 計算機視覺市場未來規模超200億美元
計算機視覺市場未來規模超200億美元
近日,Forrester咨詢公司對中國計算機視覺及智能影像市場進行了調查,訪問了包括研究機構、科研院校、投資機構以及部分互聯網企業,視頻行業企業,針對以視頻行業為代表的文娛產業中人工智能的應用趨勢、面臨的挑戰進行了分析,并提出相應的戰略建議。
網易智能節選整理如下:
近年來,在互聯網、大數據、超級計算、傳感網、腦科學等新理論、新技術以及經濟社會發展強烈需求的共同驅動下,人工智能呈現出飛躍式的進步,進入新的發展階段。無論是企業還是政府在人工智能方面的關注和投入,都在不同層面推動著人工智能技術和應用的蓬勃發展。各種創新的AI應用逐步開始進入社會生活的各個場景。
同時,我們也看到,新興科技正在推動新一輪全球產業變革,而人工智能毫無疑問成為了釋放產業變革潛能的重要力量。作為人工智能技術的重要分支,計算機視覺技術在算法、數據及算力的加持下,更是得到了飛速的發展,已經具備大規模應用的可行性。特別是在文娛產業得到了廣泛應用的智能影像技術已經成為行業變革的核心驅動力,將進一步催生新應用、新產品、新產業、新業態、新模式的出現,推動智能影像產業生態的繁榮。
01
調查結果摘要
人工智能為影像分析技術帶來變革。人工智能在影像行業的綜合應用,特別是通過對動態視覺內容的理解和重構,是計算機視覺技術及計算機動畫技術的交叉和融合,給智能影像產業帶來了充滿想象力的廣闊舞臺和空間。
智能影像技術為產業變革帶來強勁動力。過去幾年文娛產業經歷了快速的發展,以內容制作方、視頻平臺方為代表行業參與者正面臨著諸多的挑戰,各方仍在行業變局中摸索前行,期望不斷通過運用新興技術和應用的創新提升自身的核心競爭力。智能影像技術在行業的應用日漸深入,成為新一輪行業變革的核心驅動力。
把握數字化轉型新契機,智能影像技術加速業務變革。智能影像技術不僅成為文娛產業商業價值變現的核心引擎,也在逐漸進入更多的內容原創領域,通過自動化影像加工、生產技術為產業升級提供動力。而且,智能影像技術也通過全面賦能推動應用在教育、零售等更多領域落地,成為行業價值創新的基石。
深耕行業場景,聚焦價值創造,拓展行業生態。智能影像技術企業需要聚焦行業實踐、商業價值閉環,以及開放性平臺技術,推動智能影像行業的協同發展和生態的進一步繁榮。
02
智能影像技術的發展歷程
2006年以來,隨著深度學習技術的進展,人工智能再次獲得了廣泛關注。特別在圖像領域,深度學習帶來的突破性效果在很多領域已經超過人類水平,各種類型的神經網絡不斷涌現,伴隨著計算力的提升以及海量數據的積累,人工智能為廣闊的圖像分析領域帶來深刻變革。資本市場對與計算機視覺的熱度空前高漲。
根據Forrester統計,全球在計算機視覺領域的投資持續增長,截止到2018年11月末投資較2017年增長113%,在過去的五年中復合增長率高達135%,在本次訪談調研中了解到,未來五年內全球計算機視覺軟件及服務市場規模將超過200億美金。
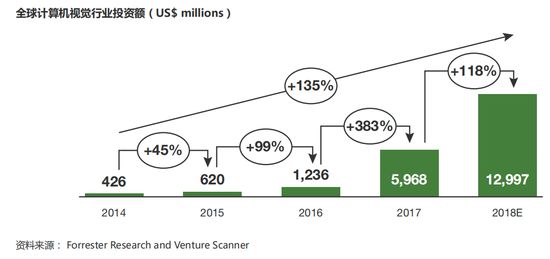
影像相關的市場規模相當可觀,人工智能技術的賦能將會催生更多商業場景,進一步推動整體市場繁榮。在眾多細分領域中,智能影像生產技術直接從源頭上提高了視頻影像的生產能力。除了與影像源頭密切相關的文娛產業,智能影像還將賦能廣告營銷、教育、游戲、零售乃至制造等相關行業。
影像生產技術以計算機視覺(Computer Vision) 與計算機圖形學為基礎。計算機視覺誕生于上世紀六十年代,是指能夠賦予機器自然視覺能力的學科,關注圖像的識別和分割。在初步興起的二十年時間里,“識別”領域進展有限,而分割領域取得了一定的進展。進入本世紀,隨著互聯網的不斷發展,圖片的來源日趨豐富,各類圖像數據庫開始出現,標注數據進一步促進計算機視覺的發展。
在深度學習廣泛應用之前,視覺算法一般分為:特征感知、圖像預處理、特征提取、特征篩選、推理與識別。手工設計特征需要對相關領域具有足夠的積累和經驗,對于提取的特征還需要進行大量調試工作。不同的特征對應的后端機器學習算法也有所不同。二者組合起來,通用性差而且需要投入大量工程性工作,進展緩慢且效果不佳,與人類水平有很大差距,遲遲難以大規模商用,對于圖像之外的多模態感知識別更是困難重重。
計算機圖形學(Computer Graphics)是指在計算機上用專門的軟件和硬件用來表現和控制圖像數據,它同樣誕生于上世紀六十年代。自誕生之初開始即開始踴躍發展,分形理論、曲面造型技術、光柵圖形學算法、光照模型、光線追蹤算法、輻射度算法等技術手段陸續被提出。80年代中期,皮克斯使用SGI計算機創作了第一段完全用計算機生成的短片。1995年首部計算機生成的動畫影片《玩具總動員》全球上映,1996年最早的全三維游戲《雷神之錘》發售。
一些事實標準的出現,如SGI公司開發的OpenGL開放式三維圖形標準,微軟公司的標準接口DirectX,Adobe公司的Postscript等,進一步加速了影像生產的產業化進程。但是,影像生產中大量人工仍然不可避免,具體到面向大眾的個性化影像生產而言,重復性的人力勞動已經嚴重制約了產能,亟需智能化、自動化的影像生產技術推動產業的升級。
03
智能影像生產技術的發展現狀
Forrester對人工智能技術進行分類研究時采用了Sense、Act、Think的框架。類比來看,在感知(Sense)層面,人工智能技術為靜態圖片識別乃至多模態影像識別帶來了突破;在思考(Think)層面,基于多模態識別結合商業需求可以形成深入的影像智能化理解。以感知、思考為基礎,在行動(Act)層面,人工智能技術為自動化影像生產帶來了強勁動力。為此,我們將智能影像生產技術分為兩部分:影像智能化理解(Sense和Think)和影像自動化生成(Act)。

