") 機(jī)器學(xué)習(xí)研究中常見的七大謠傳總結(jié)
機(jī)器學(xué)習(xí)研究中常見的七大謠傳總結(jié)
在學(xué)習(xí)深度學(xué)習(xí)的過程中,我們常會(huì)遇到各種謠傳,也會(huì)遇到各種想當(dāng)然的「執(zhí)念」。在本文中,作者總結(jié)了機(jī)器學(xué)習(xí)研究中常見的七大謠傳,他們很多都是我們以前的固有概念,而最近又有新研究對(duì)它們提出質(zhì)疑。所以在為機(jī)器學(xué)習(xí)填坑的生涯中,快自檢這七個(gè)言傳吧。
謠傳一:TensorFlow 是一個(gè)張量運(yùn)算庫
事實(shí)上,TensorFlow 是矩陣而不是張量運(yùn)算庫,這兩者的區(qū)別非常大。
在 NeurIPS 2018 的論文 Computing Higher Order Derivatives of Matrix and Tensor Expressions 中,研究者表明,他們基于張量微積分(Tensor Calculus)所建立的新自動(dòng)微分庫具有明顯更緊湊(compact)的表達(dá)式樹(expression trees)。這是因?yàn)椋瑥埩课⒎e分使用了索引標(biāo)識(shí),進(jìn)而使前向模式和反向模式的處理方式相同。
與此相反,矩陣微積分出于標(biāo)識(shí)方便的考慮隱藏了索引,這也通常會(huì)導(dǎo)致自動(dòng)微分的表達(dá)式樹顯得過于復(fù)雜。
若有矩陣的乘法運(yùn)算:C=AB。在前向模式中,有
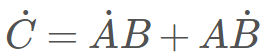
,而在反向模式中,則有
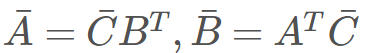
。為了正確完成乘法計(jì)算,我們需要注意乘法的順序和轉(zhuǎn)置的使用。對(duì)于機(jī)器學(xué)習(xí)開發(fā)者而言,這只是在標(biāo)識(shí)上的一點(diǎn)困惑,但對(duì)于程序而言,這是一個(gè)計(jì)算上的開銷。
以下是另一個(gè)例子,毫無疑問意義更大一些:對(duì)于求行列式 c=det(A)。在前向模式中,有
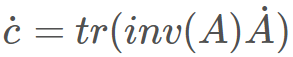
,而在反向模式中,則有
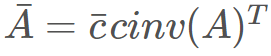
。這里可以明顯看出,無法使用同一個(gè)表達(dá)式樹來表示兩種模式,因?yàn)槎呤怯刹煌\(yùn)算組成的。
總的來說,TensorFlow 和其他庫(如 Mathematica、Maple、 Sage、SimPy、ADOL-C、TAPENADE、TensorFlow, Theano、PyTorch 和 HIPS autograd)實(shí)現(xiàn)的自動(dòng)微分方法,會(huì)在前向模式和反向模式中,得出不同的、低效的表達(dá)式樹。而在張量微積分中,通過索引標(biāo)識(shí)保留了乘法的可交換性,進(jìn)而輕松避免了這些問題(具體的實(shí)現(xiàn)原理,請(qǐng)閱讀論文原文)
研究者通過反向傳播,在三個(gè)不同問題上,測(cè)試了反向模式自動(dòng)微分新方法的性能,并度量了其計(jì)算 Hessian 矩陣所消耗的時(shí)間。
