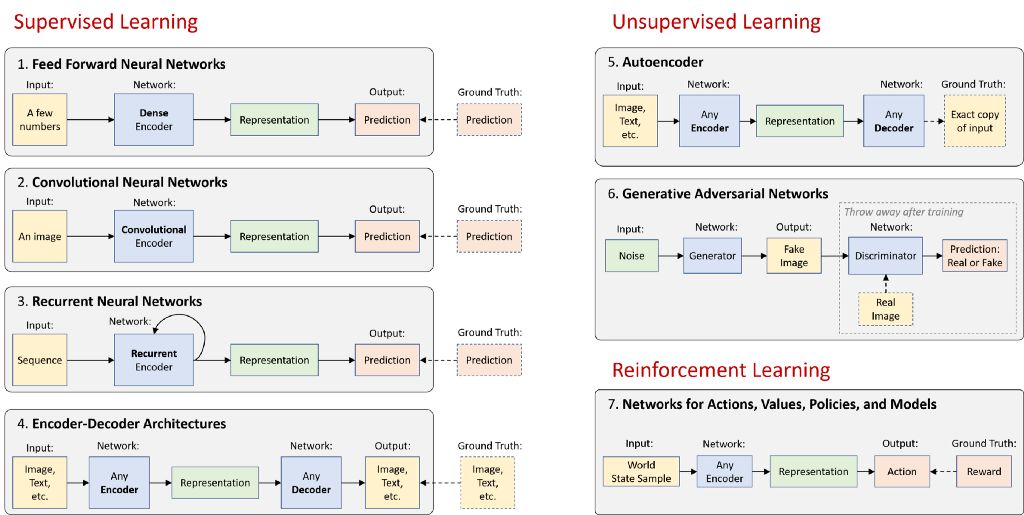
在下面的部分,我將分別簡要描述這 7 種架構范例,每種范例均提供 TensorFlow 教程鏈接,以作說明。請參閱本文結尾的 “基礎知識拓展” 部分,其中探討了一些令人興奮的深度學習領域,不完全屬于這 7 種類別。
1.前饋神經網絡 (FFNN)
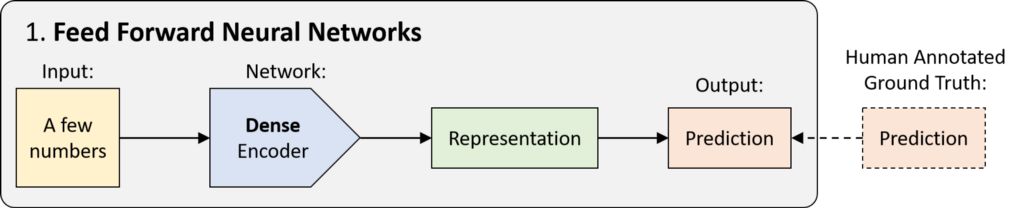
FFNN 的歷史可以追溯至 20 世紀 40 年代,只是一種沒有任何循環的網絡。數據以單次傳遞的方式從輸入傳遞至輸出,而沒有任何之前的 “狀態記憶”。從技術上講,深度學習中的大多數網絡均可被視為 FFNN,但 “FFNN” 通常指的是其最簡單的變體:一種密集連接的多層感知器 (MLP)。
密集編碼器用于將輸入上已經很緊湊一組數字映射至預測:分類(離散)或回歸(連續)數據。
TensorFlow 教程:請參閱 深度學習基礎知識教程 的第 1 部分,其中有一個用于預測波士頓房價的 FFNN 示例,屬于回歸問題:
注:深度學習基礎知識教程 鏈接
https://github.com/lexfridman/mit-deep-learning/blob/master/tutorial_deep_learning_basics/deep_learning_basics.ipynb
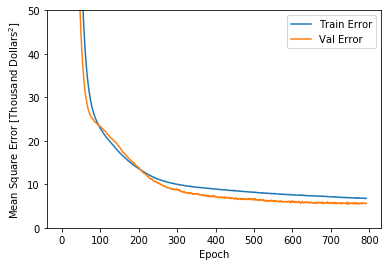
網絡學習過程中訓練集與驗證集中的錯誤
2.卷積神經網絡 (CNN)