傳統的計算機視覺技術大量聚焦在特征生成和選擇。端到端深度學習帶來了自動特征學習能力,從而極大促進了計算機視覺的發展。深度學習所需的大量訓練數據以及運算能力在當下也得到了良好的供應。對于“識別”這種人類無需思考即可在極短時間內作出判斷的任務目前是人工智能最擅長的領域。從包括圖像、語音、文字的多模態識別,人工智能對于影 像感知和理解能力不斷提升,推動了智能影像產業的快速發展。

此外,各種神經網絡的組合為靜態圖像識別提供了有力武器。憑借著AlexNet在ILSVRC競賽的一戰成名,卷積神經網絡(CNN)因其良好的泛化能力以及優秀的實際效果已經替代了眾多傳統計算機視覺算法,成為當前圖像識別領域的主流。
在此基礎上,ResNet、Inception、Xception、DenseNet、ShuffleNet等多種改良結構也不斷涌現,推動了識別效果的進一步提高,在大規模人臉與人體識別、物體檢測與追蹤、3D視覺等領域都獲得了廣泛應用,已經達到了可以廣泛實際落地的程度,甚至有的受訪者表示這類任務的性能一定程度上已經達到飽和。
圖像、語音、文本等多模態識別進一步豐富了影像識別能力。深度學習不僅賦能了計算機視覺領域,還為語音識別、文本分析領域帶來突破。循環神經網絡(RNN)及其變種LSTM在這些領域取得令人矚目的進展而成為主流。以此為基礎,各種增強技術如雙向LSTM、Attention model等也開始得以廣泛應用。深度學習的理論基礎在“去黑盒化”的 道路上已經取得進展,各種技術的組合為也不斷刷新著各類任務的效果新高。多模態識別已成為計算機視覺和AI最令人激動的領域之一,現有感知能力甚至已經超出商業變現的步伐。尋找應用場景、促進技術落地的難度開始大于技術本身。
影像語義理解增加了商業模式的可能性。通過視頻結構化分析、目標檢測跟蹤、動作態勢感知、人物識別以及情感分析等多模態感知技術,人類已經可以從動態影像中獲取淺層信息。但是要做到商業模式變現,仍需進一步從語義的層面深入理解影像內容。
在這一領域,需要有大量的行業積累,例如對綜藝類視頻節目中人物、物體等的識別標注,需要專業的經驗,基于編劇、布景、拍攝等角度,對視頻進行結構化建模進行分析和學習,把特征空間提升到語義空間。在此基礎上對影像數據生成語義標簽、業務分類乃至文字描述以供后續業務場景使用。常識的建立可以極大提升機器性能,既有經驗與多種深度網絡的融合將會形成企業差異化的競爭優勢。
04
智能影像行業案例
Netflix:總部位于美國加州的Netflix成立于1997年,是一家在線影片服務提供商。Netflix以投入優質內容吸引用戶,通過用戶加入會員付費觀看內容獲取收入。但近年來面臨新增用戶增長放緩以及內容成本急劇攀升的壓力,Netflix 2018Q2新增了447萬國際用戶和67萬美國用戶,低于Q1的500萬和120萬。隨著用戶對內容的要求越來越高,在線視頻平臺圍繞優質內容進行競爭,內容正成為流量入口,Netflix也不例外,投入大量資源自己制作的內容,代表作包括《紙牌屋》,《怪奇物語》等。用戶對視頻形態也發生了變化,隨著用戶的觀看視頻的時間碎片化,短視頻、倍速觀看、跨屏看等等的個性化和自主化趨勢對體驗提出了更高挑戰。
在這個挑戰下,Netflix在繼續加大對原創內容投入的同時,積極嘗試并希望通過機器學習、神經網絡和深度學習、計算機視覺等新興AI技術, 保持行業優勢,優化內部運營。
Netflix嘗試將人工智能應用在核心系統上,帶來的直接效果就是付費用戶超過1億,推薦引擎提高3到4倍的點擊率。同時,通過對視頻及客戶觀影數據的分析,避免購買低收益的視頻內容,累計已經實現了超過十億美元的內容成本的節省。
影譜科技(Moviebook):他們通過整合視頻類渠道,覆蓋了各硬件終端與計算機芯片、貫穿可視化場景,其智能影像生產技術具有批量自動化處理、子像素級分析、智能疊加和無痕展示等特征。
在人工智能業務領域,Moviebook通過Vedio AI制作引擎,實現影像內容生產制作的“從視頻中捕獲動作”Motion Capture from Video System(MCVS)框架。MCVS無需預先進行動作捕捉合成的高度結構化數據,就可以讓機器直接模仿大量已存視頻片段來學習高難度技能,允許數據為驅動的模仿以生成無監督學習視頻內容。