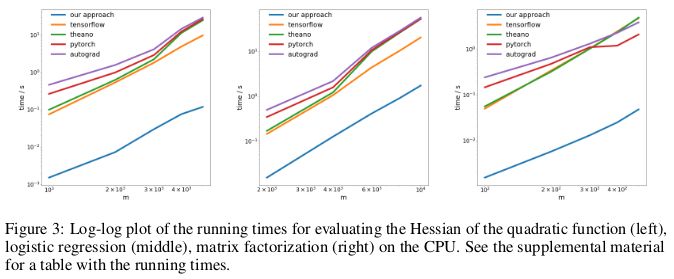
第一個(gè)問題是優(yōu)化一個(gè)形如 xAx 的二次函數(shù);第二個(gè)問題是求解一個(gè)邏輯回歸;第三個(gè)問題是求解矩陣分解。
在 CPU 上,新方法與當(dāng)下流行的 TensorFlow、Theano、PyTorch 和 HIPS autograd 等自動(dòng)微分庫相比,要快兩個(gè)數(shù)量級(jí)。
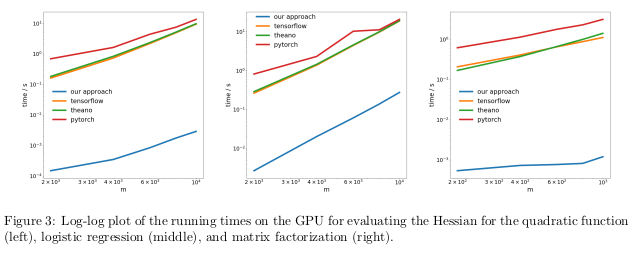
在 GPU 上,研究者發(fā)現(xiàn),新方法的提速更加明顯,超出流行庫的速度近似三個(gè)數(shù)量級(jí)。
意義:利用目前的深度學(xué)習(xí)庫完成對(duì)二次或更高階函數(shù)的求導(dǎo),所花費(fèi)的成本比本應(yīng)消耗的更高。這包含了計(jì)算諸如 Hessian 的通用四階張量(例:在 MAML 中,以及二階牛頓法)。幸運(yùn)的是,在「深度」學(xué)習(xí)中,二階函數(shù)并不常見。但在「?jìng)鹘y(tǒng)」機(jī)器學(xué)習(xí)中,它們卻廣泛存在:SVM對(duì)偶問題、最小二乘回歸、LASSO,高斯過程……
謠傳二:機(jī)器學(xué)習(xí)研究者并不使用測(cè)試集進(jìn)行驗(yàn)證
在機(jī)器學(xué)習(xí)第一門課中,我們會(huì)學(xué)習(xí)到將數(shù)據(jù)集分為訓(xùn)練集、驗(yàn)證集以及測(cè)試集。將在訓(xùn)練集上訓(xùn)練得到模型,在驗(yàn)證集上進(jìn)行效果評(píng)估,得出的效果用以指導(dǎo)開發(fā)者調(diào)節(jié)模型,以求在真實(shí)場(chǎng)景下獲得效果最好的模型。直到模型調(diào)節(jié)好之后,才應(yīng)該使用測(cè)試集,提供模型在真實(shí)場(chǎng)景下實(shí)際表現(xiàn)的無偏估計(jì)。如果開發(fā)者「作弊」地在訓(xùn)練或驗(yàn)證階段使用了測(cè)試集,那么模型就很可能遇到對(duì)數(shù)據(jù)集偏差產(chǎn)生過擬合的風(fēng)險(xiǎn):這類偏差信息是無法在數(shù)據(jù)集外泛化得到的。
在機(jī)器學(xué)習(xí)研究高度競(jìng)爭(zhēng)的環(huán)境下,對(duì)新算法/模型的評(píng)估,通常都會(huì)使用其在測(cè)試集上的表現(xiàn)。因此對(duì)于研究者而言,沒有理由去寫/提交一篇測(cè)試集效果不 SOTA 的論文。這也說明在機(jī)器學(xué)習(xí)研究領(lǐng)域,總體而言,使用測(cè)試集進(jìn)行驗(yàn)證是一個(gè)普遍現(xiàn)象。
這種「作弊」行為的影響是什么?
在論文 DoCIFAR-10Classifiers Generalize to CIFAR-10? 中,研究者們通過在 CIFAR-10 上建立了一個(gè)新的測(cè)試集,來研究此問題。為此,他們解析標(biāo)注了來自 Tiny Images 庫的圖像,就像最初的數(shù)據(jù)采集過程一樣。
常用測(cè)試集帶來過擬合?你真的能控制自己不根據(jù)測(cè)試集調(diào)參嗎
