 決策神經科學:解決機器人技術中的關鍵挑戰
決策神經科學:解決機器人技術中的關鍵挑戰
通過模仿人類大腦在日常生活中做出決策時使用的策略,可以顯著增強機器人智能。最近,科學家們找到了最新觀點。
本周五在國內上映的《阿麗塔:戰斗天使》又掀起了一波智能熱,這部由著導演詹姆斯·卡梅隆(James Cameron)擔任編劇和制片的電影,講述了擁有人類大腦、機械身軀的女主角,不斷改變世界、認識自我的故事。
這部背景發生在26世紀的電影,依舊把人類大腦作為承載智慧、情感和決策的關鍵能力。
而現在,一份來自韓國高等科學技術研究院(KAIST)、劍橋大學、日本國家信息通信技術研究所(NICT)和谷歌DeepMind的聯合研究認為,通過模仿人類大腦在日常生活中做出決策時使用的策略,可以顯著增強機器人智能,他們的方法是:將神經科學應用于機器人大腦。
最近,這項研究發表在了Science Robotics雜志上。
決策神經科學:解決機器人技術中的關鍵挑戰
人類和自主機器人不斷需要學習和適應新的環境。兩者的不同之處在于,人類能夠根據獨特情況做出決策,而機器人仍然依靠預定數據來做出決策,這是目前機器人的短板。
強化學習(RL)成為通過與世界交互來理解決策的主要理論框架,并且最近在構建具有超人類表現的智能體方面取得成功。然而,哪怕是最新的強化算法仍然存在很大的局限性,例如,缺乏制定目標導向策略的能力,或依賴大量經驗來學習。
這些限制阻礙了機器人在任務或背景頻繁變化的動態環境中快速適應的能力。
相比之下,人類在經驗有限的條件下迅速適應環境變化方面具有非凡的能力。決策神經科學(decision neuroscience)的最新發現表明,大腦不僅為RL使用多個控制系統,而且還使用一種靈活的元控制機制(metacontrol mechanism)來選擇控制選項,每個不同選項分別與預測性能、認知負荷和學習速度相關。
理解大腦如何實現這些選項可能會讓RL算法解決機器人的實際控制問題。
在Science Robotics上發表的研究中,研究人員討論了人類RL相關的最新發現,這些發現可能會解決機器人技術中的幾個關鍵挑戰:性能—效率—速度權衡、多機器人設置中的沖突需求以及探索—開發困境。
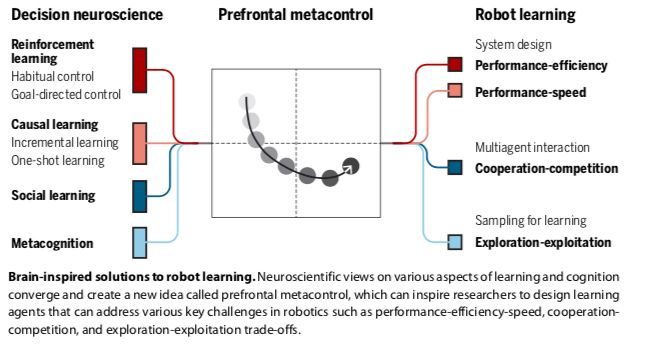
詳細解讀:元控制可以類似大腦
首先,決策神經科學的證據表明,人類利用兩種不同的行為控制策略:
刺激驅動的習慣性(stimulus--driven habitual);
目標導向的認知控制(goal--directed cognitive control)。
習慣性控制是自動且快速的,盡管它在不穩定的環境中很脆弱,并且能由model--free RL很好地解釋,model--free RL通過無環境模型下的試錯過程來逐步學習行為的價值。
相反,目標導向的控制可以迅速適應環境的變化,但它具有認知需求。它通過學習環境模型來指導行動,并利用這個知識庫快速適應環境結構的變化,例如學習狀態-行動空間中的潛在(隱藏)原因。
model--based RL和model--free RL之間的這種計算上的區別表明它們之間存在不可避免的妥協。model--free RL學習起來比較慢,但一旦策略被學習并實現自動化,就可以快速地實現目標。model--based RL通常比model--free RL提供更多的準確預測,但計算量要大得多。每種策略都提供了關于準確性、速度和認知負荷的互補解決方案,突出了預測性能和計算效率之間的權衡。
其次,RL算法通常需要大量經驗來充分學習不同環境因素下的因果關系(incremen-tal learning)。然而,人類的學習速度很快——通常一個從未經歷過的事件發生一次之后就已學習(“one--shot learn-ing”)。
神經科學最近的研究發現,當與環境的交互受到限制時,人類有很強的提高學習速度的傾向;他們會努力迅速弄清環境中未知的部分,即使這會危及安全。這些結果表明,大腦是直接執行計算來尋找性能和速度之間的權衡。
第三,越來越多的證據支持這樣一種觀點,即前額葉皮層使元控制能夠靈活地在不同的學習策略之間進行選擇,例如在model--based RL和model--free RL 之間,以及在incremental learning和one--shot learning之間。
