 探析深度學習中的各種卷積
探析深度學習中的各種卷積
如果你聽說過深度學習中不同種類的卷積(比如 2D / 3D / 1x1 /轉置/擴張(Atrous)/空間可分/深度可分/平展/分組/混洗分組卷積),并且搞不清楚它們究竟是什么意思,那么這篇文章就是為你寫的,能幫你理解它們實際的工作方式。
一、卷積與互相關
在信號處理、圖像處理和其它工程/科學領域,卷積都是一種使用廣泛的技術。在深度學習領域,卷積神經網絡(CNN)這種模型架構就得名于這種技術。但是,深度學習領域的卷積本質上是信號/圖像處理領域內的互相關(cross-correlation)。這兩種操作之間存在細微的差別。
無需太過深入細節,我們就能看到這個差別。
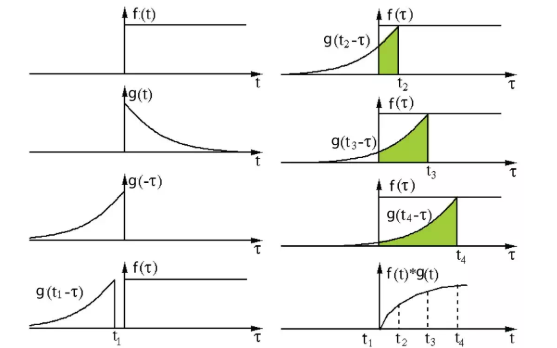
其定義是兩個函數中一個函數經過反轉和位移后再相乘得到的積的積分。下面的可視化展示了這一思想:
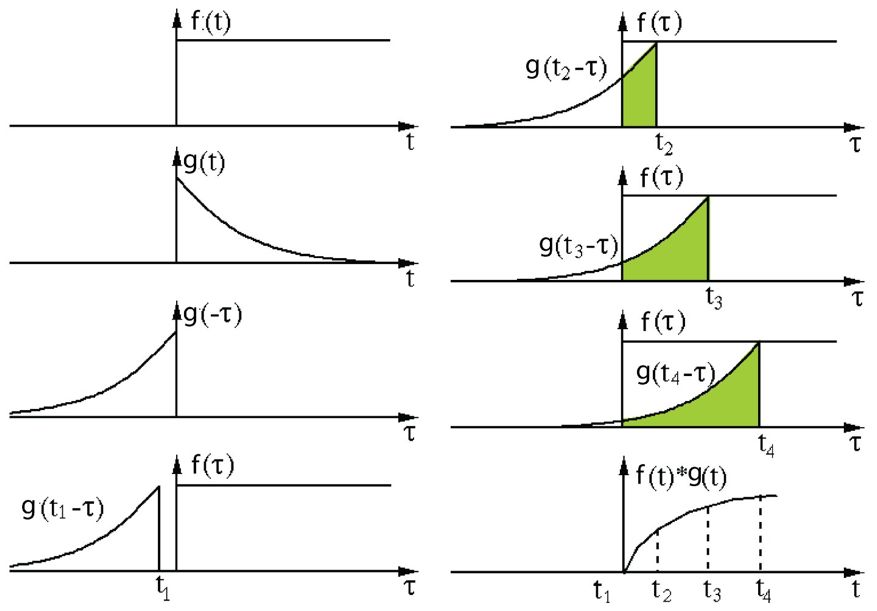
信號處理中的卷積。過濾器 g 經過反轉,然后再沿水平軸滑動。在每一個位置,我們都計算 f 和反轉后的 g 之間相交區域的面積。這個相交區域的面積就是特定位置出的卷積值。
這里,函數 g 是過濾器。它被反轉后再沿水平軸滑動。在每一個位置,我們都計算 f 和反轉后的 g 之間相交區域的面積。這個相交區域的面積就是特定位置出的卷積值。
另一方面,互相關是兩個函數之間的滑動點積或滑動內積。互相關中的過濾器不經過反轉,而是直接滑過函數 f。f 與 g 之間的交叉區域即是互相關。下圖展示了卷積與互相關之間的差異。
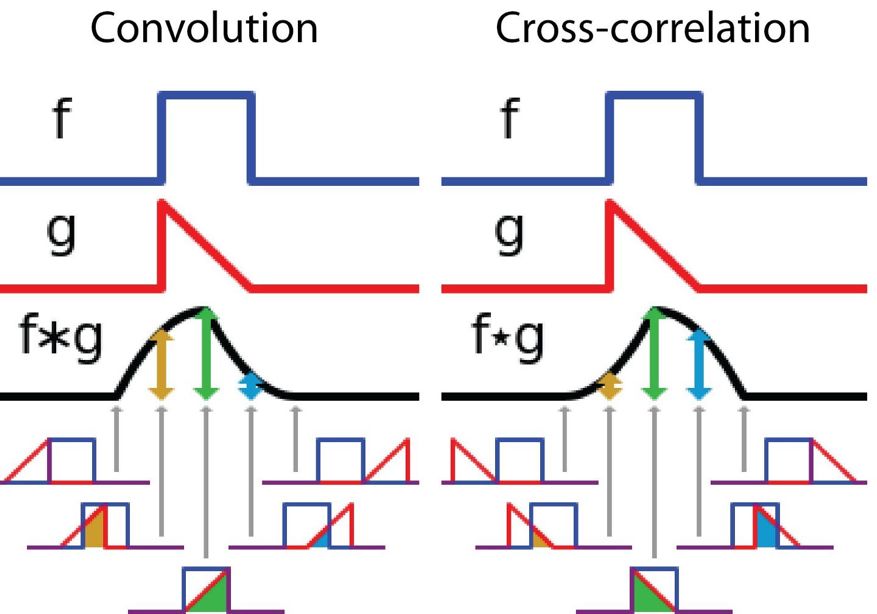
信號處理中卷積與互相關之間的差異
在深度學習中,卷積中的過濾器不經過反轉。嚴格來說,這是互相關。我們本質上是執行逐元素乘法和加法。但在深度學習中,直接將其稱之為卷積更加方便。這沒什么問題,因為過濾器的權重是在訓練階段學習到的。如果上面例子中的反轉函數 g 是正確的函數,那么經過訓練后,學習得到的過濾器看起來就會像是反轉后的函數 g。因此,在訓練之前,沒必要像在真正的卷積中那樣首先反轉過濾器。
二、3D 卷積
在上一節的解釋中,我們看到我們實際上是對一個 3D 體積執行卷積。但通常而言,我們仍在深度學習中稱之為 2D 卷積。這是在 3D 體積數據上的 2D 卷積。過濾器深度與輸入層深度一樣。這個 3D 過濾器僅沿兩個方向移動(圖像的高和寬)。這種操作的輸出是一張 2D 圖像(僅有一個通道)。