研究者們之所以選擇 CIFAR-10,是因?yàn)樗菣C(jī)器學(xué)習(xí)界使用最廣泛的數(shù)據(jù)集之一,也是 NeurIPS 2017 中第二受歡迎的數(shù)據(jù)集(在 MNIST 之后)。CIFAR-10 數(shù)據(jù)集的創(chuàng)建過程也有完善公開的文檔記錄。而龐大的 Tiny Images 庫中,也有足夠的細(xì)粒度標(biāo)簽數(shù)據(jù),進(jìn)而使得在盡量不引起分布偏移的情況下重建一個(gè)測(cè)試集成為了可能。
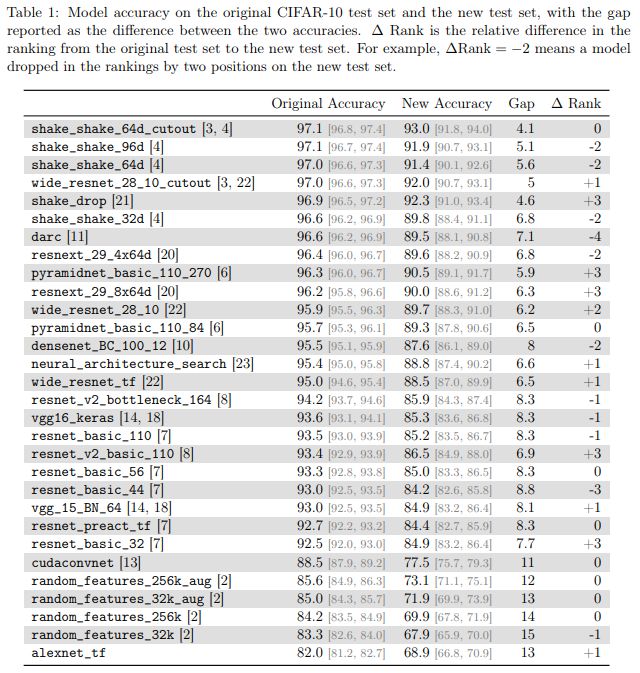
研究者發(fā)現(xiàn),很多神經(jīng)網(wǎng)絡(luò)模型在從原來的測(cè)試集切換到新測(cè)試集的時(shí)候,都出現(xiàn)了明顯的準(zhǔn)確率下降(4% - 15%)。但各模型的相對(duì)排名依然相對(duì)穩(wěn)定。
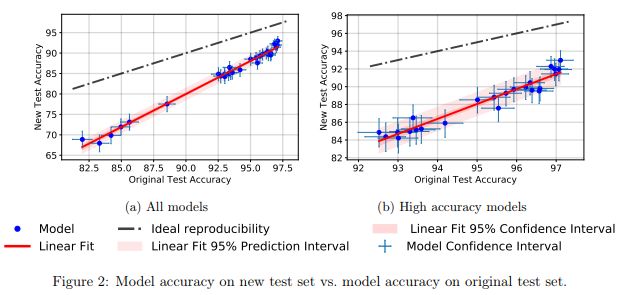
總的來說,相較于表現(xiàn)較差的模型,表現(xiàn)較好模型的準(zhǔn)確率下降程度也相對(duì)更小。這是一個(gè)振奮人心的消息,因?yàn)橹辽僭?CIFAR-10 上,隨著研究社區(qū)發(fā)明出更好機(jī)器學(xué)習(xí)模型/方法,由于「作弊」得到的泛化損失,也變得更加輕微。
謠傳三:神經(jīng)網(wǎng)絡(luò)訓(xùn)練過程會(huì)使用訓(xùn)練集中的所有數(shù)據(jù)點(diǎn)。
有這樣一個(gè)常見說法,數(shù)據(jù)是新的原油(財(cái)富),數(shù)據(jù)量越大,我們就能將數(shù)據(jù)相對(duì)不足的、過參數(shù)化的深度學(xué)習(xí)模型訓(xùn)練得越好。
在 ICLR 2019 的一篇論文 An Empirical Study of Example Forgetting During Deep Neural Network Learning 中,研究者們表示在多個(gè)常見的較小圖像數(shù)據(jù)集中,存在顯著冗余。令人震驚的是,在 CIFAR-10 中,我們可以在不顯著影響測(cè)試集準(zhǔn)確率的情況下剔除 30% 的數(shù)據(jù)點(diǎn)。
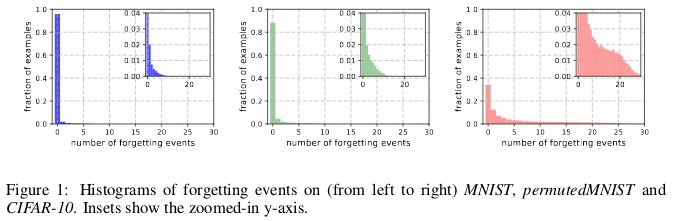
當(dāng)神經(jīng)網(wǎng)絡(luò)在 t+1 時(shí)刻給出誤分類、而在 t 時(shí)刻給出了準(zhǔn)確的分類時(shí),就稱為發(fā)生了遺忘事件(forgetting event)。這里的「時(shí)刻」是指訓(xùn)練網(wǎng)絡(luò)的隨機(jī)梯度下降(SGD)的更新次數(shù)。為了讓記錄遺忘事件變得可行,研究者每次只在用于完成 SGD 更新的小批量數(shù)據(jù)上運(yùn)行神經(jīng)網(wǎng)絡(luò),而不是在數(shù)據(jù)集的單個(gè)樣本上運(yùn)行。對(duì)于不會(huì)經(jīng)歷遺忘事件的樣本,稱之為不可遺忘樣本(unfogettable example)。
研究者發(fā)現(xiàn),MNIST 中 91.7%、permutedMNIST 中 75.3%、CIFAR-10 中 31.3% 以及 CIFAR-100 中 7.62% 的數(shù)據(jù)屬于不可遺忘樣本。這符合直觀理解,因?yàn)殡S著圖像數(shù)據(jù)集的多樣性和復(fù)雜性上升,神經(jīng)網(wǎng)絡(luò)理應(yīng)遺忘更多的樣本。