該系統MCVS每天可以處理日常視頻網絡上的數百萬端視頻圖像,提取關鍵幀,進行自動結構化,為下游任務提供大量數字化資源,如視頻搜索、原生視頻內容營銷、視頻內容創作、視頻識別、游戲生產、在線教育等。
迪士尼:迪士尼研究院的一項內部研究,正在改變影片和VR的創作。過去,拍攝影片或開發一款VR游戲/內容,都需要先有劇本描述人物及場景等,但文字難以直觀地描述復雜場景,這一步驟將耗費大量時間。為了在編寫故事的過程中協助編劇,迪士尼開發了一個系統,可以從自然語言故事中提取信息,并允許以故事為中心以及以人物為中心的推理。這些推理功能通過直觀的查詢系統向創作人員開放,允許腳本編寫者向系統詢問有關故事和角色信息的問題,并形成可視化的動畫或簡單視頻的展示,導演更直觀地了解角色將如何在場景中進行表演,以及腳本的變化會怎樣影響場景。
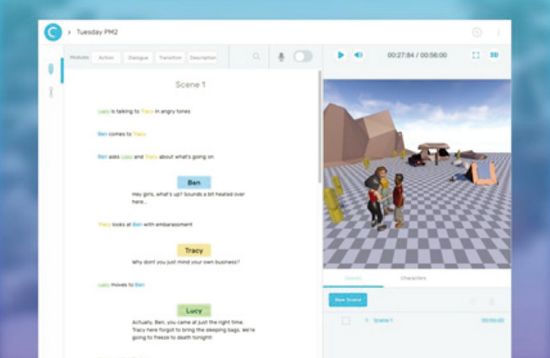
這項技術將應用在電影的創作和拍攝中,通過初步自動生成簡單動畫,進行現場整合及語音錄制,然后戴上ⅤR頭顯直接在虛擬場景中進行預覽,提供“親臨”影片故事場景的體驗,制作人員還可移動預覽場景中的虛擬人物角色的位置。這項技術將與迪士尼的數字影像、人工智能以及特效技術整合用于電影的創作制作以及后期過程。
-
人工智能
+關注
關注
1791文章
47183瀏覽量
238266 -
計算機視覺
+關注
關注
8文章
1698瀏覽量
45980
原文標題:計算機視覺及智能影像報告:未來規模超200億美元
文章出處:【微信號:AItists,微信公眾號:人工智能學家】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
計算機視覺有哪些優缺點
計算機視覺的五大技術
計算機視覺的工作原理和應用
計算機視覺與人工智能的關系是什么
計算機視覺與智能感知是干嘛的
計算機視覺的主要研究方向
微軟和OpenAI計劃投資1000億美元建造“星際之門”AI超級計算機
【量子計算機重構未來 | 閱讀體驗】+ 初識量子計算機
計算機視覺的十大算法

特斯拉在布法羅超級工廠投資5億美元建造Dojo超級計算機
中國計算機主板市場規模產業鏈分析





 工商網監
工商網監
評論