很自然,3D 卷積確實存在。這是 2D 卷積的泛化。下面就是 3D 卷積,其過濾器深度小于輸入層深度(核大小<通道大小)。因此,3D 過濾器可以在所有三個方向(圖像的高度、寬度、通道)上移動。在每個位置,逐元素的乘法和加法都會提供一個數值。因為過濾器是滑過一個 3D 空間,所以輸出數值也按 3D 空間排布。也就是說輸出是一個 3D 數據。
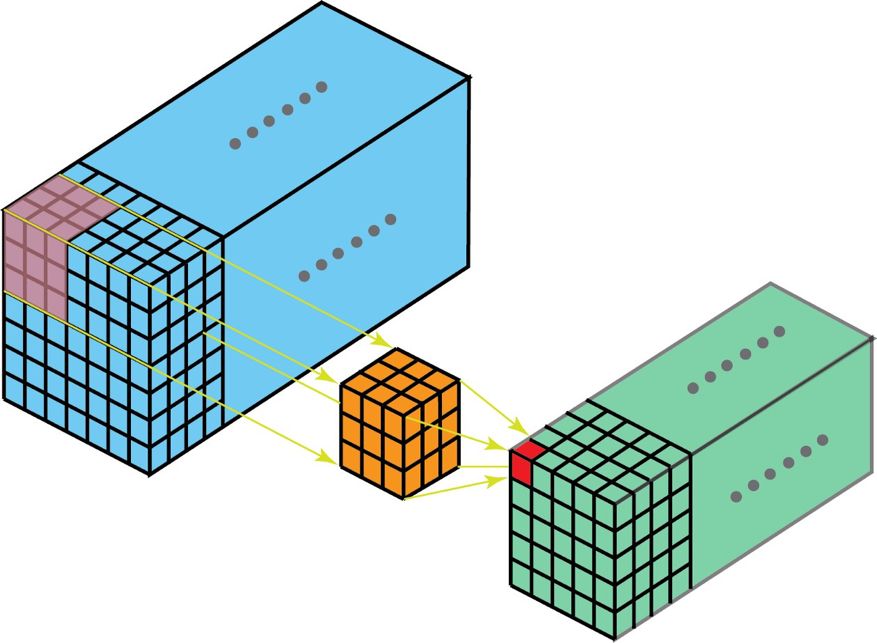
在 3D 卷積中,3D 過濾器可以在所有三個方向(圖像的高度、寬度、通道)上移動。在每個位置,逐元素的乘法和加法都會提供一個數值。因為過濾器是滑過一個 3D 空間,所以輸出數值也按 3D 空間排布。也就是說輸出是一個 3D 數據。
與 2D 卷積(編碼了 2D 域中目標的空間關系)類似,3D 卷積可以描述 3D 空間中目標的空間關系。對某些應用(比如生物醫學影像中的 3D 分割/重構)而言,這樣的 3D 關系很重要,比如在 CT 和 MRI 中,血管之類的目標會在 3D 空間中蜿蜒曲折。
三、轉置卷積(去卷積)
對于很多網絡架構的很多應用而言,我們往往需要進行與普通卷積方向相反的轉換,即我們希望執行上采樣。例子包括生成高分辨率圖像以及將低維特征圖映射到高維空間,比如在自動編碼器或形義分割中。(在后者的例子中,形義分割首先會提取編碼器中的特征圖,然后在解碼器中恢復原來的圖像大小,使其可以分類原始圖像中的每個像素。)
實現上采樣的傳統方法是應用插值方案或人工創建規則。而神經網絡等現代架構則傾向于讓網絡自己自動學習合適的變換,無需人類干預。為了做到這一點,我們可以使用轉置卷積。
轉置卷積在文獻中也被稱為去卷積或 fractionally strided convolution。但是,需要指出「去卷積(deconvolution)」這個名稱并不是很合適,因為轉置卷積并非信號/圖像處理領域定義的那種真正的去卷積。從技術上講,信號處理中的去卷積是卷積運算的逆運算。但這里卻不是這種運算。因此,某些作者強烈反對將轉置卷積稱為去卷積。人們稱之為去卷積主要是因為這樣說很簡單。后面我們會介紹為什么將這種運算稱為轉置卷積更自然且更合適。
我們一直都可以使用直接的卷積實現轉置卷積。對于下圖的例子,我們在一個 2×2 的輸入(周圍加了 2×2 的單位步長的零填充)上應用一個 3×3 核的轉置卷積。上采樣輸出的大小是 4×4。
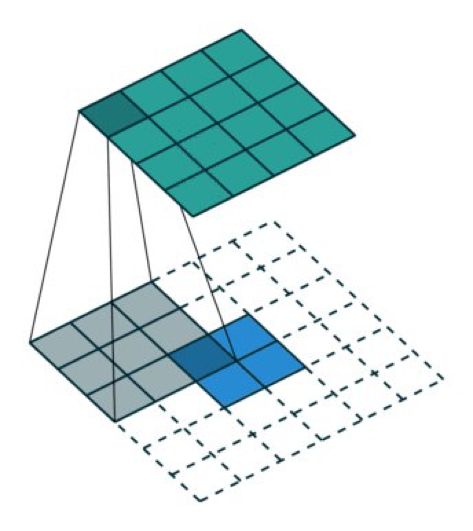
將 2×2 的輸入上采樣成 4×4 的輸出
有趣的是,通過應用各種填充和步長,我們可以將同樣的 2×2 輸入圖像映射到不同的圖像尺寸。下面,轉置卷積被用在了同一張 2×2 輸入上(輸入之間插入了一個零,并且周圍加了 2×2 的單位步長的零填充),所得輸出的大小是 5×5。
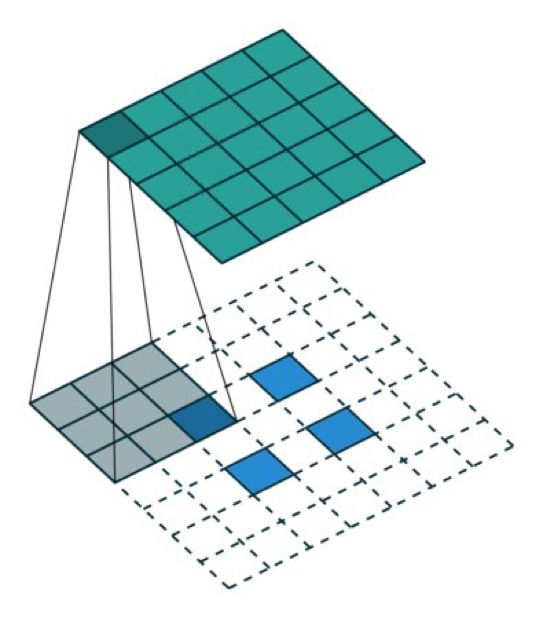