相較于不可遺忘樣本,可遺忘樣本似乎表現(xiàn)了更多不尋常的獨(dú)特特征。研究者將其類比于 SVM 中的支持向量,因?yàn)樗鼈兯坪鮿澐至藳Q策邊界。
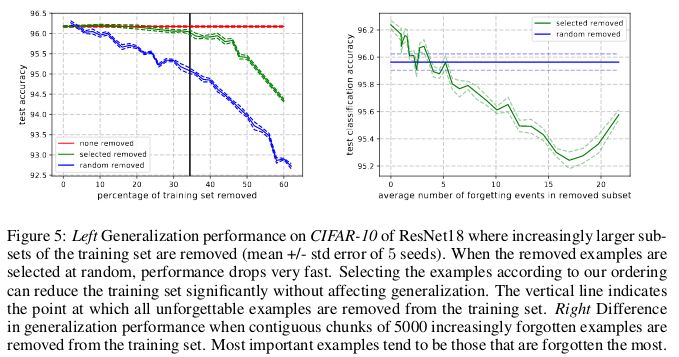
與此相反,不可遺忘樣本則編碼了絕大部分的冗余信息。如果將樣本按其不可遺忘性(unforgettability)進(jìn)行排序,就可以通過刪除絕大部分的不可遺忘樣本,而對(duì)數(shù)據(jù)集完成壓縮。
在 CIFAR-10 中,30% 的數(shù)據(jù)可以在不影響測(cè)試集準(zhǔn)確率的情況下移除,而刪除 35% 的數(shù)據(jù)則會(huì)產(chǎn)生 0.2% 的微小測(cè)試準(zhǔn)確率下降。如果所移除的 30% 數(shù)據(jù)是隨機(jī)挑選而非基于不可遺忘性,那么就會(huì)導(dǎo)致約 1% 的顯著下降。
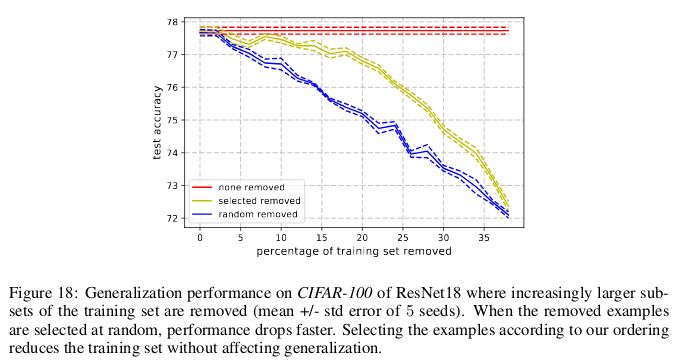
與此類似,在 CIFAR-100 上,8% 的數(shù)據(jù)可以在不影響測(cè)試集準(zhǔn)確率的情況下移除。
這些發(fā)現(xiàn)表明,在神經(jīng)網(wǎng)絡(luò)的訓(xùn)練中,存在明顯的數(shù)據(jù)冗余,就像 SVM 的訓(xùn)練中,非支持向量的數(shù)據(jù)可以在不影響模型決策的情況下移除。
意義:如果在開始訓(xùn)練之前,就能確定哪些樣本是不可遺忘的,那么我們就可以通過刪除這些數(shù)據(jù)來節(jié)省存儲(chǔ)空間和訓(xùn)練時(shí)間。
謠傳四:我們需要批標(biāo)準(zhǔn)化來訓(xùn)練超深度殘差網(wǎng)絡(luò)。
長(zhǎng)久以來,人們都相信「通過隨機(jī)初始參數(shù)值和梯度下降,直接優(yōu)化有監(jiān)督目標(biāo)函數(shù)(如:正確分類的對(duì)數(shù)概率)來訓(xùn)練深度網(wǎng)絡(luò),效果不會(huì)很好。」
從那時(shí)起,就有很多聰明的隨機(jī)初始化方法、激活函數(shù)、優(yōu)化方法以及其他諸如殘差連接的結(jié)構(gòu)創(chuàng)新,來降低利用梯度下降訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)的難度。
但真正的突破來自于批標(biāo)準(zhǔn)化(batch normalization)的引入(以及其他的后續(xù)標(biāo)準(zhǔn)化技術(shù)),批標(biāo)準(zhǔn)化通過限制深度網(wǎng)絡(luò)每層的激活值尺度,來緩和梯度消失、爆炸等問題。
值得注意的是,在今年的論文 Fixup Initialization: Residual Learning Without Normalization 中,研究表明在不引入任何標(biāo)準(zhǔn)化方法的情況下,通過使用 vanilla SGD,可以有效地訓(xùn)練一個(gè) 10,000 層的深度網(wǎng)絡(luò)。
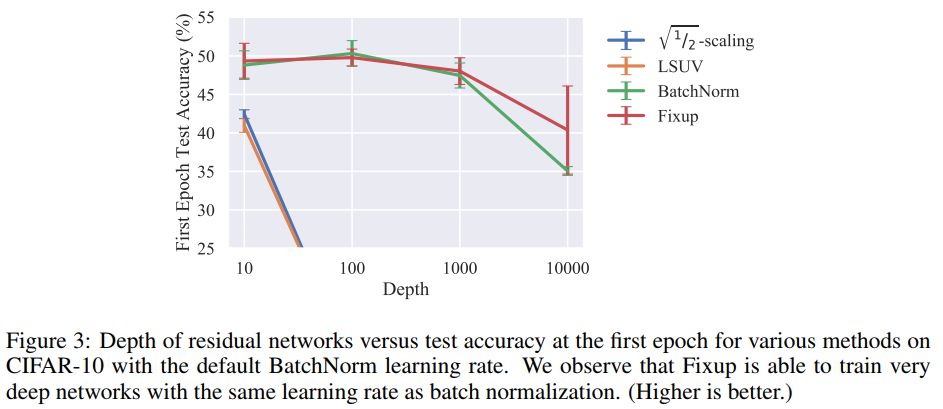