在新的環境中,元控制通過選擇model--based RL來強調性能。因為這在計算上很昂貴,當大腦發現進一步學習沒有什么好處時,就會轉向model--free RL:要么環境非常穩定,可以做出精確的預測;要么高度不穩定,以至于基于模型的RL的預測不如無模型RL的預測可靠。
在其他情況下,元控制優先考慮速度。當預估的因果關系中的不確定性很高時,大腦傾向于轉換到one-shot學習,以快速解決預測結果中的不確定性。然而,當agent對所有可能的因果關系都同樣不確定時,它會重新轉向incremental learning以確保安全的學習。
這些機制表明類似于大腦的元控制可以處理性能-效率-速度的權衡。
第四,人類的RL可以解釋在人類進化中起重要作用的社會現象。在多主體相互作用的人類社會中,存在著具有部分競爭性和部分一致性激勵機制的社會困境。
使用model--based的RL方法成功地在更復雜的時間擴展設置中實現了協作。
人類似乎通過使用元認知(metacognition)來繞過這個問題——元認知是一種評估自己表現的能力,即評估自信和/或不確定性的水平。例如,較低的任務難度或較低的環境噪聲會使學習主體自信,從而導致更果斷的行動,而失去自信則會導致更謹慎和防御性的策略。元認知學習因此可以快速適應環境的變化,同時保持對環境噪聲的魯棒性。這樣的策略有可能增強機器人的決策能力。
總之,將人類決策神經科學的發現整合起來,可以為機器人的動作控制系統提供有價值的見解,從而實現更安全、更有能力、更高效的學習。
對大腦建模,算法能否支撐起意識?
另外,研究團隊還認為,這種跨學科的方法也應該引起神經科學的注意,為開發新的人類決策計算理論提供一個可靠的測試基礎。
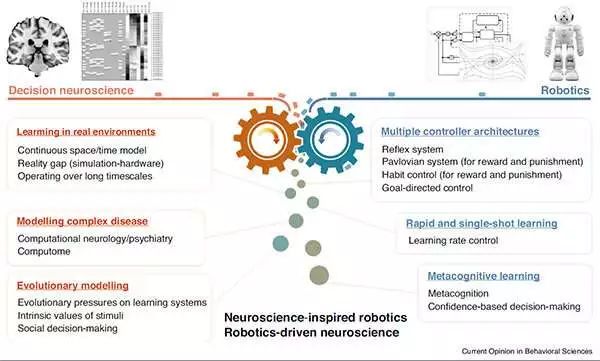
最近對焦慮、抑郁和成癮等精神疾病背后的興趣引起了很多人的興趣,這使得一系列復雜的理論在沒有某種先進的情境平臺的情況下難以測試。這種情況需要一種對人類大腦進行建模的方法,以找出它在現實生活中如何與世界相互作用,以測試這些模型中的不同異常是否以及如何引起某些疾病。
例如,如果我們可以在機器人中重現焦慮行為或強迫癥,那么就可以預測需要做些什么來治療。研究團隊預計,開發不同精神疾病的機器人模型,與研究人員現在使用動物模型的方式類似,將成為臨床研究的關鍵未來技術。
最后再回到電影《阿麗塔》。
電影中所有的機器人都擁有人類的生命、有機大腦。機器人能從脊髓或大腦直接將信號傳遞到假體中的代碼,使截癱或四肢癱瘓的人能夠隨著機器人技術的進步再次獲得行動能力。
如果放到現在的時代,這種技術看上去非常棒;但電影設定發生在五百年后,AI依然只是作為支撐軀體的技術,核心還是人類的大腦而不是由算法主導意識與行動,看來卡梅隆和羅德里格斯導演的腦洞還是小了點:)
-
控制系統
+關注
關注
41文章
6657瀏覽量
110796 -
機器人
+關注
關注
211文章
28632瀏覽量
208000 -
代碼
+關注
關注
30文章
4823瀏覽量
68900
原文標題:Science子刊:為機器人復制腦代碼,無限接近人類決策
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人的基礎模塊
《具身智能機器人系統》第10-13章閱讀心得之具身智能機器人計算挑戰
【「具身智能機器人系統」閱讀體驗】2.具身智能機器人大模型
【「具身智能機器人系統」閱讀體驗】1.初步理解具身智能
【「具身智能機器人系統」閱讀體驗】1.全書概覽與第一章學習
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
【「具身智能機器人系統」閱讀體驗】+數據在具身人工智能中的價值
【「具身智能機器人系統」閱讀體驗】+初品的體驗
《具身智能機器人系統》第1-6章閱讀心得之具身智能機器人系統背景知識與基礎模塊
虹科攜手Seed Robotics,開啟機器人靈巧手合作新篇章

名單公布!【書籍評測活動NO.51】具身智能機器人系統 | 了解AI的下一個浪潮!
機器人神經網絡系統的特點包括
機器人神經網絡控制原理是什么
「探索」康復機器人在神經康復中的應用






 工商網監
工商網監
評論