 講真,AI研究發表和模型開源,真的該制定一個規范了
講真,AI研究發表和模型開源,真的該制定一個規范了
深度學習界“最敢說的人”Yann LeCun再次放話,不過今天是提問:要是他早先能夠預料到如今CNN被濫用,比如制作DeepFake換臉假視頻,他當初還該不該開源CNN?講真,AI研究發表和模型開源,真的該制定一個規范了。
Yann LeCun今天在Twitter上提問:
講真,要是當初知道卷積神經網絡(CNN)會催生DeepFake,我們還要不要發表CNN?
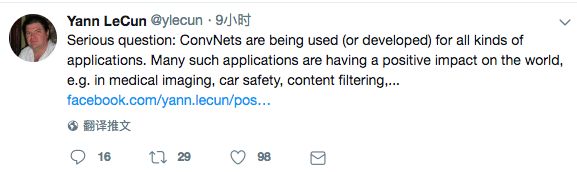
LeCun說:“問個嚴肅的問題:卷積神經網絡(CNN)被用于(或開發)各種各樣的應用。很多這樣的應用對世界起到了積極影響,例如,醫療影像、汽車安全、內容過濾、環境監控等等。
“但有的應用則可能起到負面的效果,或者說侵犯隱私,例如,公眾場所的人臉識別系統、進攻性武器,以及有偏見的“過濾”系統……
“那么,假設在上世紀80年代那時我們能夠預見CNN的這些負面影響,我們該不該把CNN模型保密不公開呢?
“幾點想法:
最終,CNN(或者類似的東西)還是會被其他人發明出來(實際上,有些人可以說差不多已經做到了)。其實,福島邦彥就跟我說,他80年代末的時候正在研究一種用BP訓練的新認知機(Neocogitron),但看到我們1989年發表的神經計算論文“大感震驚”(shocked),然后停止了他的項目。
開源CNN或深度學習軟件平臺直到2002年才出現(CNN是20世紀90年代早期商業軟件包SN和2002年開源的Lush軟件包的一項功能。20世紀90年代中后期才開始有OSS分發)。因此,在某種程度上,CNN直到2002年才完全發表(released)。但那時基本沒有什么人關注CNN,或者想到用Lush來訓練CNN。”
LeCun的這番話,可以說是為他此前的“表態”做出了完美的解釋。
是的,這里說的還是關于OpenAI模型開源的那件事。
LeCun:擔心模型太強大而不開源,干脆別研究AI
2月中旬,OpenAI宣布他們開發了一個通用文本生成模型GPT-2,擁有15億參數,使用了800萬網頁進行訓練,能夠同時完成文本生成、回答問題、總結摘要、機器翻譯等多項任務,有的時候效果甚至比專門的文本生成/問答/摘要總結等模型還要好。
接著,OpenAI用一個又一個的示例,充分展示了GPT-2模型有多強大,等到眾人迫不及待地要了解設計細節時,突然話鋒一轉,說他們擔心模型“太過強大”,開源后可能遭人濫用,這次決定不公布具體參數和訓練數據集,只是放出一個小很多的樣本模型供人參考。
誰料,OpenAI這一舉動引爆了整個AI圈,相比GPT-2模型本身,對于模型是否該開源的爭論在短時間內得到了更多的關注,NLP領域以外的研究人員和開發者也湊過來,而且“群眾的意見”幾乎是一邊倒的反對OpenAI,簡而言之:
擔心AI過于強大而不開源太矯情,這樣還不如一開始就別研究AI。
當時,LeCun不僅轉發了一條諷刺OpenAI的推文,還“火上澆油”地寫了個段子,大意是:可不能開源在MNIST數據集上精度99.99%的模型,這可能被人用來篡改郵編,發動垃圾郵件恐怖襲擊,那還得了。具體見下:
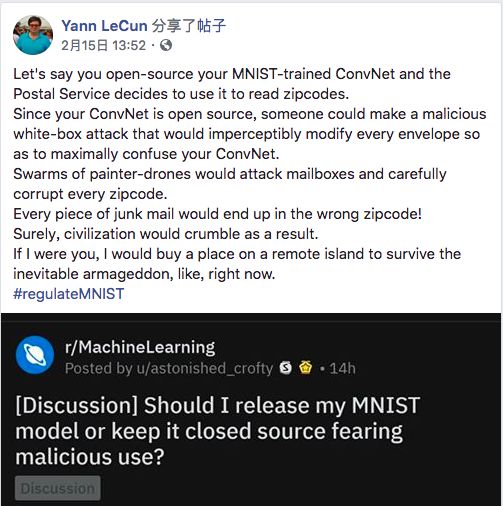
最終,LeCun對OpenAI不予開源的嘲諷發展到了極致:
“每個新生出來的人都可能造謠、傳播流言并影響其他人,那我們是不是該別生孩子了?”