研究者比較了在 CIFAR-10 上,不同深度殘差網(wǎng)絡(luò)訓(xùn)練一個(gè) epoch 的結(jié)果。并發(fā)現(xiàn),雖然標(biāo)準(zhǔn)初始化方法在 100 層的網(wǎng)絡(luò)上失敗了,但 Fixup 和批標(biāo)準(zhǔn)化都在 10,000 層的網(wǎng)絡(luò)上成功了。

研究者通過理論分析,證明了「特定神經(jīng)層的梯度范數(shù),以某個(gè)隨網(wǎng)絡(luò)深度增加而增大的數(shù)值為期望下界」,即梯度爆炸問題。
為避免此問題,F(xiàn)ixup 中的核心思想是在每 L 個(gè)殘差分支上,對(duì) m 個(gè)神經(jīng)層的權(quán)重,使用同時(shí)依賴于 L 和 m 的因子進(jìn)行調(diào)整。」
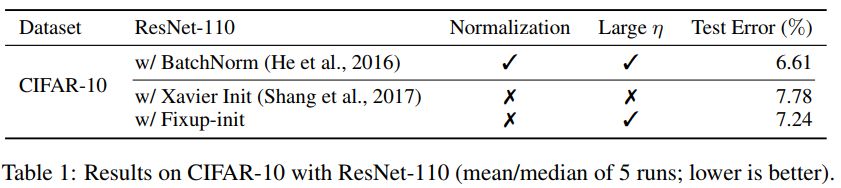
Fixup 使得能夠在 CIFAR-10 上以高學(xué)習(xí)速率訓(xùn)練一個(gè) 110 層的深度殘差網(wǎng)絡(luò),得到的測(cè)試集表現(xiàn)和利用批標(biāo)準(zhǔn)化訓(xùn)練的同結(jié)構(gòu)網(wǎng)絡(luò)效果相當(dāng)。
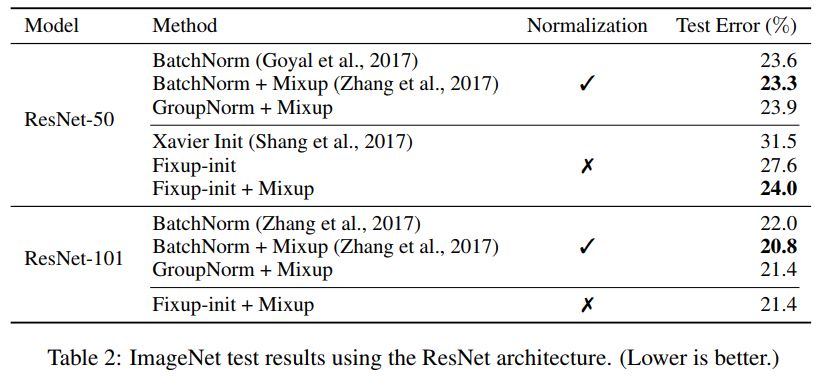
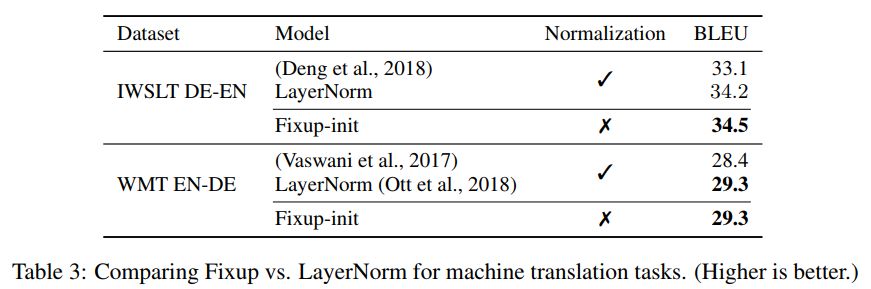
研究者也進(jìn)一步展示了在沒有任何標(biāo)準(zhǔn)化處理下,基于 Fixup 得到的神經(jīng)網(wǎng)絡(luò)在 ImageNet 數(shù)據(jù)集和英語-德語機(jī)器翻譯任務(wù)上相當(dāng)?shù)臏y(cè)試結(jié)果。
謠傳五:注意力>卷積
在機(jī)器學(xué)習(xí)領(lǐng)域,有一個(gè)正得到認(rèn)同的說法,認(rèn)為注意力機(jī)制是卷積的更優(yōu)替代。重要的是 Vaswani et al 注意到「一個(gè)可分離卷積的計(jì)算成本,和一個(gè)自注意力層與一個(gè)逐點(diǎn)前饋層結(jié)合后的計(jì)算成本一致」。
即使是最新的 GAN 網(wǎng)絡(luò),也展示出自注意力相較于標(biāo)準(zhǔn)卷積,在對(duì)長(zhǎng)期、多尺度依賴性的建模上效果更好。
在 ICLR 2019 的論文 Pay Less Attention with Lightweight and Dynamic Convolutions 中,研究者對(duì)自注意力機(jī)制在長(zhǎng)期依賴性的建模中,參數(shù)的有效性和效率提出了質(zhì)疑,他們表示一個(gè)受自注意力啟發(fā)而得到的卷積變體,其參數(shù)效率更高。
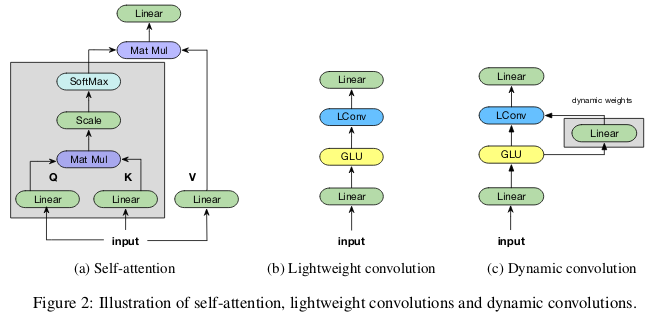
輕量級(jí)卷積(lightweight convolutions)是深度可分離(depthwise-separable)的,它在時(shí)間維度上進(jìn)行了 softmax 標(biāo)準(zhǔn)化,通道維度上共享權(quán)重,且在每個(gè)時(shí)間步上重新使用相同權(quán)重(類似于 RNN 網(wǎng)絡(luò))。動(dòng)態(tài)卷積(dynamic convolutions)則是在每個(gè)時(shí)間步上使用不同權(quán)重的輕量級(jí)卷積。