將 2×2 的輸入上采樣成 5×5 的輸出
觀察上述例子中的轉置卷積能幫助我們構建起一些直觀認識。但為了泛化其應用,了解其可以如何通過計算機的矩陣乘法實現是有益的。從這一點上我們也可以看到為何「轉置卷積」才是合適的名稱。
在卷積中,我們定義 C 為卷積核,Large 為輸入圖像,Small 為輸出圖像。經過卷積(矩陣乘法)后,我們將大圖像下采樣為小圖像。這種矩陣乘法的卷積的實現遵照:C x Large = Small。
下面的例子展示了這種運算的工作方式。它將輸入平展為 16×1 的矩陣,并將卷積核轉換為一個稀疏矩陣(4×16)。然后,在稀疏矩陣和平展的輸入之間使用矩陣乘法。之后,再將所得到的矩陣(4×1)轉換為 2×2 的輸出。
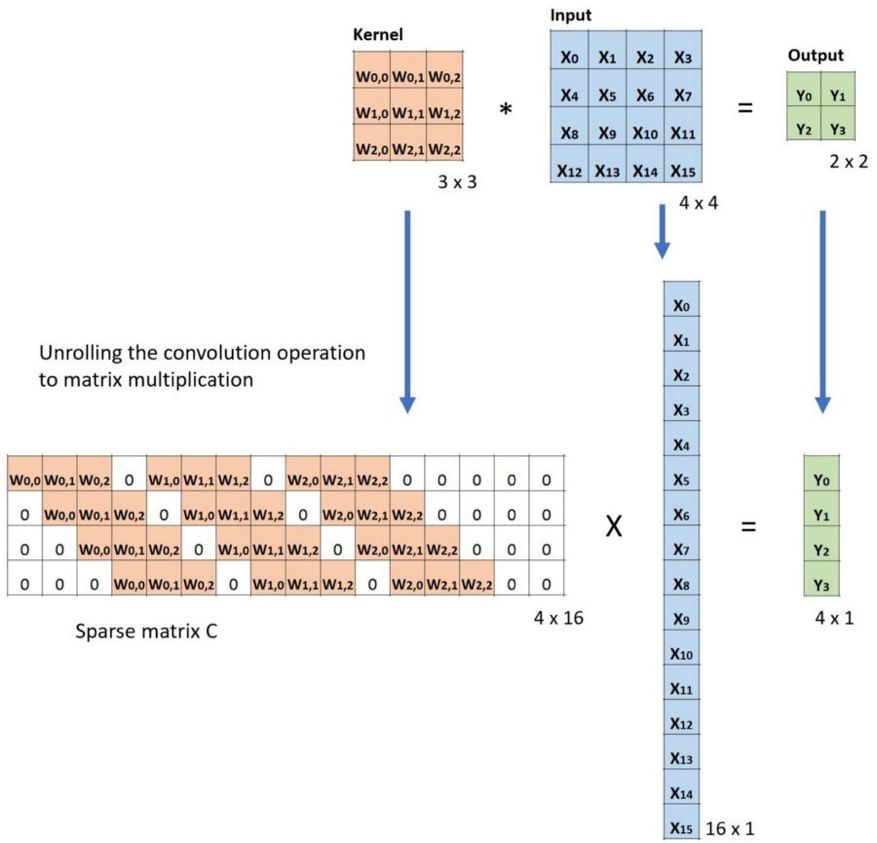
卷積的矩陣乘法:將 Large 輸入圖像(4×4)轉換為 Small 輸出圖像(2×2)
現在,如果我們在等式的兩邊都乘上矩陣的轉置 CT,并借助「一個矩陣與其轉置矩陣的乘法得到一個單位矩陣」這一性質,那么我們就能得到公式 CT x Small = Large,如下圖所示。
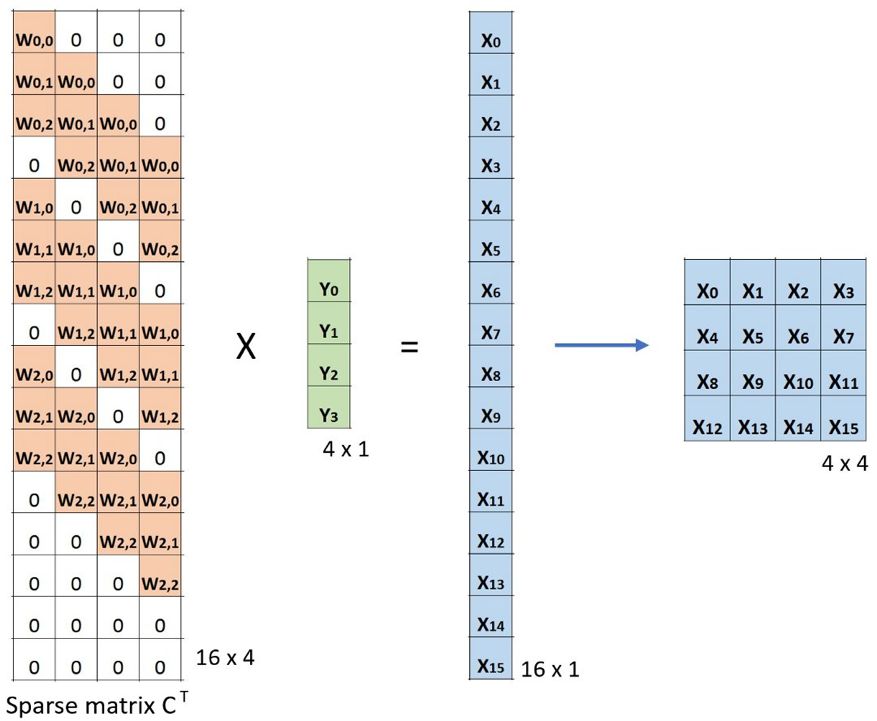
卷積的矩陣乘法:將 Small 輸入圖像(2×2)轉換為 Large 輸出圖像(4×4)
這里可以看到,我們執行了從小圖像到大圖像的上采樣。這正是我們想要實現的目標。現在。你就知道「轉置卷積」這個名字的由來了。
轉置矩陣的算術解釋可參閱:https://arxiv.org/abs/1603.07285
四、擴張卷積(Atrous 卷積)
擴張卷積由這兩篇引入:
https://arxiv.org/abs/1412.7062;
https://arxiv.org/abs/1511.07122
這是一個標準的離散卷積:
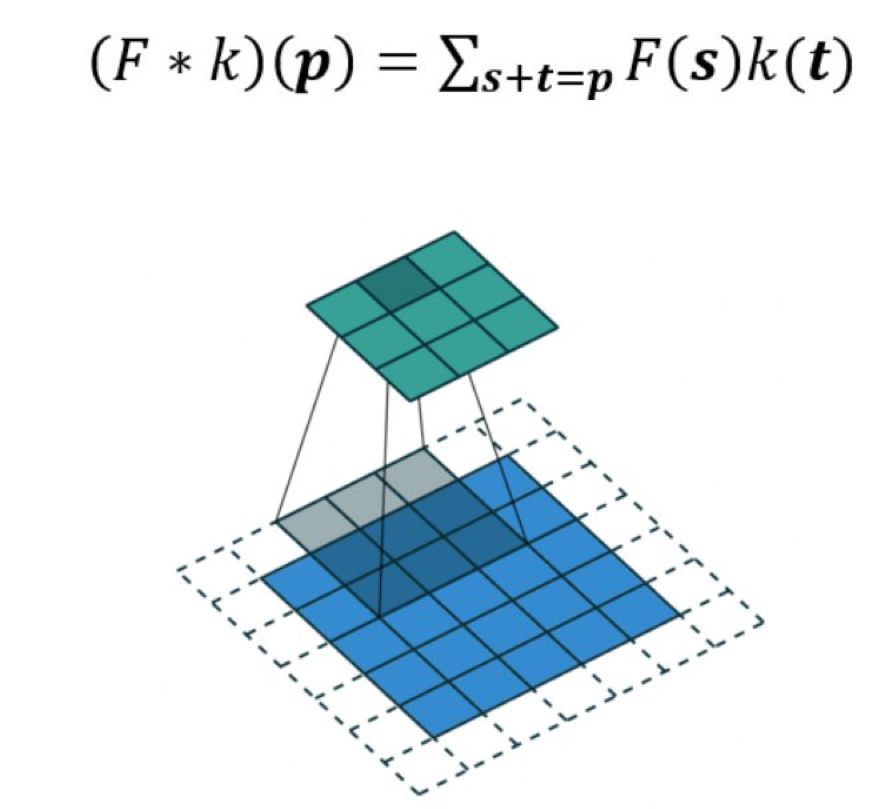
擴張卷積如下:
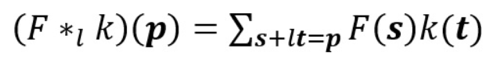
當 l=1 時,擴張卷積會變得和標準卷積一樣。
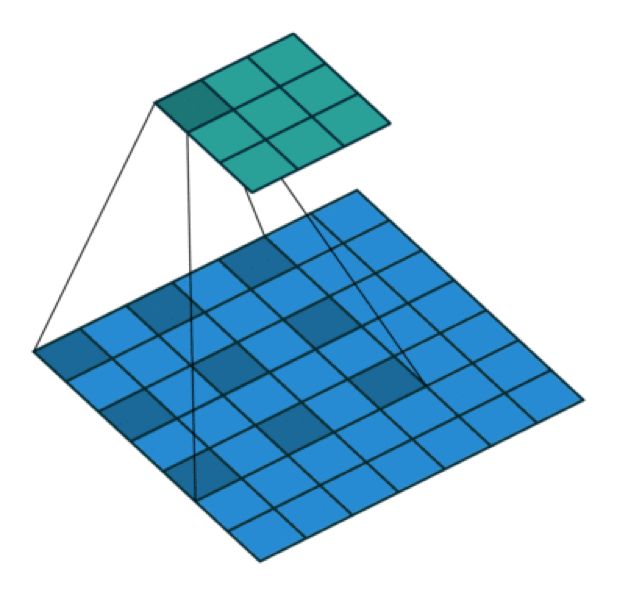
擴張卷積
直觀而言,擴張卷積就是通過在核元素之間插入空格來使核「膨脹」。新增的參數 l(擴張率)表示我們希望將核加寬的程度。具體實現可能各不相同,但通常是在核元素之間插入 l-1 個空格。下面展示了 l = 1, 2, 4 時的核大小。
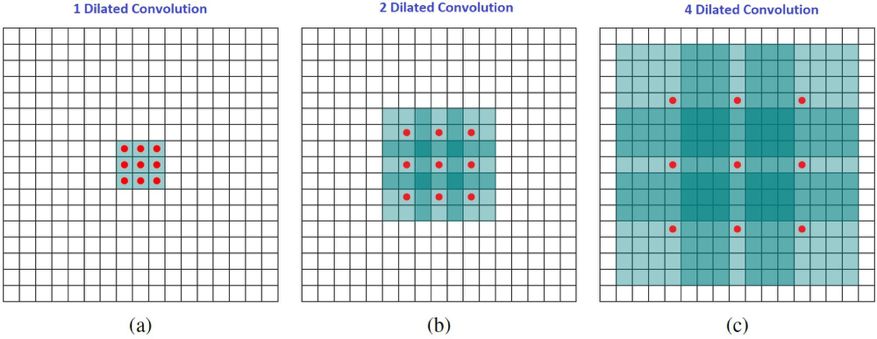
擴張卷積的感受野。我們基本上無需添加額外的成本就能有較大的感受野。