CNN(又名 ConvNet)是一種前饋神經網絡,其使用空間不變性技巧來有效學習圖像中最常見的局部模式。舉例而言,若圖像左上方與右下方的貓耳擁有相同的特征,我們便可將其稱為空間不變性。CNN 可跨空間共享權重,從而更高效地檢測出貓耳及其他模式。
CNN 不是只使用密集連接層,而是使用卷積層(卷積編碼器)。這些網絡可用于圖像分類、對象檢測、視頻動作識別,以及任何在結構上具備一些空間不變性的數據(例如語音音頻)。
TensorFlow 教程:請參閱深度學習基礎知識教程的第 2 部分,了解用于對 MNIST 數據集中的手寫數字進行分類的 CNN 示例。我們利用影像變形技術創造夢幻般的精彩扭曲效果,并通過數據集之外生成的高分辨率手寫數字對分類器進行測試:
利用影像變形技術生成手寫數字(左側)并進行分類預測(右側)
3.遞歸神經網絡 (RNN)

RNN 是具有循環的網絡,因此具有 “狀態記憶”。這種網絡可適時展開,以成為共享權重的前饋網絡。正如 CNN 可跨 “空間” 共享權重一樣,RNN 可跨 “時間” 共享權重。這使其能夠處理并有效表示序列數據中的模式。
我們已開發出 RNN 模塊的許多變體(包括LSTM和GRU),以幫助學習較長序列中的模式。其應用包括自然語言建模、語音識別、語音生成等。
TensorFlow 教程:遞歸神經網絡的訓練頗具挑戰性,但同時也讓我們可以對序列數據進行一些有趣而強大的建模。利用 TensorFlow 生成文本是我最喜歡的教程之一,因為只需幾行代碼便可完成一些事情:逐字生成合理文本:
注:利用 TensorFlow 生成文本 鏈接
https://www.tensorflow.org/tutorials/sequences/text_generation
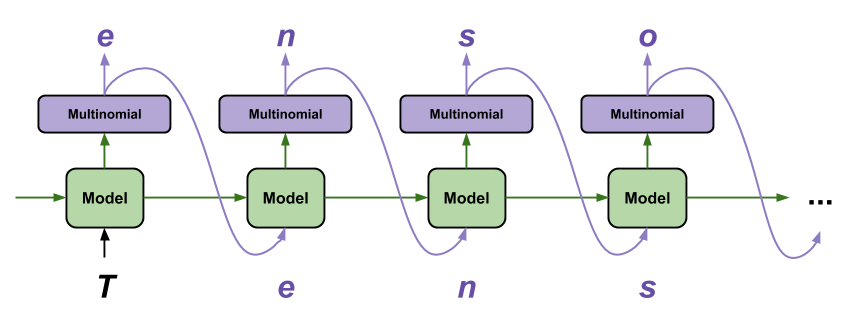
資料來源:利用 TensorFlow 生成文本
4.編碼器-解碼器架構