這些技巧使得輕量級(jí)卷積和動(dòng)態(tài)卷積相較于傳統(tǒng)的不可分卷積,在效率上優(yōu)越幾個(gè)數(shù)量級(jí)。
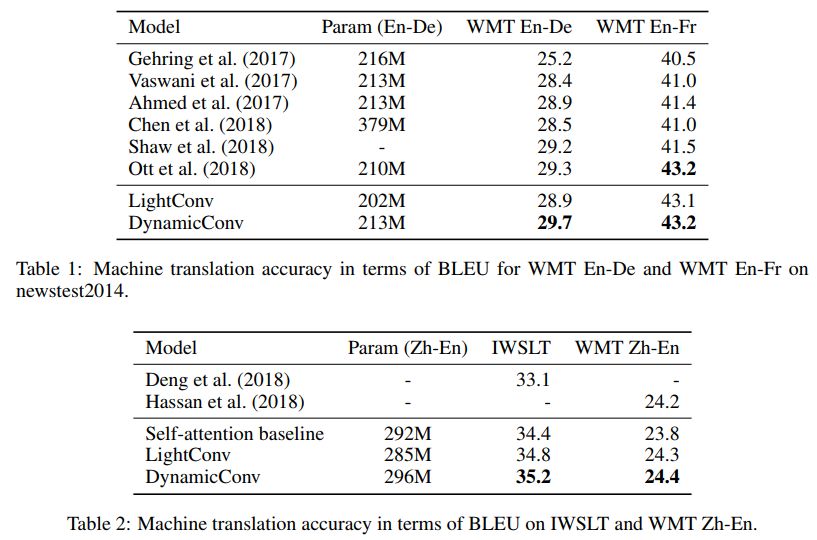
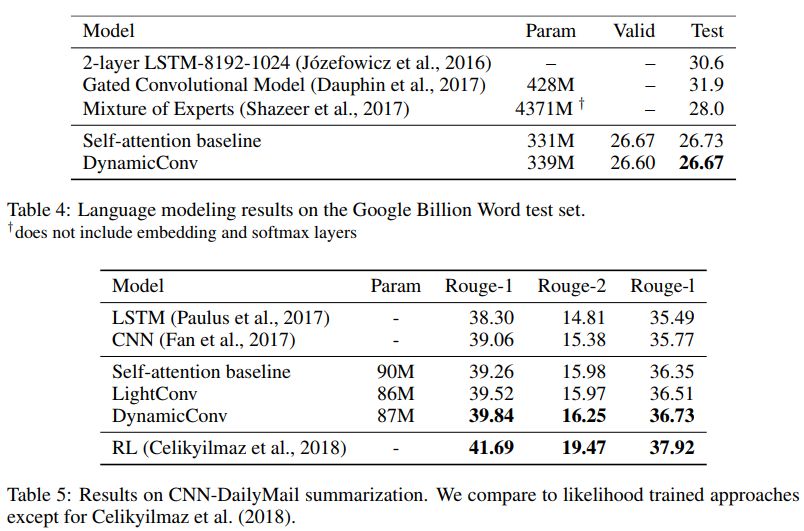
研究者也證明,在機(jī)器翻譯、語言建模和抽象總結(jié)等任務(wù)上,這些新卷積能夠使用數(shù)量相當(dāng)或更少的參數(shù),達(dá)到或超過基于自注意力的基準(zhǔn)效果。
謠傳六:圖像數(shù)據(jù)集反映了自然世界真實(shí)圖像分布
我們可能會(huì)認(rèn)為,如今的神經(jīng)網(wǎng)絡(luò)在目標(biāo)識(shí)別任務(wù)上,效果已經(jīng)超出真人水平。這并不正確。在 ImageNet 等篩選出來的圖像數(shù)據(jù)集上,它們的效果可能確實(shí)優(yōu)于真人。但對(duì)于自然世界的真實(shí)圖像,它們?cè)谀繕?biāo)識(shí)別上絕對(duì)無法比正常成年人做得更加出色。這是因?yàn)椋瑥哪壳暗膱D像數(shù)據(jù)集中抽取的圖像,和從真實(shí)世界整體中抽取的圖像并不一樣,二者分布并不相同。
這里有一篇 2011 年比較老的論文: Unbiased Look at Dataset Bias,其中,研究者根據(jù) 12 個(gè)流行的圖像數(shù)據(jù)集,嘗試通過訓(xùn)練一個(gè)分類器用以判斷一個(gè)給定圖像來自于哪個(gè)數(shù)據(jù)集,來探索是否存在數(shù)據(jù)集偏差。
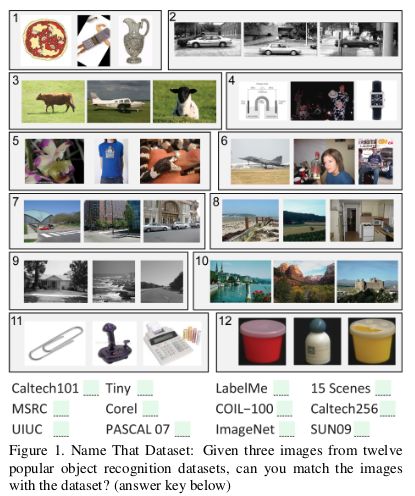
隨機(jī)猜測(cè)的正確率應(yīng)該是 1/12 = 8%,而實(shí)驗(yàn)結(jié)果的準(zhǔn)確率高于 75%。

研究者在 HOG 特征上訓(xùn)練了一個(gè) SVM,并發(fā)現(xiàn)其正確率達(dá)到 39%,高于隨機(jī)猜測(cè)水平。如今,如果使用最先進(jìn)的 CNN 來復(fù)現(xiàn)這一實(shí)驗(yàn),很可能得到更好的分類器效果。
如果圖像數(shù)據(jù)集確實(shí)能夠表征來自自然世界的真實(shí)圖像,就不應(yīng)能夠分辨出某個(gè)特定圖像是來自于哪個(gè)數(shù)據(jù)集的。
但數(shù)據(jù)中的偏差,使得每個(gè)數(shù)據(jù)集變得可識(shí)別。例如,在 ImageNet 中,有非常多的「賽車」,不能認(rèn)為這代表了通常意義上「汽車」的理想概念。
研究者在某數(shù)據(jù)集訓(xùn)練分類器,并在其他數(shù)據(jù)集上評(píng)估表現(xiàn)效果,進(jìn)一步度量數(shù)據(jù)集的價(jià)值。根據(jù)這個(gè)指標(biāo),LabelMe 和 ImageNet 是偏差最小的數(shù)據(jù)集,在「一籃子貨幣(basket of currencies)」上得分 0.58。所有數(shù)據(jù)集的得分都小于 1,表明在其他數(shù)據(jù)集上訓(xùn)練的模型都給出了更低的準(zhǔn)確度。在沒有數(shù)據(jù)集偏差的理想情況下,應(yīng)該有一些得分是高于 1 的。