在這張圖像中,3×3 的紅點表示經過卷積后,輸出圖像是 3×3 像素。盡管所有這三個擴張卷積的輸出都是同一尺寸,但模型觀察到的感受野有很大的不同。l=1 時感受野為 3×3,l=2 時為 7×7。l=3 時,感受野的大小就增加到了 15×15。有趣的是,與這些操作相關的參數的數量是相等的。我們「觀察」更大的感受野不會有額外的成本。因此,擴張卷積可用于廉價地增大輸出單元的感受野,而不會增大其核大小,這在多個擴張卷積彼此堆疊時尤其有效。
論文《Multi-scale context aggregation by dilated convolutions》的作者用多個擴張卷積層構建了一個網絡,其中擴張率 l 每層都按指數增大。由此,有效的感受野大小隨層而指數增長,而參數的數量僅線性增長。
這篇論文中擴張卷積的作用是系統性地聚合多個比例的形境信息,而不丟失分辨率。這篇論文表明其提出的模塊能夠提升那時候(2016 年)的當前最佳形義分割系統的準確度。請參閱那篇論文了解更多信息。
五、可分卷積
某些神經網絡架構使用了可分卷積,比如MobileNets。可分卷積有空間可分卷積和深度可分卷積。
1、空間可分卷積
空間可分卷積操作的是圖像的 2D 空間維度,即高和寬。從概念上看,空間可分卷積是將一個卷積分解為兩個單獨的運算。對于下面的示例,3×3 的 Sobel 核被分成了一個 3×1 核和一個 1×3 核。
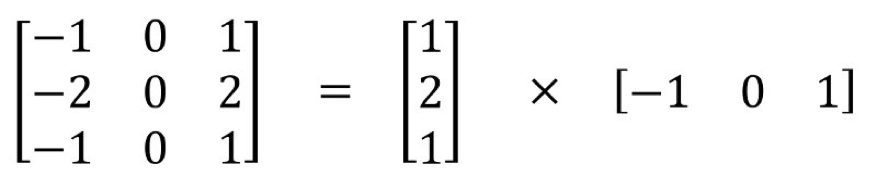
Sobel 核可分為一個 3x1 和一個 1x3 核
在卷積中,3×3 核直接與圖像卷積。在空間可分卷積中,3×1 核首先與圖像卷積,然后再應用 1×3 核。這樣,執行同樣的操作時僅需 6 個參數,而不是 9 個。
此外,使用空間可分卷積時所需的矩陣乘法也更少。給一個具體的例子,5×5 圖像與 3×3 核的卷積(步幅=1,填充=0)要求在 3 個位置水平地掃描核(還有 3 個垂直的位置)。總共就是 9 個位置,表示為下圖中的點。在每個位置,會應用 9 次逐元素乘法。總共就是 9×9=81 次乘法。
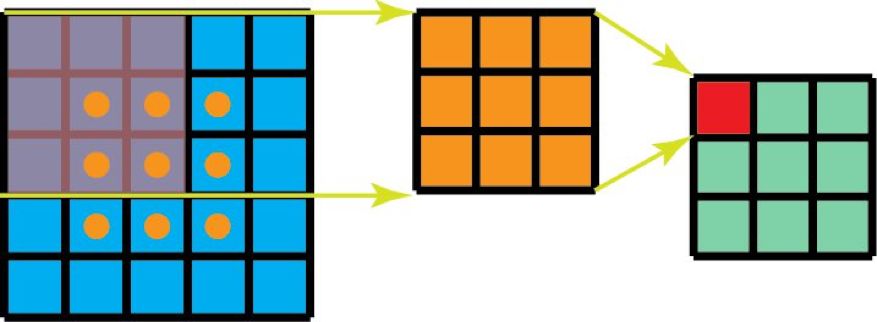
具有 1 個通道的標準卷積
另一方面,對于空間可分卷積,我們首先在 5×5 的圖像上應用一個 3×1 的過濾器。我們可以在水平 5 個位置和垂直 3 個位置掃描這樣的核。總共就是 5×3=15 個位置,表示為下圖中的點。在每個位置,會應用 3 次逐元素乘法。總共就是 15×3=45 次乘法。現在我們得到了一個 3×5 的矩陣。這個矩陣再與一個 1×3 核卷積,即在水平 3 個位置和垂直 3 個位置掃描這個矩陣。對于這 9 個位置中的每一個,應用 3 次逐元素乘法。這一步需要 9×3=27 次乘法。因此,總體而言,空間可分卷積需要 45+27=72 次乘法,少于普通卷積。