前 3 部分介紹的 FFNN、CNN 和 RNN 都只是分別使用密集編碼器、卷積編碼器或遞歸編碼器進行預測的網絡。這些編碼器可以組合或切換,具體取決于我們嘗試生成有用表征的原始數據類型。“編碼器 — 解碼器” 架構是一種更高層次的概念,此架構基于編碼步驟而構建,通過對壓縮表征進行上采樣的步驟來生成高維輸出,而不是進行預測。
請注意,編碼器與解碼器彼此之間可能大不相同。例如,圖像描述生成 (image captioning) 網絡可能采用卷積編碼器(用于圖像輸入)和遞歸解碼器(用于自然語言輸出)。其應用包括語義分割、機器翻譯等。
TensorFlow 教程:請參閱我們的 駕駛場景分割教程,其中展示了用于處理無人車輛感知問題的最先進分割網絡:
注:駕駛場景分割教程 鏈接
https://github.com/lexfridman/mit-deep-learning/blob/master/tutorial_driving_scene_segmentation/tutorial_driving_scene_segmentation.ipynb
教程:利用 TensorFlow 進行駕駛場景分割
5.自動編碼器
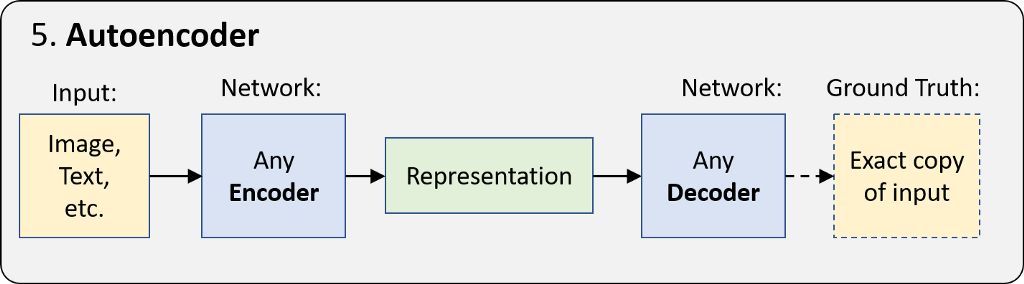
自動編碼器是其中一種更簡單的 “無監督學習” 形式,其采用編碼器 — 解碼器架構,并學習生成輸入數據的精確副本。由于編碼表征比輸入數據小得多,此網絡被迫學習如何生成最有意義的表征。
其 ground truth 數據來自輸入數據,因此無需人工操作。換言之,此網絡可自我監督。其應用包括無監督嵌入、圖像降噪等。但最重要的是,其 “表征學習” 的基本思想是下個部分的生成模型與所有深度學習的核心。
TensorFlow 教程:在這個TensorFlow Keras 教程中,您可以探索自動編碼器在以下兩方面的功能:(1) 對輸入數據進行降噪,(2) 在 MNIST 數據集中生成嵌入。
注:TensorFlow Keras 教程 鏈接
https://www.kaggle.com/vikramtiwari/autoencoders-using-tf-keras-mnist
6.生成對抗網絡 (GAN)
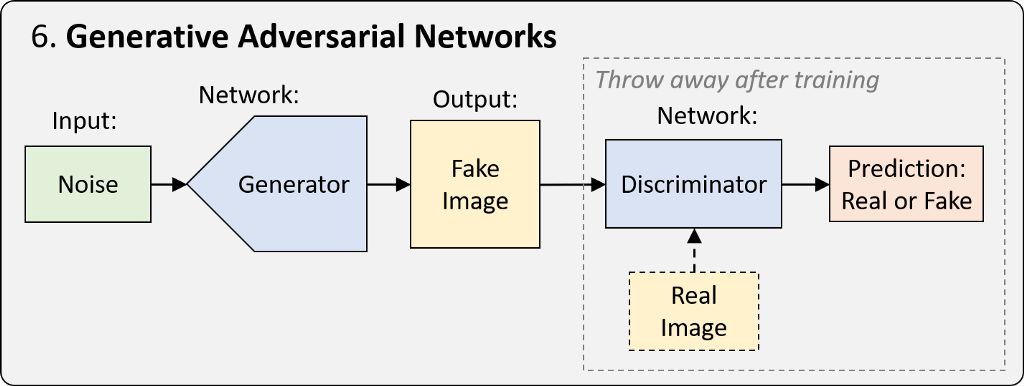
GAN 是一種訓練網絡框架,已經過優化,可以通過特定表征生成新的真實樣本。簡單而言,其訓練過程涉及兩個網絡。其中一個網絡稱為生成器 (generator),它會生成新的數據實例并試圖欺騙另一個網絡,即判別器 (discriminator),后者會對圖像的真偽進行分類。
在過去幾年,GAN 出現了許多變體和改進,包括從特定類別生成圖像的能力,以及將圖像從一個域映射到另一個域的能力,而且所生成圖像的真實度也有極大提升。請觀看有關 深度學習先進技術的講座,其中談及并探討了 GAN 的快速發展過程。例如,看看 BigGAN 從單個類別(毒蠅傘)中生成的三張樣本(arXiv 論文):
注:深度學習先進技術的講座 鏈接
https://www.youtube.com/watch?v=53YvP6gdD7UarXiv 論文 鏈接
https://arxiv.org/abs/1809.11096
BigGAN生成的圖像
TensorFlow 教程:如需 GAN 早期變體的示例,請參閱有關條件 GAN和DCGAN的教程。隨著課程的進展,我們將在GitHub上發布有關 GAN 先進技術的教程。
注:條件GAN 鏈接
https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/contrib/eager/python/examples/pix2pix/pix2pix_eager.ipynb