謠傳七:顯著圖(saliency maps)是解釋神經(jīng)網(wǎng)絡(luò)的一個(gè)穩(wěn)健方法。
雖然神經(jīng)網(wǎng)絡(luò)通常被認(rèn)為是黑箱模型,現(xiàn)在還是已經(jīng)有了有非常多對(duì)其進(jìn)行解釋的探索。顯著圖,或其他類似對(duì)特征或訓(xùn)練樣本賦予重要性得分的方法,是其中最受歡迎的形式。
能夠?qū)D像進(jìn)行特定分類的理由,總結(jié)為圖像特定部分對(duì)模型決策過程中起的作用,是一個(gè)非常誘人的課題。已有的幾種計(jì)算顯著圖的方法,通常都基于神經(jīng)網(wǎng)絡(luò)在特定圖像上的激活情況,以及網(wǎng)絡(luò)中所傳播的梯度。
在 AAAI 2019 的一篇論文 Interpretation of Neural Networks is Fragile 中,研究者表明,可以通過引入一個(gè)無法感知的擾動(dòng),來破壞一個(gè)特定圖像的顯著圖。
「帝王蝶之所以被分類為帝王蝶,并不是因?yàn)槌岚虻膱D案樣式,而是因?yàn)楸尘吧弦恍┎恢匾木G色樹葉。」
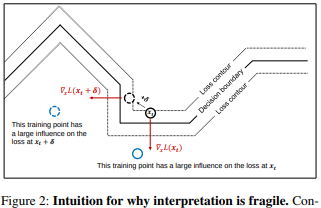
高維圖像通常都位于深度神經(jīng)網(wǎng)絡(luò)所建立的決策邊界附近,因此很容易受到對(duì)抗攻擊的影響。對(duì)抗攻擊會(huì)將圖像移動(dòng)至決策邊界的另一邊,而對(duì)抗解釋攻擊則是將圖像在相同決策區(qū)域內(nèi),沿著決策邊界等高線移動(dòng)。

為實(shí)現(xiàn)此攻擊,研究者所使用的基本方法是Goodfellow提出的 FGSM(fast gradient sign method)方法的變體,這是最早的一種為實(shí)現(xiàn)有效對(duì)抗攻擊而引入的方法。這也表明,其他更近的、更復(fù)雜的對(duì)抗攻擊也可以用于攻擊神經(jīng)網(wǎng)絡(luò)的解釋性。
意義:隨著深度學(xué)習(xí)越來越普遍地應(yīng)用于高風(fēng)險(xiǎn)場(chǎng)景,如醫(yī)學(xué)成像,對(duì)于如何解釋神經(jīng)網(wǎng)絡(luò)所做的結(jié)論也越發(fā)重要。例如,雖然 CNN 網(wǎng)絡(luò)將 MRI 圖像上的小點(diǎn)識(shí)別為惡性致癌腫瘤是非常好的事情,但如果它們是基于非常脆弱的解釋方法,那么也不應(yīng)姑妄信之。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8460瀏覽量
133423 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60733
原文標(biāo)題:機(jī)器學(xué)習(xí)的七大謠傳,這都是根深蒂固的執(zhí)念吧
文章出處:【微信號(hào):CAAI-1981,微信公眾號(hào):中國人工智能學(xué)會(huì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
最新!智慧燈桿七大應(yīng)用場(chǎng)景案例獨(dú)家匯總

揭秘注塑機(jī)快速換模的七大步驟,助力智能制造升級(jí)
什么是機(jī)器學(xué)習(xí)?通過機(jī)器學(xué)習(xí)方法能解決哪些問題?