具有 1 個通道的空間可分卷積
我們稍微推廣一下上面的例子。假設我們現在將卷積應用于一張 N×N 的圖像上,卷積核為 m×m,步幅為 1,填充為 0。傳統卷積需要 (N-2) x (N-2) x m x m 次乘法,空間可分卷積需要 N x (N-2) x m + (N-2) x (N-2) x m = (2N-2) x (N-2) x m 次乘法。空間可分卷積與標準卷積的計算成本比為:
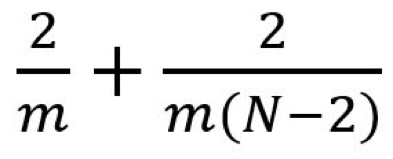
因為圖像尺寸 N 遠大于過濾器大小(N>>m),所以這個比就變成了 2/m。也就是說,在這種漸進情況(N>>m)下,當過濾器大小為 3×3 時,空間可分卷積的計算成本是標準卷積的 2/3。過濾器大小為 5×5 時這一數值是 2/5;過濾器大小為 7×7 時則為 2/7。
盡管空間可分卷積能節省成本,但深度學習卻很少使用它。一大主要原因是并非所有的核都能分成兩個更小的核。如果我們用空間可分卷積替代所有的傳統卷積,那么我們就限制了自己在訓練過程中搜索所有可能的核。這樣得到的訓練結果可能是次優的。
2、深度可分卷積
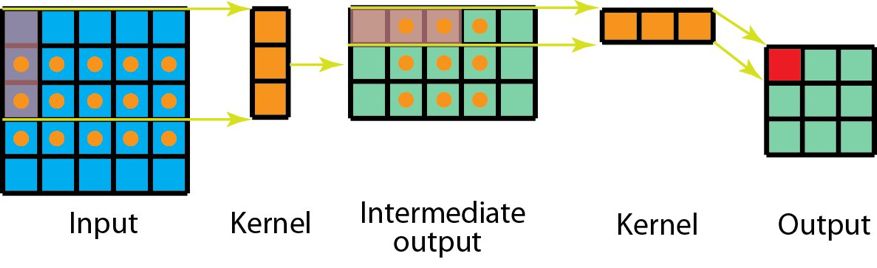
現在來看深度可分卷積,這在深度學習領域要常用得多(比如 MobileNet 和 Xception)。深度可分卷積包含兩個步驟:深度卷積核 1×1 卷積。
在描述這些步驟之前,有必要回顧一下我們之前介紹的 2D 卷積核 1×1 卷積。首先快速回顧標準的 2D 卷積。舉一個具體例子,假設輸入層的大小是 7×7×3(高×寬×通道),而過濾器的大小是 3×3×3。經過與一個過濾器的 2D 卷積之后,輸出層的大小是 5×5×1(僅有一個通道)。
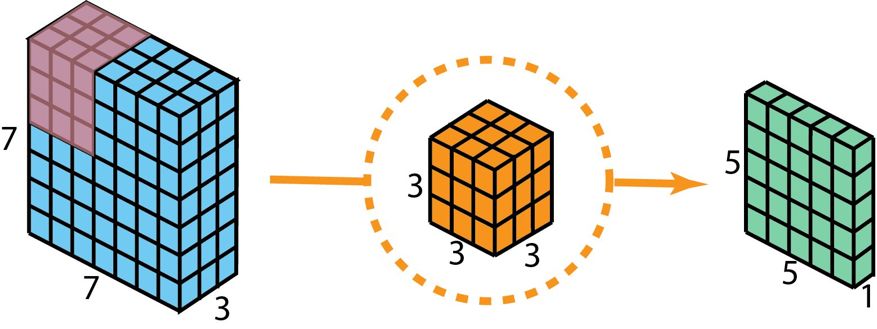
用于創建僅有 1 層的輸出的標準 2D 卷積,使用 1 個過濾器
一般來說,兩個神經網絡層之間會應用多個過濾器。假設我們這里有 128 個過濾器。在應用了這 128 個 2D 卷積之后,我們有 128 個 5×5×1 的輸出映射圖(map)。然后我們將這些映射圖堆疊成大小為 5×5×128 的單層。通過這種操作,我們可將輸入層(7×7×3)轉換成輸出層(5×5×128)。空間維度(即高度和寬度)會變小,而深度會增大。
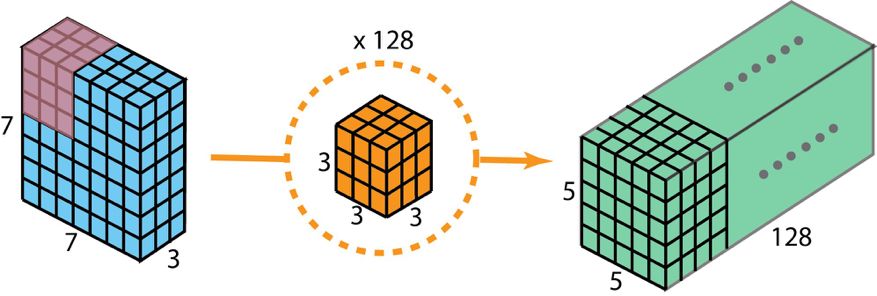
用于創建有 128 層的輸出的標準 2D 卷積,要使用 128 個過濾器