DCGAN 鏈接
https://github.com/tensorflow/tensorflow/blob/r1.11/tensorflow/contrib/eager/python/examples/generative_examples/dcgan.ipynb
7.深度強化學習 (Deep RL)
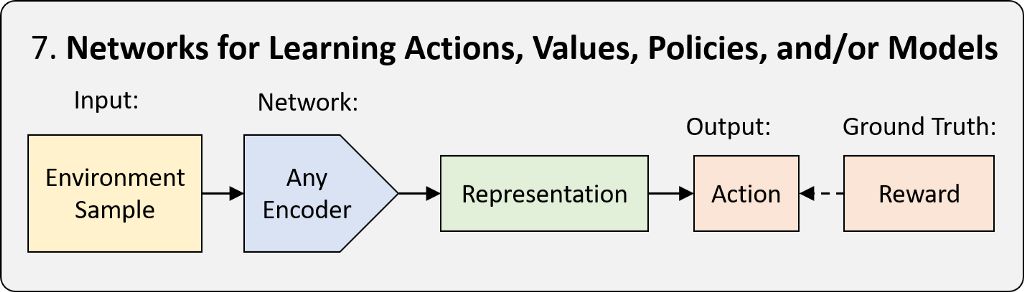
強化學習 (RL) 是一種框架,可以教導智能體如何以使獎勵最大化的方式在現實世界中采取行動。我們將由神經網絡完成的學習稱為深度強化學習 (Deep RL)。RL 框架有三種類型:基于策略、基于值和基于模型。三者的區別在于神經網絡需要學習的內容。如需了解更多詳情,請觀看 MIT 課程 6.S091 的Deep RL 簡介講座。當我們需要作出一系列決策時,可以借助 Deep RL 在模擬環境或真實環境中應用神經網絡。其中包括游戲操作、機器人、神經架構搜索等等。
注:Deep RL 簡介講座 鏈接
https://www.youtube.com/watch?v=zR11FLZ-O9M&list=PLrAXtmErZgOeiKm4sgNOknGvNjby9efdf
教程:我們的 DeepTraffic 環境提供了 教程 與 代碼示例,可以讓您快速地在瀏覽器中探索、訓練和評估 Deep RL 智能體。此外,我們很快將在GitHub上發布支持 GPU 訓練的 TensorFlow 教程:
注:教程 鏈接
https://selfdrivingcars.mit.edu/deeptraffic-documentation/
代碼示例 鏈接
https://github.com/lexfridman/deeptraffic
MIT DeepTraffic:深度強化學習競賽
基礎知識拓展
深度學習中有幾個重要概念并非由上述架構直接表示。例如,變分自編碼器 (VAE)、LSTM/GRU或神經圖靈機環境中的 “記憶” 概念、膠囊網絡、一般的注意力、遷移學習及元學習理念,以及 RL 中基于模型、基于值和基于策略的方法與 actor-critic 方法的區別。最后,許多深度學習系統以復雜的方式將這些架構結合起來,從而共同從多模態數據中學習,或共同學習解決多個任務。其中很多概念在本課程的其他講座中均有涉及,我們很快會介紹更多概念。
就個人而言,正如我在評論中所說,我很榮幸能有機會在 MIT 授課,并對加入 AI 和 TensorFlow 社區感到興奮不已。感謝大家在過去幾年的支持與熱烈討論。這是一次絕妙的旅程。如果您對我在未來的講座中應談及的主題有任何建議,請在Twitter或LinkedIn上告訴我。
-
MIT
+關注
關注
3文章
254瀏覽量
24393 -
深度學習
+關注
關注
73文章
5560瀏覽量
122753 -
tensorflow
+關注
關注
13文章
330瀏覽量
61153
原文標題:MIT 深度學習基礎知識:TensorFlow 簡介與概覽
文章出處:【微信號:tensorflowers,微信公眾號:Tensorflowers】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
怎么理解真正的編碼器和解碼器?
編碼器和解碼器的區別是什么,編碼器用軟件還是硬件好
詳解編碼器和解碼器電路:定義/工作原理/應用/真值表

PyTorch教程-10.6. 編碼器-解碼器架構

基于transformer的編碼器-解碼器模型的工作原理
基于 RNN 的解碼器架構如何建模
基于 Transformers 的編碼器-解碼器模型
神經編碼器-解碼器模型的歷史
詳解編碼器和解碼器電路
視頻編碼器與解碼器的應用方案





 工商網監
工商網監

評論