七騰機(jī)器人:防爆輪式機(jī)器人-四輪八驅(qū)全新上線

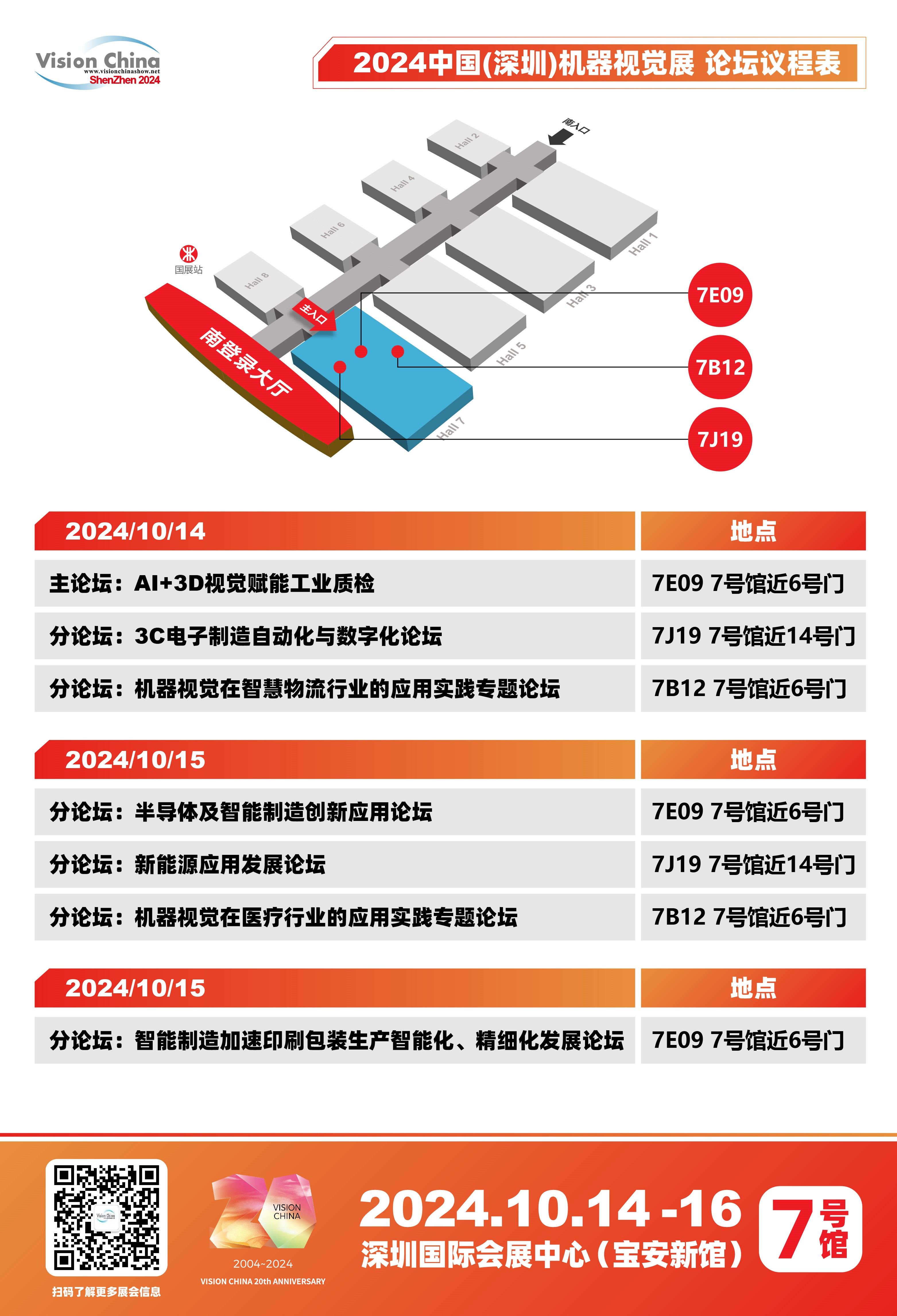
VisionChina2024(深圳)七大議題引領(lǐng)視覺技術(shù)跨界融合,部分論壇議程搶先看!
放大電路中常見的噪聲有哪些
【「時(shí)間序列與機(jī)器學(xué)習(xí)」閱讀體驗(yàn)】+ 簡(jiǎn)單建議
機(jī)器學(xué)習(xí)中的數(shù)據(jù)分割方法
機(jī)器人視覺技術(shù)中常見的圖像分割方法
甲烷濃度檢測(cè)儀中常見的檢測(cè)技術(shù)及其應(yīng)用

機(jī)器學(xué)習(xí)算法原理詳解
小度發(fā)布首款百度文心大模型學(xué)習(xí)機(jī)
基于FPGA的常見的圖像算法模塊總結(jié)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論