現在使用深度可分卷積,看看我們如何實現同樣的變換。
首先,我們將深度卷積應用于輸入層。但我們不使用 2D 卷積中大小為 3×3×3 的單個過濾器,而是分開使用 3 個核。每個過濾器的大小為 3×3×1。每個核與輸入層的一個通道卷積(僅一個通道,而非所有通道!)。每個這樣的卷積都能提供大小為 5×5×1 的映射圖。然后我們將這些映射圖堆疊在一起,創建一個 5×5×3 的圖像。經過這個操作之后,我們得到大小為 5×5×3 的輸出。現在我們可以降低空間維度了,但深度還是和之前一樣。
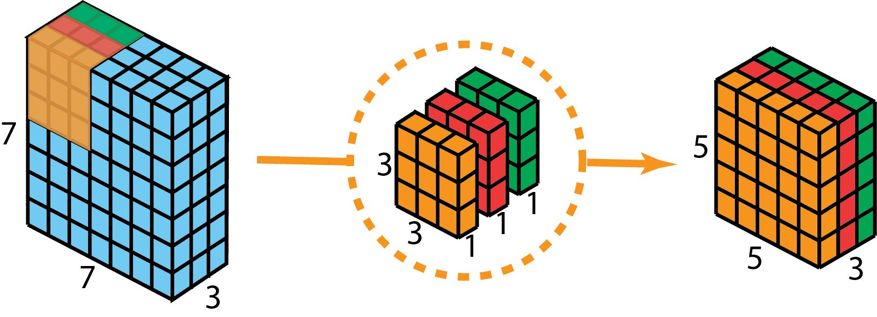
深度可分卷積——第一步:我們不使用 2D 卷積中大小為 3×3×3 的單個過濾器,而是分開使用 3 個核。每個過濾器的大小為 3×3×1。每個核與輸入層的一個通道卷積(僅一個通道,而非所有通道!)。每個這樣的卷積都能提供大小為 5×5×1 的映射圖。然后我們將這些映射圖堆疊在一起,創建一個 5×5×3 的圖像。經過這個操作之后,我們得到大小為 5×5×3 的輸出。
在深度可分卷積的第二步,為了擴展深度,我們應用一個核大小為 1×1×3 的 1×1 卷積。將 5×5×3 的輸入圖像與每個 1×1×3 的核卷積,可得到大小為 5×5×1 的映射圖。
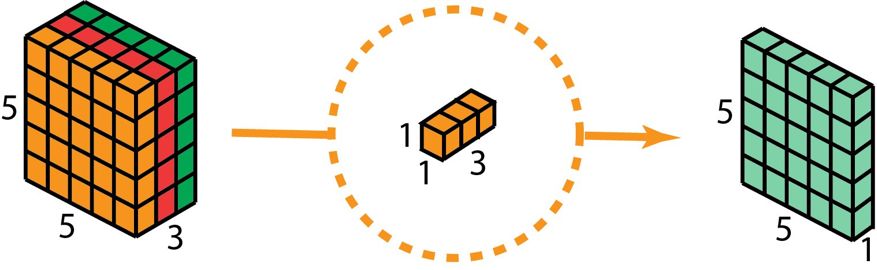
因此,在應用了 128 個 1×1 卷積之后,我們得到大小為 5×5×128 的層。
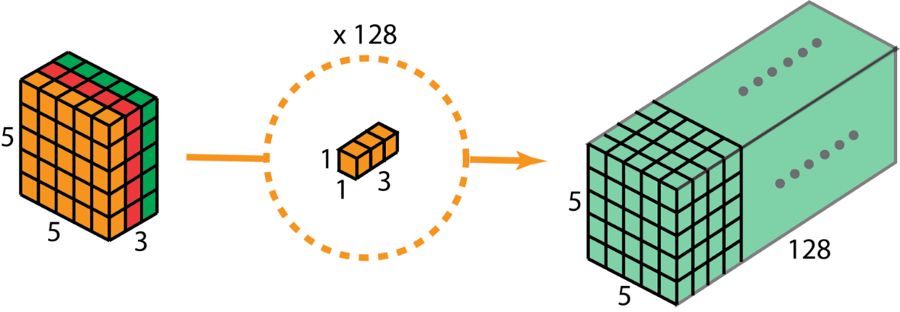
深度可分卷積——第二步:應用多個 1×1 卷積來修改深度。
通過這兩個步驟,深度可分卷積也會將輸入層(7×7×3)變換到輸出層(5×5×128)。
下圖展示了深度可分卷積的整個過程。
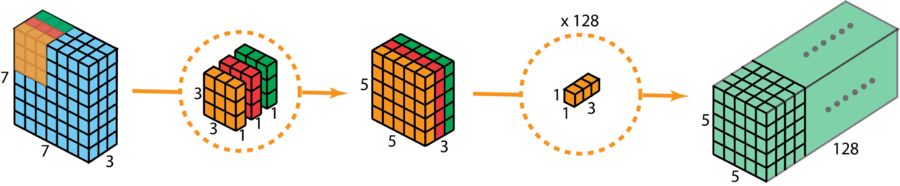
深度可分卷積的整個過程
所以,深度可分卷積有何優勢呢?效率!相比于 2D 卷積,深度可分卷積所需的操作要少得多。
回憶一下我們的 2D 卷積例子的計算成本。有 128 個 3×3×3 個核移動了 5×5 次,也就是 128 x 3 x 3 x 3 x 5 x 5 = 86400 次乘法。
可分卷積又如何呢?在第一個深度卷積步驟,有 3 個 3×3×1 核移動 5×5 次,也就是 3x3x3x1x5x5 = 675 次乘法。在 1×1 卷積的第二步,有 128 個 1×1×3 核移動 5×5 次,即 128 x 1 x 1 x 3 x 5 x 5 = 9600 次乘法。因此,深度可分卷積共有 675 + 9600 = 10275 次乘法。這樣的成本大概僅有 2D 卷積的 12%!