這番言論實在稱不上嚴謹,甚至不能算“嚴肅”,但作為Facebook首席科學家、卷積神經網絡發明人和深度學習三巨頭之一,LeCun在如今的AI圈子里擁有巨大的影響力,他的這一表態迅速成為重磅砝碼,壓在了天平“反對不開源”的這邊,不僅堅定了此前站出來表示反對的人的信念,還影響了不少后來人的觀點。
關于模型開源,我們真正關注的應該是什么?
當然,現在業界的重點已經從最初的口水戰聚焦到AI研究發表和開源政策的討論上來。
LeCun或許也是希望用今天這個“serious question”來闡述自己當初過于簡單而容易被人誤會的表態。
大多數研究人員都同意,OpenAI決定不開源的出發點是好的,但給出的理由卻不盡人意:
首先,GPT-2模型是否真有那么強大?不公布細節無法證明這一點。這也是一開始口水戰的一大焦點,如果不給出細節,誰都可以站出來說我實現了強AI,但由于“擔心太過強大”,所以我不能發表。
插一句,從OpenAI公布的統計數據中可以看出,GPT-2不僅僅是“記住了”數據,而是確實具有更強的泛化性能。
其次,公開了模型設計和訓練數據集,是否就會被人拿去在網上“假言惑眾”?先拋開結果復現程度,但看訓練成本——OpenAI并沒有介紹訓練GPT-2模型的時間,但根據知情的研究人員透露,OpenAI取得了特許,使用谷歌TPU來訓練模型,1小時花費2048美元。這個費用不是一般人能承擔得起的,而能承擔起這種費用的,如果真要“作惡”,有大概率不需要借助開源模型。
最后,關于企業研究機構如何宣傳AI研究,如何面對公眾、媒體和研究人員等不同群體,OpenAI的做法也有一些爭議。DeepMind在最初介紹WaveNet,一個能合成與真人語音幾乎無二的強大語音生成模型的時候對于潛在危險只字不提,而OpenAI不但主動提出并且還想要牽頭制定AI研究發表的相關政策。這里說不出誰對誰錯,但OpenAI只給出一個郵箱地址,歡迎“感興趣的研究人員”聯系他們的做法是遠遠不夠的。
現在能夠肯定的是,關于AI研究發表和模型開源,相關的政策真的需要制定了。OpenAI在擔心模型被濫用時舉了DeepFake為例,DeepFake是基于CNN構建的圖像生成模型,由于強大的圖像生成能力,能夠生成以假亂真的人臉,甚至騙過先進的人臉識別模型。
那么回到LeCun一開始問的那個嚴肅的問題:
要是當初知道卷積神經網絡(CNN)會催生DeepFake,我們還要不要發表CNN呢?
-
AI
+關注
關注
87文章
31000瀏覽量
269333 -
深度學習
+關注
關注
73文章
5504瀏覽量
121246 -
cnn
+關注
關注
3文章
352瀏覽量
22238
原文標題:LeCun:30年前知道DeepFake,我還該不該開源CNN?
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Meta重磅發布Llama 3.3 70B:開源AI模型的新里程碑





 工商網監
工商網監
評論