所以,對于任意尺寸的圖像,如果我們應用深度可分卷積,我們可以節省多少時間?讓我們泛化以上例子。現在,對于大小為 H×W×D 的輸入圖像,如果使用 Nc 個大小為 h×h×D 的核執行 2D 卷積(步幅為 1,填充為 0,其中 h 是偶數)。為了將輸入層(H×W×D)變換到輸出層((H-h+1)x (W-h+1) x Nc),所需的總乘法次數為:
Nc x h x h x D x (H-h+1) x (W-h+1)
另一方面,對于同樣的變換,深度可分卷積所需的乘法次數為:
D x h x h x 1 x (H-h+1) x (W-h+1) + Nc x 1 x 1 x D x (H-h+1) x (W-h+1) = (h x h + Nc) x D x (H-h+1) x (W-h+1)
則深度可分卷積與 2D 卷積所需的乘法次數比為:
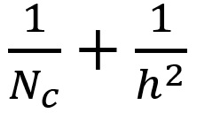
現代大多數架構的輸出層通常都有很多通道,可達數百甚至上千。對于這樣的層(Nc >> h),則上式可約簡為 1 / h2。基于此,如果使用 3×3 過濾器,則 2D 卷積所需的乘法次數是深度可分卷積的 9 倍。如果使用 5×5 過濾器,則 2D 卷積所需的乘法次數是深度可分卷積的 25 倍。
使用深度可分卷積有什么壞處嗎?當然是有的。深度可分卷積會降低卷積中參數的數量。因此,對于較小的模型而言,如果用深度可分卷積替代 2D 卷積,模型的能力可能會顯著下降。因此,得到的模型可能是次優的。但是,如果使用得當,深度可分卷積能在不降低你的模型性能的前提下幫助你實現效率提升。
六、分組卷積
AlexNet 論文(https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf)在 2012 年引入了分組卷積。實現分組卷積的主要原因是讓網絡訓練可在 2 個內存有限(每個 GPU 有 1.5 GB 內存)的 GPU 上進行。下面的 AlexNet 表明在大多數層中都有兩個分開的卷積路徑。這是在兩個 GPU 上執行模型并行化(當然如果可以使用更多 GPU,還能執行多 GPU 并行化)。
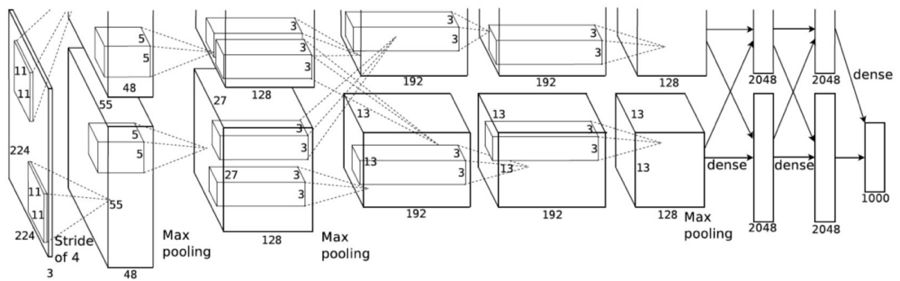
圖片來自 AlexNet 論文
這里我們介紹一下分組卷積的工作方式。首先,典型的 2D 卷積的步驟如下圖所示。在這個例子中,通過應用 128 個大小為 3×3×3 的過濾器將輸入層(7×7×3)變換到輸出層(5×5×128)。推廣而言,即通過應用 Dout 個大小為 h x w x Din 的核將輸入層(Hin x Win x Din)變換到輸出層(Hout x Wout x Dout)。
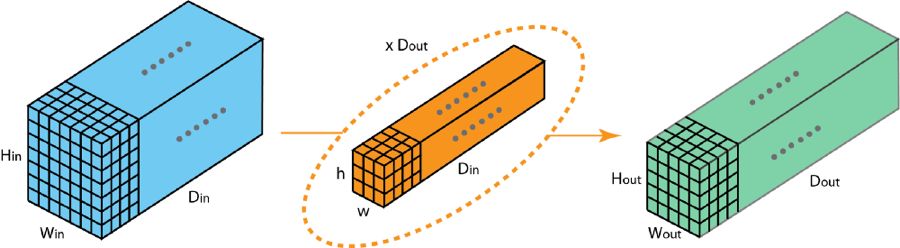
標準的 2D 卷積
在分組卷積中,過濾器會被分為不同的組。每一組都負責特定深度的典型 2D 卷積。下面的例子能讓你更清楚地理解。
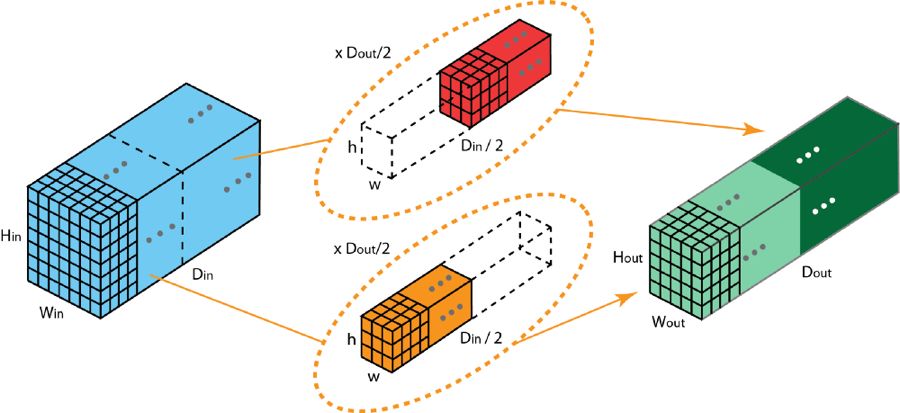
具有兩個過濾器分組的分組卷積
上圖展示了具有兩個過濾器分組的分組卷積。在每個過濾器分組中,每個過濾器的深度僅有名義上的 2D 卷積的一半。它們的深度是 Din/2。每個過濾器分組包含 Dout/2 個過濾器。第一個過濾器分組(紅色)與輸入層的前一半([:, :, 0:Din/2])卷積,而第二個過濾器分組(橙色)與輸入層的后一半([:, :, Din/2:Din])卷積。因此,每個過濾器分組都會創建 Dout/2 個通道。整體而言,兩個分組會創建 2×Dout/2 = Dout 個通道。然后我們將這些通道堆疊在一起,得到有 Dout 個通道的輸出層。
1、分組卷積與深度卷積
你可能會注意到分組卷積與深度可分卷積中使用的深度卷積之間存在一些聯系和差異。如果過濾器分組的數量與輸入層通道的數量相同,則每個過濾器的深度都為 Din/Din=1。這樣的過濾器深度就與深度卷積中的一樣了。
另一方面,現在每個過濾器分組都包含 Dout/Din 個過濾器。整體而言,輸出層的深度為 Dout。這不同于深度卷積的情況——深度卷積并不會改變層的深度。在深度可分卷積中,層的深度之后通過 1×1 卷積進行擴展。
分組卷積有幾個優點。
第一個優點是高效訓練。因為卷積被分成了多個路徑,每個路徑都可由不同的 GPU 分開處理,所以模型可以并行方式在多個 GPU 上進行訓練。相比于在單個 GPU 上完成所有任務,這樣的在多個 GPU 上的模型并行化能讓網絡在每個步驟處理更多圖像。人們一般認為模型并行化比數據并行化更好。后者是將數據集分成多個批次,然后分開訓練每一批。但是,當批量大小變得過小時,我們本質上是執行隨機梯度下降,而非批梯度下降。這會造成更慢,有時候更差的收斂結果。
在訓練非常深的神經網絡時,分組卷積會非常重要,正如在 ResNeXt 中那樣。
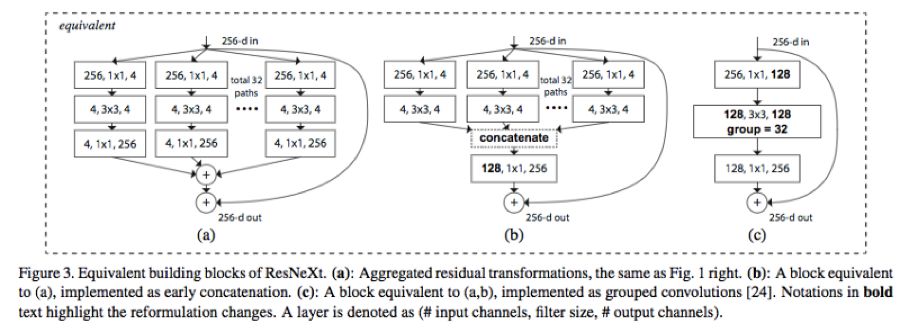
圖片來自 ResNeXt 論文,https://arxiv.org/abs/1611.05431
第二個優點是模型會更高效,即模型參數會隨過濾器分組數的增大而減少。在之前的例子中,完整的標準 2D 卷積有 h x w x Din x Dout 個參數。具有 2 個過濾器分組的分組卷積有 (h x w x Din/2 x Dout/2) x 2 個參數。參數數量減少了一半。
第三個優點有些讓人驚訝。分組卷積也許能提供比標準完整 2D 卷積更好的模型。另一篇出色的博客已經解釋了這一點:https://blog.yani.io/filter-group-tutorial。這里簡要總結一下。
原因和稀疏過濾器的關系有關。下圖是相鄰層過濾器的相關性。其中的關系是稀疏的。

在 CIFAR10 上訓練的一個 Network-in-Network 模型中相鄰層的過濾器的相關性矩陣。高度相關的過濾器對更明亮,而相關性更低的過濾器則更暗。圖片來自:https://blog.yani.io/filter-group-tutorial
分組矩陣的相關性映射圖又如何?

在 CIFAR10 上訓練的一個 Network-in-Network 模型中相鄰層的過濾器的相關性,動圖分別展示了有 1、2、4、8、16 個過濾器分組的情況。圖片來自 https://blog.yani.io/filter-group-tutorial
上圖是當用 1、2、4、8、16 個過濾器分組訓練模型時,相鄰層的過濾器之間的相關性。那篇文章提出了一個推理:「過濾器分組的效果是在通道維度上學習塊對角結構的稀疏性……在網絡中,具有高相關性的過濾器是使用過濾器分組以一種更為結構化的方式學習到。從效果上看,不必學習的過濾器關系就不再參數化。這樣顯著地減少網絡中的參數數量能使其不容易過擬合,因此,一種類似正則化的效果讓優化器可以學習得到更準確更高效的深度網絡。」
AlexNet conv1 過濾器分解:正如作者指出的那樣,過濾器分組似乎會將學習到的過濾器結構性地組織成兩個不同的分組。本圖來自 AlexNet 論文。
此外,每個過濾器分組都會學習數據的一個獨特表征。正如 AlexNet 的作者指出的那樣,過濾器分組似乎會將學習到的過濾器結構性地組織成兩個不同的分組——黑白過濾器和彩色過濾器。
你認為深度學習領域的卷積還有那些值得注意的地方?
-
深度學習
+關注
關注
73文章
5500瀏覽量
121111 -
cnn
+關注
關注
3文章
352瀏覽量
22203
原文標題:卷積有多少種?一文讀懂深度學習中的各種卷積
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解深度學習、神經網絡與卷積神經網絡的應用

深度學習中常用的幾種卷積 不同情況下的卷積定義方式
深度學習中的各種卷積網絡大家知多少
綜述深度學習的卷積神經網絡模型應用及發展






 工商網監
工商網監
評論